










卡尔曼滤波图画示意
先从简单的说起:
考虑轨道上的一个小车,无外力作用,它在时刻t的状态向量 只与
只与 相关:
相关:
(状态向量就是描述它的t=0时刻所有状态的向量,比如:
[速度大小5m/s, 速度方向右, 位置坐标0],反正有了这个向量就可以完全预测t=1时刻小车的状态)

那么根据t=0时刻的初值 ,理论上我们可以求出它任意时刻的状态。
,理论上我们可以求出它任意时刻的状态。
当然,实际情况不会这么美好。
这个递推函数可能会受到各种不确定因素的影响(内在的外在的都算,比如刮风下雨地震,小车结构不紧密,轮子不圆等等)导致并不能精确标识小车实际的状态。
我们假设每个状态分量受到的不确定因素都服从正态分布。
现在仅对小车的位置进行估计
请看下图:t=0时小车的位置服从红色的正态分布。

根据小车的这个位置,我们可以预测出t=1时刻它的位置:

分布变“胖”了,这很好理解——因为在递推的过程中又加了一层噪声,所以不确定度变大了。
为了避免纯估计带来的偏差,我们在t=1时刻对小车的位置坐标进行一次雷达测量,当然雷达对小车距离的测量也会受到种种因素的影响,于是测量结果告诉我们,小车t=1时的位置服从蓝色分布:

好了,现在我们得到两个不同的结果。前面有人提过加权,Kalman老先生的牛逼之处就在于找到了相应权值,使红蓝分布合并为下图这个绿色的正态分布(啰嗦一句,这个绿色分布均值位置在红蓝均值间的比例称为Kalman增益(比如下图中近似0.8),就是各种公式里的K(t))

