






这些是关于大型语言模型(LLM)的 Function Calling、MCP、A2A 比较常见的问题。
1. Function call怎么训练的?怎么微调的?
将 Function Calling 能力赋予 LLM 主要通过监督微调 (Supervised Fine-tuning, SFT) 实现,而不是在预训练阶段从零开始专门训练。基础模型需要先具备良好的指令遵循和代码/结构化数据生成能力。
- 训练/微调的核心思想: 教会模型两件事:
- 识别意图 (Intent Recognition): 理解用户的请求是否需要借助外部工具/函数来完成,而不是直接生成文本回答。
- 参数提取与格式化 (Argument Extraction & Formatting): 如果需要调用函数,正确地从用户请求中抽取出所需的参数,并按照预先定义的格式(通常是 JSON)生成函数调用的指令。
- 训练/微调过程:
- 准备数据集: 这是最关键的一步。需要构建一个包含 Function Calling 场景的指令微调数据集。每条数据样本通常包含:
- 用户输入 (Input/Query): 一个可能需要或不需要调用函数的用户请求。例如:“查询北京今天的天气怎么样?” 或 “给我写一首关于春天的诗”。
- 可用函数/工具描述 (Available Functions/Tools Description): 一个结构化的描述,告知模型当前有哪些函数可用,每个函数的用途、所需参数及其类型和描述。这个描述本身通常就是文本,需要设计一种清晰的格式(见下一个问题)。
- 期望的输出 (Desired Output):
- 如果需要调用函数: 一个特定格式的字符串,通常是包含函数名和提取出的参数的 JSON 对象。例如:
{
"name": "get_weather",
"arguments": {
"city": "北京",
"date": "今天"
}
}
-
-
-
- 如果不需要调用函数: 模型应该生成的直接文本回答。例如:“好的,这是一首关于春天的诗:...”
-
-
- 选择基础模型: 选择一个具备强大指令遵循能力的预训练 LLM (例如 Llama, GPT, ChatGLM 等)。
- 格式化训练数据: 将每条数据样本组合成模型可以理解的格式。通常是将“用户输入”和“可用函数描述”拼接起来作为模型的输入 (Prompt),将“期望的输出”(无论是 JSON 函数调用还是文本回答)作为目标输出 (Completion/Target)。需要使用特定的分隔符或模板来区分不同部分。
- 进行微调: 使用标准的 SFT 方法(全参数微调或 PEFT 如 LoRA)在准备好的数据集上训练模型。模型的优化目标是最小化预测输出和期望输出之间的差异(例如,使用交叉熵损失)。模型通过学习这些样本,学会根据用户输入和可用函数描述,决定是直接回答还是生成特定格式的函数调用 JSON。
- 关键挑战:
- 数据集质量: 需要足够多、覆盖各种场景(需要/不需要调用、不同函数、参数变化、模糊表达)的高质量数据。
- 函数描述的清晰度: 函数描述的质量直接影响模型能否正确理解和使用函数。
- 负样本: 需要包含足够多明确不需要调用函数的样本,防止模型“过度触发”函数调用。
2. Function call怎么组织文本的格式喂给模型?
这个其实看一下HuggingFace上常见的Function-Call数据集就知道了。
https://huggingface.co/datasets?search=function-calling
例如:
https://huggingface.co/datasets/NousResearch/hermes-function-calling-v1

在训练和推理时,将信息喂给模型的格式至关重要。虽然没有绝对统一的标准,但通常遵循以下结构,通过特殊的提示词(Prompting)或模板来实现:
- 基本结构:
[系统提示/全局指令] (可选,设定角色、能力边界等)
[可用函数/工具描述区]
(这里详细列出每个可用函数的结构化描述)
[对话历史] (可选,对于多轮对话很重要)
User: ...
Assistant: ...
