







【ML】 transform(self-attention)的各种变体
- 1、transform模型背景
- 2. 引入讲解的任务场景
- 3. 模型整体结构
- 4. 输入部分&Embedding
- 5、位置编码(Positional Encoding)
- 6、Encoder部分
- 7、Decoder部分
- 8、输出部分
- 9、有关训练
- 10、全部代码及资料
1、transform模型背景
paper:Attention Is All You Need
原文对 transform的定义是:
Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence aligned RNNs or convolution。
1.1 发展动机:
目前在序列建模和转换问题中,如语言建模和机器翻译,所采用的主流框架为Encoder-Decoder框架。传统的Encoder-Decoder一般采用RNN作为主要方法,基于RNN所发展出来的LSTM和GRU也被曾认为是解决该问题最先进的方法。而RNN模型的计算被限制为顺序,这种机制阻碍了样本训练的并行化,又会导致在计算过程中信息丢失从而引发长期依赖问题。RNN及其衍生网络的缺点就是慢,问题在于前后隐藏状态的依赖性,无法实现并行。
1.2 transformer为何优于RNN及RNN的一系列变体?
Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。作者采用Attention机制的原因是考虑到RNN(或者LSTM,GRU等)的计算限制为是顺序的,也就是说RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
- 时间片的计算依赖时刻的计算结果,这样限制了模型的并行能力。
- 顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。
如上图所示,不管中间用的是RNN还是GRU,它们都无法避免一种情况:它们是前后相互依赖的(图中箭头),对于后面的输出,它依赖的是前面的状态和当前的输入。
这就意味着,我们想要得到这个输出,那就必须得到前面的状态。所以必须要走完上一步,才能走下一步。所以说它的计算被限制为顺序,阻碍了样本的并行化训练。
1.3 transformer特点
基于Attention机制,将序列中任意两个位置之间的距离缩小为一个常量。
Transformer利用self-attention机制实现快速并行,改进了RNN/LSTM最被人诟病的训练慢的缺点,同时也符合现有GPU框架的矩阵化训练。
Transformer可以增加到非常深的深度跳跃连接,充分发掘DNN模型的特性,提升模型准确率。
2. 引入讲解的任务场景
方便讲解,和原论文一致是机器翻译场景。
图片
3. 模型整体结构
3.1 模型结构图
在这里插入图片描述
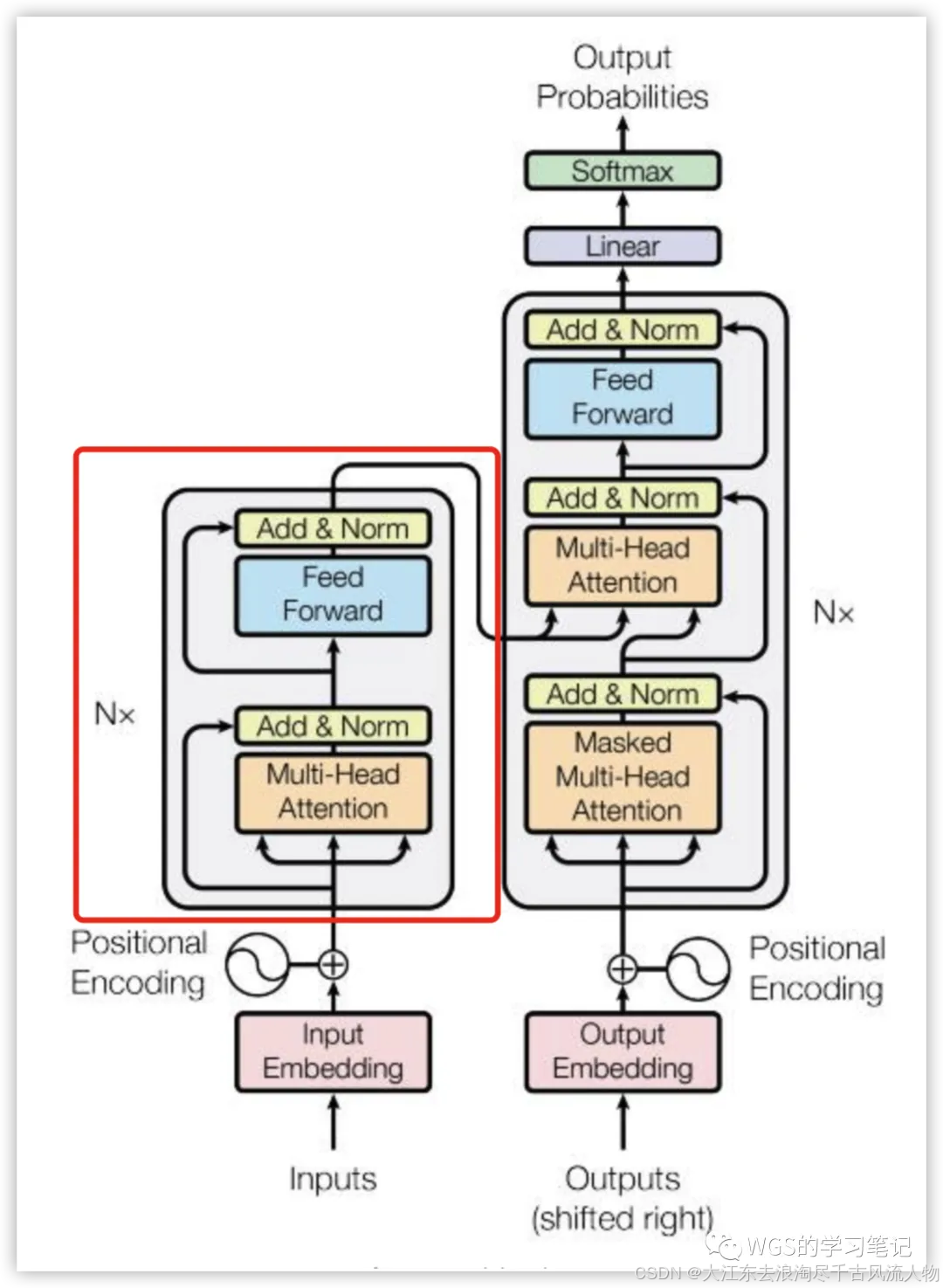
这是论文中的原图,可以看到左右两边都有乘N,左半部分就是encoders,右半部分就是decoders
自底向上看各部分为:
1.首先是encoder部分的输入和decoder部分的输入,经过Embedding;
2.其次是Positional Encoding(位置编码);
3.其次是Multi-Head Attention(多头注意力机制);
4.其次是Add&Norm(跳跃连接&LayerNorm);
5.其次是Feed Forward(前馈神经网络);
6.其次是输出层(Linear、Softmax)。
3.2 机器翻译工作流程举例
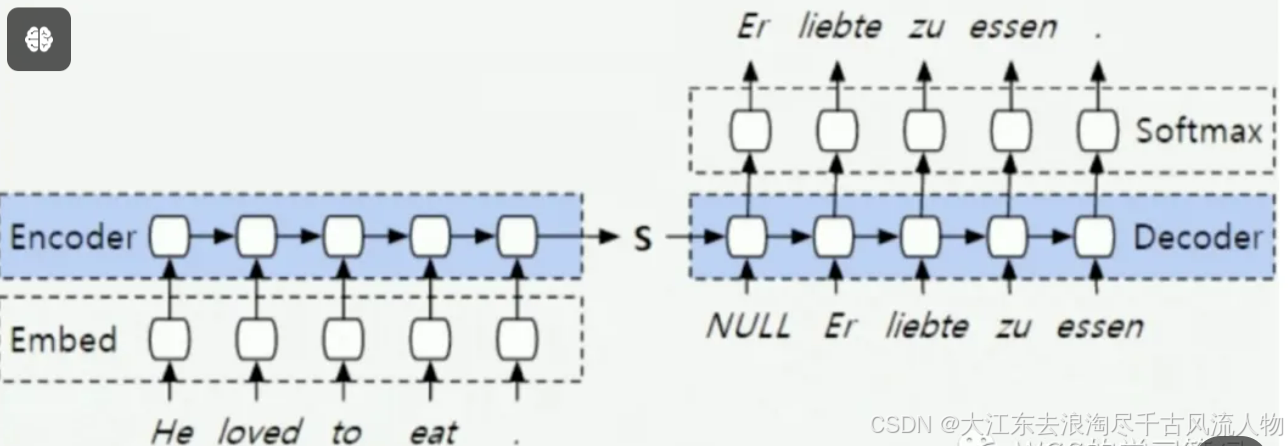
第一步:输入要翻译的英文,即encoder端的输入:“Why do we work?”;
第二步:经过encoder部分的运算后,将隐层输出到decoder端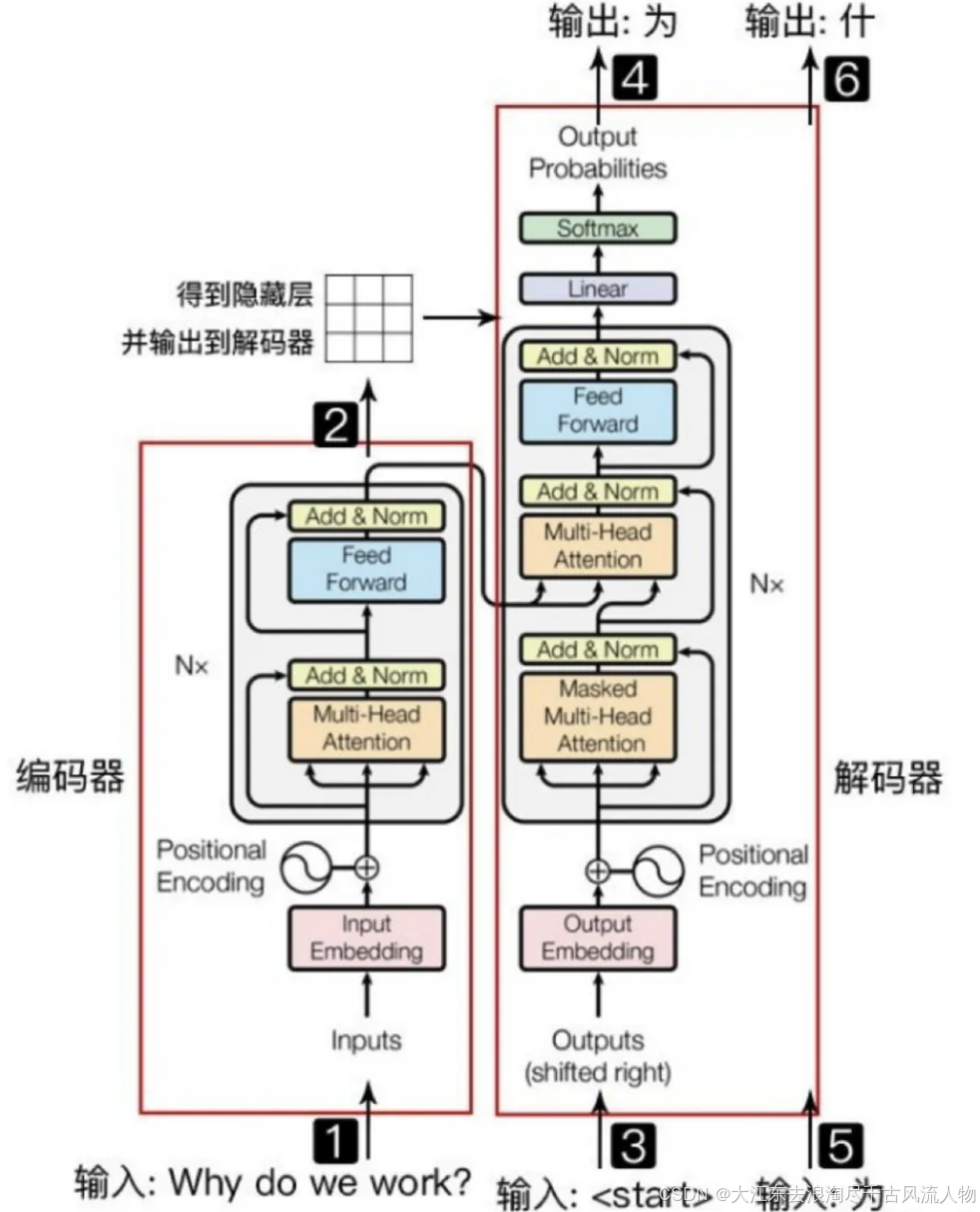
第三步:decoder部分输入,这里需要注意的是因为预测的时候是一个单词一个单词预测的,所以先输入的是起始符"start"
第四步:经过decoder部分的运算输出"为";
第五步:有了"为"之后,可以用"start 为"预测"什";
然后重复执行,直到遇到结束符表示预测结束。
下面参考博主 WSG 再以中英翻译为例举个例子帮助小伙伴们理解:
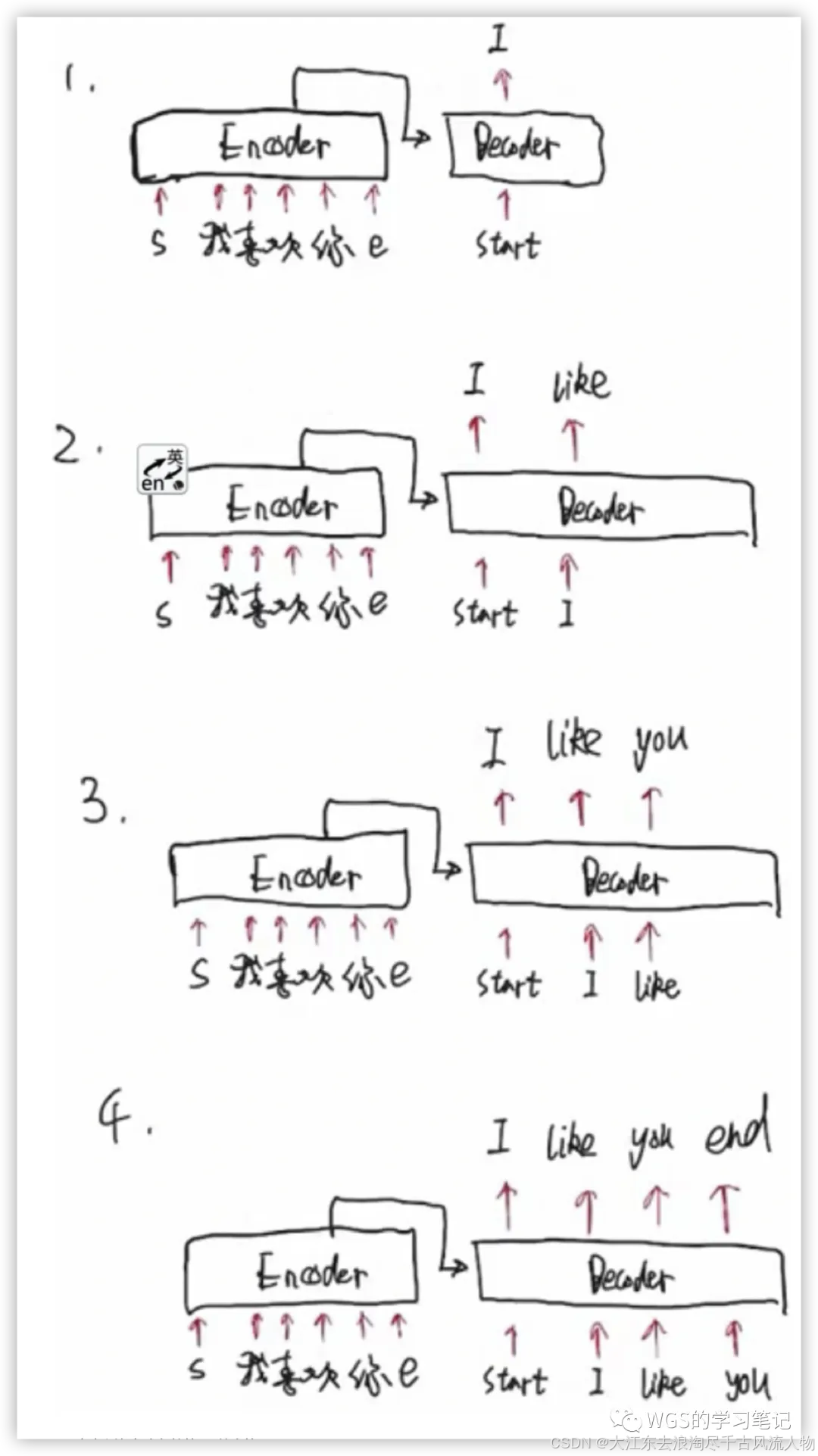
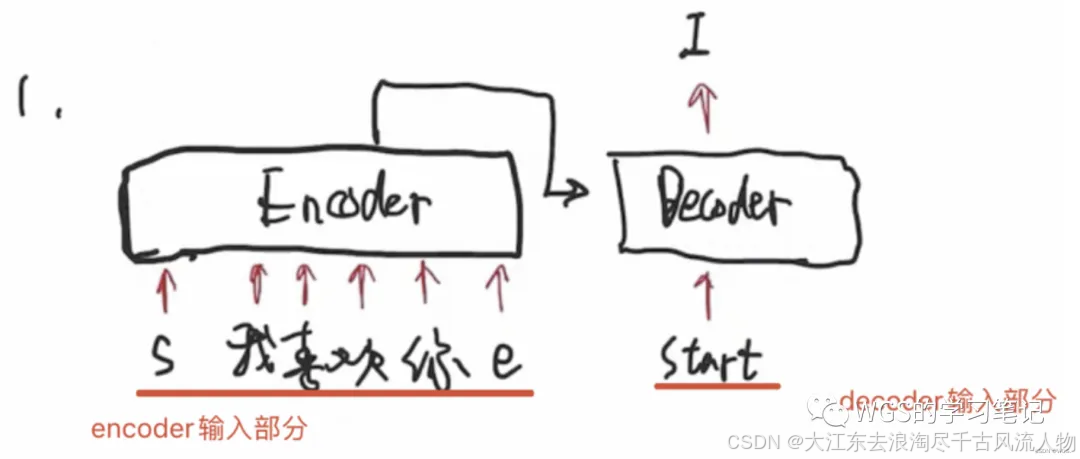
每句话都包含起始符s、结束符e
下面看下流程解释:
这句话输进来都会在encoder部分进行并行化运算,将encoder传过来的语义信息和decoder初始化的起始符,预测下一个要产生的单词是谁。比如输出"I"。
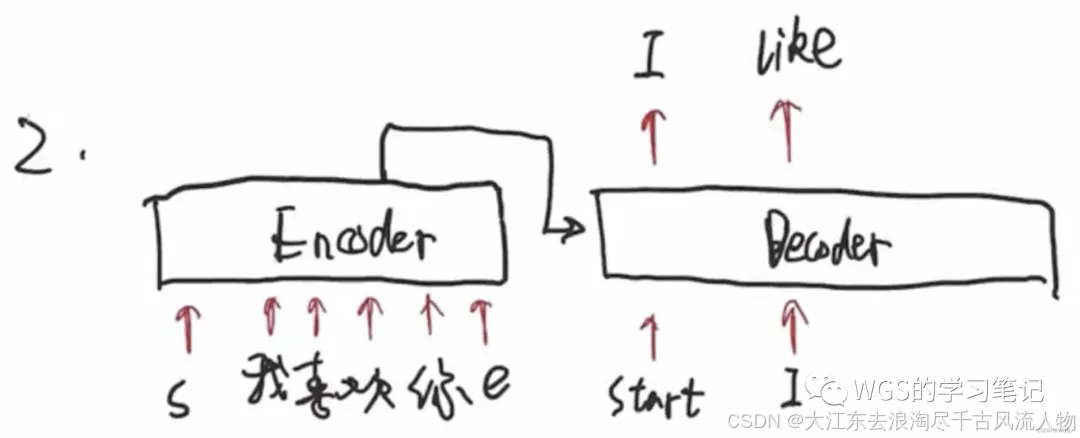
第2步的时候,decoder的输入就变成了两个,即它会拿上一步的输出,当做下一步的输入。用’start’和’I’预测出’like’。
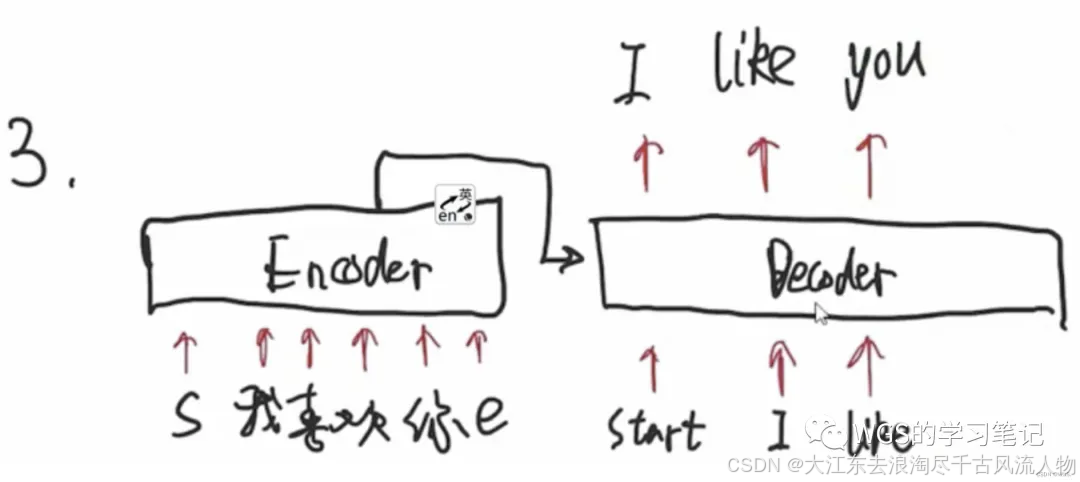
上一步的输出’like’变成了下一步的输入,也是先将I和like屏蔽掉,用start预测出I,用’start I’预测出like,在用’start I like’预测出you。
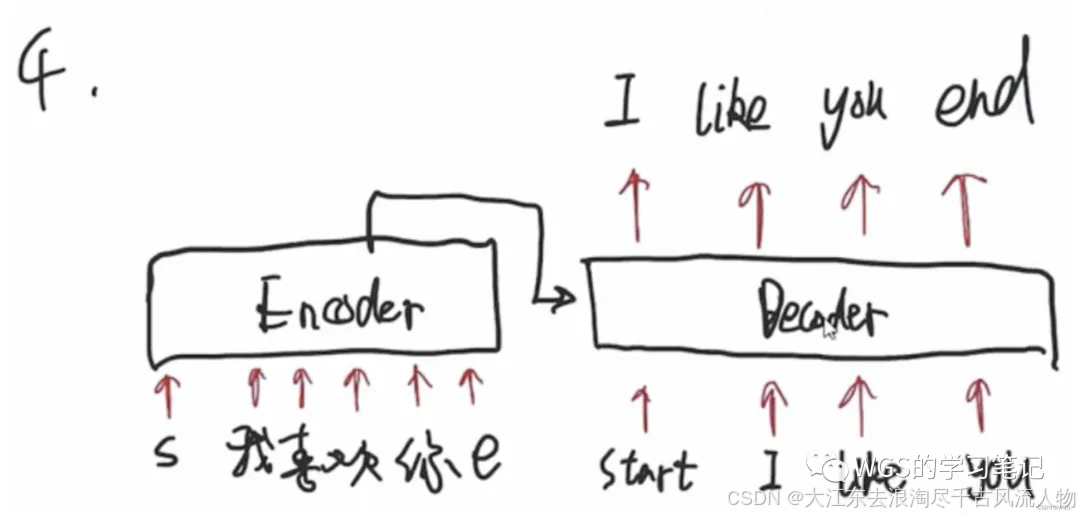
4. 输入部分&Embedding
在一个机器翻译场景中的数据预处理部分一般包括以下几个步骤:
1.将字符串转为数字编码;
2.按句子长度进行过滤;
3.添加起始符与结束符;
4.mini-batch、padding填充。
这里没什么好讲的,直接上示例代码
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import math
'''句子的输入部分:编码端的输入、解码端的输入、解码端的真实标签'''
# P指padding、S指起始符、E指结束符
sentences = [['我 喜 欢 你 P', 'S i like you', 'i like you E'],
['我 喜 欢 你 P', 'S i like you', 'i like you E'],
['我 喜 欢 你 P', 'S i like you', 'i like you E']]
'''构建词表,编码端和解码端可以共用一个词表,这里方便演示分开构建'''
# encoder端词表及词表大小
src_vocab = {'P': 0, '我': 1, '喜': 2, '欢': 3, '你': 4}
src_vocab_size = len(src_vocab)
# decoder端词表及词表大小
tgt_vocab = {'P': 0, 'i': 1, 'like': 2, 'you': 3, 'S': 4, 'E': 5}
tgt_vocab_size = len(tgt_vocab)
src_len = 5 # length of source
tgt_len = 4 # length of target
'''将单词与词表映射,这里可以理解为label编码'''
enc_inputs, dec_inputs, target_batch = make_batch(sentences)
print(enc_inputs)
print(dec_inputs)
print(target_batch)
tensor([[1, 2, 3, 4, 0],