你问为什么牛逼?
绿色分布不仅保证了在红蓝给定的条件下,小车位于该点的概率最大,而且,而且,它居然还是一个正态分布!
正态分布就意味着,可以把它当做初值继续往下算了!这是Kalman滤波能够迭代的关键。
最后,把绿色分布当做第一张图中的红色分布对t=2时刻进行预测,算法就可以开始循环往复了。
你又要问了,说来说去绿色分布是怎么得出的呢?
其实可以通过多种方式推导出来。我们课上讲过的就有最大似然法、Ricatti方程法,以及上面参考文献中提及的直接对高斯密度函数变形的方法,这个不展开说了。
另外,由于我只对小车位移这个一维量做了估计,因此Kalman增益是标量,通常情况下它都是一个矩阵。而且如果估计多维量,还应该引入协方差矩阵的迭代,我也没有提到。如果楼主有兴趣,把我提及那篇参考文献吃透,就明白了。
Kalman滤波算法的本质就是利用两个正态分布的融合仍是正态分布这一特性进行迭代而已。
作者:肖畅 来源:知乎 链接:https://www.zhihu.com/question/23971601/answer/46480923
卡尔曼滤波的原理
1、卡尔曼滤波的原理说明
在学习卡尔曼滤波器之前,首先看看为什么叫“卡尔曼”。跟其他著名的理论(例如傅立叶变换,泰勒级数等等)一样,卡尔曼也是一个人的名字,而跟他们不同的是,他是个现代人!
卡尔曼全名RudolfEmilKalman,匈牙利数学家,1930年出生于匈牙利首都布达佩斯。1953,1954年于麻省理工学院分别获得电机工程学 士及硕士学位。1957年于哥伦比亚大学获得博士学位。我们现在要学习的卡尔曼滤波器,正是源于他的博士论文和1960年发表的论文 《ANewApproachtoLinearFilteringandPredictionProblems》(线性滤波与预测问题的新方法)。
简单来说,卡尔曼滤波器是一个 “optimalrecursivedataprocessingalgorithm(最优化自回归数据处理算法)”。对于解决很大部分的问题,他是最优,效率最高甚至是最有用的。他的广泛应用已经超过30年,包括机器人导航,控制,传感器数据融合甚至在军事方面的雷达系统以及导弹追踪等等。近年来更被应用于计算机图像处理,例如头脸识别,图像分割,图像边缘检测等等。
2.卡尔曼滤波器的介绍(IntroductiontotheKalmanFilter)
为了可以更加容易的理解卡尔曼滤波器,这里会应用形象的描述方法来讲解,而不是像大多数参考书那样罗列一大堆的数学公式和数学符号。但是,他的5条公式是其核心内容。结合现代的计算机,其实卡尔曼的程序相当的简单,只要你理解了他的那5条公式。
在介绍他的5条公式之前,先让我们来根据下面的例子一步一步的探索。
假设我们要研究的对象是一个房间的温度。根据你的经验判断,这个房间的温度是恒定的,也就是下一分钟的温度等于现在这一分钟的温度(假设我们用一分钟来做时 间单位)。假设你对你的经验不是100%的相信,可能会有上下偏差几度。我们把这些偏差看成是高斯白噪声(WhiteGaussianNoise),也就 是这些偏差跟前后时间是没有关系的而且符合高斯分配(GaussianDistribution)。
另外,我们在房间里放一个温度计,但是这个温度计也不准确的,测量值会比实际值偏差。我们也把这些偏差看成是高斯白噪声。
好了,现在对于某一分钟我们有两个有关于该房间的温度值:你根据经验的预测值(系统的预测值)和温度计的值(测量值)。下面我们要用这两个值结合他们各自的噪声来估算出房间的实际温度值。
假如我们要估算k时刻的是实际温度值。首先你要根据k-1时刻的温度值,来预测k时刻的温度。因为你相信温度是恒定的,所以你会得到k时刻的温度预测值是跟k-1时刻一样的,假设是23度,同时该值的高斯噪声的偏差是5度(5是这样得到的:如果k-1时刻估算出的最优温度值的偏差是3,你对自己预测的不确定 度是4度,他们平方相加再开方,就是5)。
然后,你从温度计那里得到了k时刻的温度值,假设是25度,同时该值的偏差是4度。
由于我们用于估算k时刻的实际温度有两个温度值,分别是23度和25度。究竟实际温度是多少呢?相信自己还是相信温度计呢?究竟相信谁多一点,我们可以用他们的协方差covariance来判断。因为Kg^2=5^2/(5^2+4^2),所以Kg=0.78,[sqrt(5^2/(5^2+4^2)) ]我们可以估算出k时刻的实际温度值 是:23+0.78*(25-23)=24.56度。可以看出,因为温度计的covariance比较小(比较相信温度计),所以估算出的最优温度值偏向温度计的值。
现在我们已经得到k时刻的最优温度值了,下一步就是要进入k+1时刻,进行新的最优估算。到现在为止,好像还没看到什么自回归的东西出现。对了,在进入k+1时刻之前,我们还要算出k时刻那个最优值(24.56度)的偏差。算法如下:((1- Kg)*5^2)^0.5=2.35。这里的5就是上面的k时刻你预测的那个23度温度值的偏差,得出的2.35就是进入k+1时刻以后k时刻估算出的最优温度值的偏差(对应于上面的3)。
就是这样,卡尔曼滤波器就不断的把covariance递归,从而估算出最优的温度值。他运行的很快,而且它只保留了上一时刻的covariance。上面的Kg,就是卡尔曼增益(KalmanGain)。他可以随不同的时刻而改变他自己的值,是不是很神奇!
下面就要言归正传,讨论真正工程系统上的卡尔曼。
3.卡尔曼滤波器算法(TheKalmanFilterAlgorithm)
在这一部分,我们就来描述源于DrKalman的卡尔曼滤波器。下面的描述,会涉及一些基本的概念知识,包括概率(Probability),随机变量 (RandomVariable),高斯或正态分配(GaussianDistribution)还有State-spaceModel等等。但对于卡尔曼滤波器的详细证明,这里不能一一描述。
首先,我们先要引入一个离散控制过程的系统。该系统可用一个线性随机微分方程(LinearStochasticDifferenceequation)来描述:X(k)=AX(k-1)+BU(k)+W(k)