User: ... (当前用户请求)
[触发指令/分隔符] (提示模型开始思考或生成)
Assistant:
- 可用函数/工具描述区的格式: 这是核心部分,需要清晰地传达每个函数的信息。常见做法是使用 JSON 列表或类似的结构化文本:
Functions available:
[
{
"name": "get_weather",
"description": "查询指定城市和日期的天气信息。",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "需要查询天气的城市名称,例如:北京"
},
"date": {
"type": "string",
"description": "需要查询的日期,例如:今天、明天、2023-10-26"
}
},
"required": ["city", "date"] // 指明哪些参数是必须的
}
},
{
"name": "send_email",
"description": "发送邮件给指定的收件人。",
"parameters": {
"type": "object",
"properties": {
"recipient": {
"type": "string",
"description": "收件人的邮箱地址"
},
"subject": {
"type": "string",
"description": "邮件主题"
},
"body": {
"type": "string",
"description": "邮件正文内容"
}
},
"required": ["recipient", "subject", "body"]
}
}
// ... 可以有更多函数描述
]
- 关键要素:
- name: 函数的唯一标识符。
- description: 用自然语言清晰描述函数的功能和适用场景,这是模型理解何时调用该函数的关键。
- parameters: 定义函数接受的参数。
- type: 通常是 "object"。
- properties: 一个对象,列出每个参数的名称、类型 (string, integer, boolean, enum 等) 和描述 (解释参数的含义和格式)。
- required: 一个列表,包含必须提供的参数名称。
- 对话流程中的格式:
1 用户请求: 用户发出请求,例如 "帮我查一下明天上海的天气,然后给张三发邮件告诉他结果"。
2 模型首次响应 (Function Call): 模型识别到需要调用 get_weather,生成 JSON:
{
"name": "get_weather",