[1, 2, 3, 4, 0],
[1, 2, 3, 4, 0]])
tensor([[4, 1, 2, 3],
[4, 1, 2, 3],
[4, 1, 2, 3]])
tensor([[1, 2, 3, 5],
[1, 2, 3, 5],
[1, 2, 3, 5]])
'''将单词与词表映射,这里可以理解为label编码,把单词序列转换为数字序列'''
def make_batch(sentences):
input_batch, output_batch, target_batch = [], [], []
for sentence in sentences:
input_batch.append([src_vocab[n] for n in sentence[0].split()])
output_batch.append([tgt_vocab[n] for n in sentence[1].split()])
target_batch.append([tgt_vocab[n] for n in sentence[2].split()])
return torch.LongTensor(input_batch), torch.LongTensor(output_batch), torch.LongTensor(target_batch)
这里简单的来说一下什么是embedding,用一个向量来表征一个单词或是一个句子,这就是embedding,解决了传统onehot离散化带来的稀疏性问题。embedding作为网络的第一层被输入。
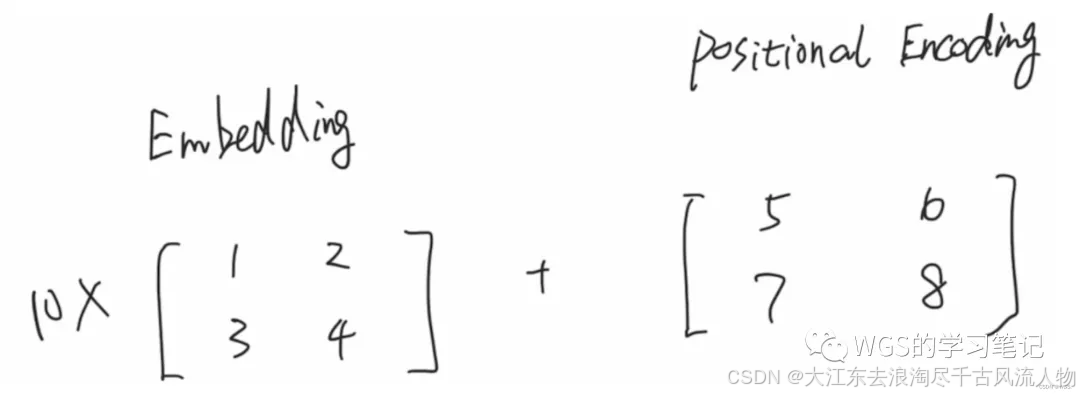
比如上述例子,“我喜欢你”,对这句话做一个512维的embedding,如下图:
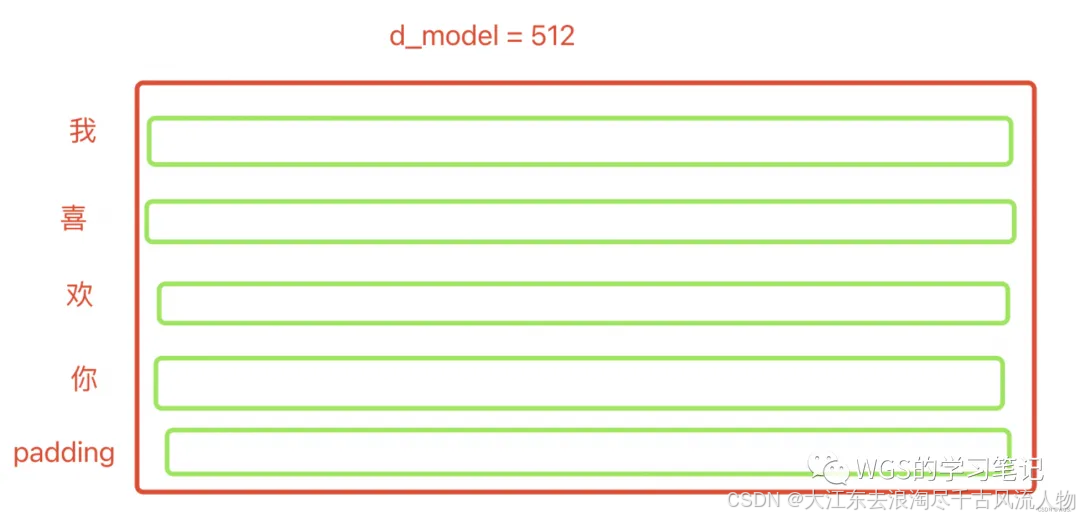
在forward里,我们需要知道emb后的维度为:[batch_size, src_len, d_model],上述例子中就是:[3, 5, 512]
# 其中src_vocab_size指词表大小,d_model为emb维度
self.src_emb = nn.Embedding(num_embeddings=src_vocab_size, embedding_dim=d_model)
enc_outputs = self.src_emb(enc_inputs)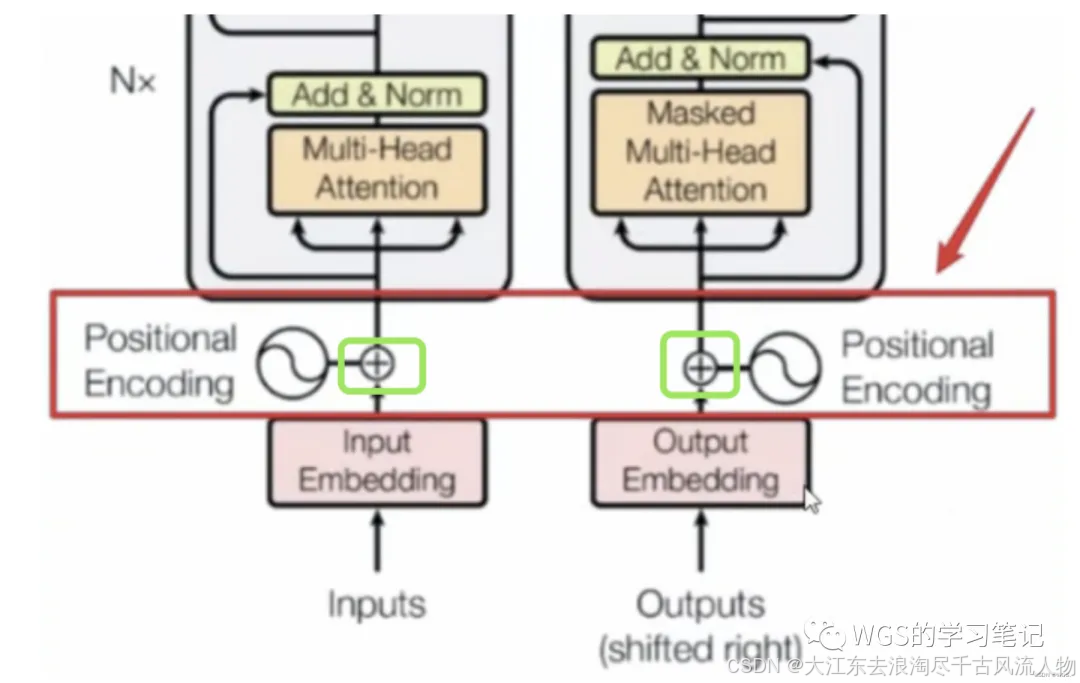
5、位置编码(Positional Encoding)
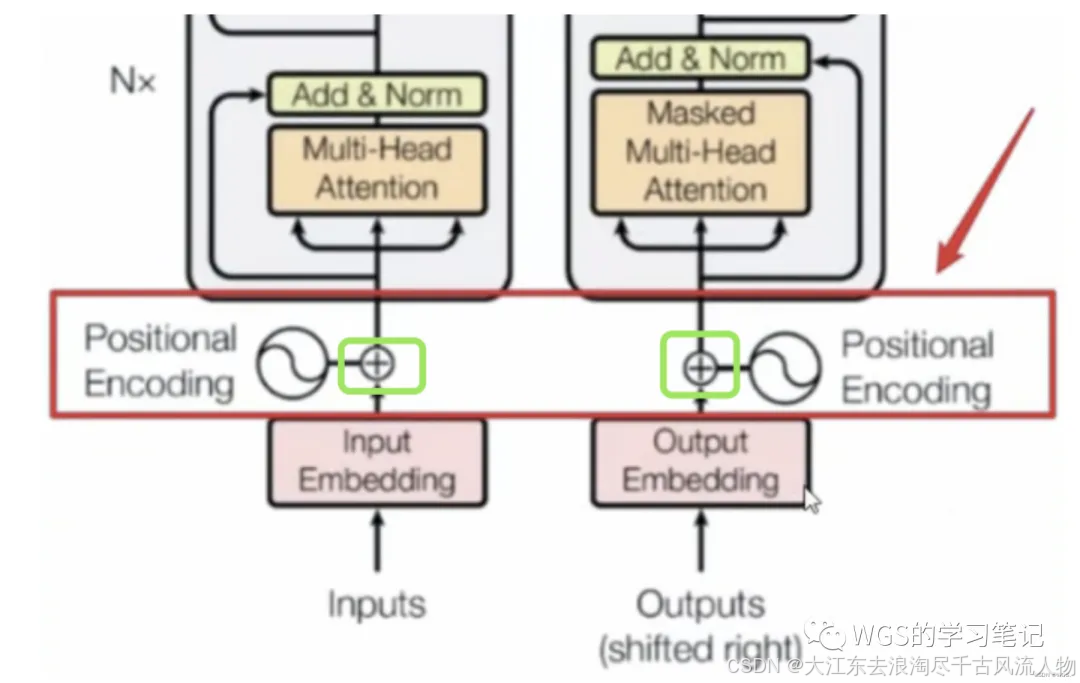
5.1 为什么要引入位置编码?
从图中我们发现,embedding后要加上位置编码,那么为什么要假如位置编码呢?
这就要引入并行化计算带来的问题,也就是传统RNN循环网络的特点:
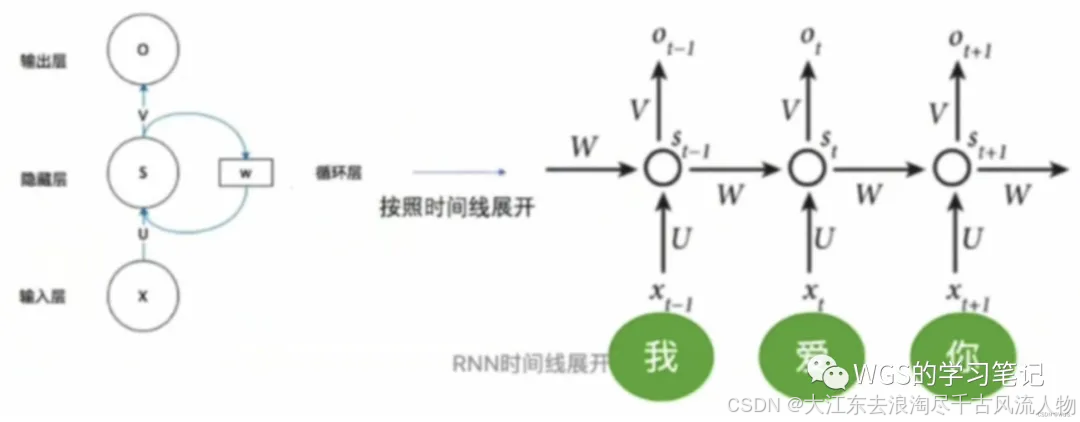
在本文的最开始也提到过,它是有前后依赖的语义关系的,在生成”爱“之前必须生成”我“,生成”爱“之后才能生成”你“。
具体的,由于句子中单词的序列关系,所以后一个timestep的输入必须等于前一个timestep的输出,它不具备并行处理的能力;
并且RNN中的每个timestep共享一套参数 U V W , 所以会出现梯度消失或梯度爆炸的问题;
相对于attention,它具有并行处理的能力,但并不具有位置信息显示的能力。
ps:这里插一个面试小问题,RNN的梯度消失有什么不同?连乘效应导致梯度消失放在RNN这里不是太准确,RNN的梯度是一个总的梯度和,它的梯度消失不单单是梯度和变为0,而是说总体的梯度被近距离梯度主导,被远距离梯度忽略不计,这才是RNN梯度消失的真正含义。
transformer因为有注意力所以是并行化的计算,所以语义位置信息就没有了,没有办法去理解”我 “在”爱“前面。
比如输入是”你礼貌吗“,如果将位置信息打乱,变成”礼貌你吗“的时候,因为模型没有位置信息所 以也就没办法识别语义,但是从人的⻆度理解这是完全不同的两句话。所以就有了位置编码,解决方案:引入绝对位置信息和相对位置信息。
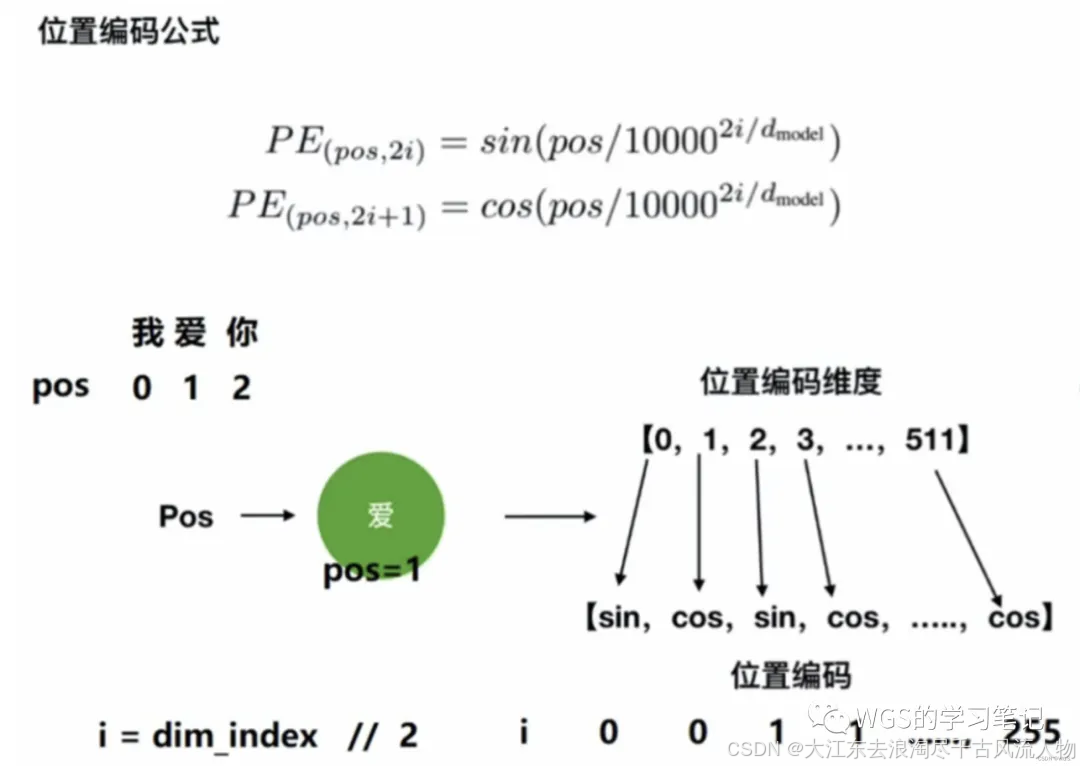
上图就是偶数位置使用 sin 函数,奇数位置使用 cos 函数。
根据位置编码公式,可以将emb向量的每个值来区分开来,也可以将每句话来区分开来,比如告诉模型 ”我“ 是在 “喜” 之前的。
将位置编码后的向量和embedding进行对位相加,作为整个transformer的输入
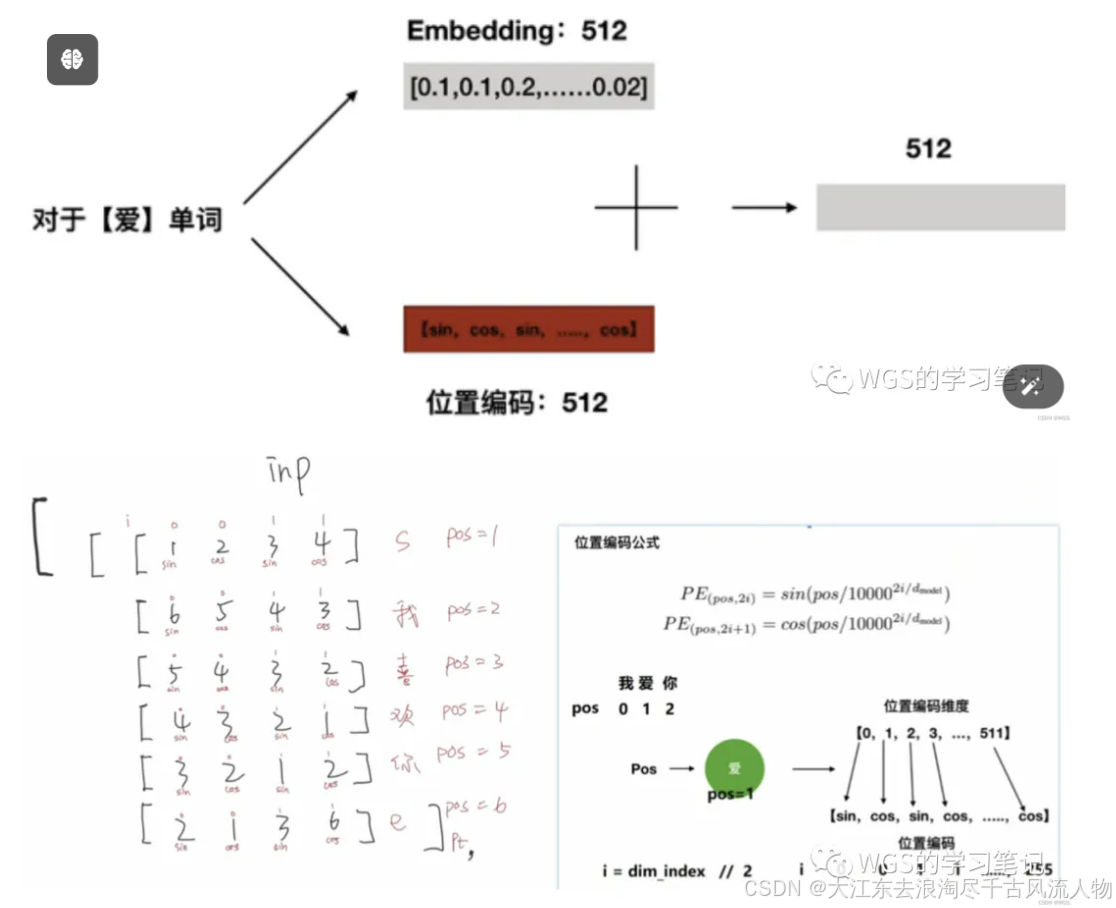
pos指的就是这句话的每个位置,比如起始符s的pos就是1,“我”的pos就是2,也可以认为是这个向量的顺序。
2i代表偶数位置,2i+1代表奇数位置。
i=emb向量的下标对2求模,如图所示假如有512维的emb向量,当emb向量索引为0的位置时,它的i就是,同理1的位置是,以此类推…
d_model指的是emb向量的维度,也是个定值。
所以根据公式,就能计算出emb向量的位置编码张量。
观察可以发现: 位置编码跟句子⻓度seq_len有关,它由pos决定,句子有多⻓就决定了pos从多少到多少;其次还和emb向量的维度有关。一旦这两个确定了,那么位置编码就根据公式唯一的确定了。它跟emb向量内的值没有关系。只和 seq_len 和d_model有关系。
总结来说,当d_model和seq_length确定,位置编码即可确定。
引入位置编码的同时,也引入了绝对位置信息与相对位置信息。
5.2 绝对位置如何体现?
如下图:
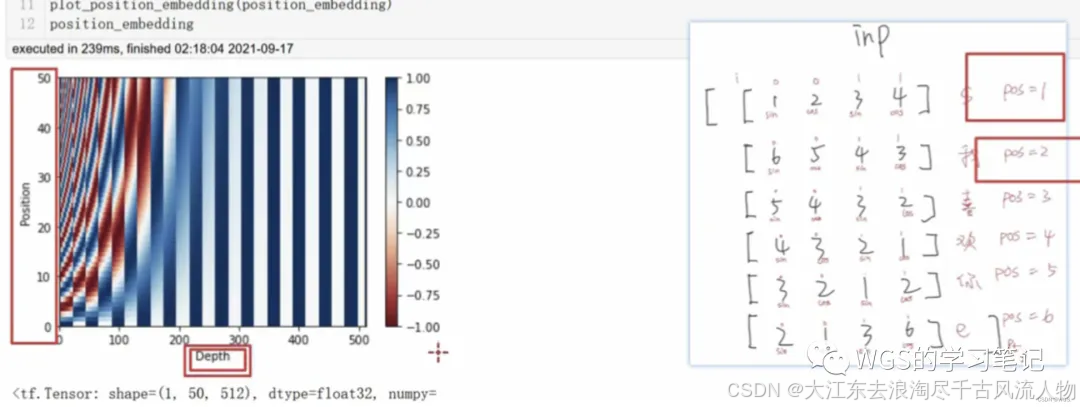
def plot_position_embedding(position_embedding):
# 绘制位置编码
plt.pcolormesh(position_embedding[0],cmap='RdBu') # 【50*512】
plt.xlabel('Depth')
plt.xlim((0,512))
plt.ylabel('Position')
plt.colorbar()
plt.show()
position_embedding = positional_encoding(50,512)
plot_position_embedding(position_embedding)
position_embedding
d_model=512,seq_length=50;
纵坐标就是pos,横坐标就是emb的维度;
右侧颜色的深浅就是代表数值的大小;
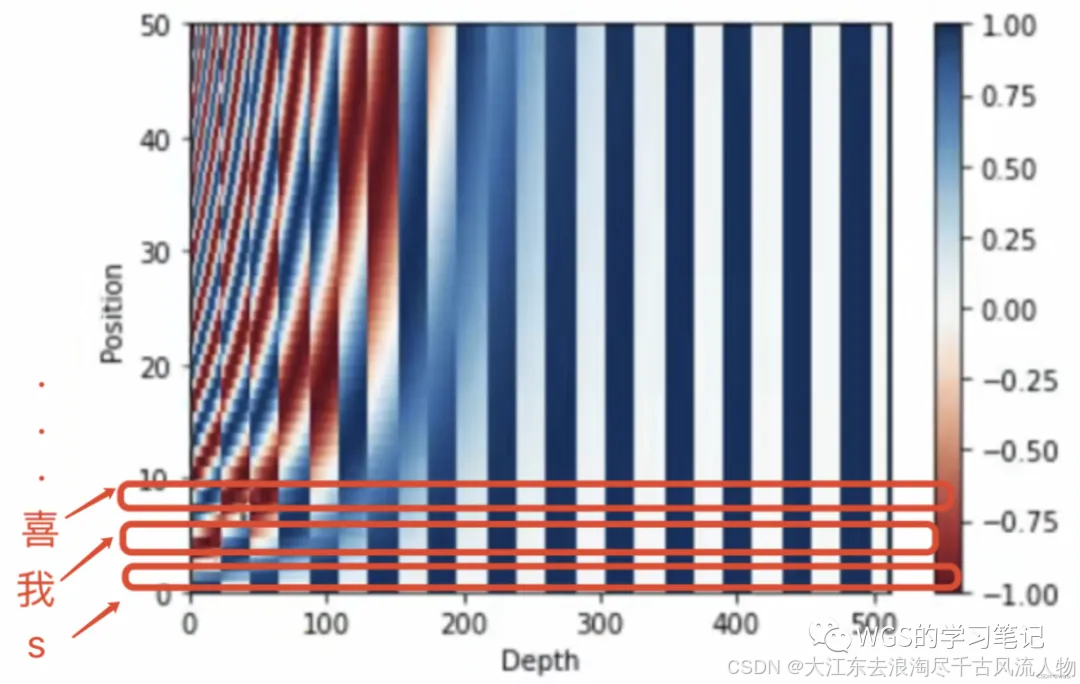
可以这样认为,从下往上看:
第一个横条是“起始符”这个向量的位置编码;
第二个是“我”这个向量的位置编码;
第三个是“喜”这个向量的位置编码…;
我们可以看到每个向量是独一无二的,那么这个就是一个绝对位置信息;因为它是唯一标识的,每个词的位置编码向量都是独一无二的。仔细观 察这些条纹还有周期性变化的规律。
5.3 相对位置如何体现?
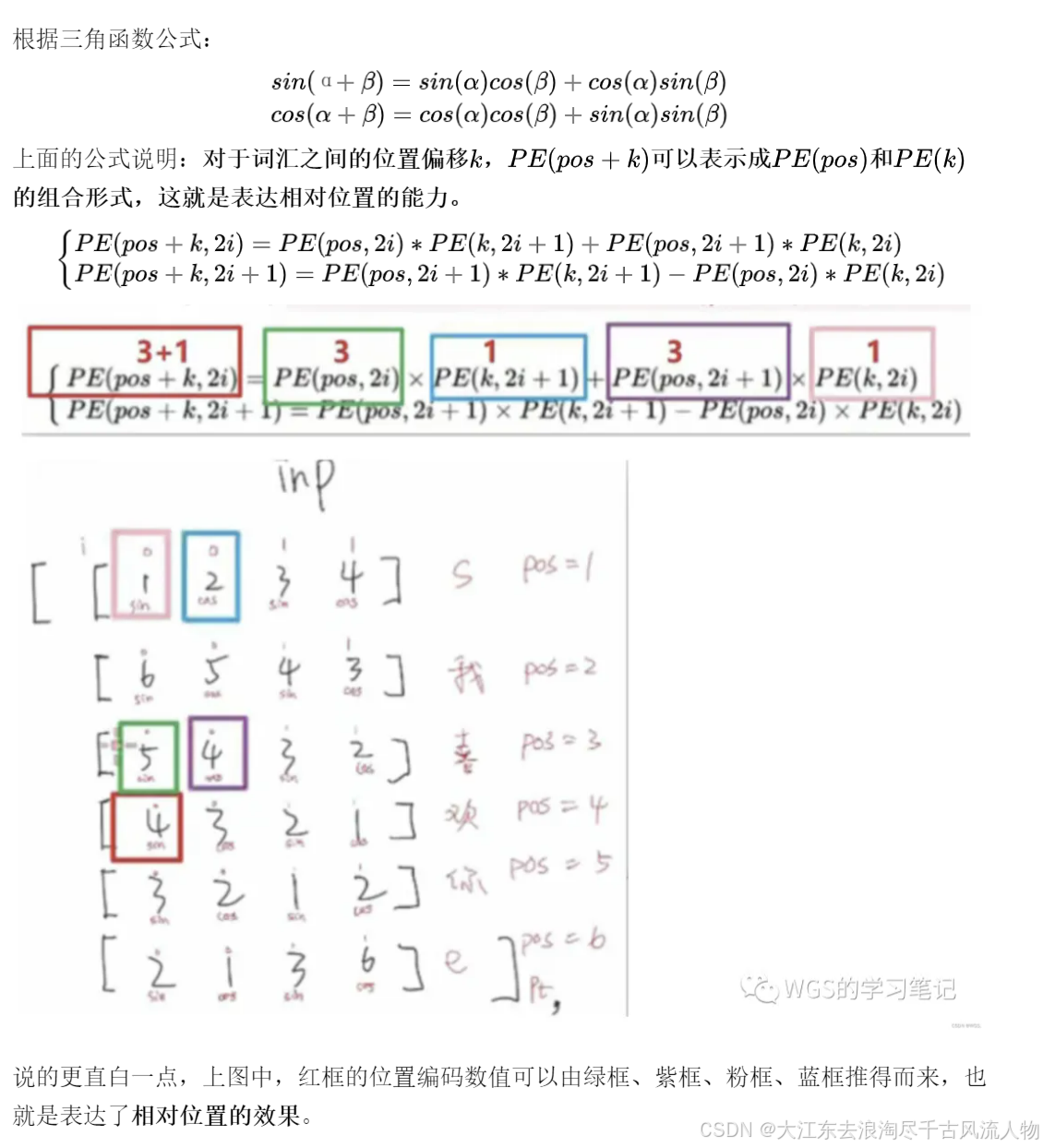
ps:这里有一个小trick,就是在位置编码之前加一个缩放:当emb和位置编码相加了之后,我们希望emb占多数,比如将emb放大10倍,那么在相加后的张 量里,emb就会占大部分。因为主要的语义信息是蕴含在emb当中的,我们希望位置编码带来的影响不要超过emb。所以对 emb进行了缩放再和位置编码相加。
5.4 位置编码代码示例

