









作者主页(文火冰糖的硅基工坊):https://blog.csdn.net/HiWangWenBing
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/119489896
目录
第1章 Tensor运算概述
1.1 概述
PyTorch提供了大量的张量运算,基本上可以对标Numpy多维数组的运算,以支持对张量的各种复杂的运算。
这些操作运算中大多是对数组中每个元素执行相同的函数运算,并获得每个元素函数运算的结果序列,这些序列生成一个新的同维度的数组。
https://www.runoob.com/numpy/numpy-linear-algebra.html

不同维度张量的维度方向标识
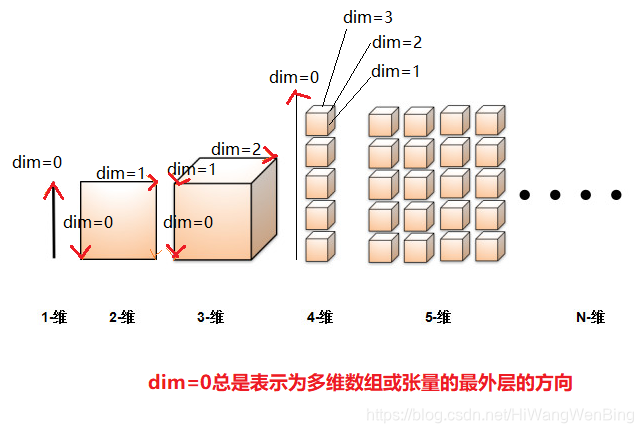
- 随着张量维度的增加,张量维度的标识dim的范围也在扩宽
- 在张量维度扩展的过程中,维度标识值(dim=n)的含义也在发生变化。
- dim=0总是指向张量的多维数组存储的最外层:[ ] [ ] [ ], 这与物理存储的标识是相反的。
1.2 运算分类
(1)算术运算:加、减、系数乘、系数除
(2)函数运算:sin,cos
(3)取整运算:上取整、下取整
(4)统计运算:最大值、最小值、均值
(5)比较运算:大于,等于,小于、排序
(6)线性代数运算:矩阵、点乘、叉乘
1.3 张量的操作与变换
(1)变换内容: 变换张量元素的值。
(1)变换长度:变换张量的某个方向的长度(即向量的维度或长度),长度可增加,可减少。
(3)变换维度:变化张量的维度,维度可以增加,可减少。
1.4 环境准备
import numpy as np
import torch
print("Hello World")
print(torch.__version__)
print(torch.cuda.is_available())1.5 张量的操作 - 拆分与分割


张量的切分有两种主要的基本策略:
- 在某个维度方向,平均分割:chunk()
- 在某个维度方向,指定分割:split()
第2章 平均分割:chunk()
2.1 工作原理
张量的任意一个dim方向,都是有长度的,这个长度就是该方向上向量的维度或长度。
平均分割是把这个维度的长度,分割成几个等分的部分。
当张量dim方向的长度不能被整除时,切分后的最后一个张量块的大小会少一些。
2.2 函数描述
功能:在不改变张量的维度的情况下,在某个dim方向上,把一个长度较大的张量,分割成多个长度相同的张量。
原型:chunk(input, chunks,dim)
输入参数:
input: 输入张量
chunks:均匀分割的张量个数
dim:切分的方向
2.3 代码示例
#均匀切分
print("源张量")
a = torch.Tensor([[0,2,4,6,8,10,12,14,16,18],[1,3,5,7,9,11,13,15,17,19]])
print(a)
print("\ndim=0切分后张量")
c = torch.chunk(a,chunks=2,dim=0)
print(c[0])
print(c[1])
print("\ndim=1切分后张量")
c = torch.chunk(a,chunks=3,dim=1)
print(c[0])
print(c[1])
print(c[2])
输出:
源张量
tensor([[ 0., 2., 4., 6., 8., 10., 12., 14., 16., 18.],
[ 1., 3., 5., 7., 9., 11., 13., 15., 17., 19.]])
dim=0切分后张量
tensor([[ 0., 2., 4., 6., 8., 10., 12., 14., 16., 18.]])
tensor([[ 1., 3., 5., 7., 9., 11., 13., 15., 17., 19.]])
dim=1切分后张量
tensor([[0., 2., 4., 6.],
[1., 3., 5., 7.]])
tensor([[ 8., 10., 12., 14.],
[ 9., 11., 13., 15.]])
tensor([[16., 18.],
[17., 19.]])
备注:
dim=1的方向,长度为10,三等分的结果为:4+4+2,不是3+3+4.
这是这个函数的算法所决定的,它要最后一个张量的长度不能大于其他张量的长度。
第3章 任意分割:split()
3.1 工作原理
张量的任意一个dim方向,都是有长度的,这个长度就是该方向上向量的维度或长度。
任意分割就是指定每个分块的长度,并通过[1,3,5]的形式,指明每个分块的长度和顺序。
3.2 函数描述
功能:在不改变张量的维度的情况下,在某个dim方向上,把一个长度较大的张量,按照指定的长度,依次分割成多个张量。
原型:split(input, split_size_or_sections, dim)
输入参数:
input: 输入张量
split_size_or_sections
dim:切分的方向
3.3 代码示例
#任意切分
print("源张量")
a = torch.Tensor([[0,2,4,6,8,10,12,14,16,18],[1,3,5,7,9,11,13,15,17,19]])
print(a)
print("\ndim=0切分后张量")
c = torch.split(a,split_size_or_sections=[1,1],dim=0)
print(c[0])
print(c[1])
print("\ndim=1切分后张量")
c = torch.split(a,[2,4,4],dim=1)
print(c[0])
print(c[1])
print(c[2])输出:
源张量
tensor([[ 0., 2., 4., 6., 8., 10., 12., 14., 16., 18.],
[ 1., 3., 5., 7., 9., 11., 13., 15., 17., 19.]])
dim=0切分后张量
tensor([[ 0., 2., 4., 6., 8., 10., 12., 14., 16., 18.]])
tensor([[ 1., 3., 5., 7., 9., 11., 13., 15., 17., 19.]])
dim=1切分后张量
tensor([[0., 2.],
[1., 3.]])
tensor([[ 4., 6., 8., 10.],
[ 5., 7., 9., 11.]])
tensor([[12., 14., 16., 18.],
[13., 15., 17., 19.]])备注:
dim=0时,长度为0,因此只能分割成[1,1]两个块。
dim=1是,长度为10,这里的分割成3个块,分割方法是:[2,4,4]。 2+4+4=10.
作者主页(文火冰糖的硅基工坊):https://blog.csdn.net/HiWangWenBing
本文网址:
















 7553
7553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











