







【上一节蒙特卡洛方法(Monte Carlo Method)】
Temporal-difference (TD) learning可以说是增强学习的中心,它集成了蒙特卡洛思想和动态编程(dynamic programming, DP)思想,像蒙特卡洛方法一样,TD 方法不需要环境的动态模型,直接从经验经历中学习,像 DP 方法一样,TD 方法不需要等到最终的 outcome 才更新模型,它可以基于其他估计值来更新估计值。
1、TD Prediction
TD 和 蒙特卡洛方法都使用经验来解决预测问题,给定服从规则
π
的一些经历,两种方法均可更新经历中的每一个非终止的状态
St
的
vπ
。粗略的说, Monte Carlo 方法要等到
return
知道之后才将其设为是
V(St)
的目标值,一个适合非固定环境的简单的 every-visit Monte Carlo 方法为:
其中 Gt 代表得是时间 t 之后的真实 return, alpha 是固定的 step-size 参数,可以将这种方法称为是 constant−α MC ,Monte Carlo 方法必须等到 episode 结束之后才能决定 V(St) 的增量,与 Monte Carlo 方法不同的是 TD 方法只需等到下一个 time step 即可,即在时刻 t+1 ,TD 方法立刻形成一个 target 并使用观测到的 reward Rt+1 和估计的 V(St+1) 进行更新,最简单的 TD 方法称为是 TD(0) ,其更新方法为:
比较上面的式子可以看出,TD 方法与Monte Carlo 方法一样,都是基于已有的估计进行更新,因此 TD 方法也是一种 bootstrapping 方法,只不过Monte Carlo 更新的目标值为 Gt ,而 TD 更新的目标值为 Rt+1+γV(St+1) ,他们俩的关系其实可以从下面的式子来更好的理解:
粗略地说,Monte Carlo 方法使用的目标值是 vπ(s)≐Eπ[Gt|St=s] ,而 DP 方法使用的是 vπ(s)=Eπ[Rt+1+γvπ(St+1)|St=s] ,在 TD 方法中,由于 vπ(St+1) 是未知的,因此就用当前的估计值 V(St+1) 来代替,TD(0) 的伪代码如下所示:

TD(0) 的 backup diagram 如下图所示,它对最上面的节点的 value 评估值的更新基于的是从它到下一个 state 的一次样本转换,TD 和 Monte Carlo 更新可以称为是 sample back-ups,因为他们都涉及到采样的连续的状态或状态对,sample back-ups 与 DP 方法的 full backups 的不同在于,它利用的不是所有可能的转换的完全分布,而是一个单一的样本转换。

在 TD 学习中还有一个重要的概念叫 TD error,用
δt
表示,它表示的就是在该时刻估计得误差,在 TD(0) 中它指的就是
Rt+1+γV(St+1)
与
V(St)
的差,即在
V(St)
的误差:
Monte Carlo error 可以写作是一系列 TE errors 的和:
2、TD Prediction方法的优点
相比于 DP 方法,TD 方法不需要环境的模型,相比于 Monte Carlo 方法,TD 方法可以采用在线的、完全增量式的实现方式,在 Monte Carlo 方法中,必须要等到 episode 结束有了 return 之后才能更新,在有些应用中 episodes 的时间很长,甚至有些应用环境是连续型任务,根本没有 episodes。而 TD 方法不需等到最终的真实的 return,并且 TD 方法可以保证收敛到 vπ 。
3、TD(0) 方法的最优性
假如经历或者经验的数量是有限的,如 10 个 episodes 或者 100 个 time steps,在这种情况下,增量式学习方法的通常做法是不断重复地利用这些经历直到收敛到确定的结果,即给定一个近似的 value 函数 V,在每个时间 t,只要访问的不是终止状态,就可以计算其增量,并在结束时更新一次函数 V,之后再重复处理,直到最后的 value 函数收敛,这种方法常常称为是 batch updating,因为更新是在训练数据的整个 batch 处理之后发生的,并且每遍历一次 batch 只更新一次。
在 batch updating 模式下,只要选择的 step-size 参数
α
足够小,TD(0) 一定会收敛到一个单一的结果,并且与 step-size 参数
α
无关。注意到在同样的条件下,constant-
α
MC 方法也会收敛到一个确定的值,但这个值与 TD(0) 的不同。
batch TD(0) 与 batch MC 的区别在于,batch MC 是得到在训练集上使得 mean-squared error 最小的估计值,而 batch TD(0) 获得的总是 Markov 过程的最大似然估计模型,我们知道一个 data 的最大似然估计是指在该估计值时生成当前 data 的概率最大,因此对于我们待估计的 Markov 过程,在当前已有的 episodes 下,其最大似然估计模型为:从状态
i
到状态
j
的转换概率的估计值就是所有观测到的从状态
i
转换到状态
j
占所有从状态
i
进行转换的经历的比例,从状态
i
到状态
j
的 reward 的评估值就是观测到的所有从状态
i
转换到状态
j
的rewards 的平均值。因此,只要模型正确则计算的 value function 一定是正确的,通常将这种估计称作是“确定性等价估计”(certainty-equivalence estimate),因为它相当于假定了基本过程的估计是确定而不是近似的。通常 batch TD(0) 会收敛到 certainty-equivalence estimate,因此在批模式下 TD(0) 的收敛速度比 Monte Carlo 方法快。虽然在某种意义上说 certainty-equivalence estimate 是一个优化的解,但常常无法直接计算求解,在状态空间很大的情况下,TD 方法是唯一可以近似求得近似的 certainty-equivalence estimate 的可行方法。
4、Sarsa: On-Policy TD Control
同样有了 TD prediction 方法,下一步就是如何利用 prediction 方法来解决 control problem,在这里的 control problem 中,同样要考虑 exploration 和 exploitation 的权衡问题,与 MC 方法一样,TD control method 也包含 on-policy 和 off-policy,这一小节介绍的是 on-policy TD control method。
对于 on-policy 方法,第一步是要对当前的行为规则
π
估计所有状态
s
和行为
a
的
qπ(s,a)
,估计的方法与上面介绍的学习
vπ
的方法一样,每一个 episode 是由一系列 states 和 state-action 对组成的转换序列:

