






令人兴奋的消息,Meta发布了Lllam3.2系列模型,当前的基准显示,Llama 3.2 在各种基准测试中表现优于 Claude3.5 Haiku 以及 GPT-4o-mini;加上前几天的Qwen2.5,现在开源的模型正在一步步缩小和闭源模型之间的差距,这很棒。
这是他们的第1次开源多模态大模型,总共有4个;其中两个是视觉模型(11B、90B)。90B可能是目前最大的视觉模型了,我记得前面一个比较大的是 Qwen2 VL 72B。
剩下的两个是1B和3B的,这些模型专为边缘计算和移动设备优化,支持 128k 令牌,擅长任务如摘要和遵循指令,针对各种处理器进行了优化。
Llama3.2作为Llama3.1的替代品,它是经过优化的,速度、准确性提高,特别擅长图像标题、视觉问答,甚至图像文本检索。
在这个演示视频中,你可以看到 Llama 3.2 模型能够准确分析和分类收据数据,随后以表格的形式展示结果,这正是 Llama 3.2 真正发光的地方。
轻量级模型(10 亿和 30 亿模型)是专为设备使用场景设计的,这些模型通过剪枝以及不同类型的蒸馏技术创建。剪枝是通过系统地移除网络的一部分来减少模型大小,同时保留性能,它应用于 Llama 3.1 的 180 亿参数模型。
另一种技术蒸馏则涉及从更大模型(如 80 亿和 700 亿参数的 Llama 3.1 系列)向较小模型转移知识,这通过在预训练过程中使用它们的输出作为目标来实现。这一过程将使新的 10 亿和 30 亿参数模型在保持强性能的同时变得更高效、更紧凑,这是 Meta 发布的一项非常酷的策略。
