







前言
VLN和VDN的区别:
(1)VLN的语言指令清楚地描述了代理实现目标所需的步骤,而NDH代理则得到了一个模糊的提示,需要探索和对话来解决;
(2)VLN的轨迹是连续的,而由每个对话的子轨迹组成的NDH轨迹是分层的。
目前视觉对话导航存在的问题:
(1)仅使用低级视觉特征使代理模型很难在看不见的环境(即未在训练中使用的环境)中泛化;
(2)仅使用高级视觉特征的模型在看不见的环境中表现更好,然而,这些模型在可见环境中的性能显著下降,这意味着这些模型无法完全理解和记忆可见环境。
本文的主要贡献:
(1)用不同类型的高级语义特征替换了只使用低级视觉特征;
(2)研究了三种高级语义特征:ImageNet分类概率、检测到的对象区域和语义分割结果。
一、模型主要框架
1.1 任务描述
视觉对话任务由一个指令开始,后续代理和人类交流对话,然后逐步完成导航任务。
假设总共有 轮对话。在第
轮对话中:
(1)模型的输入:目标 ,历史对话
,其中
,表示代理的问题和人类回复的答案,当前时间步
时的全景视图划分成的图像块集合
,其中
;
(2)模型的输出:预测的动作A。
最后,形成一个序列。
1.2 模型介绍
模型的整体框架如下图所示:
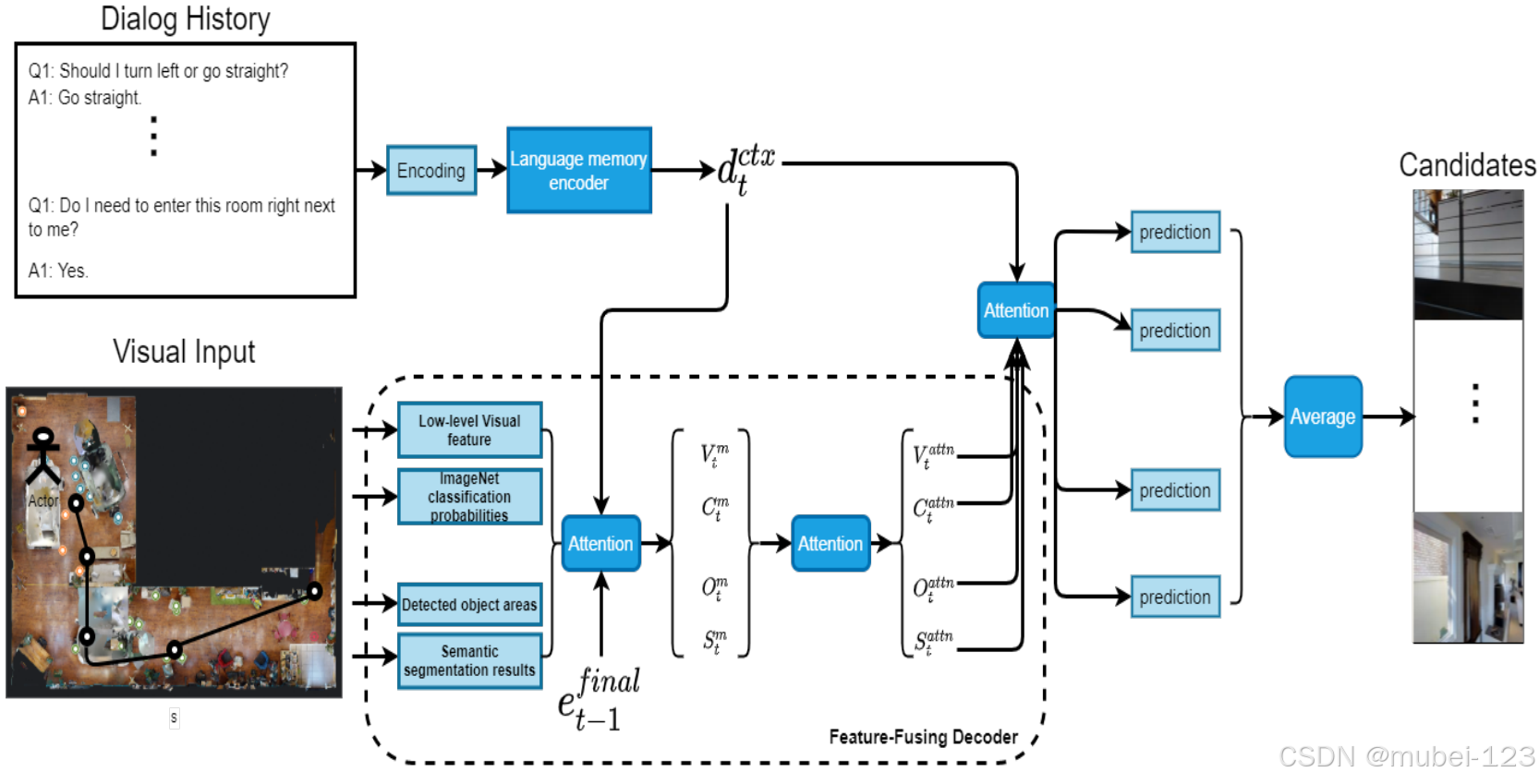
可以看出,主要由以下几部分组成:
(1)语言记忆编码器:提取历史对话和当前对话之间的相关性;
(2)特征融合解码器:得到四种视觉特征分别与最终编码和文本特征之间的注意力;
(3)决策制定模块:分别计算四种视觉特征的隐藏状态(通过LSTM实现)与文本特征之间的注意力,再得到四个预测值,平均后作为最终预测动作的输出分布。
二、 难点
3.1 语言记忆编码器
首先,得到当前对话的文本特征:
(1)将当前对话表示成嵌入
,其中
是当前第
轮对话的token数;
(2)将嵌入通过一个LSTM,得到隐藏状态;
(3)将最有一个隐藏状态 作为当前对话的文本特征,即
;
同理,可以得到历史对话的文本特征
。
得到当前对话和历史对话的特征后,接下来计算两者的相关性,主要过程如下:
(1)使用多头注意力来计算当前对话和各个历史对话之间的缩放点积注意力,计算完后进行concat连接;