再加上系统的测量值:Z(k)=HX(k)+V(k)
上两式子中,X(k)是k时刻的系统状态,U(k)是k时刻对系统的控制量。A和B是系统参数,对于多模型系统,他们为矩阵。Z(k)是k时刻的测量值,H 是测量系统的参数,对于多测量系统,H为矩阵。W(k)和V(k)分别表示过程和测量的噪声。他们被假设成高斯白噪声 (WhiteGaussianNoise),他们的covariance分别是Q,R(这里我们假设他们不随系统状态变化而变化)。
对于满足上面的条件(线性随机微分系统,过程和测量都是高斯白噪声),卡尔曼滤波器是最优的信息处理器。下面我们来用他们结合他们的covariances来估算系统的最优化输出(类似上一节那个温度的例子)。
首先我们要利用系统的过程模型,来预测下一状态的系统。假设现在的系统状态是k,根据系统的模型,可以基于系统的上一状态而预测出现在状态:X(k|k-1)=AX(k-1|k-1)+BU(k)………..(1)
式(1)中,X(k|k-1)是利用上一状态预测的结果,X(k-1|k-1)是上一状态最优的结果,U(k)为现在状态的控制量,如果没有控制量,它可以为0。
到现在为止,我们的系统结果已经更新了,可是,对应于X(k|k-1)的covariance还没更新。我们用P表示covariance:
P(k|k-1)=AP(k-1|k-1)A’+Q (2)
式(2)中,P(k|k-1)是X(k|k-1)对应的covariance,P(k-1|k-1)是X(k-1|k-1)对应的covariance,A’ 表示A的转置矩阵,Q是系统过程的covariance。式子1,2就是卡尔曼滤波器5个公式当中的前两个,也就是对系统的预测。
现在我们有了现在状态的预测结果,然后我们再收集现在状态的测量值。结合预测值和测量值,我们可以得到现在状态(k)的最优化估算值X(k|k):X(k|k)=X(k|k-1)+Kg(k)(Z(k)-HX(k|k-1)) (3)
其中Kg为卡尔曼增益(KalmanGain):Kg(k)=P(k|k-1)H’/(HP(k|k-1)H’+R) (4)
到现在为止,我们已经得到了k状态下最优的估算值X(k|k)。但是为了要另卡尔曼滤波器不断的运行下去直到系统过程结束,我们还要更新k状态下X(k|k)的covariance:
P(k|k)=(I-Kg(k)H)P(k|k-1) (5)
其中I为1的矩阵,对于单模型单测量,I=1。当系统进入k+1状态时,P(k|k)就是式子(2)的P(k-1|k-1)。这样,算法就可以自回归的运算下去。
卡尔曼滤波器的原理基本描述了,式子1,2,3,4和5就是他的5个基本公式。根据这5个公式,可以很容易的实现计算机的程序。
下面,我会用程序举一个实际运行的例子。。。
4.简单例子
(ASimpleExample)
这里我们结合第二第三节,举一个非常简单的例子来说明卡尔曼滤波器的工作过程。所举的例子是进一步描述第二节的例子,而且还会配以程序模拟结果。
根据第二节的描述,把房间看成一个系统,然后对这个系统建模。当然,我们建的模型不需要非常地精确。我们所知道的这个房间的温度是跟前一时刻的温度相同的,所以A=1。没有控制量,所以U(k)=0。因此得出:
X(k|k-1)=X(k-1|k-1)………(6)
式子(2)可以改成:
P(k|k-1)=P(k-1|k-1)+Q………(7)
因为测量的值是温度计的,跟温度直接对应,所以H=1。式子3,4,5可以改成以下:
X(k|k)=X(k|k-1)+Kg(k)(Z(k)-X(k|k-1))………(8)
Kg(k)=P(k|k-1)/(P(k|k-1)+R)………(9)
P(k|k)=(1-Kg(k))P(k|k-1)„„„(10)
现在我们模拟一组测量值作为输入。假设房间的真实温度为25度,我模拟了200个测量值,这些测量值的平均值为25度,但是加入了标准偏差为几度的高斯白噪声(在图中为蓝线)。
为了令卡尔曼滤波器开始工作,我们需要告诉卡尔曼两个零时刻的初始值,是X(0|0)和P(0|0)。他们的值不用太在意,随便给一个就可以了,因为随着卡尔曼的工作,X会逐渐的收敛。但是对于P,一般不要取0,因为这样可能会令卡尔曼完全相信你给定的X(0|0)是系统最优的,从而使算法不能收敛。我选了X(0|0)=1度,P(0|0)=10。
该系统的真实温度为25度,图中用黑线表示。图中红线是卡尔曼滤波器输出的最优化结果(该结果在算法中设置了Q=1e-6,R=1e-1)。
% 附matlab下面的kalman滤波程序:
clear
N=200;
w(1)=0;
w=randn(1,N) %产生一个均值为0,方差为1的1*n维向量(白噪声、正态分布而非均匀分布)
x(1)=0;
a=1;%即A
for k=2:N; %FOR
x(k)=a*x(k-1)+w(k-1); %200个X(k)赋值,初始值?
end %END
V=randn(1,N);
q1=std(V); %标准差
Rvv=q1.^2;
q2=std(x);
Rxx=q2.^2;
q3=std(w);
Rww=q3.^2;
c=0.2;
Y=c*x+V;
p(1)=0;
s(1)=0;
for t=2:N; %FOR
p1(t)=a.^2*p(t-1)+Rww;
b(t)=c*p1(t)/(c.^2*p1(t)+Rvv); %增益?
s(t)=a*s(t-1)+b(t)*(Y(t)-a*c*s(t-1)); %结果?
p(t)=p1(t)-c*b(t)*p1(t);
end %END
t=1:N; %循环?
plot(t,s,'r',t,Y,'g',t,x,'b'); %RGB? s,Y,x都是向量
卡尔曼滤波Matlab简单实现
1.离散时间线性动态系统的状态方程
线性系统采用状态方程、观测方程及其初始条件来描述。线性离散时间系统的一般状态方程可描述为
 其中,X(k) 是 k 时刻目标的状态向量,V(k)是过程噪声,它是具有均值为零、方差矩阵为 Q(k) 的高斯噪声向量,即
其中,X(k) 是 k 时刻目标的状态向量,V(k)是过程噪声,它是具有均值为零、方差矩阵为 Q(k) 的高斯噪声向量,即

