











1.摘要
路径规划是无人机(UAV)任务执行的核心,因为它决定了无人机完成任务所需的飞行路径。为了解决这一问题,本文提出了一种基于导航变量的多目标粒子群算法(NMOPSO)。NMOPSO采用了基于导航变量的路径表示方法,这不仅能够考虑运动学约束,还能充分利用无人机的机动性。此外,算法引入了自适应变异机制,以提高粒子群的多样性,从而优化解的质量。
2.运动学模型和约束
将无人机视为在环境中移动的一个点,其运动学方程描述如下:
{
x
˙
=
V
cos
α
cos
β
y
˙
=
V
cos
α
sin
β
,
z
˙
=
V
sin
α
\begin{cases} \dot{x}=V\cos\alpha\cos\beta \\ \dot{y}=V\cos\alpha\sin\beta, \\ \dot{z}=V\sin\alpha & \end{cases}
⎩
⎨
⎧x˙=Vcosαcosβy˙=Vcosαsinβ,z˙=Vsinα
由于物理限制,无人机的速度和角度受到以下约束:
{
V
min
≤
V
≤
V
max
∣
Δ
α
∣
=
∣
θ
∣
≤
θ
max
∣
Δ
β
∣
=
∣
ψ
∣
≤
ψ
max
,
\left.\left\{ \begin{array} {l}V_{\min}\leq V\leq V_{\max} \\ |\Delta\alpha|=|\theta|\leq\theta_{\max} \\ |\Delta\beta|=|\psi|\leq\psi_{\max} \end{array}\right.\right.,
⎩
⎨
⎧Vmin≤V≤Vmax∣Δα∣=∣θ∣≤θmax∣Δβ∣=∣ψ∣≤ψmax,
3.路径规划目标函数
路径长度成本
F 1 = { 1 − ∥ P i 1 P i n → ∥ ∑ j = 1 n − 1 ∥ P i j P i j + 1 → ∥ , i f ∥ P i j P i , j + 1 → ∥ ≥ R min ∞ , o t h e r w i s e \left.F_1=\left\{ \begin{array} {cc}1-\frac{\left\|\overrightarrow{P_{i1}P_{in}}\right\|}{\sum_{j=1}^{n-1}\left\|\overrightarrow{P_{ij}P_{ij+1}}\right\|}, & \mathrm{if}\left\|\overrightarrow{P_{ij}P_{i,j+1}}\right\|\geq R_{\min} \\ \infty, & \mathrm{otherwise} \end{array}\right.\right. F1=⎩ ⎨ ⎧1−∑j=1n−1 PijPij+1 Pi1Pin ,∞,if PijPi,j+1 ≥Rminotherwise
威胁成本
安全运行目标函数表示为:
F
2
=
1
K
(
n
−
1
)
∑
j
=
1
n
−
1
∑
k
=
1
K
T
k
(
P
i
j
P
i
j
+
1
→
)
,
F_{2}=\frac{1}{K(n-1)}\sum_{j=1}^{n-1}\sum_{k=1}^{K}\mathcal{T}_{k}\left(\overrightarrow{P_{ij}P_{ij+1}}\right),
F2=K(n−1)1j=1∑n−1k=1∑KTk(PijPij+1),
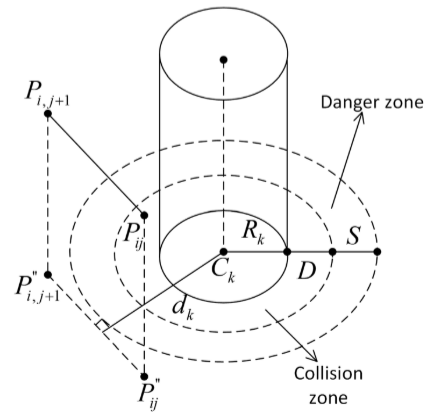
其中,
T
k
(
P
i
j
P
i
j
+
1
→
)
=
{
0
,
if
d
k
≥
D
+
R
k
+
S
1
−
d
k
−
D
−
R
k
S
,
if
D
+
R
k
<
d
k
<
D
+
R
k
+
S
