






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
SLAM(同步定位与地图构建)技术的精度评估对其可靠性和性能至关重要。常用的评估指标包括绝对轨迹误差(ATE)、相对姿态误差(RPE)、地图精度和闭环检测。ATE用于衡量SLAM系统估计轨迹与实际路径之间的偏差,通过计算估计位置和真实位置的欧氏距离来量化定位精度,低ATE值表明系统能更准确地反映实际路径。RPE评估相邻帧之间的相对运动估计误差,通过比较估计的相对运动与真实相对运动之间的差异来衡量局部精度,常用于评估短时间内的累积误差,特别适用于动态环境。地图精度通过比较生成的地图与实际环境数据来评估地图的精确度,高精度地图对机器人导航和环境理解至关重要。闭环检测用于评估SLAM系统能否在返回先前位置时正确识别并校正累积误差,成功的闭环检测能够消除漂移误差,提高系统定位和地图构建精度,增强系统鲁棒性。这些评估指标在论文中帮助研究人员全面了解SLAM系统性能,在实际工程中则确保SLAM系统在应用中的可靠性和有效性。
1.ATE/APE
绝对轨迹误差(Absolute Trajectory Error ATE):
ATE 对比数据序列时间戳中每个相 近时刻下算法解算的载体位姿估计值与真实位姿 之间的差值,是评估算法定位精度的主要指标,公式如下
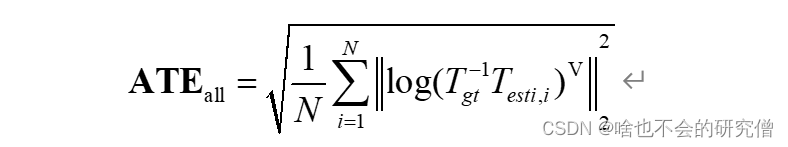
有的地方仅考虑平移误差,从而可以定义绝对平移误差(Absolute Translational Error, ATE):
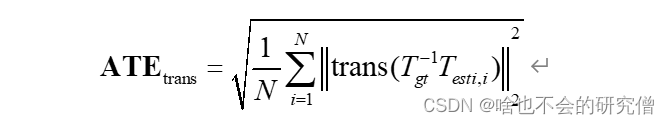
其中 trans 表示取括号内部变量的平移部分
2.RPE(Relative Pose Error)
RPE 定义的是相对的误差。RPE 计算数据序列时间戳中每个固定时间间隔内 算法估计位姿变化量与真实位姿变化量的差值,是评估系统漂移的主要指标,相对位姿误差计算的公式如下所示
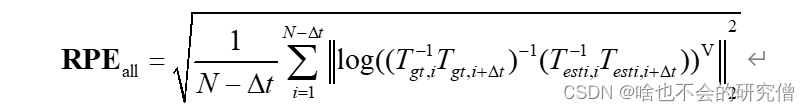
只取平移部分:
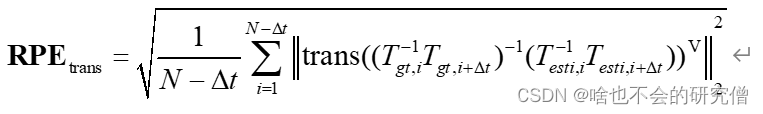
3. 具体的指标介绍
max: 表示最大误差;
mean: 平均误差;
median: 误差中位数;
min: 最小误差;
rmse: 均方根误差;
sse: 和方差、误差平方和;
std: 标准差
4. 总结
(1) ATE(Absolute Trajectory Error):绝对轨迹误差,以米(m)为单位,用于度量估计的相机在全局参考坐标系下的位置误差。
(2) RPEt(Relative Pose Error translation):相对姿态误差(平移部分),以米/米(m/m)为单位,度量估计的相机相对于真实相机的平移误差。
(3) RPER(Relative Pose Error rotation):相对姿态误差(旋转部分),以度/米(°/m)为单位,度量估计的相机相对于真实相机的旋转误差。
参考:
https://blog.csdn.net/weixin_44458958/article/details/130956717?ops_request_misc=&request_id=&biz_id=102&utm_term=SLAM%E7%B2%BE%E5%BA%A6%E7%9A%84%E8%AF%84%E4%BC%B0%E7%9A%84%E5%87%A0%E7%A7%8D%E6%8C%87%E6%A0%87%E4%BB%8B%E7%BB%8D&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-0-130956717.142v100pc_search_result_base4&spm=1018.2226.3001.4187



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