Q(k)是状态转移矩阵, G(k)是过程噪声增益矩阵。
2.传感器的测量(观测)方程
传感器的通用观测方程为

这里, Z(k+1)是传感器在 k+1 时刻的观测向量,观测噪声 W(k+1) 是具有零均值和正定协方差矩阵 R(k+1) 的高斯分布测量噪声向量,即

3.初始状态的描述
初始状态 X(0) 是高斯的,具有均值 X(0|0) 和协方差 ,即

4.Kalman滤波算法
状态估计的一步预测方程为

一步预测的协方差为

预测的观测向量为

观测向量的预测误差协方差为

新息或量测残差为

滤波器增益为
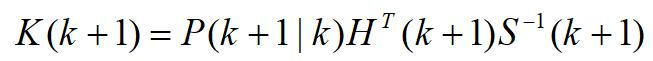
Kalman滤波算法的状态更新方程为
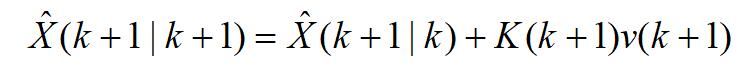
滤波误差协方差的更新方程为
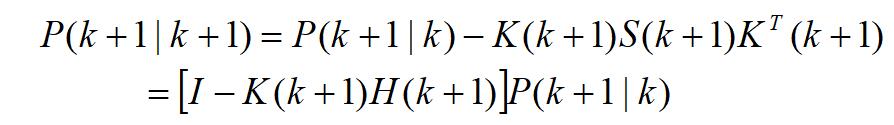
clear all;
% Kalman滤波技术
A=1; % 状态转移矩阵 Φ(k)
H=0.2; % 观测矩阵 H(k)
X(1)=0; % 目标的状态向量 X(k)
% V(1)=0; % 过程噪声 V(k)
Y(1)=1; % 一步预测x(k)的更新 X(k+1|k+1)
P(1)=10; % 一步预测的协方差 P(k)
N=200;
V=randn(1,N); % 模拟产生过程噪声(高斯分布的随机噪声)
w=randn(1,N); % 模拟产生测量噪声
for k=2:N
X(k) = A * X(k-1)+V(k-1); % 状态方程:X(k+1)=Φ(k)X(k)+G(k)V(k),其中G(k)=1
end
Q=std(V)^2; % W(k)的协方差,std()函数用于计算标准偏差
R=std(w)^2; % V(k)的协方差 covariance
Z=H*X+w; % 观测方程:Z(k+1)=H(k+1)X(k+1)+W(k+1),Z(k+1)是k+1时刻的观测值
for t=2:N
P(t) = A * P(t-1)+Q; % 一步预测的协方差 P(k+1|k)
S(t) = H.^2 * P(t)+R; % 观测向量的预测误差协方差 S(k+1)
K(t) = H * P(t)/S(t); % 卡尔曼滤波器增益 K(k+1)
v(t) = Z(t) - ( A * H * Y(t-1) ); % 新息/量测残差 v(k+1)
Y(t)=A * Y(t-1) + K(t) * v(t); % 状态更新方程 X(k+1|k+1)=X(k+1|k)+K(k+1)*v(k+1)
P(t)=(1-H * K(t)) * P(t); % 误差协方差的更新方程: P(k+1|k+1)=(I-K(k+1)*H(k+1))*P(k+1|k)
end
t=1:N;
plot(t,Y,'r',t,Z,'g',t,X,'b'); % 红色线最优化估算结果滤波后的值,%绿色线观测值,蓝色线预测值
legend('Kalman滤波结果','观测值','预测值');