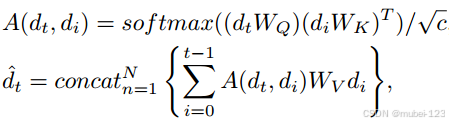
(2)残差连接+层归一化;
![]()
(3)2层非线性多头感知器+残差连接+层归一化;
![]()
(4)concat连接;
![]()
最终,得到文本表示 。
2.2 特征融合解码器
本工作使用四种视觉特征:
(1)低级是视觉特征:经过常规的神经网络处理后的特征图;
(2)图像分类特征:从ResNet-152的冻结1000路分类层中提取ImageNet分类概率,并将概率作为视觉特征;
(3)区域检测特征:使用Faster RCNN,将每个检测到的对象的置信度和区域的加权求和作为视觉特征;
(4)语义分割特征:每个场景的语义分割信息都来自Matterport3D数据集。没有直接使用语义图,而是将特征设计为每个图像中语义类的区域,得到视觉特征。
特征融合解码器旨在提取对话和视觉输入之间的相关性,并更好地融合不同的模态特征。其主要的步骤如下:
(1)获取第 步的最终编码
;
(2)分别计算与四种视觉特征的注意力,得到
;
(3)分别计算与
的注意力,得到
。
2.3 决策制定模块
主要步骤如下:
(1)将使用LSTM生成隐藏状态,然后分别与
计算注意力,得到各自的编码,以
举例:
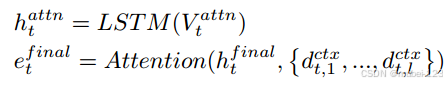
其中 是文本表示
的长度;
(2)将的编码各自通过一个两层的线性变换器,得到一个预测值,以
的
举例:
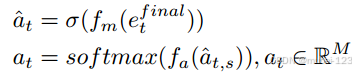
总共得到四个预测值,平均后作为最终预测动作的输出分布。
三、总结
(1)Seq2Seq和VLN Baseline两种方法有什么不同之处?
(2)最近,越来越多的研究发现,不恰当地使用视觉特征可能会损害模型在视觉和语言体现任务中的性能;
(3)目标检测提供了更多的局部语义信息,语义分割提供了更多的全局语义信息。两者对于理解环境都是不可或缺的。

















 912
912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









