






前言
在实际工作中,经常有人问,7B、14B或70B的模型需要多大的显存才能推理?如果微调他们又需要多大的显存呢?为了回答这个问题整理一份训练或推理需要显存的计算方式。如果大家对具体细节不感兴趣,可以直接参考经验法则评估推理或训练所需要的资源。更简单的方式可以通过这个工具[1]或者huggface官网计算推理/训练需要的显存工具[2]在线评估。
数据精度
开始介绍之前,先说一个重要的概念——数据精度。数据精度指的是信息表示的精细程度,在计算机中是由数据类型和其位数决定的。如果想要计算显存,从“原子”层面来看,就需要知道我们的使用数据的精度,因为精度代表了数据存储的方式,决定了一个数据占多少bit。目前,精度主要有以下几种:
-
• 4 Bytes: FP32 / float32 / 32-bit
-
• 2 Bytes: FP16 / float16 / bfloat16 / 16-bit
-
• 1 Byte: int8 / 8-bit
-
• 0.5 Bytes: int4 / 4-bit
经验法则
- • 推理: 参数量 * 精度。
例如,假设模型都是16-bit权重发布的,也就是说一个参数消耗16-bit或2 Bytes的内存,模型的参数量为70B,基于上述经验法则,推理最低内存需要70B * 2Bytes = 140G。
- • 训练: 4 - 6 倍的推理资源。
推理
在模型推理阶段,需要的资源主要有三部分:模型的权重、KV Cache和激活(在推理过程中创建的张量)。
模型权重
加载模型权重(即模型大小)占用资源主要依赖于模型的参数量和精度。其中,参数量基本不变,精度可以通过模型量化技术进行优化。尽管量化会影响模型的性能,但相比于选择更高精度的小模型来说,量化技术更受青睐。
公式:模型的大小 = 模型的参数量 * 精度
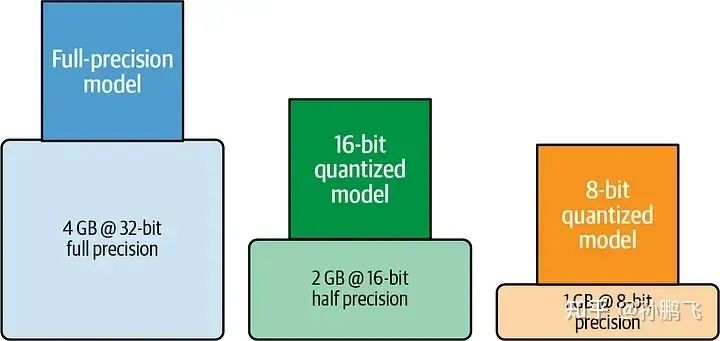
十亿参数模型在 32 位、16 位和 8 位精度下所需的近似 GPU 内存[2]
KV Cache
在Transformer的解码阶段,每次推理生成一个token,依赖于之前的token结果,如果每次都对所有token重新计算一次,代价非常大。为了避免重新计算,通过KV Cache技术将其缓存到GPU内存中。
公式:KV Cache = 2 * Batch Size * Sequence Length * Number of Layers * Hidden Size * Precision
注意:第一个因子2解释了K和V矩阵。通常,在Transformer中,Hidden Size和Number of Layers的值可以在模型相关的配置文件中找到。
激活内存
在模型的前向传播过程中,必须存储中间激活值。这些激活值代表了神经网络中每层的数据在向前传播时的输出。它们必须保持为 FP32 格式,以避免数值爆炸并确保收敛。
公式 :Activation Memory = Batch Size * Sequence Length * Hidden Size * (34 + (5 * Sequence Length * Number of attention heads) / (Hidden Size))
训练
训练阶段所需的资源,除了上述介绍的模型权重、KV Cache和激活内存之外,还需要存储优化器和梯度状态,因此,训练比推理需要更多的资源。
优化器内存
优化器需要资源来存储参数和辅助变量。这些变量包括诸如Adam或SGD等优化算法使用的动量和方差等参数。这取决于优化状态的数量及其精度。例如,AdamW优化器是最流行的微调llm,它为模型的每个参数创建并存储2个新参数。如果我们有一个70B的模型,优化器将创建140B的新参数!假设优化器的参数为float32,即每个参数占用4字节的内存。优化器至少需要 140B * 4 Bytes = 516 G的资源。
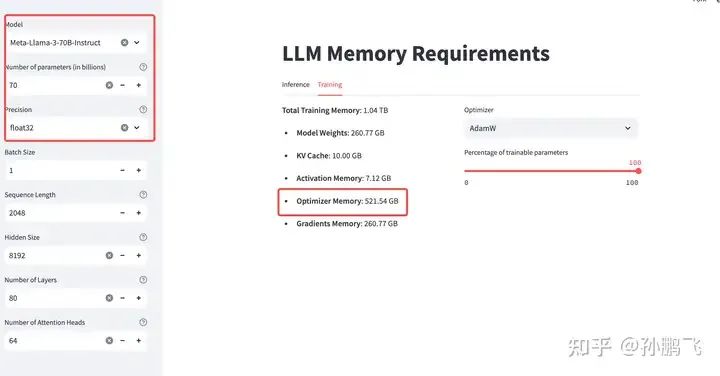
其中,不同优化器的状态数量如下:
-
• AdamW (2 states): 8 Bytes per parameter
-
• AdamW (bitsandbytes Quantized): 2 Bytes per parameter
-
• SGD (1 state): 4 Bytes per parameter
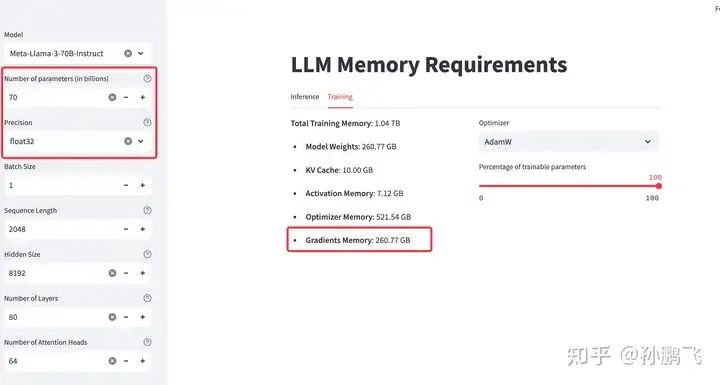
梯度
在模型的反向传播过程中计算梯度值。它们表示损失函数相对于每个模型参数的变化率,对于在优化过程中更新参数至关重要。作为激活值,它们必须存储在 FP32 中以保持数值稳定性 。因此,每个参数占用4字节的内存 。例如,一个70B的模型,计算梯度所需的内存需要 70B * 4 Bytes = 280 G左右。
总结
在本文中,我们介绍的评估方法,都是基于Transformer架构推算的,该评估方法不适合Transformer以外的其他体系结构。同时,目前存在大量的框架、模型和优化技术,估计运行大型语言模型的确切内存可能很困难。然而,本文可作为估计执行 LLM 推理和训练所需内存资源的起点。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 465
465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