扩展卡尔曼滤波EKF及其MATLAB实现
卡尔曼是真的强,我只能这么说,前面说了卡尔曼滤波,它是针对线性系统的滤波方法。但在实际工作中,我们的系统几乎都是非线性的,所以如何解决非线性系统 的滤波问题呢,这就是我们要讲的EKF(扩展卡尔曼滤波),它的原理很简单,就是在估计状态的地方进行线性化,线性化的方法也很简单,只需要进行泰勒的一 阶展开就行。当然我们也要说一下缺点,因为我们选择的线性化方法,所以只能达到二阶的精度(UKF可以达到四阶的精度),所以要求我们的系统是弱线性化 的。其实UKF也是对非线性系统的卡尔曼滤波,主要本人对其线性化方法(UT变换)不是很理解,等考完试再说。
首先,系统的状态方程和观测方程如下:
我们知道,在更新误差协方差矩阵的时候,不能直接用f和h的,所以我们要进行泰勒展开,也就是要求雅克比矩阵。再利用线性情况下的卡尔曼滤波进行计算更新。
预测:
利用雅克比矩阵进行更新模型:
更新:![]()
![]()
![]()
![]()
下面我会展示一个目标追踪的EKF例子:






%%
%扩展Kalman滤波在目标跟踪中的应用
%function EKF_For_TargetTracking
clc;clear;
T=1;%雷达扫描周期
N=60/T;%总的采样次数
X=zeros(4,N);%目标真实位置、速度
X(:,1)=[-100,2,200,20];%目标初始位置、速度
Z=zeros(1,N);%传感器对位置的观测
delta_w=1e-3;%如果增大这个参数,目标的真实轨迹就是曲线了
Q=delta_w*diag([0.5,1]);%过程噪声方差
G=[T^2/2,0;T,0;0,T^2/2;0,T];%过程噪声驱动矩阵
R=5;%观测噪声方差
F=[1,T,0,0;0,1,0,0;0,0,1,T;0,0,0,1];%状态转移矩阵
x0=200;%观测站的位置
y0=300;
Xstation=[x0,y0];
for t=2:N
X(:,t)=F*X(:,t-1)+G*sqrtm(Q)*randn(2,1);%目标真实轨迹
end
for t=1:N
Z(t)=Dist(X(:,t),Xstation)+sqrtm(R)*randn;%观测值
end
%EKF
Xekf=zeros(4,N);
Xekf(:,1)=X(:,1);%Kalman滤波的状态初始化
P0=eye(4);%误差协方差矩阵的初始化
for i=2:N
Xn=F*Xekf(:,i-1);%一步预测
P1=F*P0*F'+G*Q*G';%预测误差协方差
dd=Dist(Xn,Xstation);%观测预测
%求解雅克比矩阵H
H=[(Xn(1,1)-x0)/dd,0,(Xn(3,1)-y0)/dd,0];%泰勒展开的一阶近似
K=P1*H'*inv(H*P1*H'+R);%卡尔曼最优增益
Xekf(:,i)=Xn+K*(Z(:,i)-dd);%状态更新
P0=(eye(4)-K*H)*P1;%滤波误差协方差更新
end
%误差分析
for i=1:N
Err_KalmanFilter(i)=Dist(X(:,i),Xekf(:,i));%
end
%画图
figure
hold on;box on;
plot(X(1,:),X(3,:),'-k');%真实轨迹
plot(Xekf(1,:),Xekf(3,:),'-r');%扩展Kalman滤波轨迹
legend(' real trajectory','EKF trajectory');
xlabel('X-axis X/m');
ylabel('Y-axis Y/m');
figure
hold on ;box on;
plot(Err_KalmanFilter,'-ks','MarkerFace','r')
xlabel('Time /s');
ylabel('Position estimation bias /m');
%子函数 求欧氏距离
function d=Dist(X1,X2);
if length(X2)<=2
d=sqrt((X1(1)-X2(1))^2+(X1(3)-X2(2))^2);
else
d=sqrt((X1(1)-X2(1))^2+(X1(3)-X2(3))^2);
end
end