这些模型使开发者能够构建个性化的本地代理应用程序,确保数据始终留在设备上。我认为这是支持工具调用的最小SLLM,这真是很酷。
不同的模型适用于不同的场景,做端侧场景的人可能正在疯狂的搜索这样的小型SOTA模型。
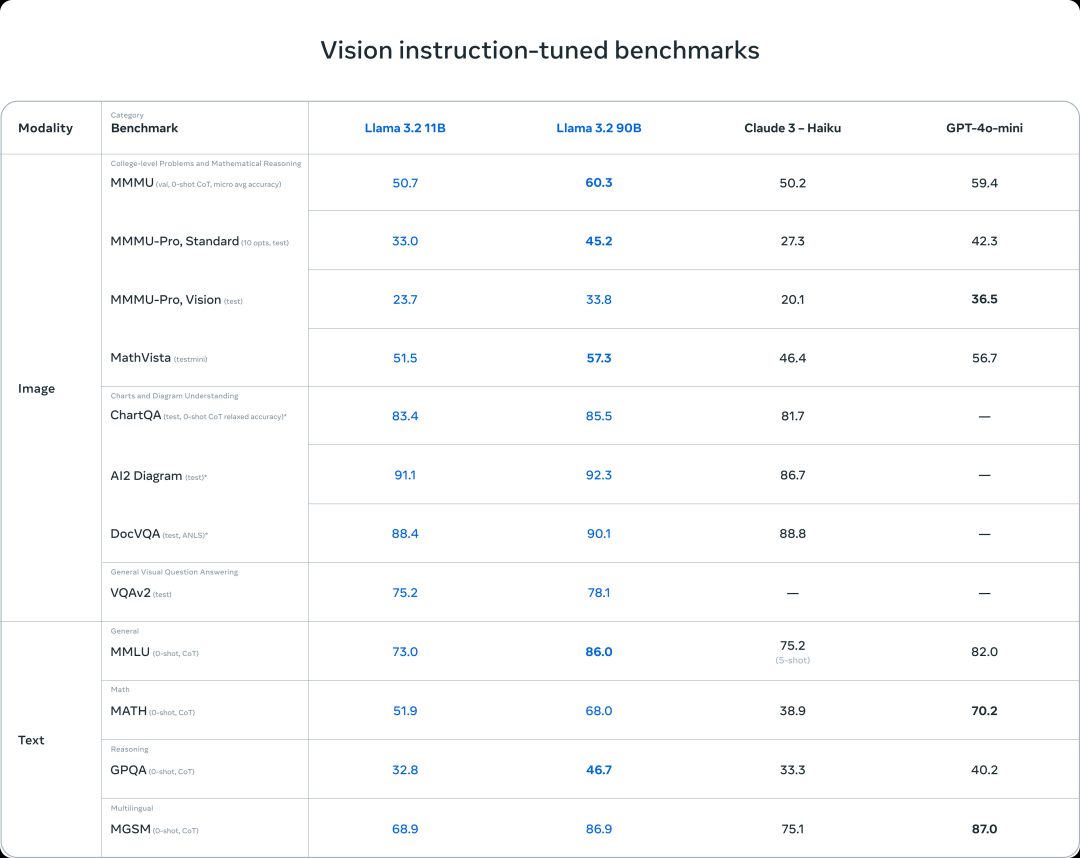
如果我们看看视觉基准,可以看到 11B 模型的表现类似于 Haiku,而 90B 模型的表现则类似于 GPT-4o-mini;他们都支持图像推理用例,比如文档级理解,包括图表和图形、图像标注以及基于自然语言描述精准定位图像中的物体。
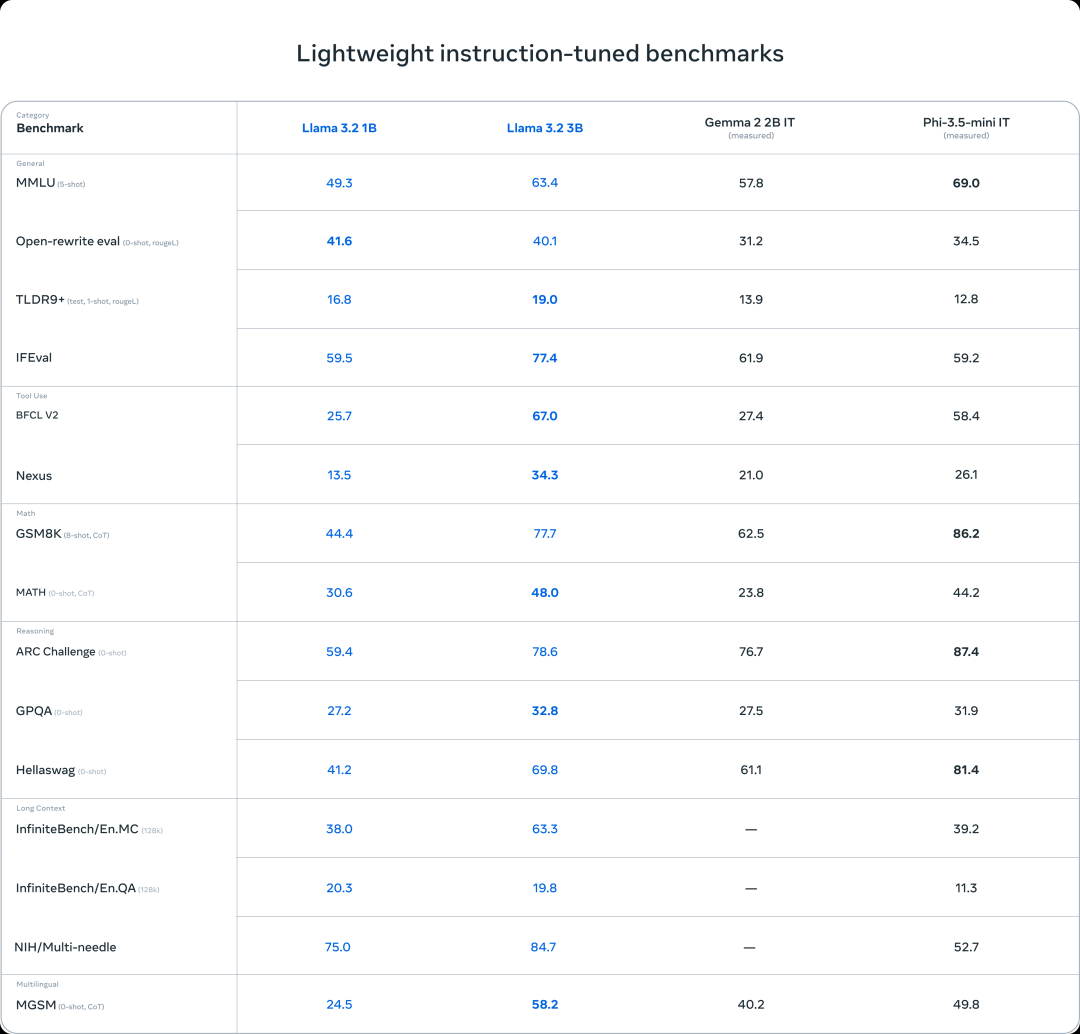
同时,小型模型的表现与 Gemma 2 和 Phi 3.5 相当,没有什么太大的突破。