∞
,
otherwise
T_k \left( P_{ij} \overrightarrow{P_{ij+1}} \right) = \begin{cases} 0, & \text{if } d_k \geq D + R_k + S \\ 1 - \frac{d_k - D - R_k}{S}, & \text{if } D + R_k < d_k < D + R_k + S \\ \infty, & \text{otherwise} \end{cases}
Tk(PijPij+1)=⎩
⎨
⎧0,1−Sdk−D−Rk,∞,if dk≥D+Rk+Sif D+Rk<dk<D+Rk+Sotherwise
高度成本
F 3 = 1 n ∑ j = 1 n H i j , F_3=\frac{1}{n}\sum_{j=1}^n\mathcal{H}_{ij}, F3=n1j=1∑nHij,
平滑成本
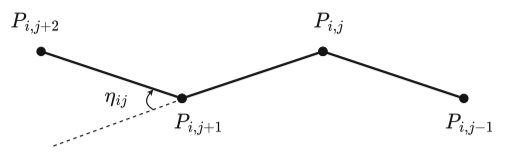
F 4 = 1 n − 2 ∑ j = 1 n − 2 ∣ η i j ∣ π , F_4=\frac{1}{n-2}\sum_{j=1}^{n-2}\frac{\left|\eta_{ij}\right|}{\pi}, F4=n−21j=1∑n−2π∣ηij∣,
3.多目标粒子群算法
在利用粒子群算法进行多目标优化时,控制粒子的分布以使粒子群找到非支配解是很重要的。粒子应该在被称为先导粒子的非主导粒子的引导下进化,在多个势域中扩散。
设
P
P
P是存储库中非支配解的集合。首先建立一个超网格,将
P
P
P中的每个粒子分配到一个超立方体中,上下界为:
G
i
L
=
min
x
∈
P
F
i
(
x
)
−
ϵ
i
G_i^L=\min_{x\in\mathcal{P}}F_i(x)-\epsilon_i
GiL=x∈PminFi(x)−ϵi
G i U = max x ∈ P F i ( x ) + ϵ i G_i^U=\max_{x\in\mathcal{P}}F_i(x)+\epsilon_i GiU=x∈PmaxFi(x)+ϵi
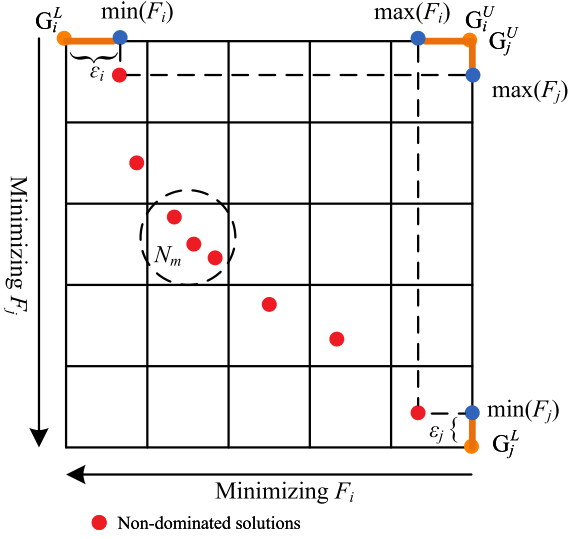
网格长度:
ϵ
i
=
1
2
(
M
−
1
)
(
max
x
∈
P
F
i
(
x
)
−
min
x
∈
P
F
i
(
x
)
)
\epsilon_i=\frac{1}{2(M-1)}\left(\max_{x\in\mathcal{P}}F_i(x)-\min_{x\in\mathcal{P}}F_i(x)\right)
ϵi=2(M−1)1(x∈PmaxFi(x)−x∈PminFi(x))
在
F
i
F_i
Fi维中包含粒子
x
x
x的超立方体的坐标:
c
i
=
⌊
M
F
i
(
x
)
−
G
i
L
G
i
U
−
G
i
L
⌉
c_i=\left\lfloor M\frac{F_i(x)-G_i^L}{G_i^U-G_i^L}\right\rceil
ci=⌊MGiU−GiLFi(x)−GiL⌉
设
N
m
N_m
Nm为位于超立方体
m
m
m中的粒子数,该超立方体的群体测度计算为:
γ
m
=
e
−
κ
N
m
\gamma_m=e^{-\kappa N_m}
γm=e−κNm
从超立方体中选择群体中每个粒子的领导者,选择概率与群体度量成正比:
p
m
=
γ
m
∑
l
=
1
L
γ
l
p_m=\frac{\gamma_m}{\sum_{l=1}^{\mathcal{L}}\gamma_l}
pm=∑l=1Lγlγm
用于粒子位置表示的导航变量:
{
Γ
i
=
(
r
i
1
,
θ
i
1
,
ψ
i
1
,
r
i
2
,
θ
i
2
,
ψ
i
2
,
.