"arguments": {
"city": "上海",
"date": "明天"
}
}
3 外部执行: 应用程序捕获这个 JSON,调用实际的天气 API。
4 将结果喂回模型: 将 API 返回的天气结果格式化后,作为新的输入信息提供给模型。例如:
Function Result for get_weather:
{
"temperature": "25°C",
"condition": "晴朗"
}
5 模型再次响应 (可能再次 Function Call 或最终回答): 模型看到天气结果,现在需要执行邮件发送任务,生成 JSON:
{
"name": "send_email",
"arguments": {
"recipient": "张三", // 可能需要澄清张三的邮箱
"subject": "明天上海天气",
"body": "明天上海的天气是 25°C,天气晴朗。"
}
}
6 外部执行: 应用程序调用邮件发送服务。
7 将结果喂回模型: 告知邮件发送成功。
8 模型最终回答: 模型生成最终的自然语言回复给用户:“我已经查询到明天上海天气是25°C,晴朗,并且已经发邮件告诉张三了。”
3. Function call怎么把下游的一些工具,插件变成模型可以理解的方式?
这个过程的核心是标准化描述 (Standardized Description) 和 执行对接 (Execution Bridging)。
- 标准化描述:
- 定义 Schema: 为每个工具、插件或 API 设计一个符合上述 Function Call 格式的结构化描述(JSON Schema 是常用方式)。这个 Schema 必须清晰地包含:
- 唯一名称 (Name): 用于模型识别调用哪个工具。
- 功能描述 (Description): 清晰说明工具的作用、输入、输出,以及何时应该使用它。这是 LLM 理解的关键。
- 参数定义 (Parameters): 详细列出工具需要的每个参数的名称、数据类型、是否必需以及描述。
- 编写高质量描述: 描述语言要自然、准确、无歧义。LLM 依赖这些描述来判断用户的意图是否与工具功能匹配。例如,避免使用过于技术化或模糊的术语。
- 定义 Schema: 为每个工具、插件或 API 设计一个符合上述 Function Call 格式的结构化描述(JSON Schema 是常用方式)。这个 Schema 必须清晰地包含:
- 执行对接:
- 提供描述给模型: 在每次与模型交互时,将所有当前可用的工具的标准化描述作为上下文信息传递给模型(通常放在 Prompt 的特定区域)。