在他们的一系列分享中,网友热议的亮点包括但不限于:
他们在 Hugging Face 上分享了模型权重,较小的模型也可以在 Ollama 上获得,但视觉模型却没有。不过,这些模型现在可以在 Together AI 上使用,所以我打算通过他们 测试一下,因为他们提供了一些免费积分。让我们开始测试吧。
5片这种产品有多少卡路里 ?(应该是100)
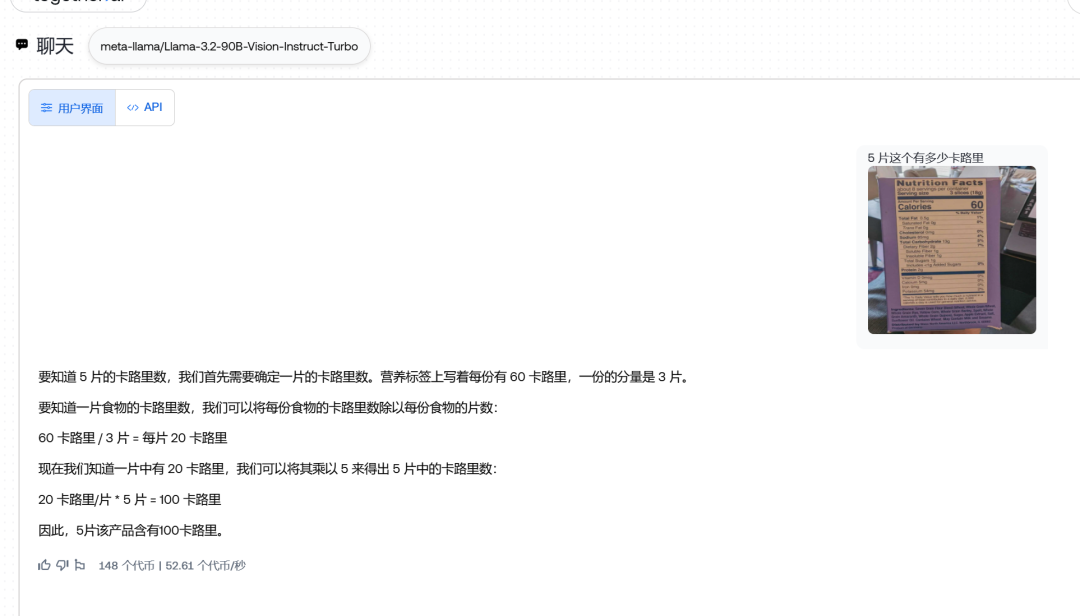
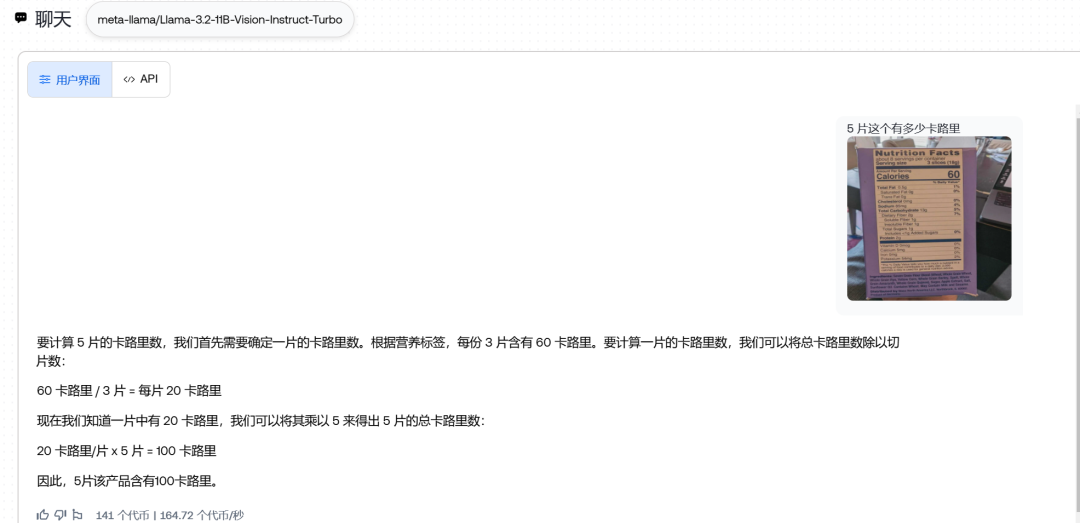
11B、 90B 都通过了,
把上面的第一个基准测试转成csv
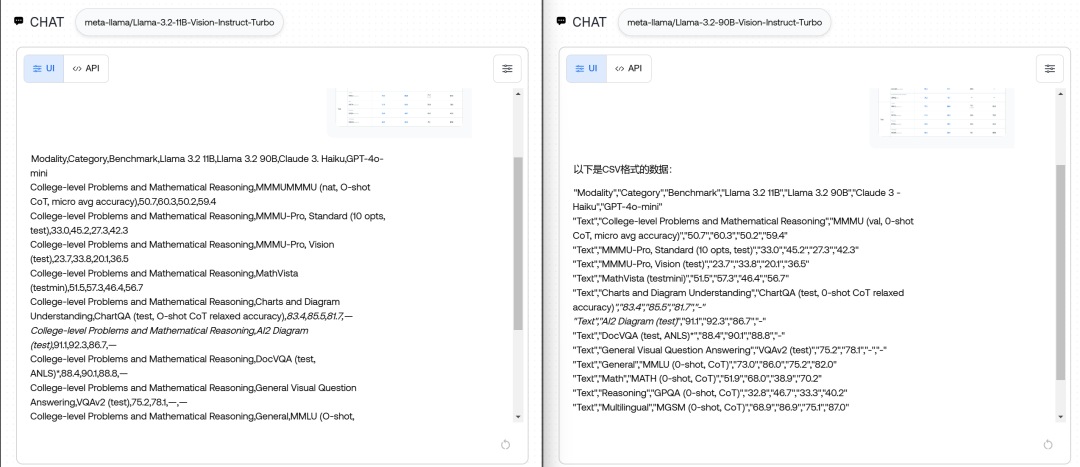
两个模型都做到了,也没有什么数值上的错误