卡尔曼滤波的数学原理当然是它最美妙的部分,不过据说挺难看懂的,我也就知难而退了,毕竟在程序中实现好像不需要非常理解其数学原理。有两篇英文博客写得不错,比较生动形象地描述了这个滤波器的工作过程,建议阅读:
一、最后一点点数学
为了不让实现滤波器的代码显得突兀,这里还是留下几个最最不可或缺的方程。实在心急,可以直接跳过这一部分。
(要找OC代码的朋友请不要一并跳过第二部分,那里讲到了参数设置)
- 被观测的系统
首先我们需要用方程来描述被观测的系统,因为后面滤波器的方程要用到这里的一些参数。卡尔曼滤波器适用于线性系统,设该系统的状态方程和观测方程为:
x(k) = A · x(k-1) + B · u(k) + w(k)
z(k) = H · x(k) + y(k)
x(k) —— k时刻系统的状态
u(k) —— 控制量
w(k) —— 符合高斯分布的过程噪声,其协方差在下文中为Q
z(k) —— k时刻系统的观测值
y(k) —— 符合高斯分布的测量噪声,其协方差在下文中为R
A、B、H —— 系统参数,多输入多输出时为矩阵,单输入单输出时就是几个常数
注意在后面滤波器的方程中我们将不会再直接面对两个噪声w(k)和y(k),而是用到他们的协方差Q和R。至此,A、B、H、Q、R这几个参数都由被观测的系统本身和测量过程中的噪声确定了。
- 滤波器
工程中用到的卡尔曼滤波是一个迭代的过程,每得到一个新的观测值迭代一次,来回来去地更新两个东西:“系统状态”(x)和“误差协方差”(P)。由于每次迭代只用到上一次迭代的结果和新的测量值,这样滤波对计算资源的占用是很小的。
每一次迭代,两个步骤:预测和修正。预测是根据前一时刻迭代的结果,即x(k-1|k-1)和P(k-1|k-1),来预测这一时刻的系统状态和误差协方差,得到x(k|k-1)和P(k|k-1):
x(k|k-1) = A · x(k-1|k-1) + B · u(k)
P(k|k-1) = A · P(k-1|k-1) · AT + Q
(这里用到的A、B、H、Q、R就是从前面的状态/观测方程中拿来的)
然后计算卡尔曼增益K(k),和这一次的实际测量结果z(k)一起,用于修正系统状态x(k|k-1)及误差协方差P(k|k-1),得到最新的x(k|k)和P(k|k):
K(k) = P(k|k-1) · HT · (H · P(k|k-1) · HT + R)-1
x(k|k) = x(k|k-1) + K(k) · (z(k) - H · x(k|k-1))
P(k|k) = (I - K(k) · H) · P(k|k-1)
好了好了不会有新的公式了。至此这次迭代就算结束了,x(k|k)就是我们要的滤波后的值,它和P(k|k)将会作为x(k-1|k-1)和P(k-1|k-1)用在下一时刻的迭代里。别看现在公式还是一大堆,在我们所谓的“简单场景”下,系统参数一定下来,就能简化很多很多。
先看状态方程和观测方程。假设我们是在测温度、加速度或者记录蓝牙RSSI,此时控制量是没有的,即:
B · u(k) ≡ 0
另外,参数A和H也简单地取1。现在滤波器的预测方程简化为:
① x(k|k-1) = x(k-1|k-1)
② P(k|k-1) = P(k-1|k-1) + Q
同时修正方程变成:
③ K(k) = P(k|k-1) / (P(k|k-1) + R)
④ x(k|k) = x(k|k-1) + K(k) · (z(k) - x(k|k-1))
⑤ P(k|k) = (1 - K(k)) · P(k|k-1)
①对②、③无影响,于是④可以写成:
x(k|k) = x(k-1|k-1) + K(k) · (z(k) - x(k-1|k-1))
在程序中,该式写起来更简单:
x = x + K * (新观测值 - x);
观察②,对这一时刻的预测值不就是上一时刻的修正值+Q嘛,不妨把它合并到上一次迭代中,即⑤改写成:
P(k+1|k) = (1 - K(k)) · P(k|k-1) + Q
这一时刻的P(k+1|k),会作为下一时刻的P(k|k-1),刚好是③需要的。于是整个滤波过程只用这三个式子来迭代即可:
K(k) = P(k|k-1) / (P(k|k-1) + R)
x(k|k) = x(k-1|k-1) + K(k) · (z(k) - x(k-1|k-1))
P(k+1|k) = (1 - K(k)) · P(k|k-1) + Q
二、Matlab实现 & 参数设置
经过前面的推导,我们发现在程序中只需要不断重复这一小段即可实现卡尔曼滤波:
while(新观测值)
{
K = P / (P + R);
x = x + K * (新观测值 - x);
P = (1 - K) · P + Q;
}
没看前面推导的朋友们别担心。现在我们只从程序的角度来看,不管物理意义。只要定好参数、赋好初值,它就能好好迭代下去。我们发现这一堆字母中,x和P只需要赋初值,每次迭代会产生新值;K用不着赋初值;Q和R赋值以后在之后的迭代中也可以改。
好消息是,x和P的初值是可以随便设的,强大的卡尔曼滤波器马上就能抹除不合理之处。但需注意,P的初值不能为0,否则滤波器会认为已经没有误差了,不玩儿了,看下图——