''' 3. PositionalEncoding 代码实现 '''
class PositionalEncoding(nn.Module):
'''
位置编码的实现其实很简单,直接对照着公式去敲代码就可以,下面这个代码只是其中一种实现方式;
从理解来讲,需要注意的就是偶数和奇数在公式上有一个共同部分,我们使用log函数把次方拿下来,方便计算;
pos代表的是单词在句子中的索引,这点需要注意;比如max_len是128个,那么索引就是从0,1,2,...,127
假设我的d_model是512,2i那个符号中i从0取到了255,那么2i对应取值就是0,2,4...510
'''
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
# 生成0~max_len-1的索引位置张量,[max_len] -> [max_len, 1]
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# 这里需要注意的是pe[:, 0::2]这个用法,就是从0开始到最后面,步长为2,其实代表的就是偶数位置
pe[:, 0::2] = torch.sin(position * div_term)
# 这里需要注意的是pe[:, 1::2]这个用法,就是从1开始到最后面,步长为2,其实代表的就是奇数位置
pe[:, 1::2] = torch.cos(position * div_term)
# 上面代码获取之后得到的pe:[max_len * d_model]
# 下面这个代码之后,我们得到的pe形状是:[max_len * 1 * d_model]
pe = pe.unsqueeze(0).transpose(0, 1)
# 定一个缓冲区,其实简单理解为这个参数不更新就可以
self.register_buffer('pe', pe)
def forward(self, x):
"""
x: [seq_len, batch_size, d_model]
"""
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
6、Encoder部分
Encoder部分输入是单词的Embedding,再加上位置编码,然后进入一个统一的结构,这个结构可以循环很多次(N次),也就是说有很多层(N层)。每一层又可以分成Attention层和全连接层,再额外加了一些处理,比如Skip Connection,做跳跃连接,然后还加了Normalization层。其实它本身的模型还是很简单的。
6.1 多头注意力机制(Multi-Head Attention)
关于Attention部分(Attention、Self-Attention、Multi-Head Attention)这里不再详细讲解,直接已经讲过了,没看过的同学可以看下:
6.1.1 理解self-attention
- 没有self-attention的情况下,每个词只表示自身的含义,不包含语义信息。
- 含有self-attention,对词向量进行重构,使得词向量不单只包含自己,而是综合考虑全局,融入上下文。
这里只是对于Attention的举例简述,如果没看懂的同学可以去上面的链接详细的了解Attention
我们这里以三个向量举例理解Attention:


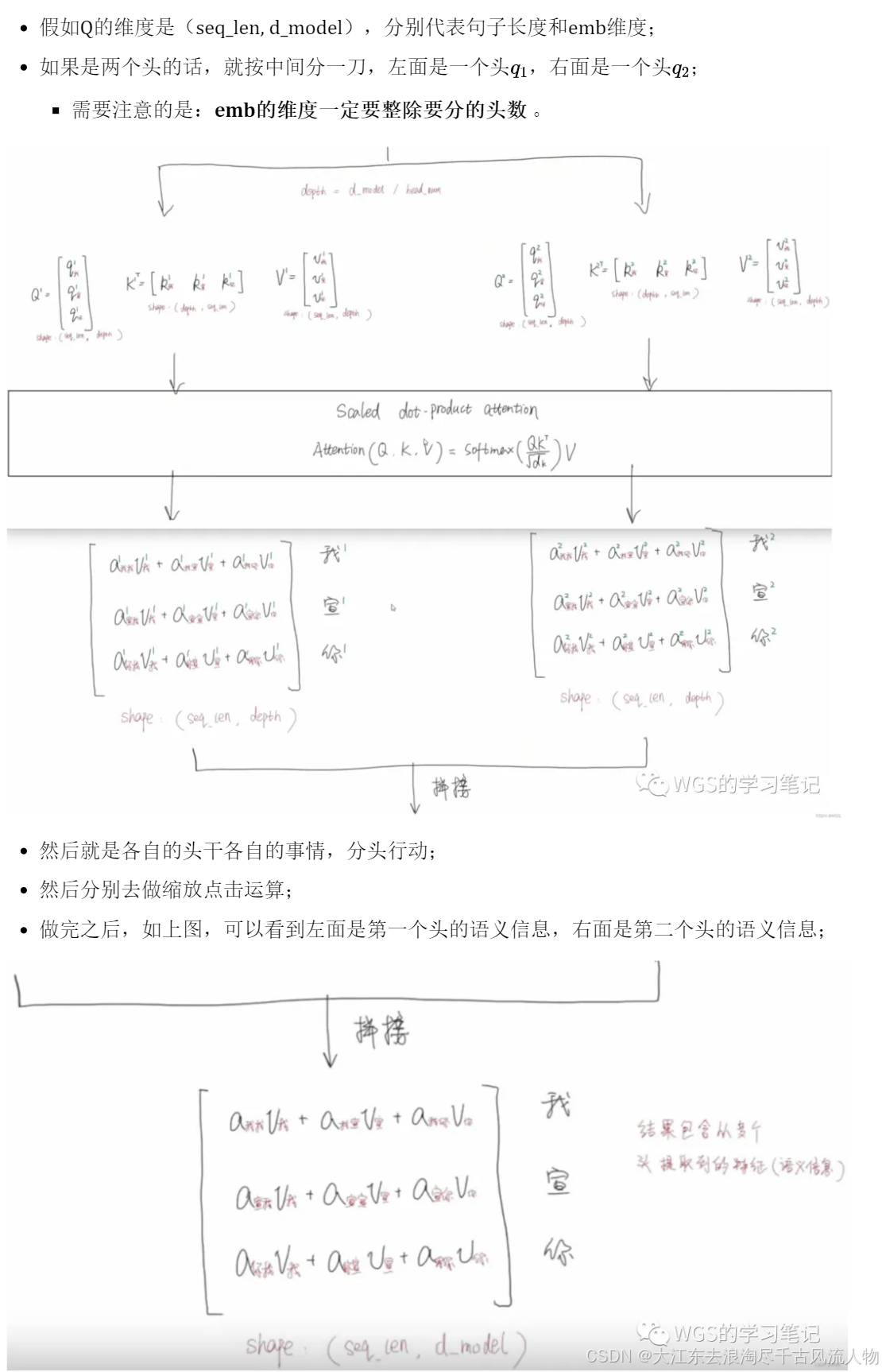
6.1.2 scaled dot-product attention 缩放点积注意力
公式如下:

6.1.3 前向传播角度理解为什么要除以
首先我们要明白的一点是:softmax是一种非常明显的⻢太效应 强者越强,弱者越弱。
而缩放后,注意力值就分散些,这样就可以获得更好的泛化能力;
举个例子:

为什么非要将均值和方差拉到0和1呢?
这是ICS内部协变量偏移问题:
机器学习都有一个前提假设那就是数据符合标准正态分布的,
那么样本经过emb之后,也是符合正太分布的,
q、k的线性变换也是符合正太分布的。
当到qk的时候,就发生了变化,因为点积的操作分布就不再是标准正态分布了,也会影响后续所有数据的分布。
所以我们现在的问题是:


6.1.4 反向传播角度理解为什么要除以

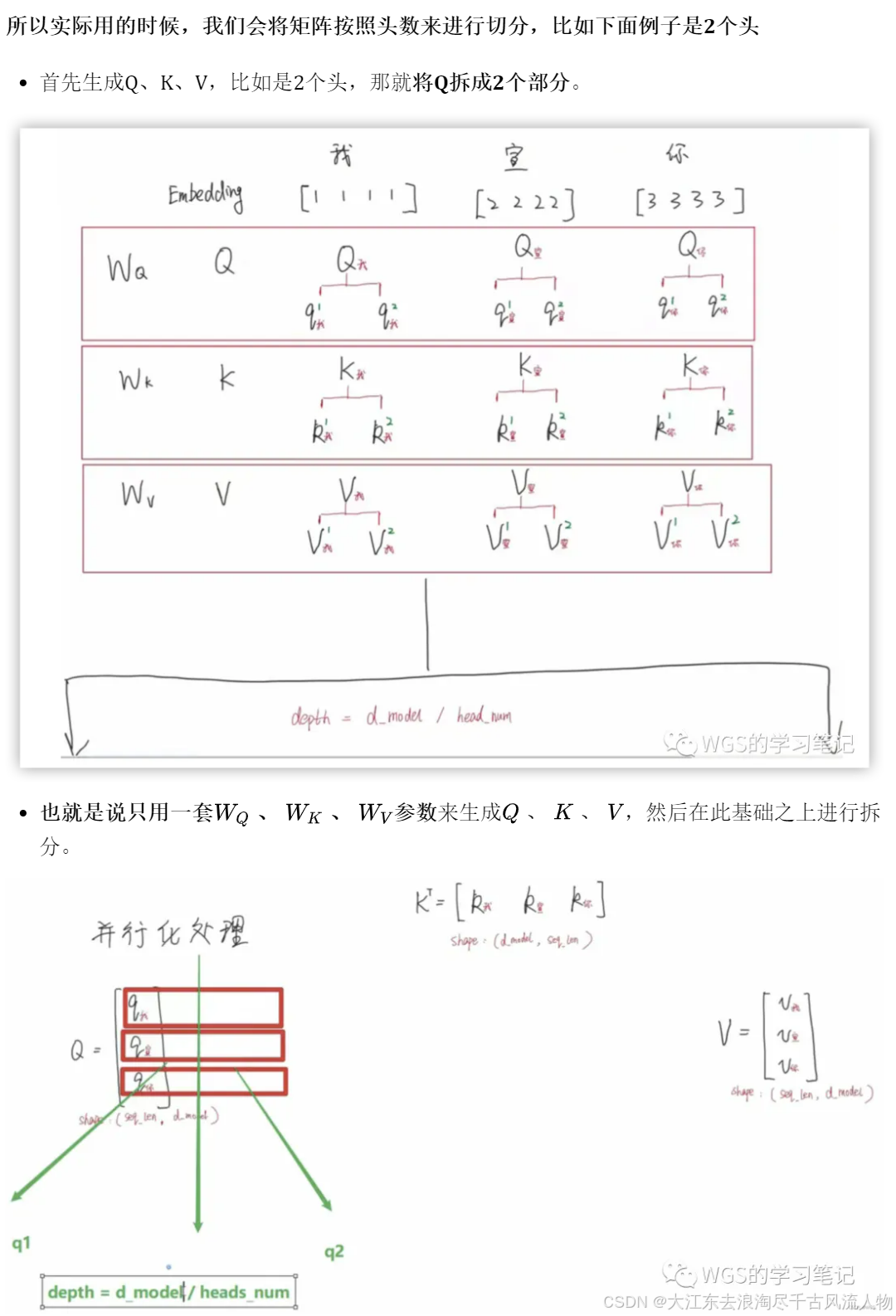
6.1.5 并行化处理(矩阵运算)
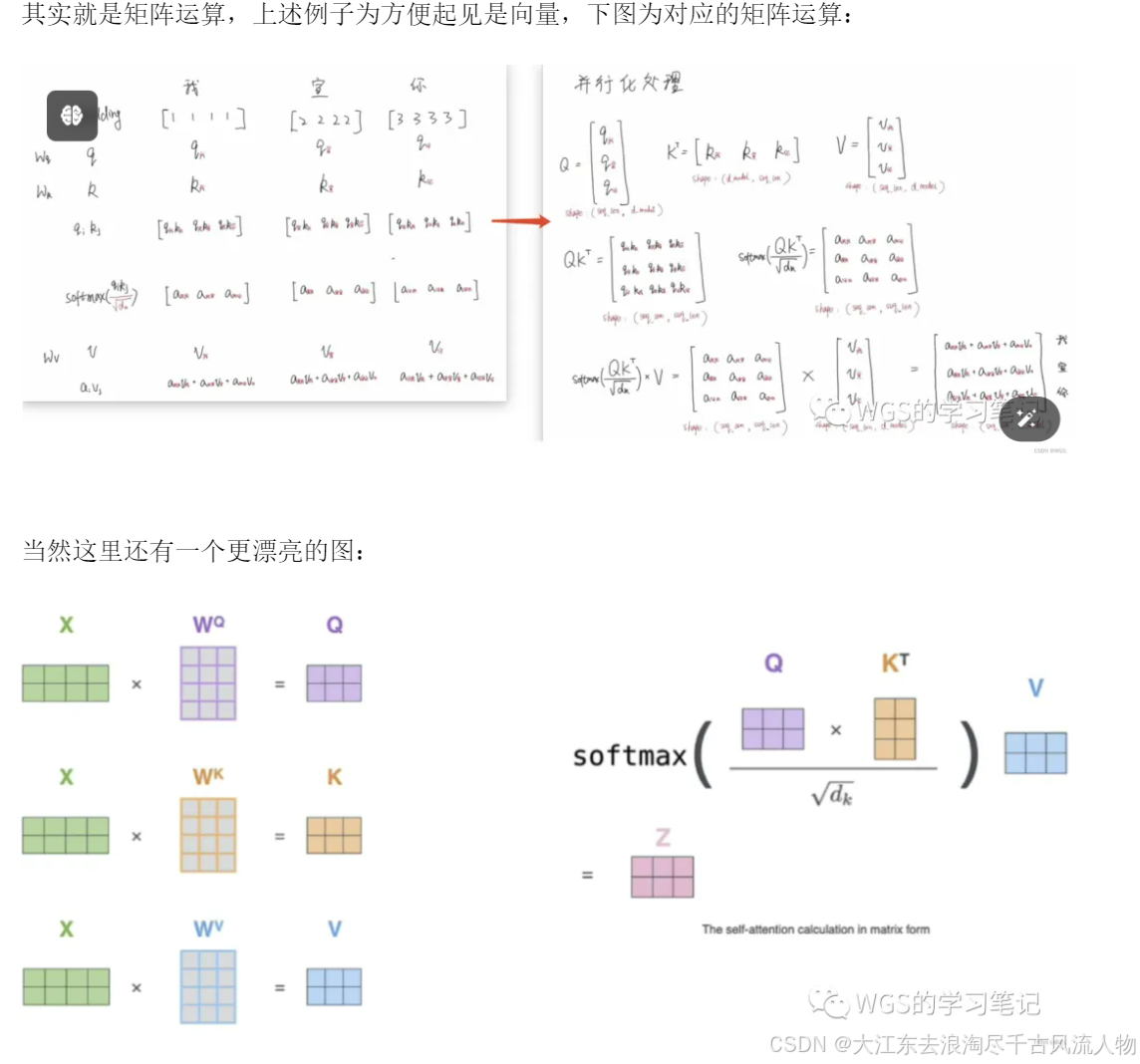
6.1.6 多头 Multi-head
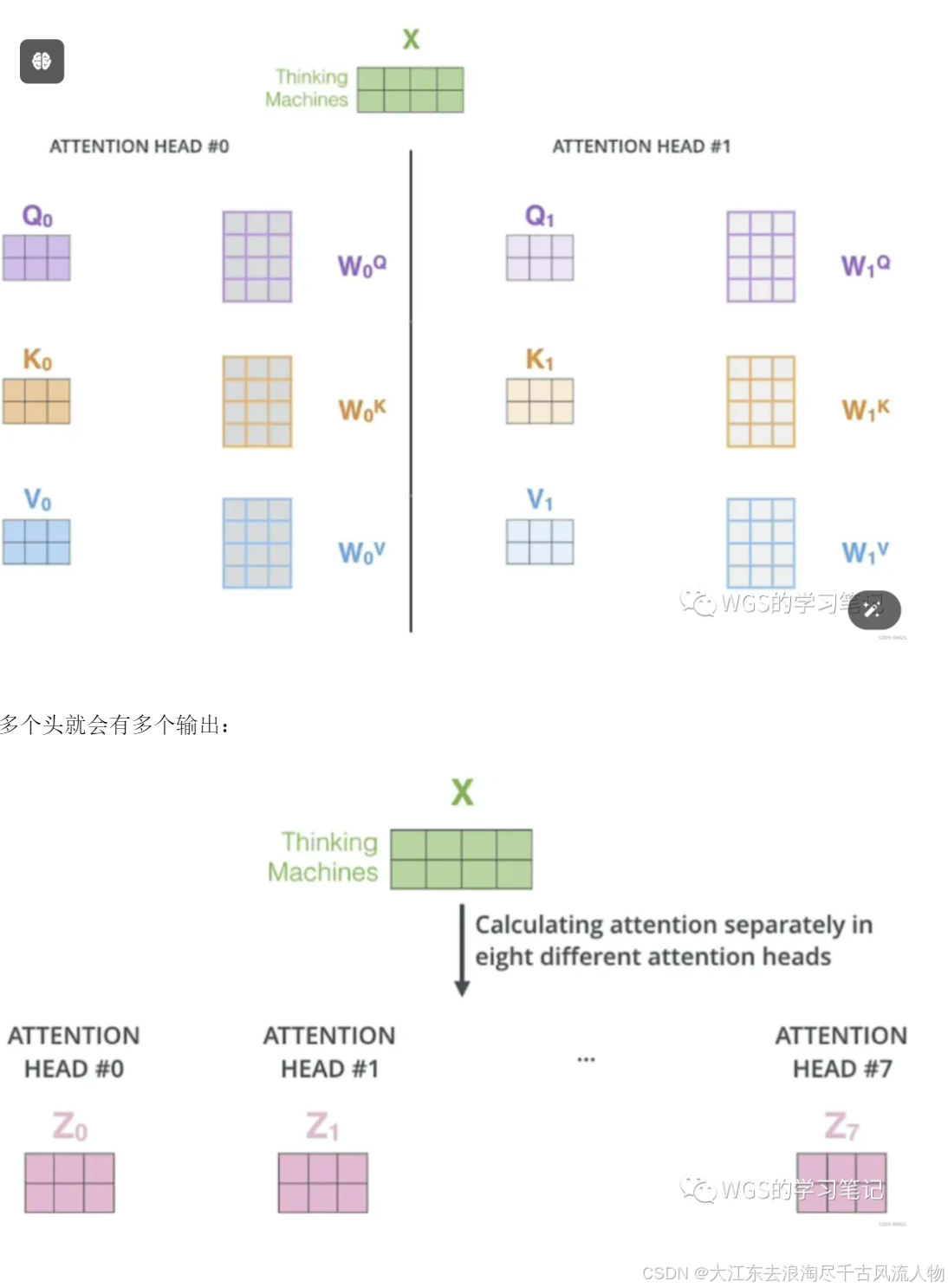
将上面的self-attention弄懂了,多头也就懂一大半了,而encoder和decoder部分是一样的,论文的名字也是attention is all you need,attention就是精华。
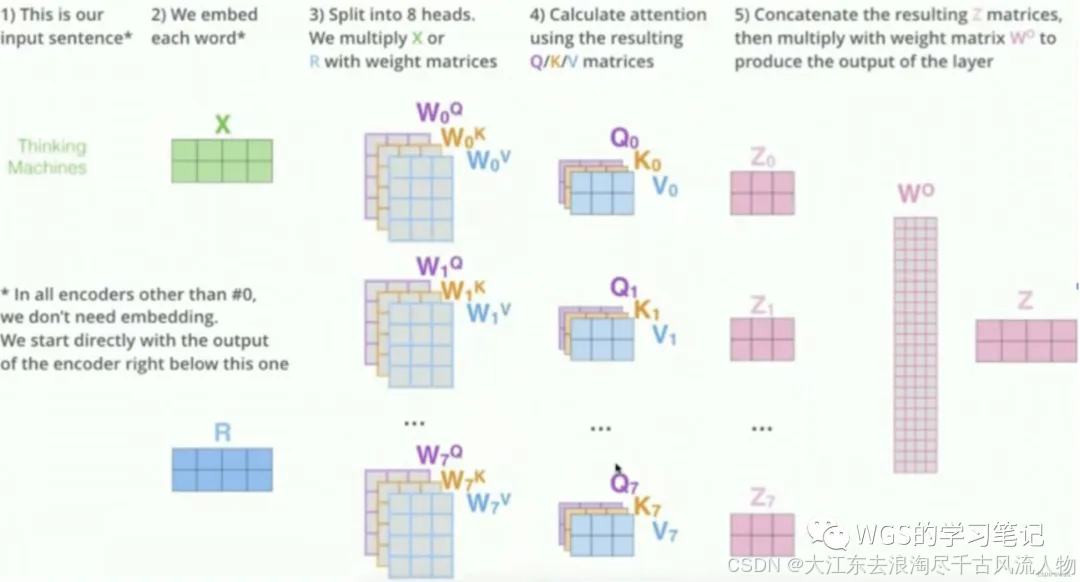
理论上,多头指的就是多套Q、K、V。比如论文原文是8个头,那就是8套Q、K、V。
多套参数相当于把原始信息放到了多个空间中,也就是捕捉了多个信息,多头保证了transformer可以注意到不同子空间的信息,能够捕捉到更加丰富的特征信息。
换句话说就是经过注意力之后的矩阵会有自己理解的语义信息,那所以最后8个Z就会有8个不同的理解。
图片
多个头就会有多个输出:
多头信息输出,由于多套参数得到了多个信息,然而我们还是只需要一个信息,因此可以通过某种方法(例如矩阵相乘)把多个信息汇总为一个信息:
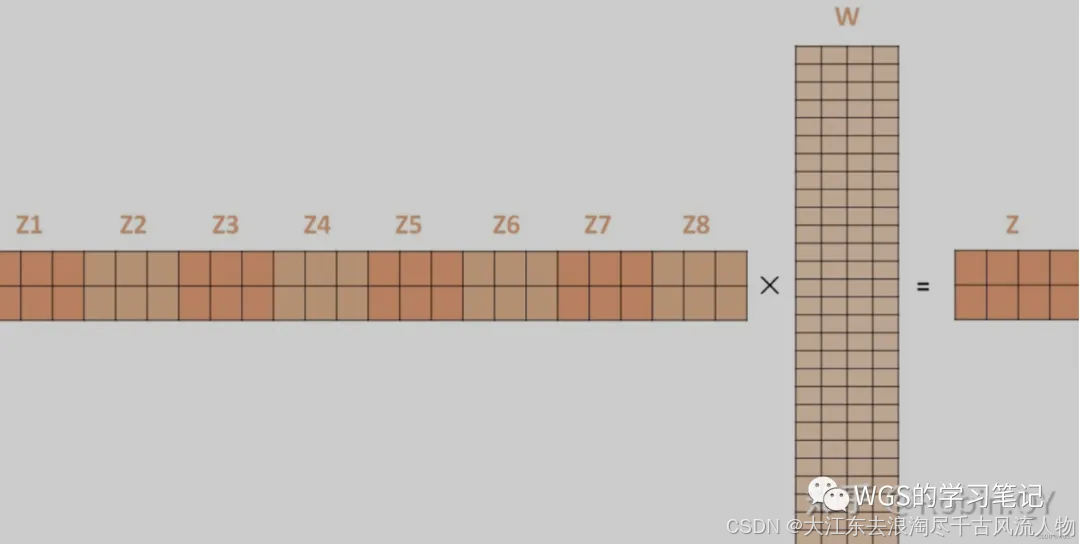
看过源码的小伙伴会发现实际上我们并不会这么干
将多个头的结果拼接起来,还原到之前的维度;
这样就相当于从多个头当中提取到的特征都给融合到了一起。