使用HTML,CSS,JS制作一个精确的副本,将所有代码放在一个文件中。
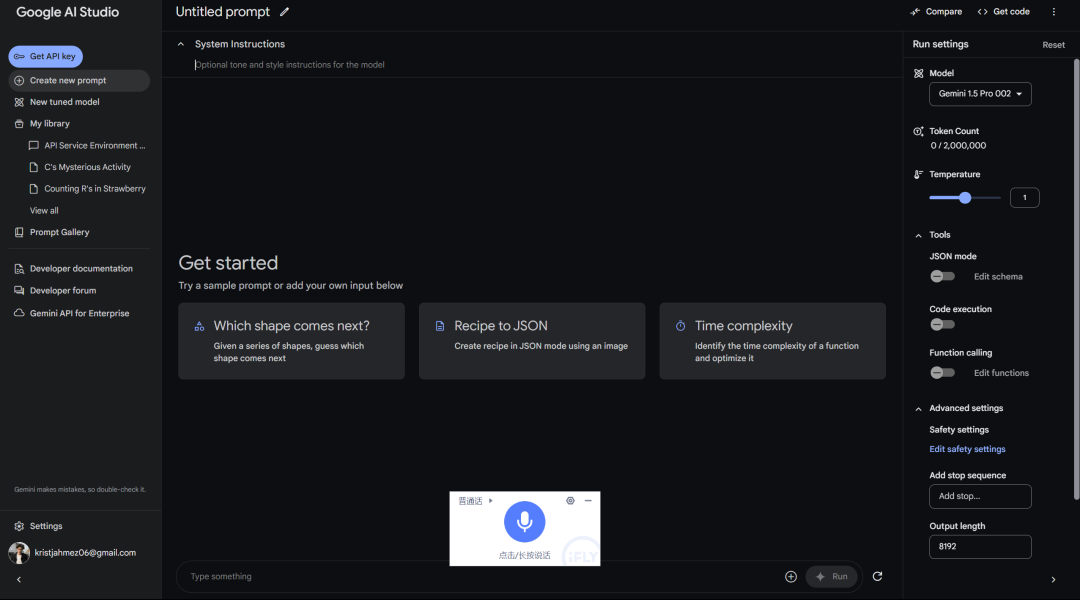
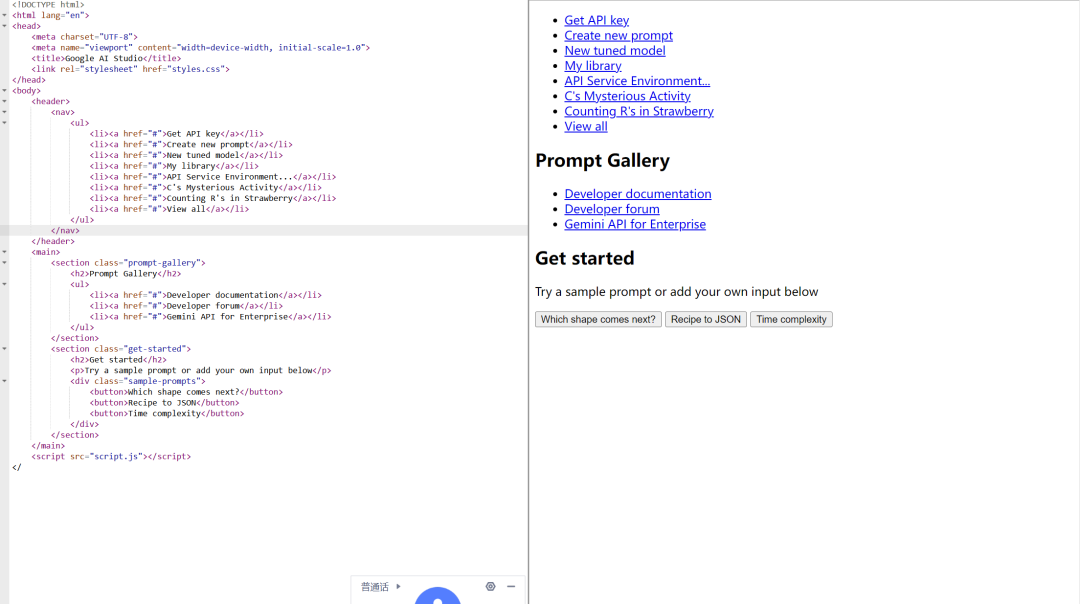
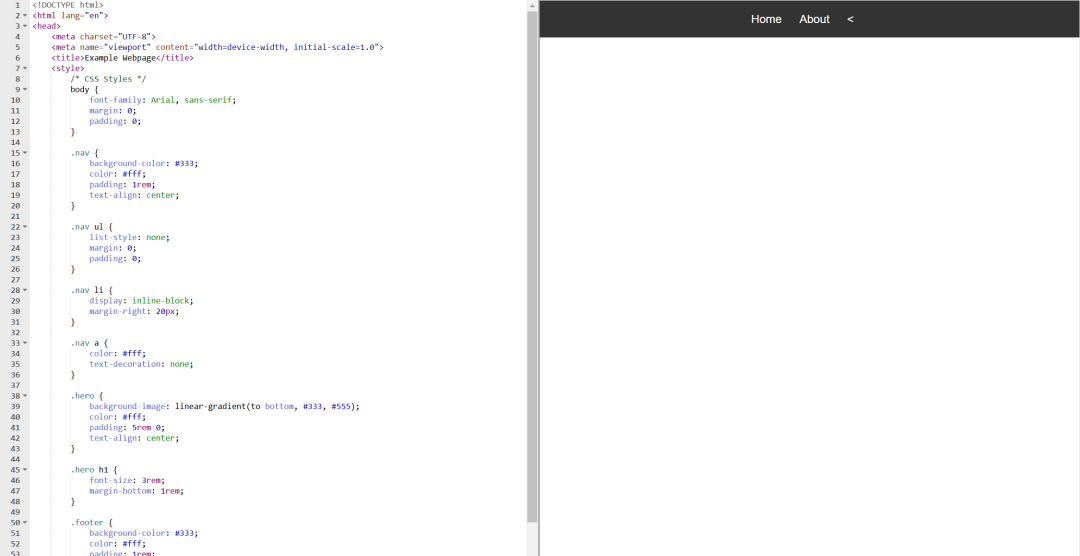
似乎完全不太相似哈,90B(上),11B(下)。
下面这个问题是我新找出来的,没想到 …
图片里有多少种水果?哪种水果最小,哪种水果最酸?它们具体放在哪里?

看90B
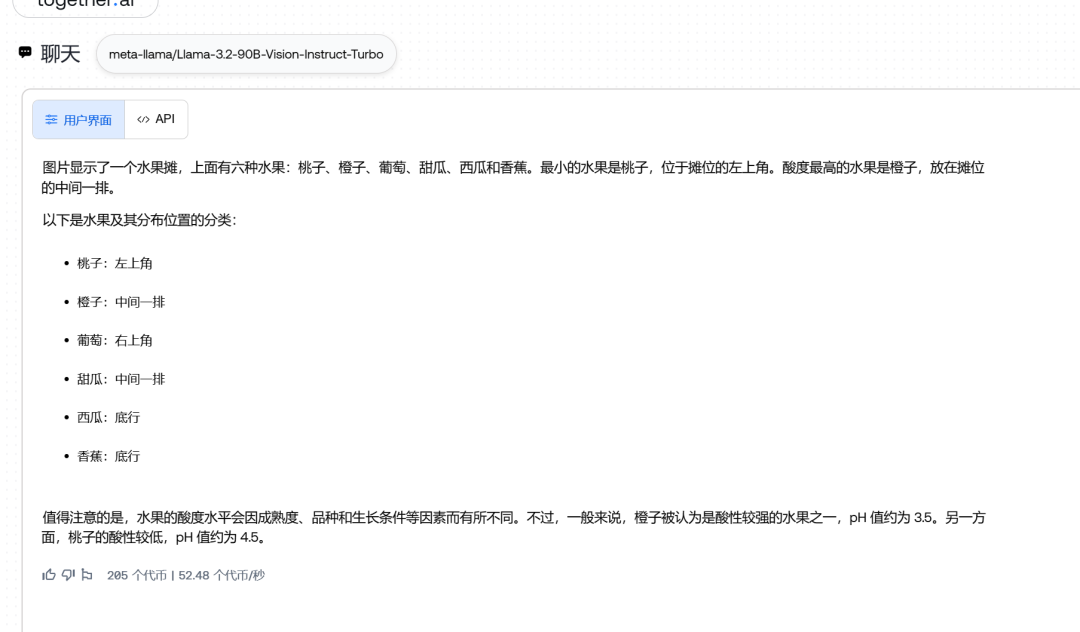
他说只有6种而实际上其实有7种,不过他说的大概位置是对的,只可惜最小的应该是葡萄,最酸的应该是柠檬。