- 解析模型输出: 应用程序需要监听模型的输出。如果输出是符合预定义格式的 Function Call JSON,则解析它。
- 调用实际工具: 根据解析出的 name 找到对应的下游工具/插件/API。
- 参数映射与校验: 从 arguments 中提取参数值,进行必要的类型转换和校验,然后调用实际的工具接口。
- 结果处理: 获取工具执行的结果(成功响应或错误信息)。
- 结果反馈给模型: 将执行结果格式化成文本,再次输入给模型,让模型基于这个结果继续生成回复或执行下一步操作。
简单来说,就是为每个工具制作一个清晰的“说明书”(Schema/描述),让模型能看懂。然后建立一个“翻译和执行”层,负责把模型根据说明书写的“指令”(JSON Call)转换成对实际工具的操作,并把工具的“回执”(结果)再翻译给模型听。
注:MCP其实就是做这个的。
4. MCP与Function Call的区别与关系
现在面试估计肯定会问道MCP与Function Call,这是一个解释的图示:
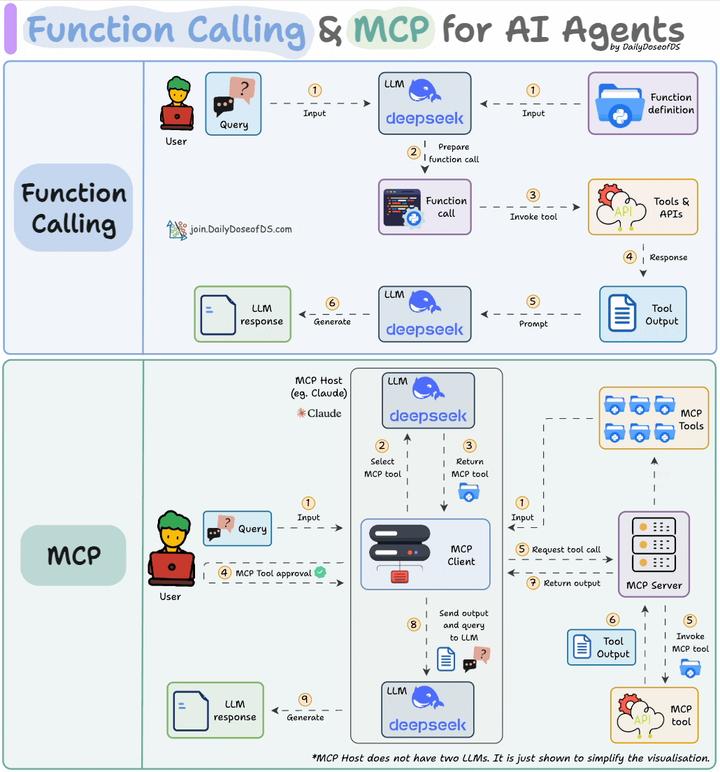
函数调用是一种机制,它允许 LLM 根据用户的输入识别它需要什么工具以及何时调用它。
以下是它通常的工作原理:
- LLM 收到来自用户的提示。
- LLM 决定它需要的工具。
- 程序员实现过程以接受来自 LLM 的工具调用请求并准备函数调用。
- 函数调用(带参数)将传递给将处理实际执行的后端服务。
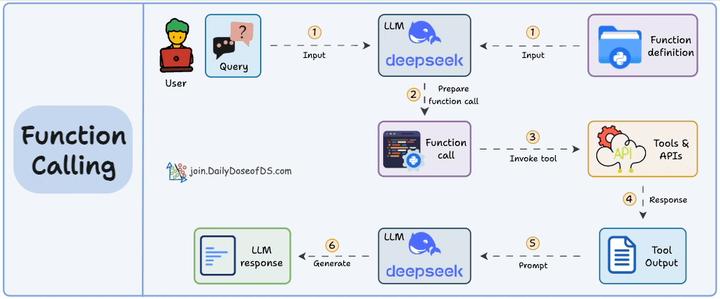
MCP(即模型上下文协议,Model Context Protocol)试图标准化此过程。 MCP (Model Context Protocol):是一个开放协议和标准,旨在标准化AI 应用(MCP 客户端)如何发现、连接和与外部工具/数据源(实现为 MCP 服务器)进行交互。它关注的是系统间的通信和集成,解决 Function Calling 指令生成后,如何高效、安全、可扩展地执行这些调用。
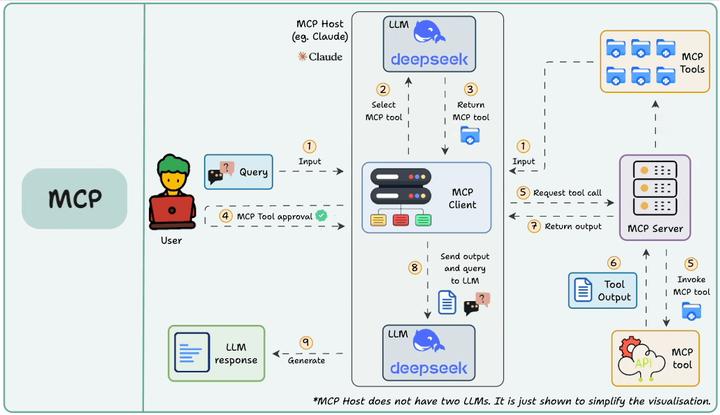
Function Call侧重于模型想要做什么,而 MCP 侧重于如何使工具可被发现和可消费,尤其是在多个Agent、模型或平台之间。MCP 不是在每个应用程序或代理中硬连接工具,而是:
- 标准化了工具的定义、托管和向 LLM 公开的方式。
- 使 LLM 能够轻松发现可用工具、了解其架构并使用它们。
- 在调用工具之前提供审批和审计工作流程。
- 将工具实施的关注与消费分开。