6.1.7 为什么要使用多头注意力?
前面也简单的提到了一点,这里总结下,加深理解:
- 多头保证了transformer可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。
- 论文作者发现这样做效果缺失好。
- 捕捉到特征的多样性,说人话就是”因为有多头,所以可以从多个⻆度去理解内容“。举个例子来理解的话:
学姐查寝
它可以理解为:学姐-查寝
也可以理解为:学-姐-查寝
通过多头注意力可以充分的解读上下文的语义信息,换句话说就是充分的带入到一个场景中去做理解。
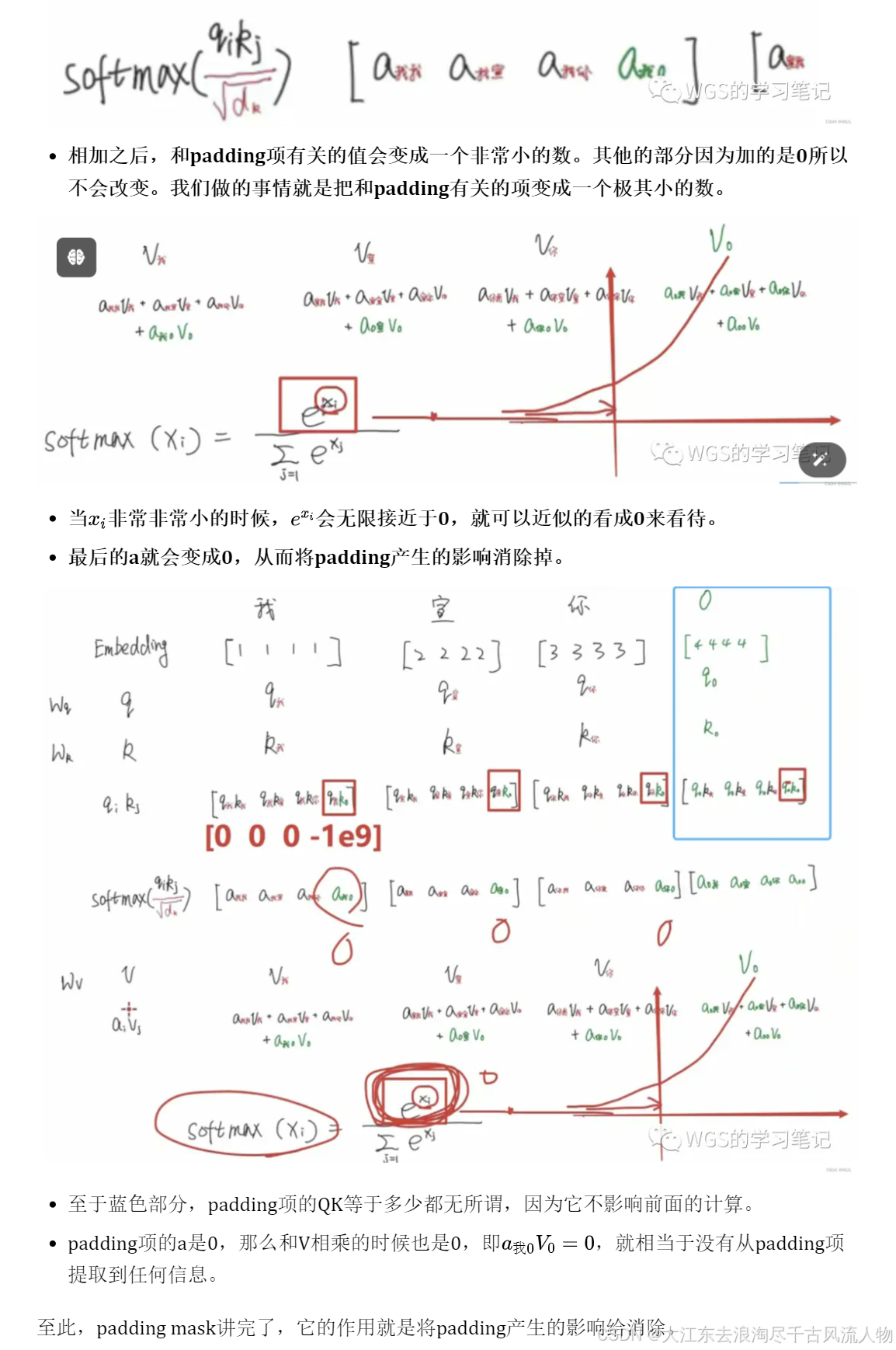
6.1.8 Padding mask
简单说padding mask的作用就是标记padding项的位置。
目的是消除padding项带来的影响。
我们先回到上面attention的例子中,在最后加了padding项,看会有怎样的影响:

绿色部分就是和padding相关的

比如上图,它会认为”我“和padding存在某种联系,这是不合理的。因为padding本身就是没有意义的, 只是我们的填充项而已。
所以要将这些部分变成0。
所以往上走就要在QK相乘的地方就要把有padding的变成0,即在softmax运算之前就要把含padding的给处理掉。