看11B:

够敷衍的,我的天,他答案中是有正确答案的,可惜刚好说反了,而且令人可气的是他说位置都放在木栏里。这这这,你要说他不对吧他好像又对了,但是对又不怎么对,如果你要强行说他聪明:突然我都觉得他已经超越了一个维度,非常圆滑的跳出了这个判域,
诶,难道他不在木篮里吗,你能怎么反驳?hhh
不过我突然不死心了,我又连着测了两轮90B:
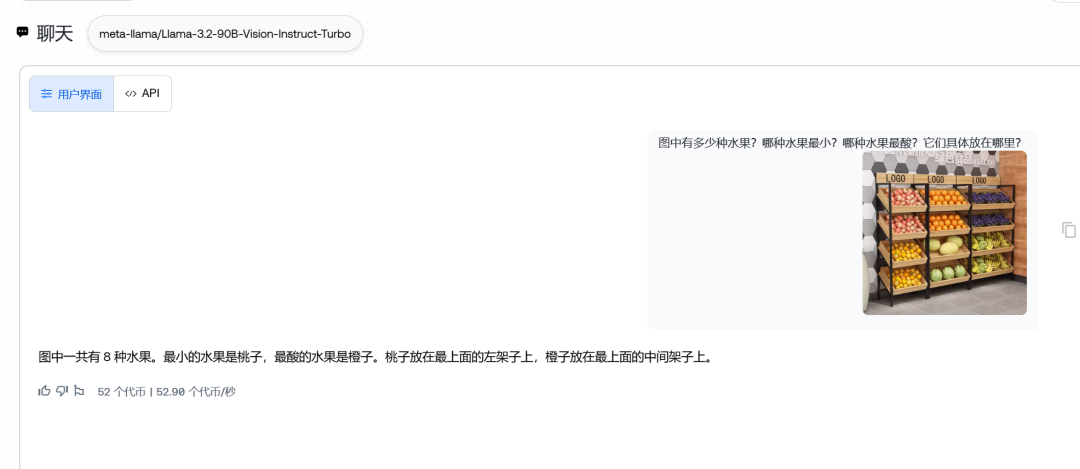
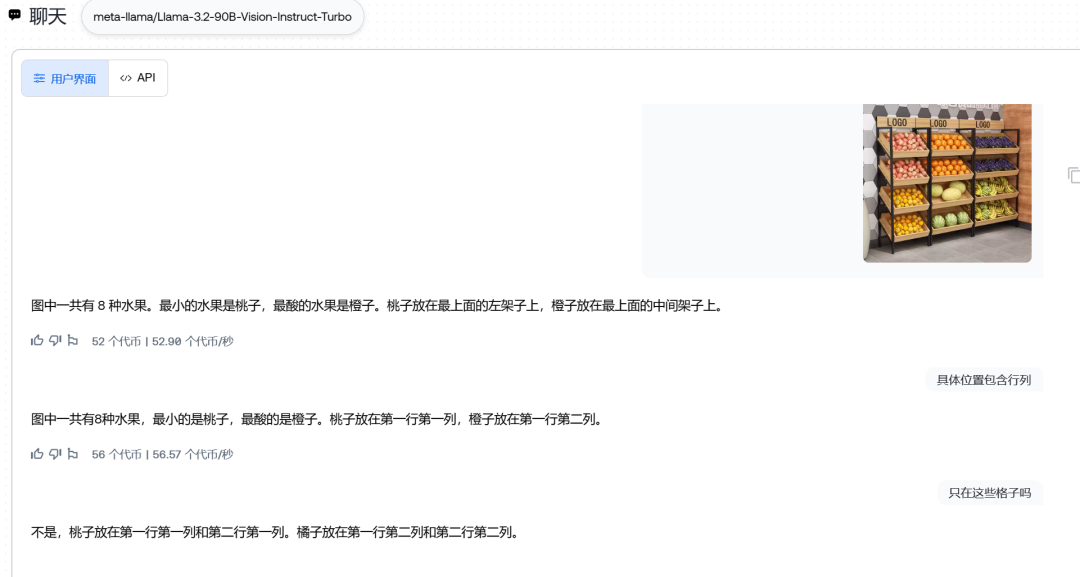
好吧,位置能找到(还能精确到行列数),数量摇摆不定,关于酸度,大小。。。尤其是大小,难道葡萄比较小这个认知都没有吗。
画面中有什么,最引人注目的是什么,它有多少,有什么东西隐藏的东西吗?