这里我们需要关注的是从一个 state-action pair 向另外一个 state-action pair 的转换过程,很容易知道,该评估值更新方程为:
每次从一个非终止状态 St 进行转换都会利用上面的更新方程来更新 Q(St,At) ,注意到该方程中一共包含了5个元素: (St,At,Rt+1,St+1,At+1) ,因此将这种方法称为是 Sarsa ,其 backup 图为:
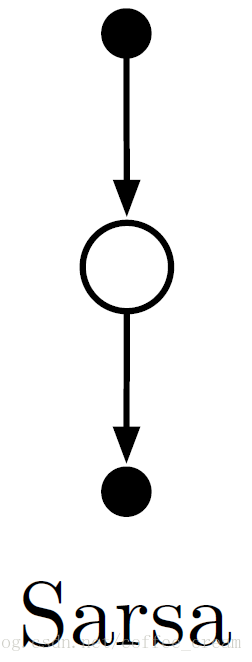
基于 Sarsa 方法,就可以得到 on-policy control algorithm,对所有 on-policy method,在持续的对行为规则
π
估计
qπ
的同时,也依据
qπ
采用贪婪的方式来修改行为规则
π
,Sarsa control algorithm 的一般形式为:

5、Q-learning:Off-Policy TD Control
想必所有听说过 RL 的人都听过 Q-learning 的大名,与 Sarsa 不同的是,Q-learning 是一种 off-policy 的策略,其定义为:
在这种情形下,学习的 action-value 函数 Q 直接近似于与规则无关的优化 action-value 函数 q∗ ,并且这个规则还决定了下一个 visit 和 update 的 state-action pairs,Q-learning 的伪代码如下:

其 backup diagram 如下所示,因为该规则更新的是一个 state-action 对,因此 backup 的顶端一定是一个 action node,并且该规则是在下个状态所有可能的 actions 中选择最大化的 action nodes,因此该图的最下面一定是所有的 action nodes,其中“maximum”是用一个跨越它们的弧线来表示的。
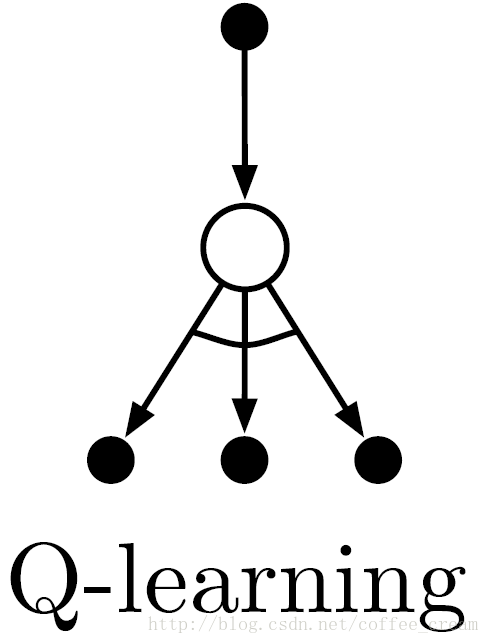
由于 Q-learning 并不关心服从的是什么 policy,而仅仅是采取最好的 Q-value,他学习的规则与实行的规则不同,因此这是一种 off-policy 学习算法
6、Expected Sarsa
Expected Sarsa 与 Sarse、Q-learning 都有点相似之处,它的更新方程如下:
Expected Sarsa 与 Q-learning 相比,Q-learning 是在下一个 state-action pairs 中选择最大化的,而 expected Sarsa 选用的是它们的平均值。给定下一个状态 St+1 ,该算法的前进方向与 Sarsa 在 expectation 的前进方向相同,因此这种方法称为是 expected Sarsa。Expected Sarsa 比 Sarsa 要复杂,但因为它对 At+1 随机采样,因此可以消除方差,在给定相同数量的 experience 下,其性能要比 Sarsa 略好。其 backup diagram 如下所示:
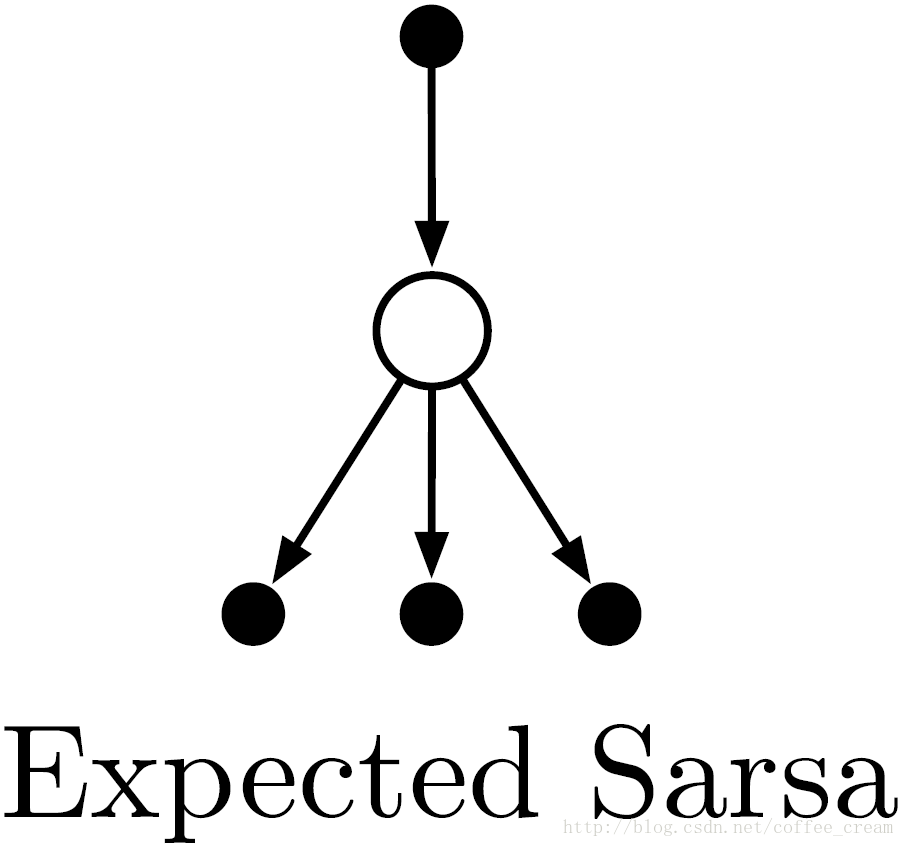
7、Maximization Bias and Double Learning
前面几节讨论的算法都含有对 target policies 最大化的内容,例如,在 Q-learning 中,target policy 是在当前 action values 中最大化的 greedy policy;在 Sarsa 中,常常采用的是
ε
-greedy 策略,其中也包含最大化的操作。这些算法,估计值中的最大值常常作为是最大值的估计,从而会带来一个显著的 positive bias,这个偏差就称为是 maximization bias。
为了避免 maximization bias,常采用的策略是 double learning。我们可以先考虑一下 maximization bias 产生的原因,假设在一个 bandit 问题中,它的原因就在于我们在决定最大化的 action 和在对它的 value 进行评估时采用的是相同的 samples / plays,因此,double learning 的思想是同时学习两个独立的估计,假设它们分别表示为
Q1(a)
和
Q2(a)
(
a∈calA
),估计值
Q1(a)
利用
A∗=argmaxaQ1(a)
来确定最大化的行为,估计值
Q2(a)
利用
Q2(A∗)=Q2(argmaxaQ1(a))
来进行估计,由
E[Q2(A∗)]=q(A∗)
可知这是一个无偏估计,可以通过反转两个估计的角色来获得第二个无偏估计
Q1(argmaxaQ2(a))
,从中可以看出即使我们学习的是两个评估值,但每次只会更新其中一个,虽然它需要两倍的内存,但每步中的计算量并没有增加。
double learning 的思想可以推广到 full MDPs 中,例如将 double learning 与 Q-learning 相结合就产生了 Double Q-learning,其更新方程为:
Double Q-learning 的伪代码如下:

参考文献
[1] Reinforcement Learning: An Introduction, Richard S. Sutton and Andrew G. Barto
[2] UCL Course on RL















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