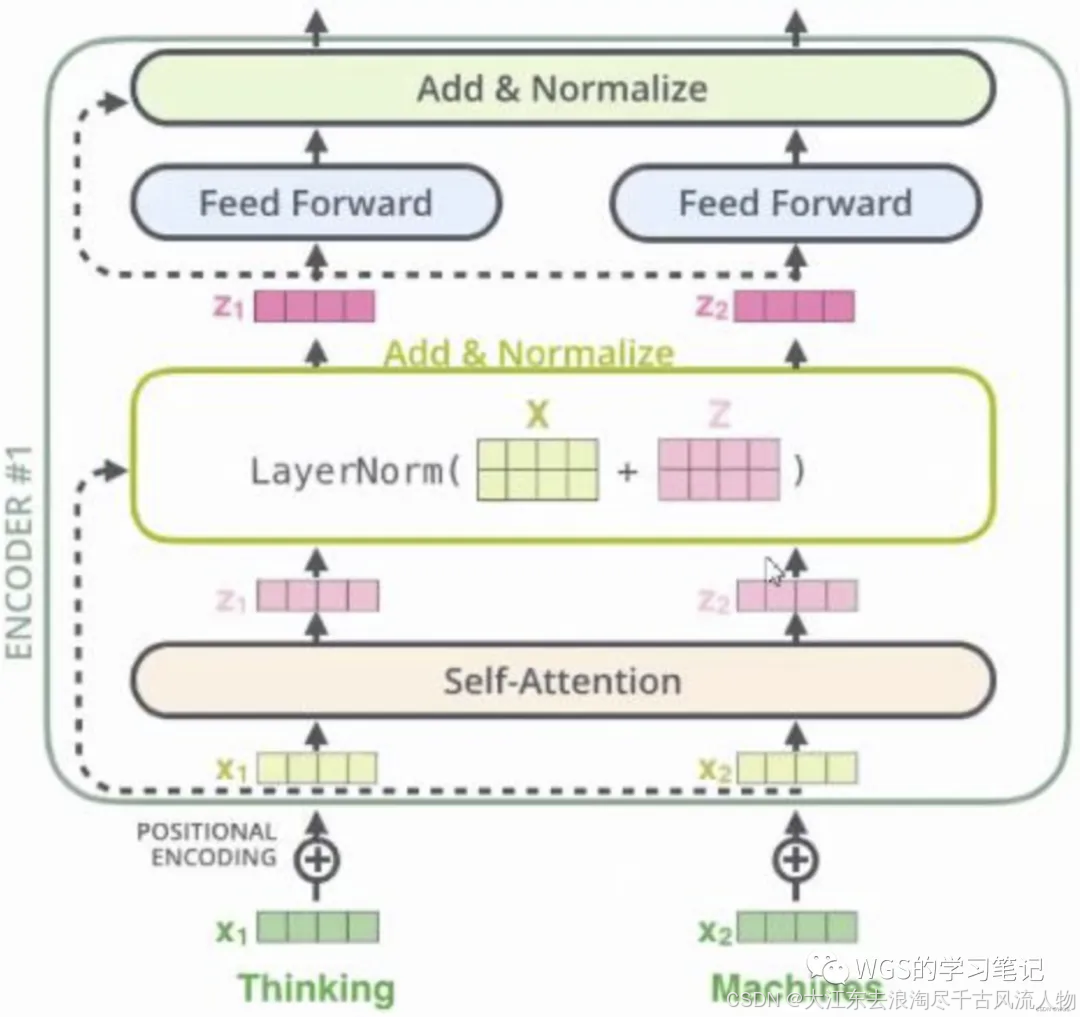
6.2 Add&Norm
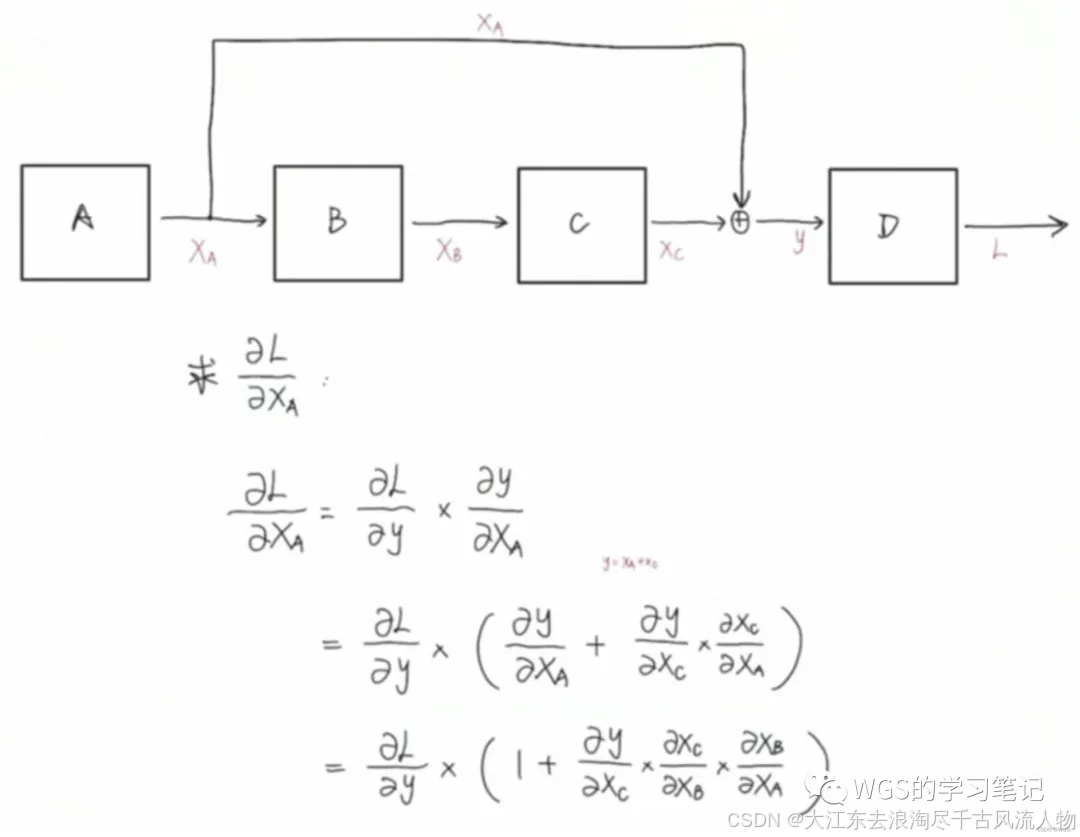
6.2.1 Add(Skip Connection)
Add部分没什么好讲的,就是残差网络的跳跃连接思想。
作用就是加深网络层数,通过跳跃连接缓解梯度消失。
6.2.3 什么是LayerNorm?
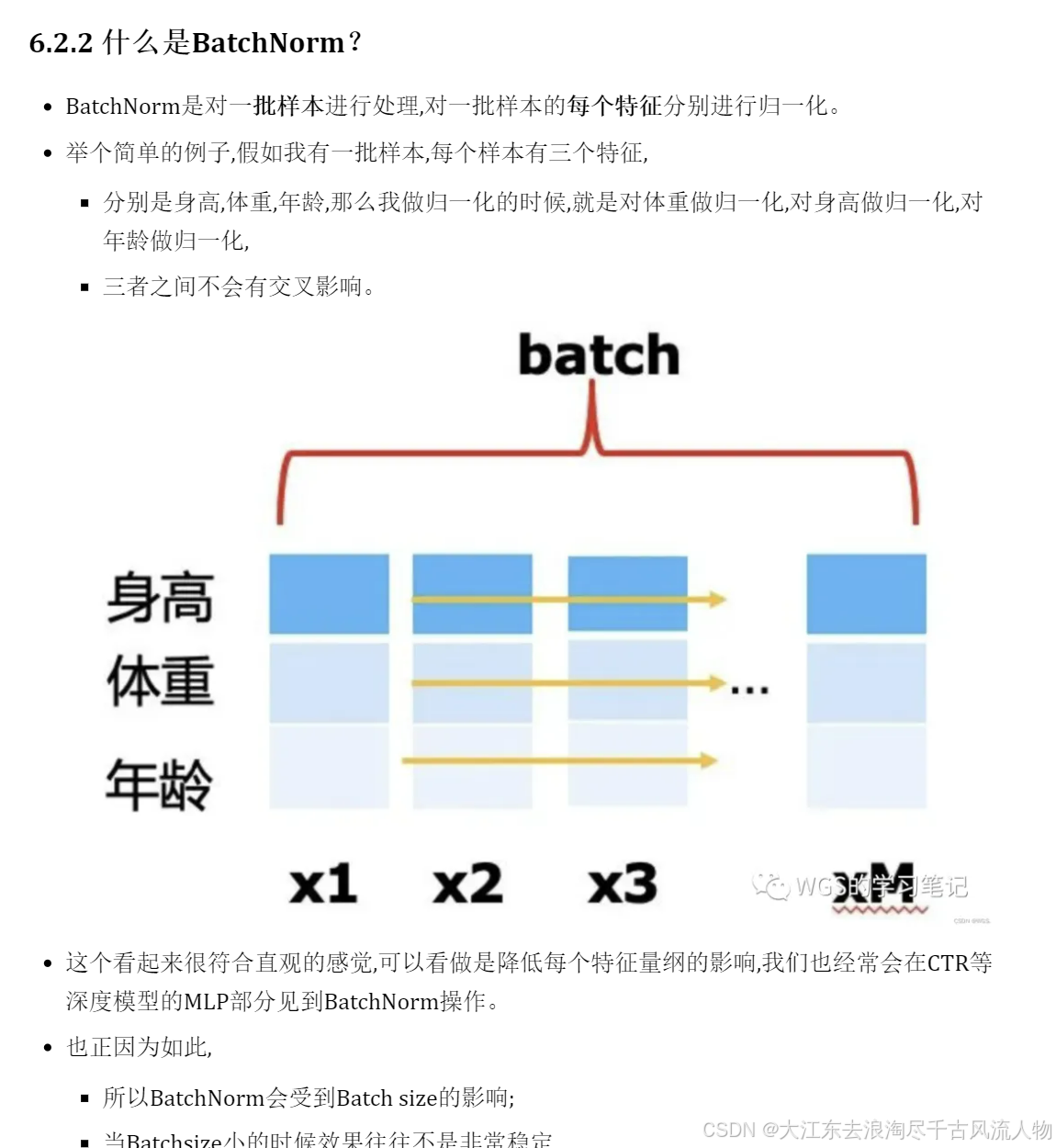
LayerNorm是对一个样本进行处理,
对一个样本的所有特征进行归一化,乍一看很没有道理,
因为如果对身高体重和年龄一起求一个均值方差,都不知道这些值有什么含义,但存在一些场景却非常有效果–NLP领域。
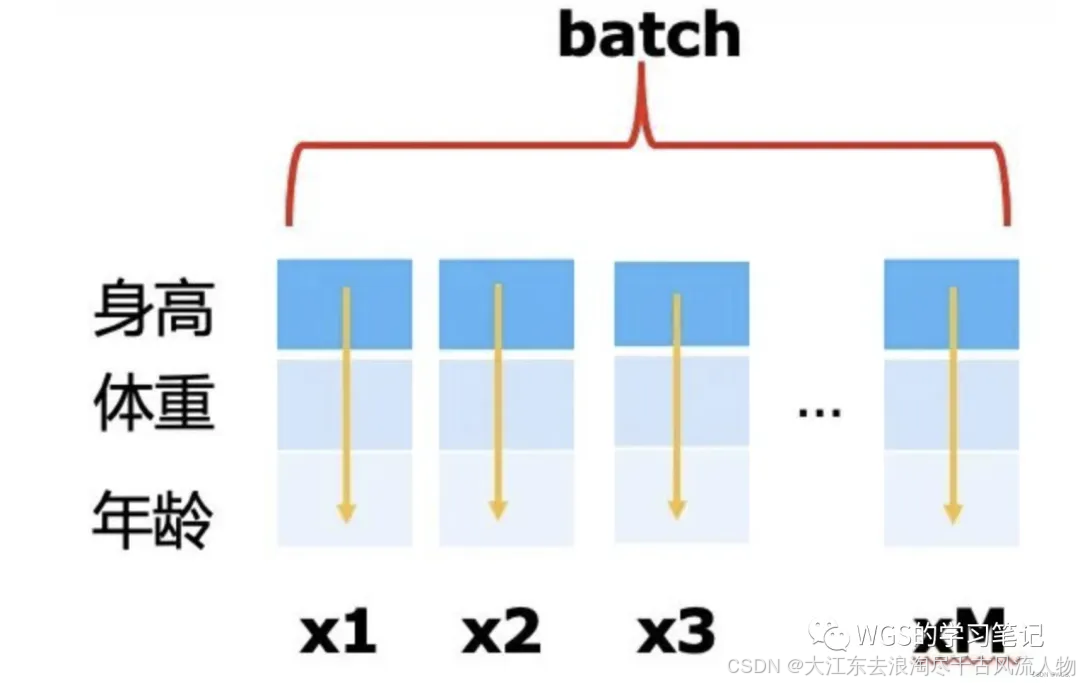
在NLP中,N个特征都可能表示不同的词,这个时候我们仍然采用BatchNorm的话,对第一个词进行操作,很显然意义就不是非常大了,
因为任何一个词都可以放在第一个位置,而且很多时候词序对于我们对于句子的影响没那么大,
而此时我们对N个词进行Norm等操作可以很好地反映句子的分布。
(LN一般用在第三维度,[batchsize,seq_len,dims]),因为该维度特征的量纲是相同的,所以并没有太多区别。
6.2.4 为什么使用LayerNorm,不用BatchNorm?
上面其实就已经给出讲解了,这里再接着上面的例子加深理解:
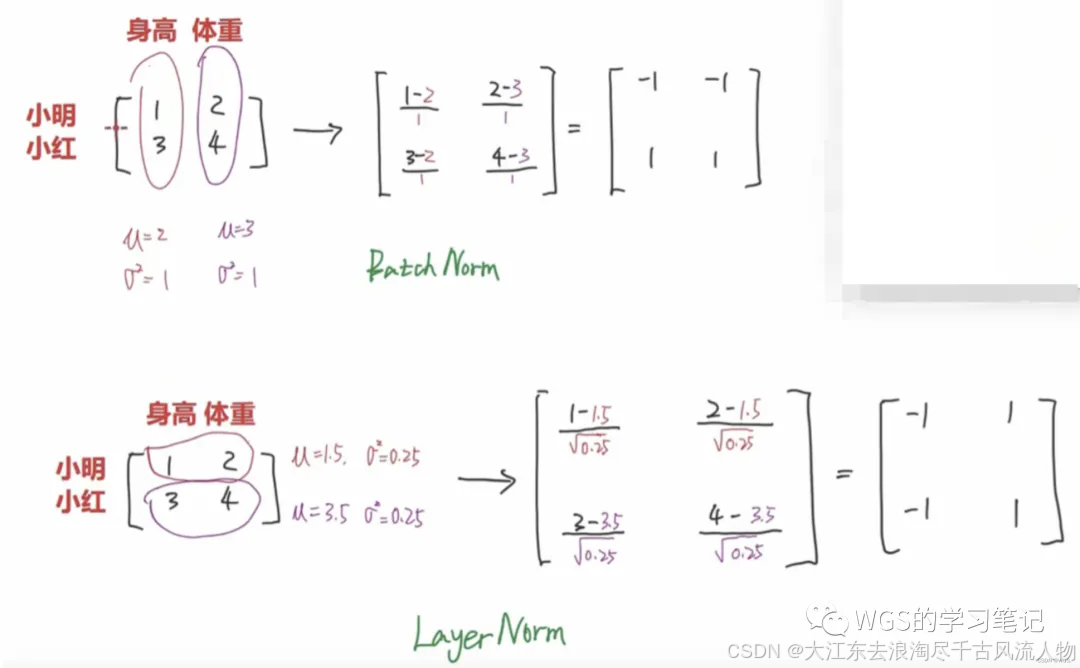
LayerNorm简称LN,BatchNorm简称BN。它俩的作用都是消除量纲影响,加快模型收敛。
BN做的事情是将这个batch内的,对每个特征分别求均值、标准差,然后再各自减去均值除以标准差。从而让分布变到均值为0,方差为1的标准正太分布当中。
LN是以样本为单位去计算均值和标准差的。
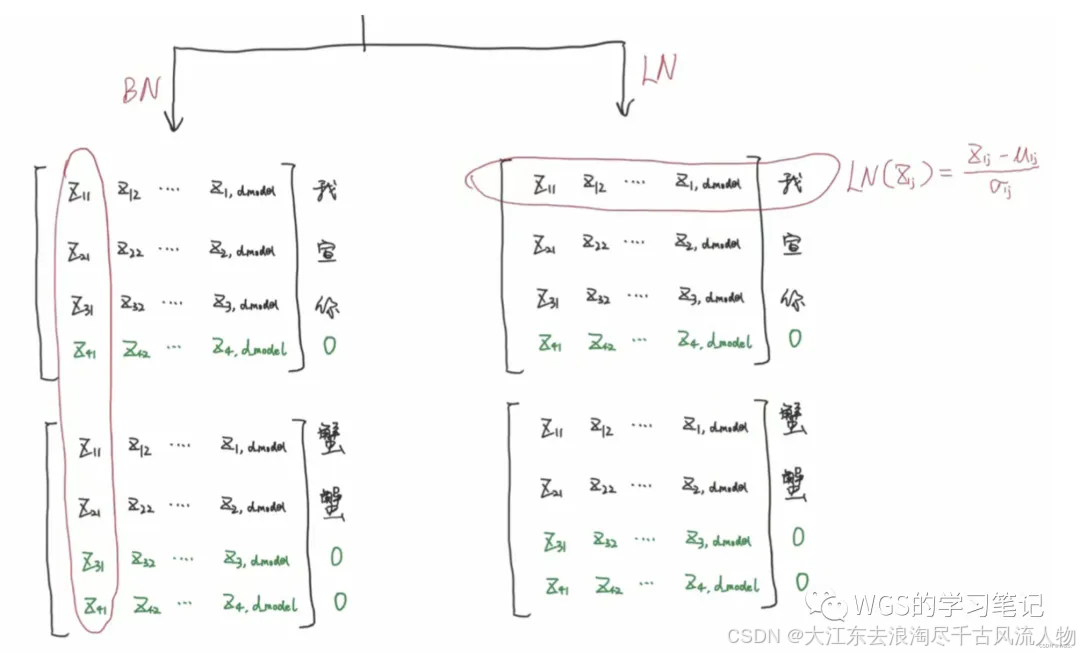
在nlp领域使用BN效果不好,BN的计算方式是以一个batch中的样本数据去计算它的均值和方差的。
这样计算它是有padding的影响的,并且代表不了整个的均值和方差。在刚刚小明和小红例子中,身高这个特征所在的列含义是相同的。但是在nlp里,第一行是”我“字的emb词向量,第二行是”宣“字的emb词向量,经过attention之后,形成的是包含语义信息的向量,每一列代表的含义并不相同了。
不能说每个词向量的每个维度代表的含义是一样的。
因此从这个⻆度来理解,这里采用BN是不合适的。
所以LN用的是比较多的。以每个词向量去做标准化就可以了,这样就不会引入padding不相关的信息。