90B:
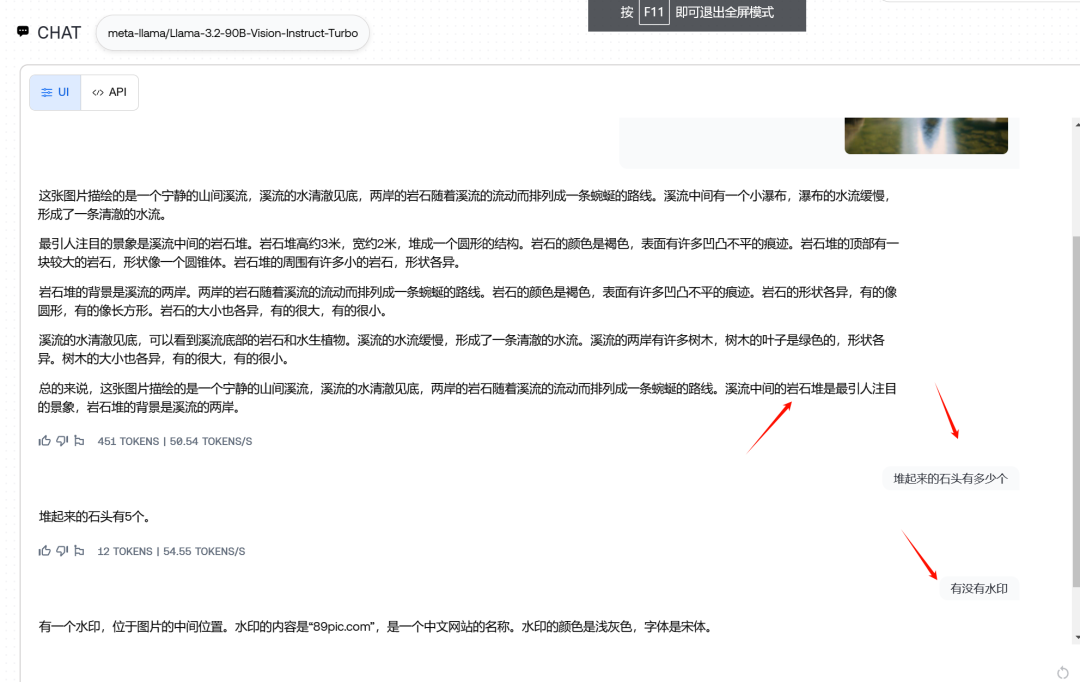
回答的还不错,水印说错了一些,应该是699pic.com,不过那水印人眼也挺难看的。
11B:

水印瞎编的,石头提醒了一次还是多数了一块。
下面:回答图片中的两个问题,
让他“戴”一下人类遇到这些验证码时候的痛苦面具
