







线代有个很难理解的知识点,即同一特征值的线性无关特征向量个数要小于等于特征值重数。 这个结论是怎么来的呢?本文用最朴素的证明来帮助大家弄懂这个知识点(结论推导所用的都是基础的线代知识,只是有些数学式子比较复杂,认真看完,理解很容易,相信自己!)。
a.首先一起看下会用到的两个tips:
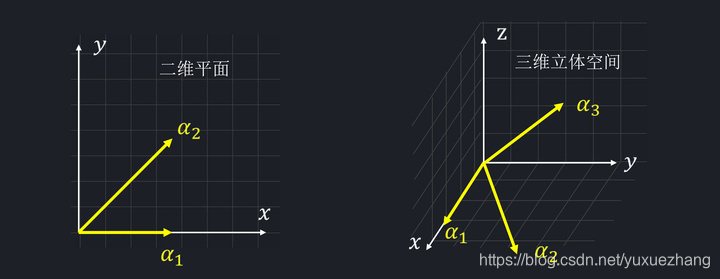
tip 1:一定可以找到n个线性无关的n维向量,且它们可以表示任何一个n维向量
比如2维向量:能找到 α 1 = ( 1 , 0 ) T 和 α 2 = ( 1 , 1 ) T \alpha_{1}=(1,0)^{T} 和 \alpha_{2}=(1,1)^{T} α1=(1,0)T和α2=(1,1)T
两个线性无关的向量,能表示二维平面里面的所有向量。
3维向量:能找到 α 1 = ( 1 , 0 , 0 ) T , α 2 = ( 1 , 1 , 0 ) T , α 3 = ( 0 , 1 , 1 ) T \alpha_{1}=(1,0,0)^{T} , \alpha_{2}=(1,1,0)^{T} ,\alpha_{3}=(0,1,1)^{T} α1=(1,0,0)T,α2=(1,1,0)T,α3=(0,1,1)T三个线性无关的向量,能表示三维立体空间里面的所有向量。
tip 2:来计算一下某种行列式的值
n阶行列式:

以5阶为例,一起来找规律。

由此可见,其行列式的值都是x的某次方乘以一堆式子。
于是我们将此规律扩展到n维:
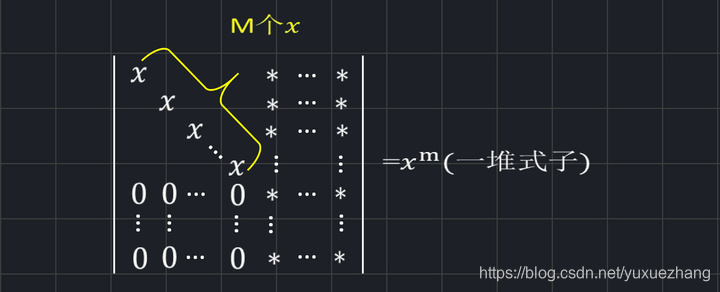
拓展到n维(为了方便,将后面的常数用“星号”代替)
至此两个需要用到的tips讲完了,接着开始证明。
b.准备就绪,开始证明:
设A为n阶矩阵, λ 1 \lambda_{1} λ1 是它特征值(重根), α 1 α m \alpha_{1} ~ \alpha_{m} α1 αm 分别为其m个线性无关的特征向量。所以我们所要证明的就是 λ 1 \lambda_{1} λ1 的重数要≥m
证明:
1.构造一个n阶可逆矩阵P:
由于 α 1 \alpha_{1} α1 ~ α m \alpha_{m} αm 为n维向量,所以一定能找到 α m + 1 \alpha_{m+1} αm+1 ~ α n \alpha_{n} αn,使 α 1 \alpha_{1} α1 ~ α n \alpha_{n} αn 线性无关且可以表示任何一个n维向量(根据前面tip 1得到的)
因此可以构造出一个n阶可逆矩阵
P = ( α 1 , α 2 , … , α m , α m + 1 , … , α n ) P=\left( \alpha_{1} ,\alpha_{2} ,…,\alpha_{m} ,\alpha_{m+1} ,…,\alpha_{n} \right) P=(α1,α2,…,αm,αm+1,…,αn)
2.A左乘可逆矩阵P:
A P = ( A α 1 , A α 2 , … , A α m , A α m + 1 , … , A α n ) AP=\left( A\alpha_{1} ,A\alpha_{2} ,…,A\alpha_{m} ,A\alpha_{m+1} ,…,A\alpha_{n} \right) AP=(Aα1,Aα2,…,Aαm,Aαm+1,…,Aαn)
由特征值与特征向量的关系: A α i = λ 1 α i A\alpha_{i}=\lambda_{1}\alpha_{i} Aαi=λ1αi (其中i=1,2,……,m)得
A P = ( λ 1 α 1 , λ 1 α 2 , … , λ 1 α m , A α m + 1 , … , A α n ) AP=\left( \lambda_{1}\alpha_{1} ,\lambda_{1}\alpha_{2} ,…,\lambda_{1}\alpha_{m} ,A\alpha_{m+1} ,…,A\alpha_{n} \right) AP=(λ1α1,λ1α2,…,λ1αm,Aαm+1,…,Aαn)
又因为: A α i A\alpha_{i} Aαi 的结果为n维向量(i=m+1,m+2,…,n)
所以 A α i A\alpha_{i} Aαi 的结果可以用 α 1 \alpha_{1} α1 ~ α n \alpha_{n} α
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3781
3781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