batch_size太小时,一个batch的样本,其均值和方差,不足以代表总体样本的均值与方差。NLP领域不适合用BN。
6.3 前馈神经网络(Feed Forword)
这里也是没什么好讲的,就是一个两层的全连接。通过激活函数引入非线性变换,变换了Attention output的空间, 从而增加了模型的表现能力。
把FFN去掉模型也是可以用的,但是效果差了很多。
7、Decoder部分
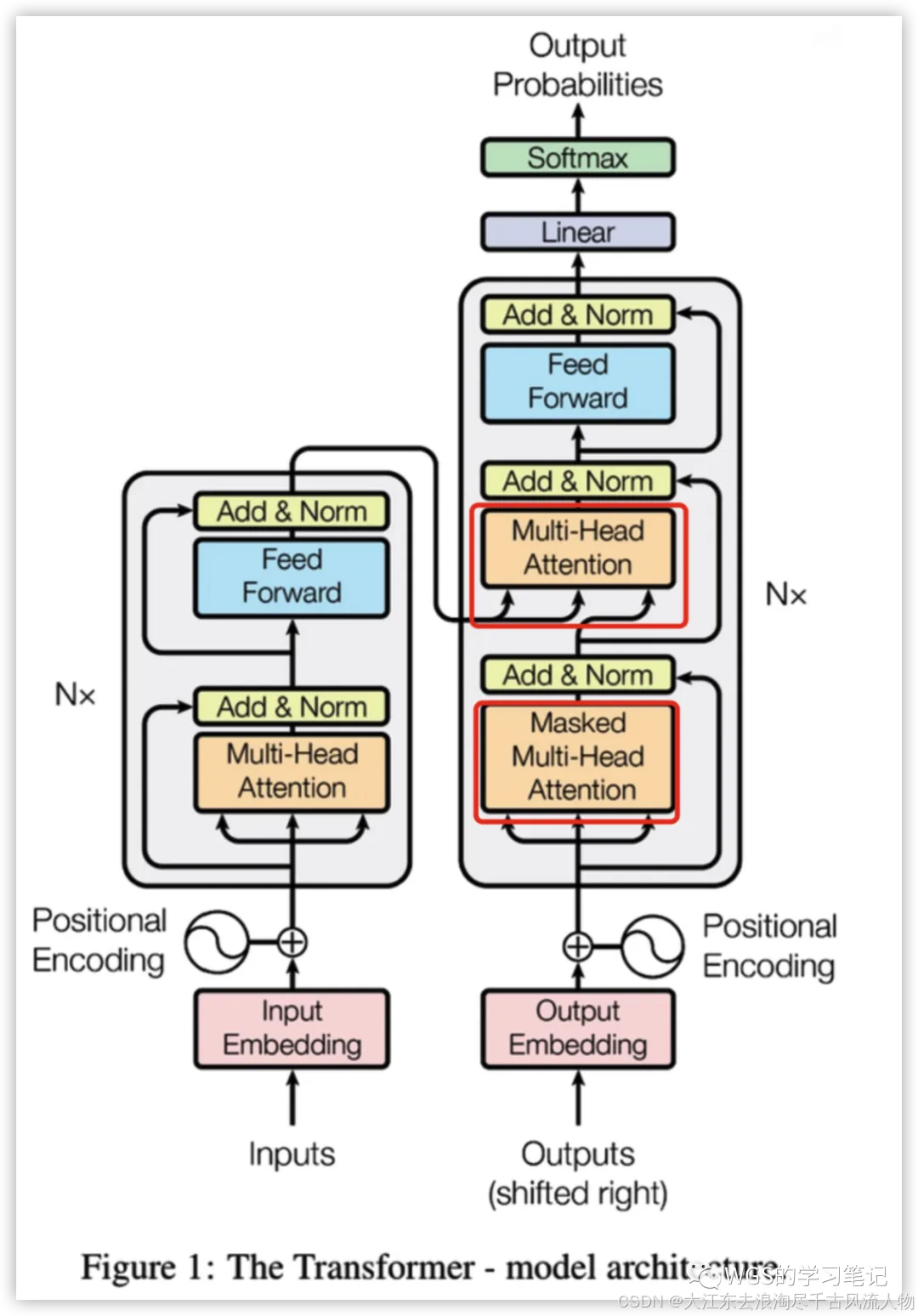
encoder和decoder结构相似,只需要关注decoder部分的attention就可以了,其它的就不再赘述了。
其中Decoder部分可以分为2个讲解:
Masked Multi-Head Attention
带mask的多头注意力机制,目的是为了防止模型看到要预测的数据,防止泄露。
如果不清楚的同学,可以往上翻,看下机器翻译工作流程的Decoder部分。
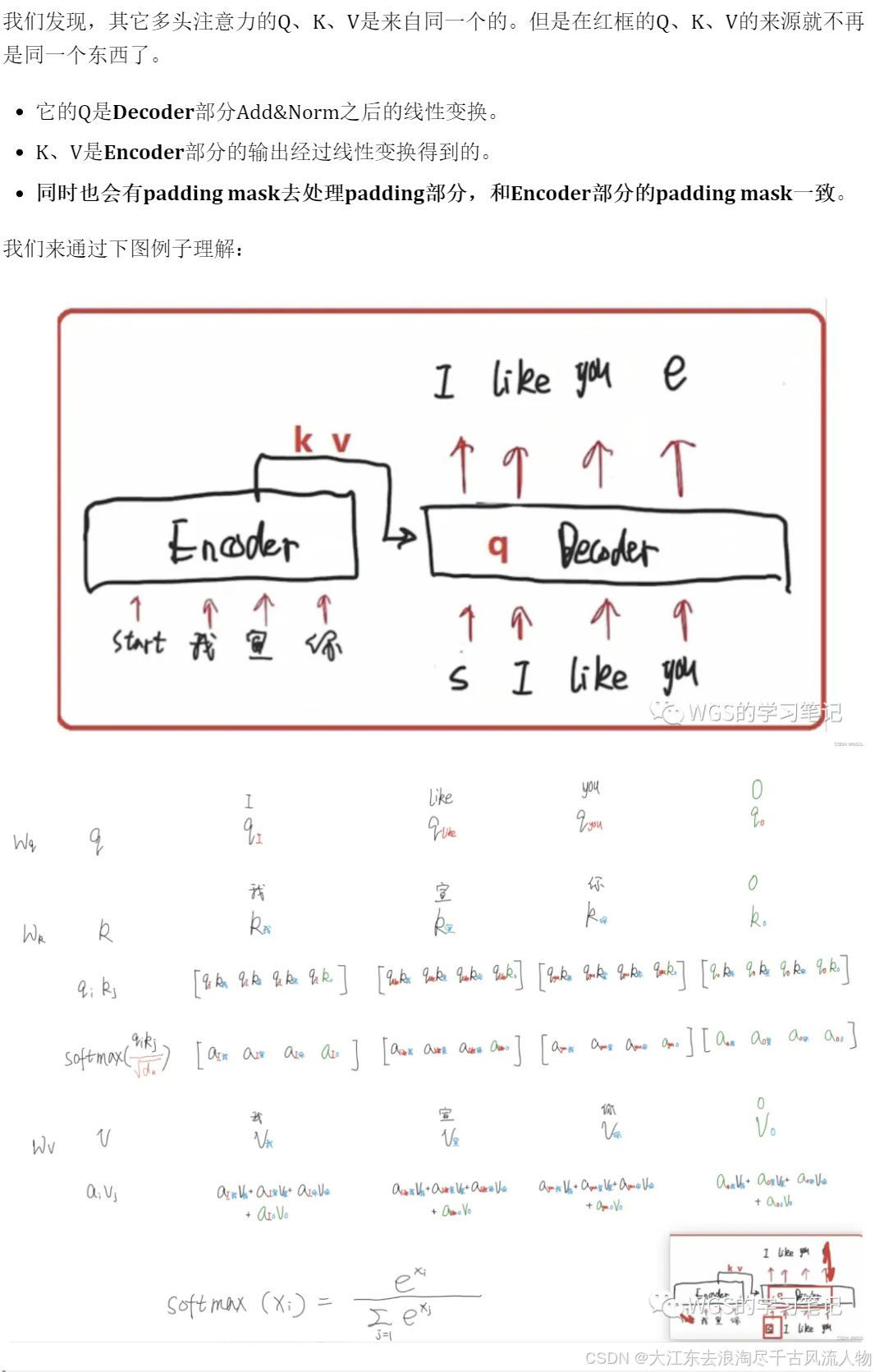
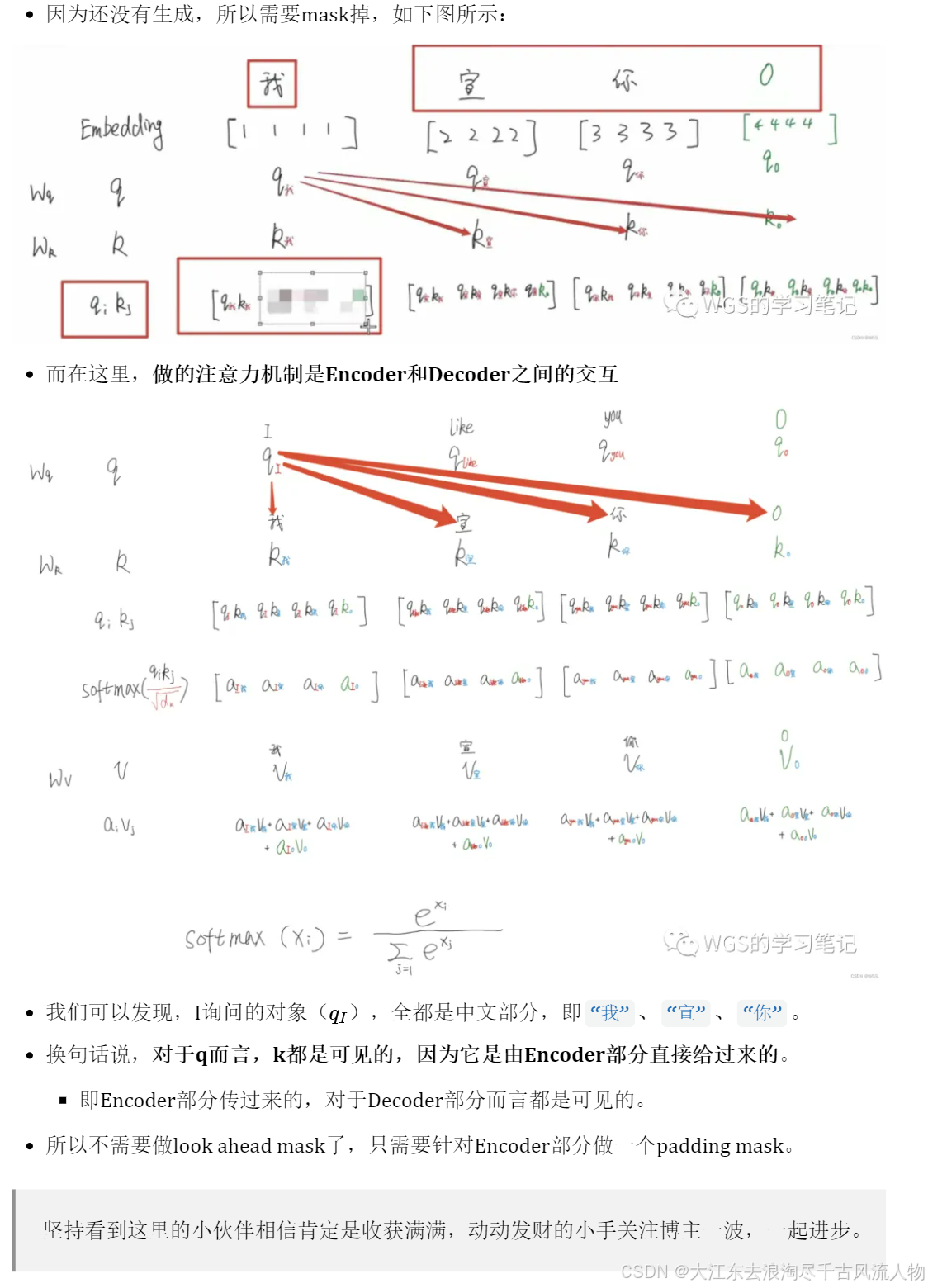
Encoder-Decoder Multi-Head Attention
用于Encoder部分和Decoder部分的交互。
细心的同学可以看到这里的箭头有两个是来自Encoder,有一个是来自Decoder。
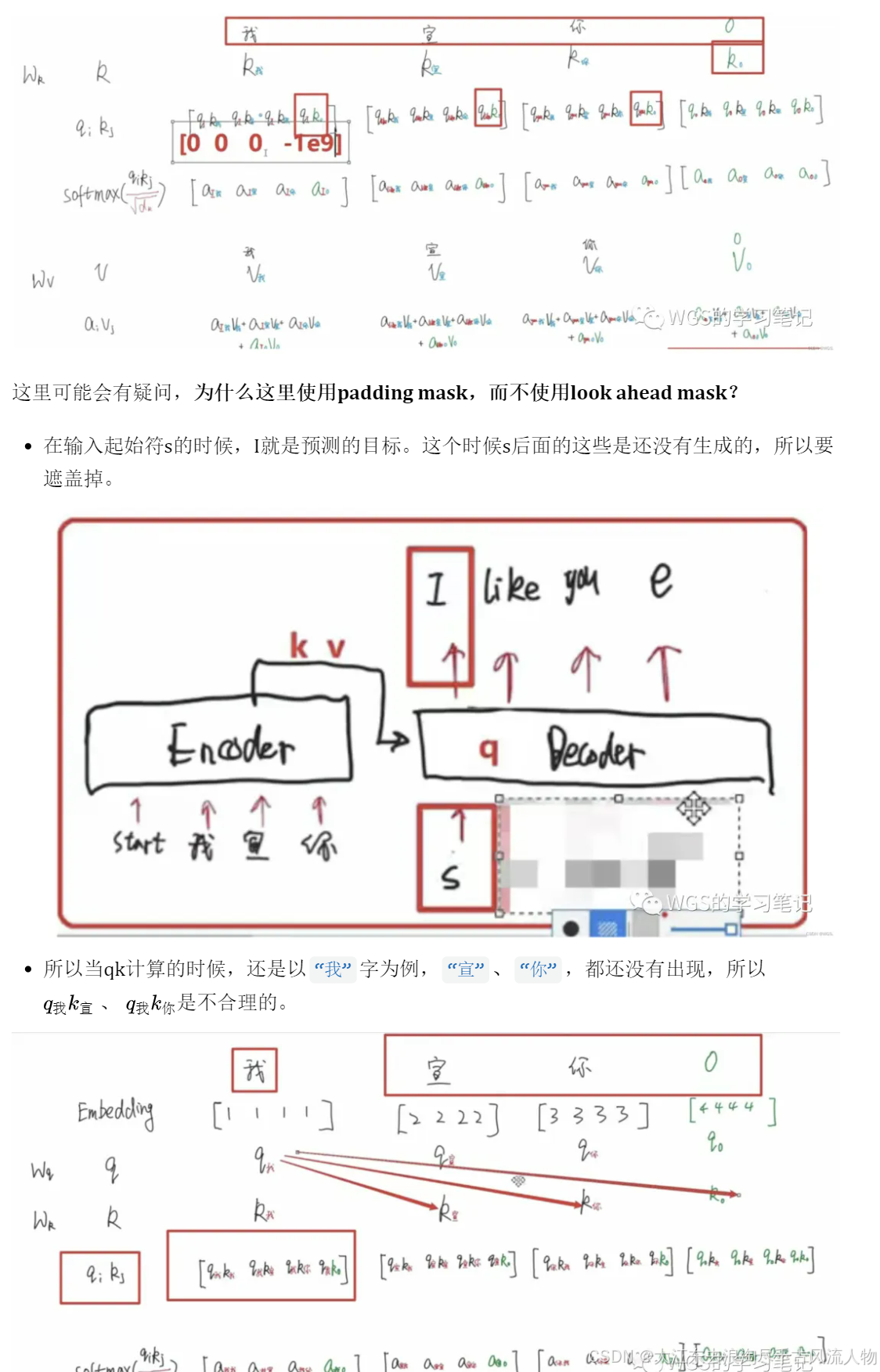
7.1 带mask的多头注意力机制(Masked Multi-Head Attention)
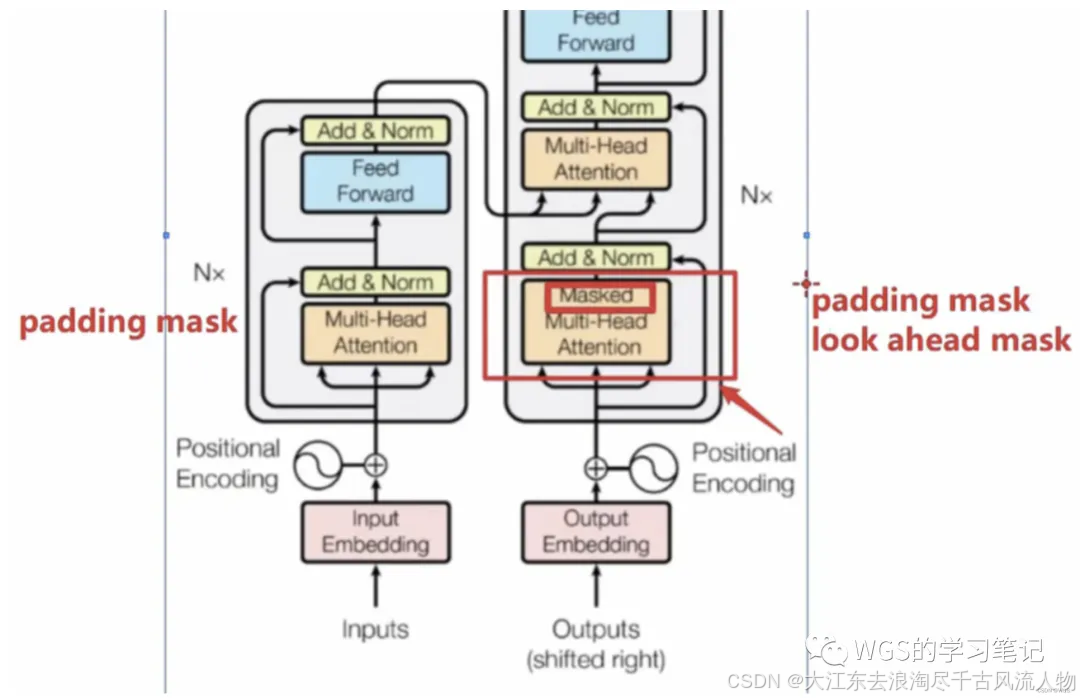
Encoder和Decoder部分都有padding mask,在Decoder部分还多了一个look ahead mask,就是masked Multi head attention的mask的含义。
先回顾一下decoder部分的工作流程:
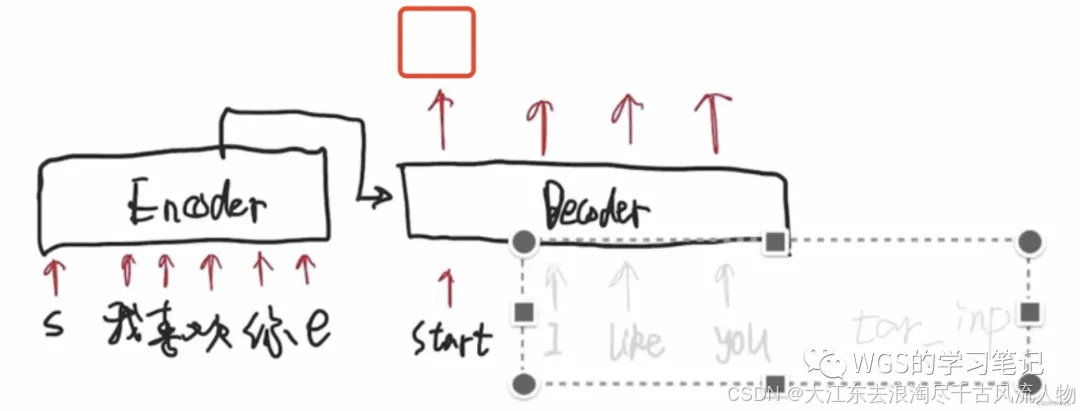
首先是预测第一个位置,图中红框,要保证第一个位置的预测只和起始符start有关,所以要把start后面的部分给遮盖掉。
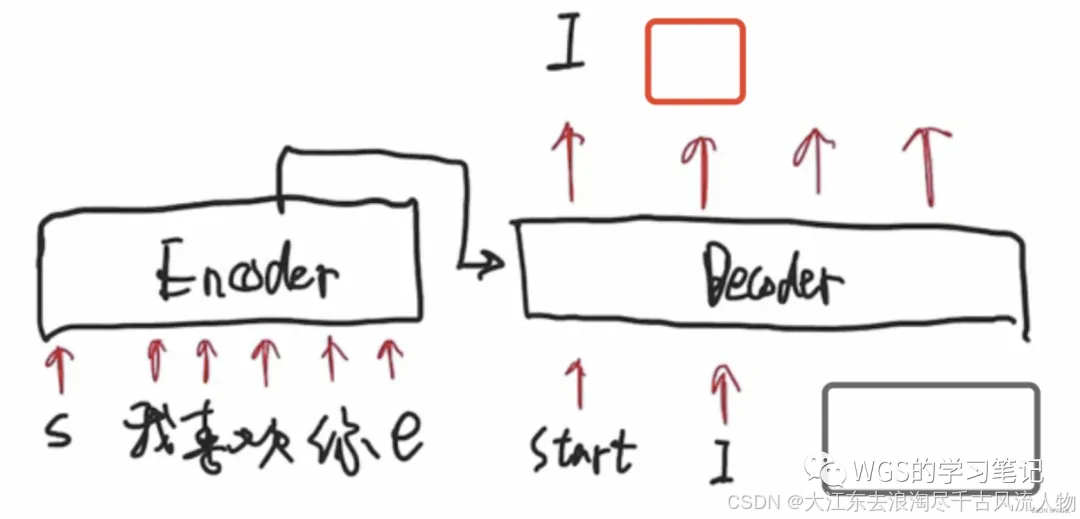
预测第二个位置的时候,要保证第二个预测位置只和start、I有关,所以后面的部分要mask掉。
很好理解,就是根据前面的信息,预测可能出现的下一个值。
假设这是decoder部分的多头注意力,我们来看一下如果不做mask会是什么样:


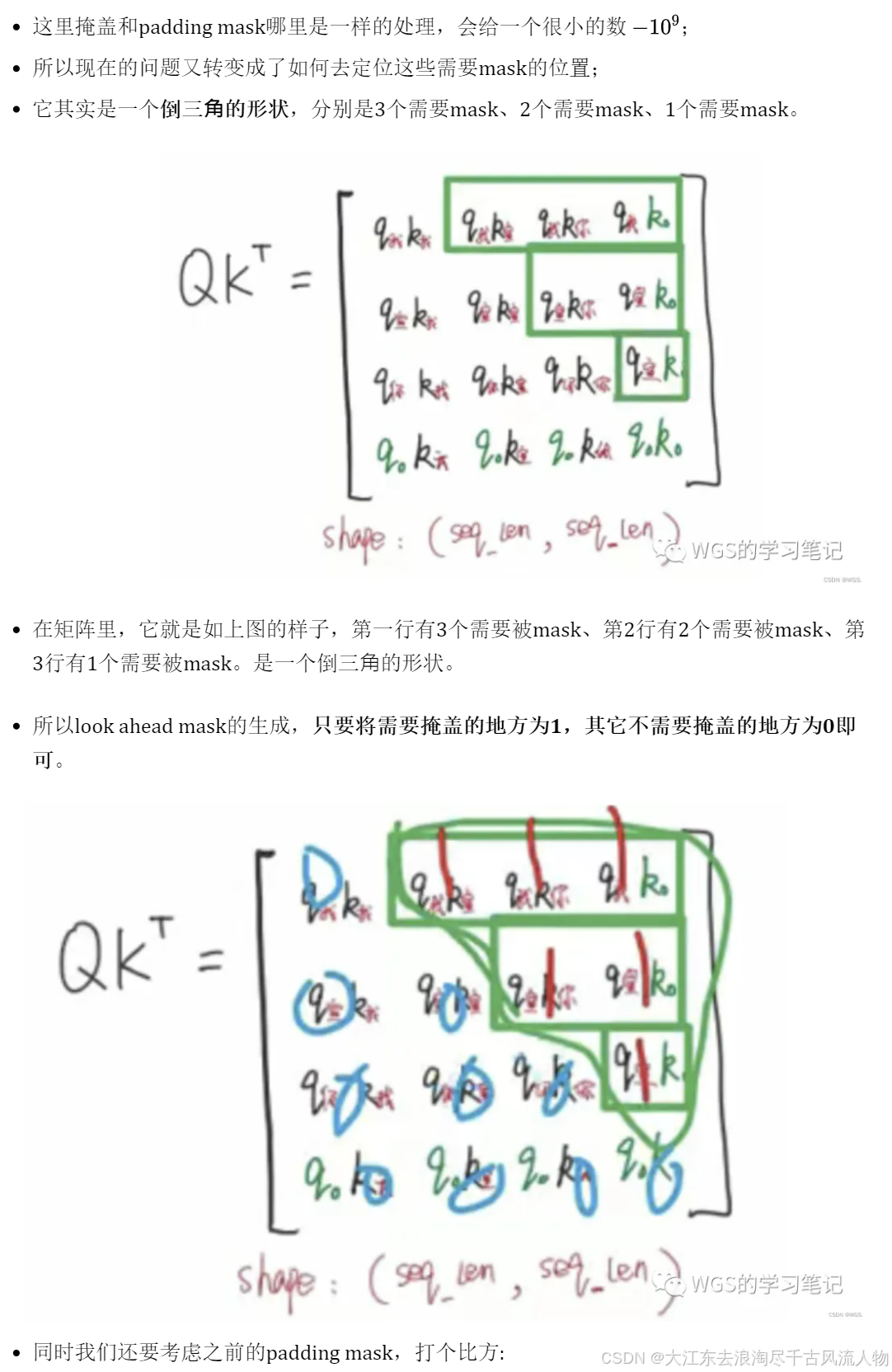

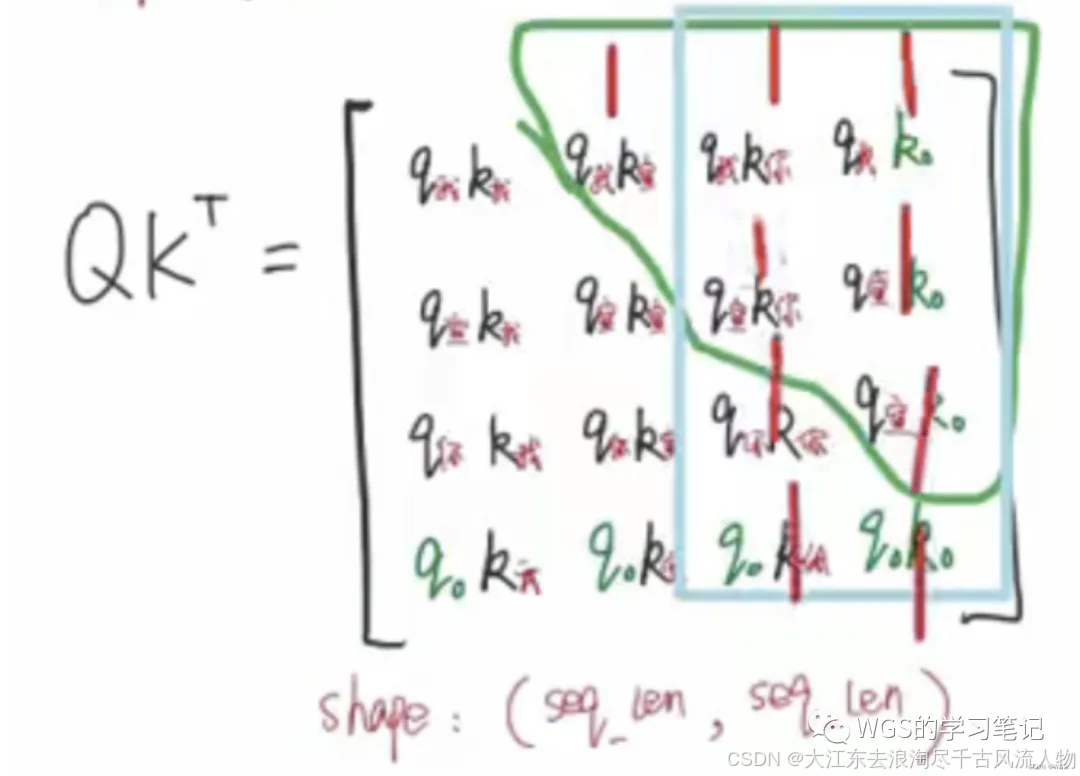
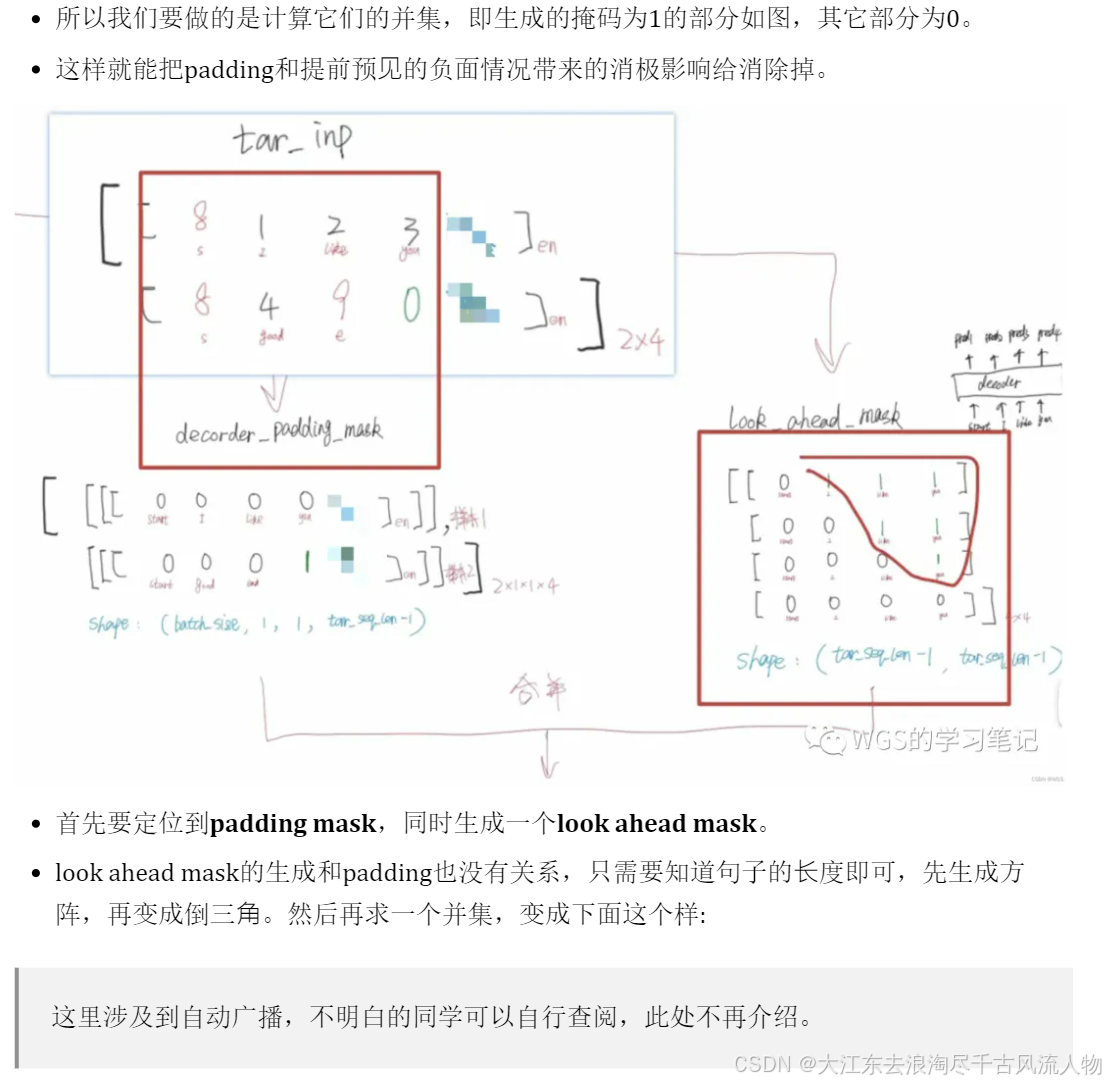
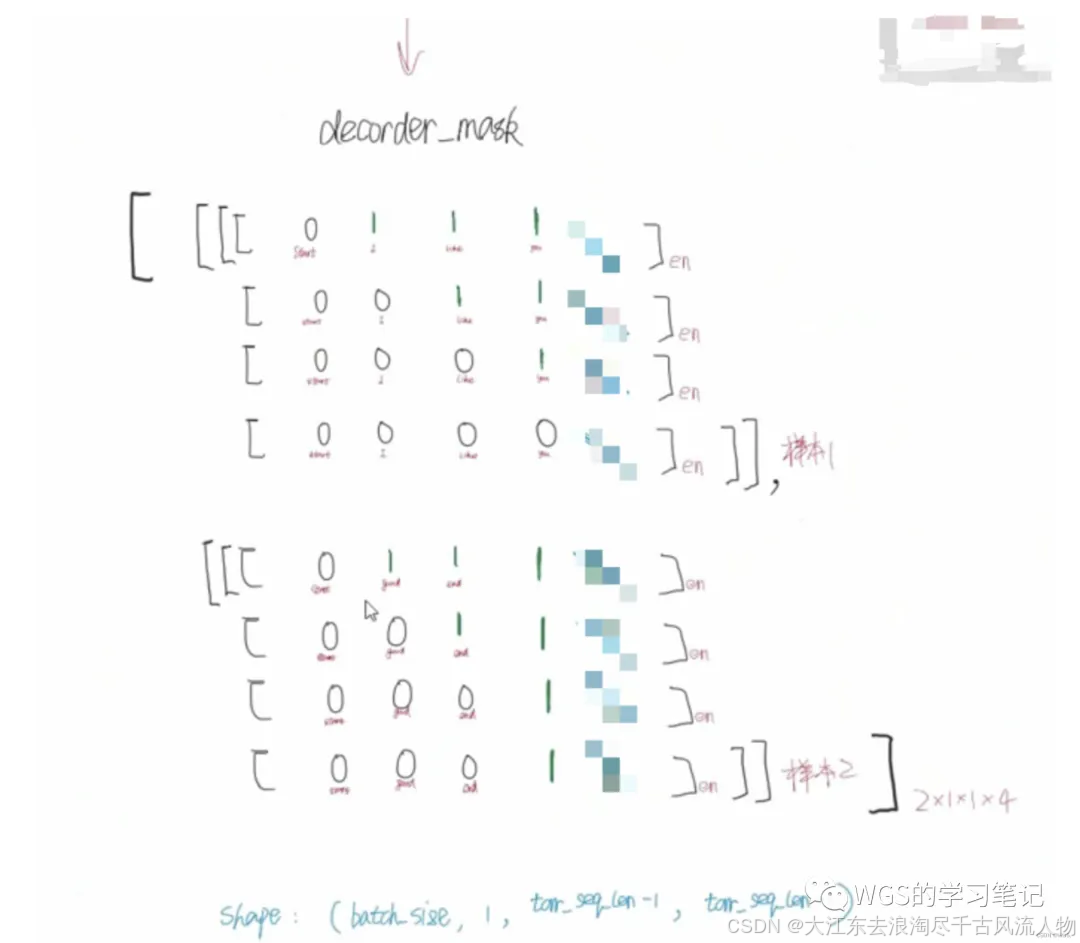
Decoder的多头注意力和Encoder的多头注意力的不同地方就在于使用的mask不同。
7.2 Encoder与Decoder间的多头注意力机制(Multi-Head Attention)
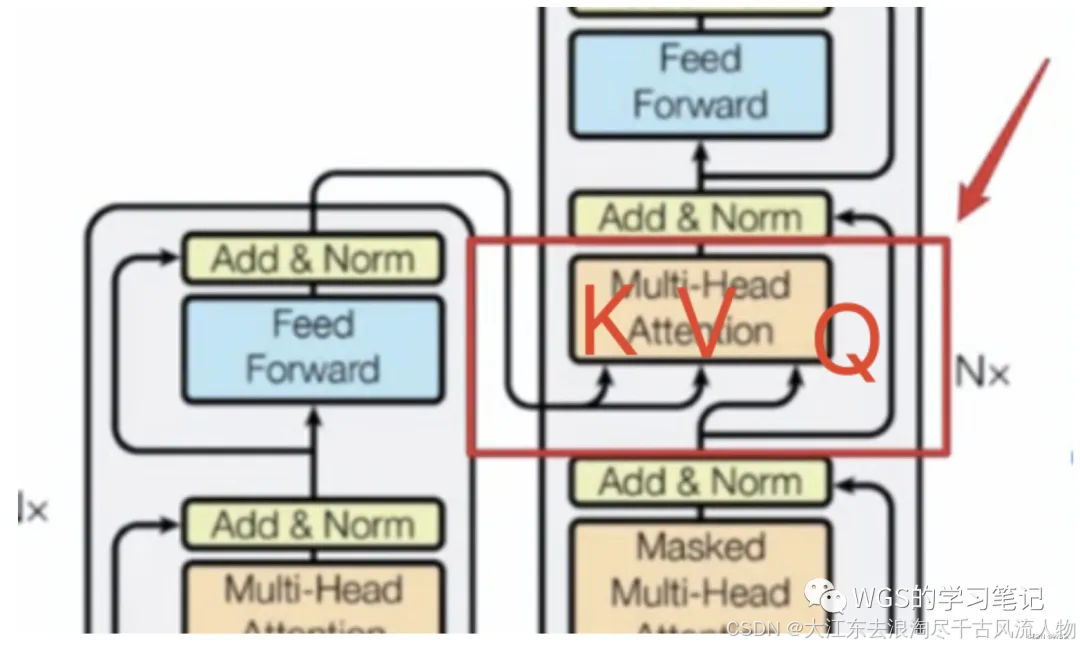

8、输出部分

9、有关训练
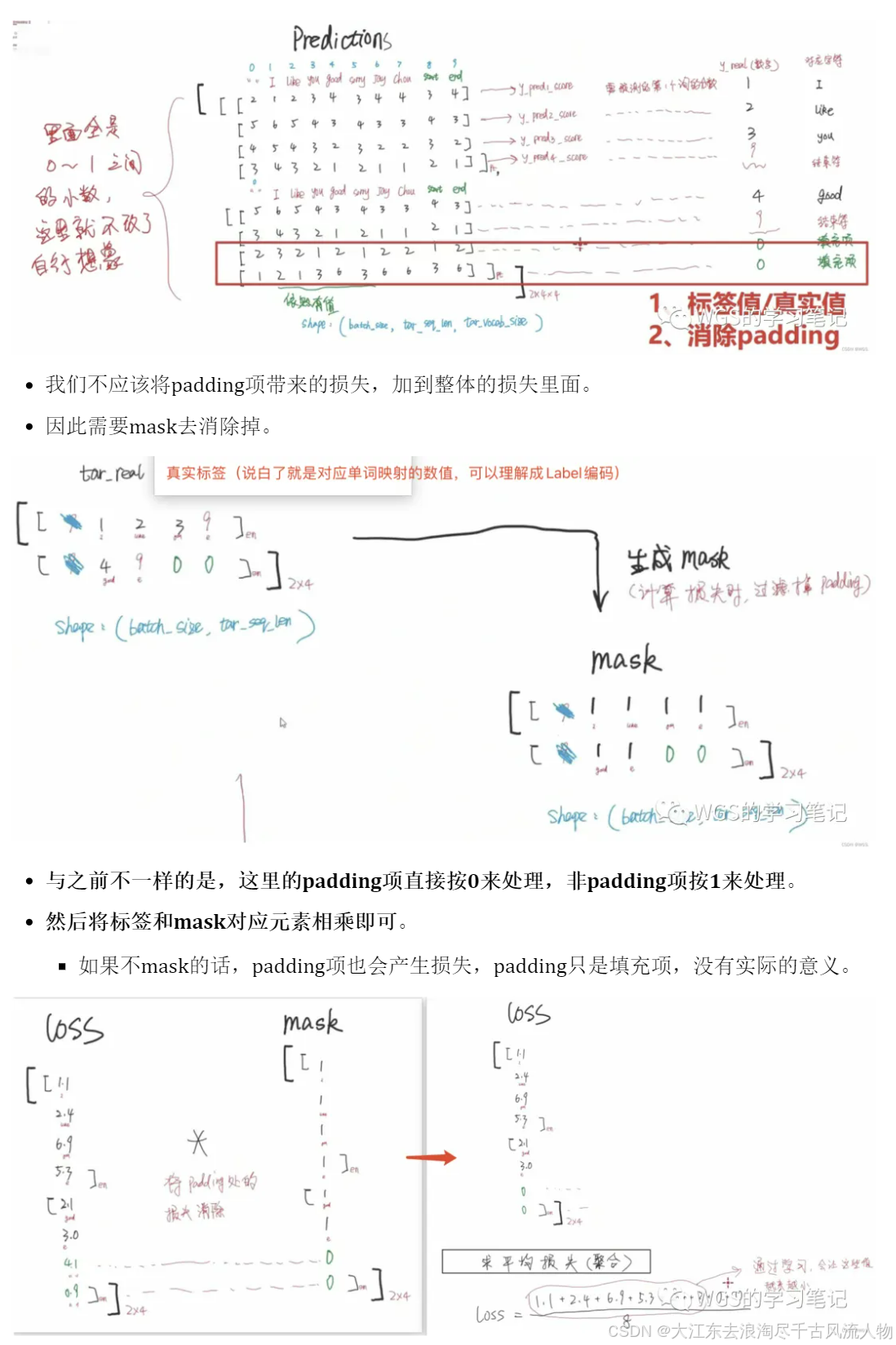
9.1 损失计算
损失依旧是交叉熵,为什么这里会讲一下,因为有padding。
也就是说我们需要注意的是,损失计算也要有mask,去消除padding项带来的损失。
在计算损失的时候,需要做:
- 先拿到标签值(真实值)。
- 消除padding带来的影响。
Predictions矩阵,是经过softmax后的预测概率值
9.2 自定义学习率

10、全部代码及资料
加粗样式
- https://github.com/WGS-note/transformer-note
- https://s3.us-west-2.amazonaws.com/secure.notion-static.com/501fb338-a6b0-484a-8a16-713dd40251de/Attention_is_All_You_Need.pdf?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Credential=AKIAT73L2G45EIPT3X45%2F20220522%2Fus-west-2%2Fs3%2Faws4_request&X-Amz-Date=20220522T014504Z&X-Amz-Expires=86400&X-Amz-Signature=180db501219c968fdd116b27d6b44bed0eed6e912755d300cd7db8e957937e1b&X-Amz-SignedHeaders=host&response-content-disposition=filename%20%3D%22Attention%2520is%2520All%2520You%2520Need.pdf%22&x-id=GetObject
- https://ugirc.blog.csdn.net/article/details/120394042
- https://luweikxy.gitbook.io/machine-learning-notes/self-attention-and-transformer#multi-headed-attention
- https://zhuanlan.zhihu.com/p/353381965
- https://www.bilibili.com/video/BV1pu411o7BE?spm_id_from=333.337.search-card.all.click
- https://www.bilibili.com/video/BV1Kq4y1H7FL?spm_id_from=333.337.search-card.all.click
- https://zhuanlan.zhihu.com/p/153183322



















 1222
1222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











