







时间序列数据出现在许多现实世界的领域,如能源、交通、通信系统。时间序列数据的精确建模和预测对于提高这些系统的效率具有重要意义。对时间序列问题进行了广泛的研究。不同类型的方法,包括基于统计的方法和基于机器学习的方法,已经被研究。在这些方法中,集成学习被证明是有效的和鲁棒的。然而,如何确定集合中基本模型的权重仍然是一个有待解决的问题。次优权重可能会阻止最终模型充分发挥其潜力。为了应对这一挑战,我们提出了一种基于强化学习(RL)的模型组合(RLMC)框架,用于确定时间序列预测任务集合中的模型权重。通过将模型选择作为一个序列决策问题来制定,RLMC学习了一种确定性策略来输出非平稳时间序列数据的动态模型权值。RLMC进一步利用深度学习来学习原始时间序列数据的隐藏特征,以快速适应变化的数据分布。在多个真实数据集上的广泛实验已经实现,以证明所提出的方法的有效性
研究问题:
本文主要研究了基于集成学习的时间序列预测的模型组合问题。在这项工作中,我们建议解决时间序列预测的模型权重确定问题作为一个强化学习问题
面临的实际问题
1。首先,现实生活中的许多时间序列具有复杂的动力学和非平稳的数据分布
2. 其次,现有的许多时间序列预测模型会过度拟合某些特定的数据分布,而不能很好地推广到其他数据区域

方案:
我们首先提出了模型组合问题的MDP公式。然后,我们从强化学习的角度讨论了模型组合问题的一些见解。最后,我们提出了基于RL的动态模型组合方法。
MDP Setting for Model Combination Problem
用动态的方法确定基本模型的权重可以看作是一个序列决策问题。用于模型选择问题的MDPM =〈S, A, P, r, γ〉
State-space S. 状态st∈RT×ds描述了时间步长t时时间序列的信息,其中t为输入序列长度,ds为输入维数。
Action-space A A是N个基本模型在时间步长t处和为1的非负模型权重


奖励函数r(s, a) 奖励rt定义为预测性能,即预测误差或在时间步t的排名性能
Discount factor γ 描述了我们对未来表现的衡量。如果我们只关心一步预测,那么我们可以设置γ = 0。

框架:

Strategies for Efficient Exploration
在训练期间,我们首先训练N个基础模型M =〈M1,···,MN在训练集上〉。值得注意的是,我们可以选择不同类型的算法,例如经典的统计模型或神经网络作为基础模型,以增加多样性。给定N个预先训练的模型,动作a =(w1,···,wN)是一个概率单形 。当集成模型由多个不同的基础模型组成时,我们面临的是一个搜索空间巨大的连续控制问题。因此,朴素的ϵ-greedy勘探策略可能需要大量的样本学习一种近乎最优的策略。本文介绍三种提高exploration效率的技术(图5)。

我们建议使用第二个回放缓冲区来存储低奖励的硬样本,并通过从两个缓冲区的采样转换来训练RLMC代理,以缓解过拟合。
RL Based Model Combination (RLMC)


Reward function r(s, a).

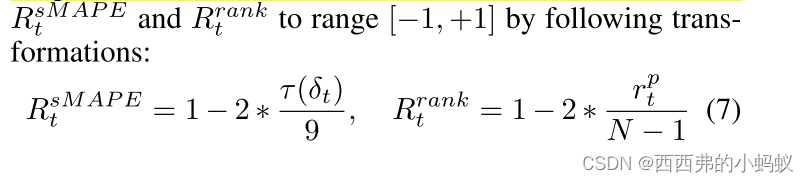

Experiments
















 1144
1144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