关系:Function Calling 是 LLM 产生调用请求的能力,MCP 是标准化执行这些请求的协议框架。FC 生成指令,MCP 负责让这些指令能在各种工具间通用、可靠地传递和执行。它们是互补的,FC 是 MCP 架构中模型表达意图的方式之一。
具体参考:北方的郎:LLMs的函数调用(Function Call)和MCP——直观的对比解释
5 MCP与A2A的关系
Agentic 应用需要同时使用 A2A 和 MCP。
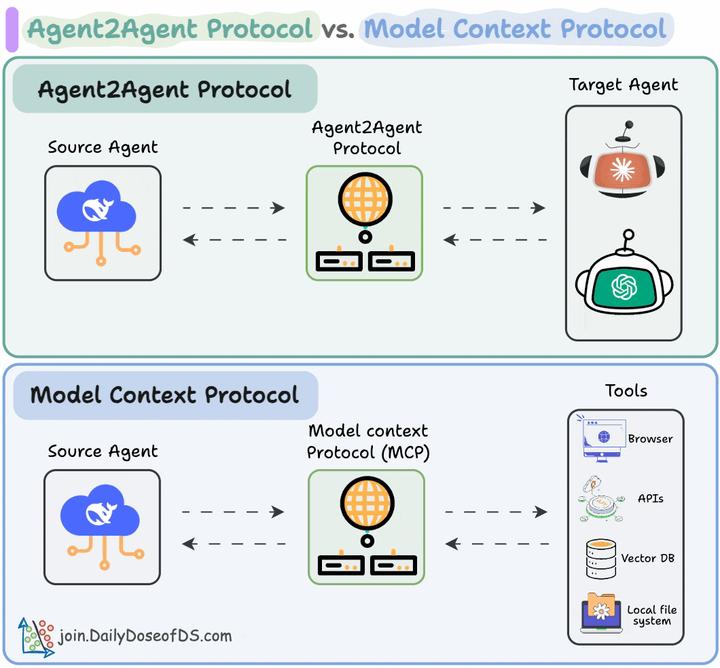
- MCP 为智能体提供对工具的访问能力。
- 而 A2A 则让智能体之间能够连接和协作组队。
简而言之:
- Agent2Agent(A2A)协议允许 AI 智能体连接其他智能体。
- Model Context Protocol(MCP)让 AI 智能体连接工具/API。
因此,使用 A2A 时,两个智能体可能正在互相对话……而他们本身也可能正在与 MCP 服务器通信。从这个意义上讲,它们并不互相冲突。
如下图所示,Agent2Agent(A2A)协议使多个 AI 智能体可以协同完成任务,而无需直接共享它们的内部记忆、思考或工具。
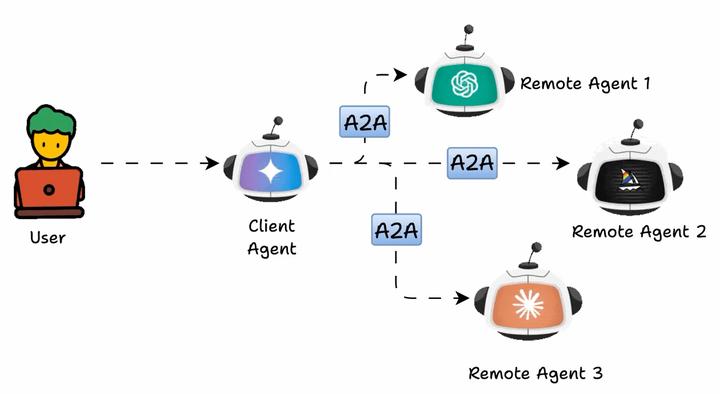
它们通过交换上下文、任务更新、指令和数据进行通信。从本质上说,AI 应用可以将 A2A 智能体建模为 MCP 资源,这些资源由它们的 AgentCard(智能体卡片) 表示。
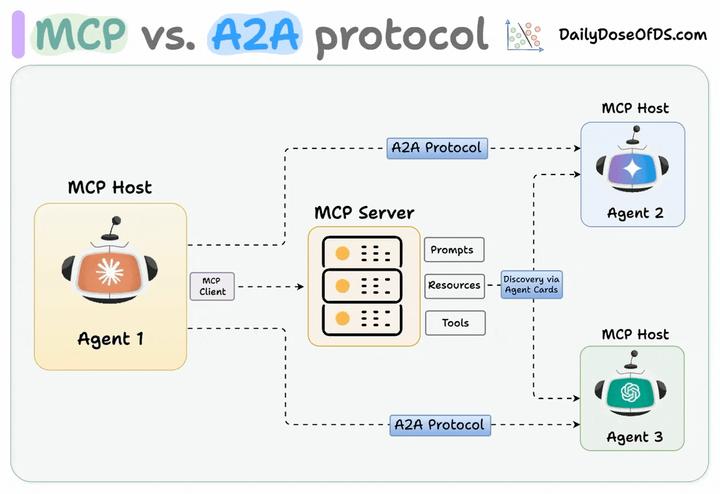
通过这种方式,连接到 MCP 服务器的 AI 智能体可以发现新的合作智能体,并通过 A2A 协议建立连接。

支持 A2A 的远程智能体必须发布一个 “JSON 智能体卡片”,详细说明其能力和认证信息。客户端使用此卡片来查找和与最适合某项任务的智能体进行通信。
A2A 的几个强大特性包括:
- 安全协作
- 任务与状态管理
- 能力发现
- 来自不同框架的智能体协同工作(如 LlamaIndex、CrewAI 等)
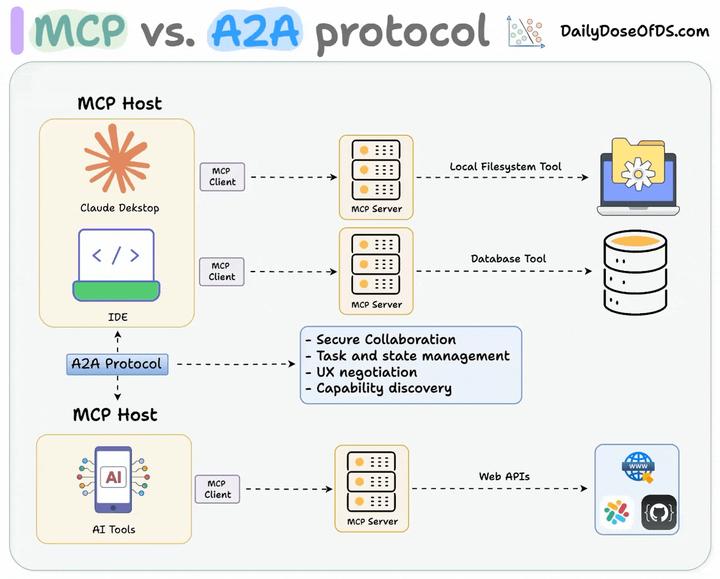
此外,它还可以与 MCP 集成使用。虽然它目前还比较新,但对智能体之间的协作进行标准化是非常有价值的,就像 MCP 为智能体与工具的交互所做的一样。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 146
146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