.
.
,
r
i
n
,
θ
i
n
,
ψ
i
n
)
∣
θ
i
j
∣
≤
θ
m
a
x
∀
j
∈
{
1
,
.
.
,
n
}
∣
ψ
i
j
∣
≤
ψ
m
a
x
∀
j
∈
{
1
,
.
.
,
n
}
\left\{ \begin{array} {c}\Gamma_i=(r_{i1},\theta_{i1},\psi_{i1},r_{i2},\theta_{i2},\psi_{i2},...,r_{in},\theta_{in},\psi_{in}) \\ \left|\theta_{ij}\right|\leq\theta_{max}\quad\forall j\in\{1,..,n\} \\ \left|\psi_{ij}\right|\leq\psi_{max}\quad\forall j\in\{1,..,n\} \end{array}\right.
⎩
⎨
⎧Γi=(ri1,θi1,ψi1,ri2,θi2,ψi2,...,rin,θin,ψin)∣θij∣≤θmax∀j∈{1,..,n}∣ψij∣≤ψmax∀j∈{1,..,n}
伪代码

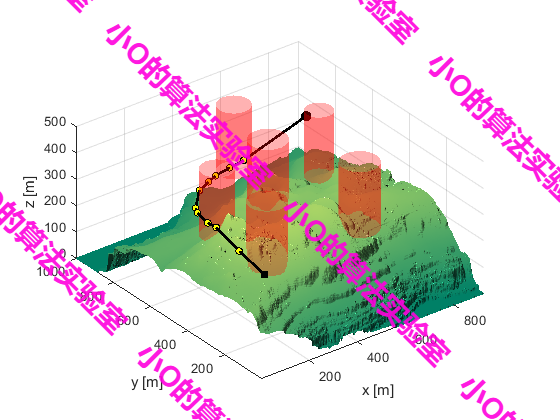
4.结果展示
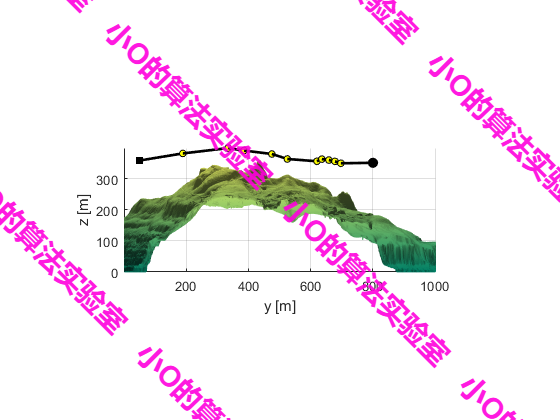
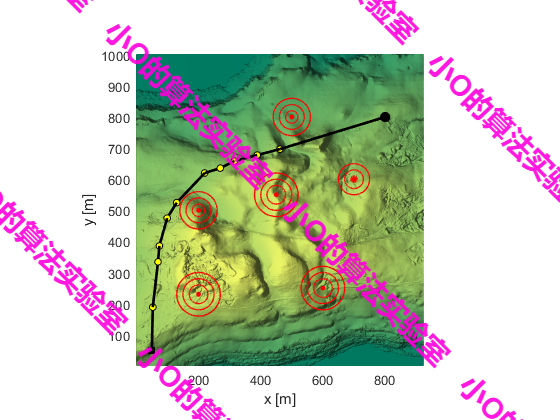
5.参考文献
[1] Duong T T N, Bui D N, Phung M D. Navigation variable-based multi-objective particle swarm optimization for UAV path planning with kinematic constraints[J]. Neural Computing and Applications, 2025: 1-15.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