只要P(0) ≠ 0,一切都好。
剩下的也就是Q和R了。他俩的物理意义是噪声的协方差,他们的值是需要我们试出来的。举个例子,我们仍用上图的数据——

减小R值以后,滤波效果就没有这么明显了。但这并不意味着R值越大越好,因为我们的数据也可能是这样:

右图中增大了R值以后,虽然滤波结果更平滑,但滤波器会变得不敏感,会有滞后。因此应该根据具体的使用场景收集到的数据来决定Q和R的取值。他俩的取值当然也可以是时变的,可以识别跳变,可以自适应……这些就是高端玩法了,这里不做讨论。
至此,所有准备工作就做完了。Matlab代码也很简单:
% kalman_filter.m
function X = kalman_filter(data,Q,R,x0,P0)
N = length(data);
K = zeros(N,1);
X = zeros(N,1);
P = zeros(N,1);
X(1) = x0;
P(1) = P0;
for i = 2:N
K(i) = P(i-1) / (P(i-1) + R);
X(i) = X(i-1) + K(i) * (data(i) - X(i-1));
P(i) = P(i-1) - K(i) * P(i-1) + Q;
end
调用及作图:
% test.m
clear;
data = [-59,-60,-55,-56,-56,-56,-57,-57,-59,-61,-57,-57,-57,-57,-57,-58,-57,-61,-57,-61,-59,-61,-60,-60,-59,-57,-56,-58,-58,-57,-57,-57,-57,-57,-60,-58,-61,-60,-60,-60,-57,-57,-57,-57,-58,-57,-58,-57,-58,-57,-58,-61,-58,-61,-62,-61,-61,-57,-57,-57,-57,-58,-57,-58,-57,-58,-61,-61,-60,-60,-58,-57,-57,-57,-57,-58,-58,-58,-58,-60,-61,-60,-57,-57,-57,-57,-57,-58,-58,-57,-57,-57,-60,-57,-60,-60,-59,-60,-57,-56]';
result = kalman_filter(data,1e-6,4e-4,-60,1);
i = 1:length(data);
plot(i,result,'r',i,data,'b');
做平面定位的时候可能需要滤x轴和y轴的数据,加速度计还可能有z轴数据。Matlab里面可以很方便地把A、B、H、Q、R变成矩阵,一次性把几个数据同时滤了;但实质上当这些数据互相之间没什么影响时,同时滤和分开滤是一毛一样的,所以上面的代码都可以不改,几个轴的数据分别调用滤波函数就是了。















 4854
4854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