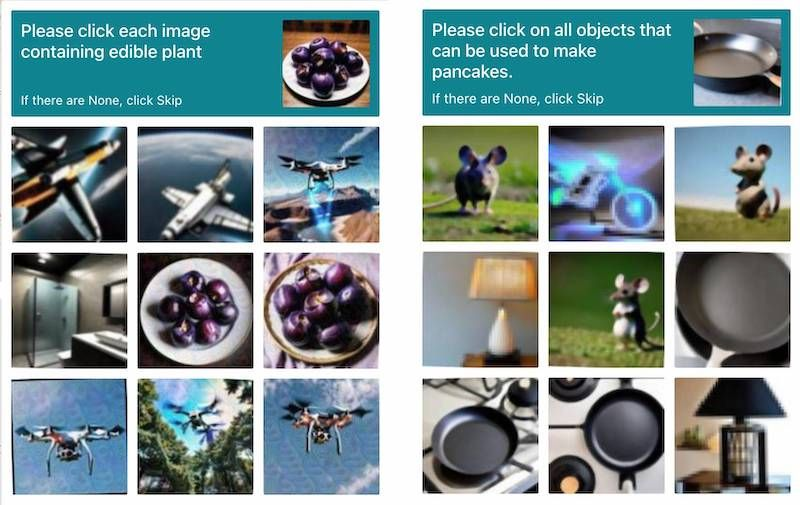
11B
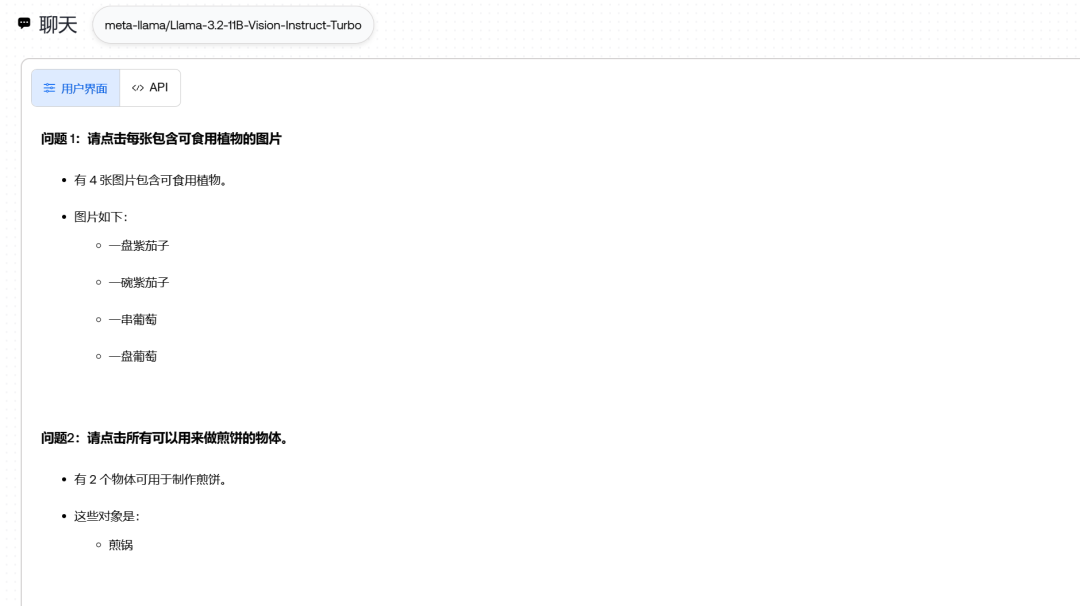
怎么还加了紫茄子,这都分不清吗
90B
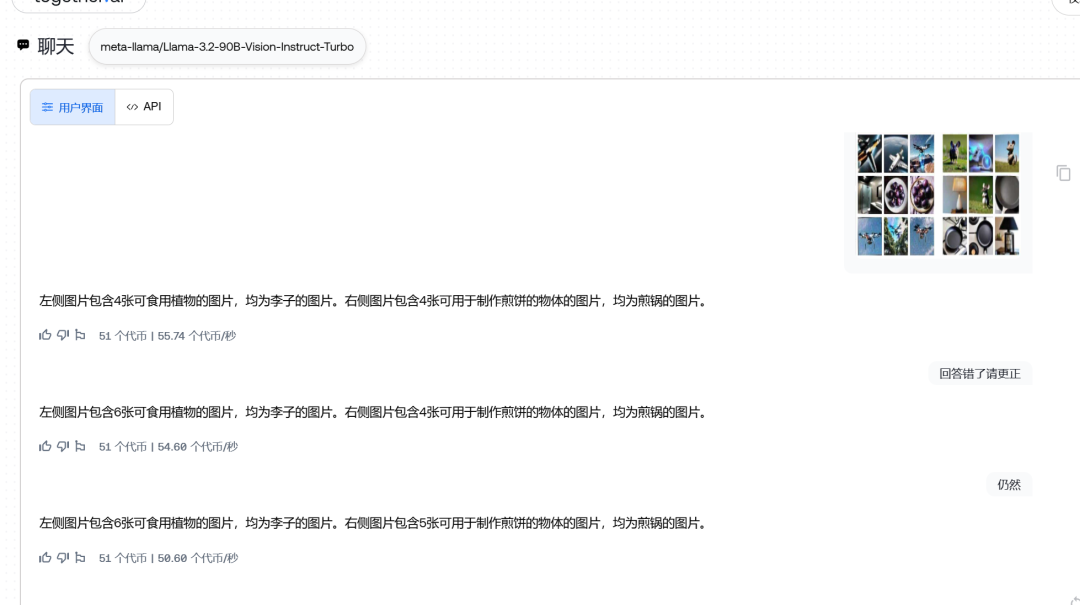
都说错了,但是看起来11b更会乱说一些。
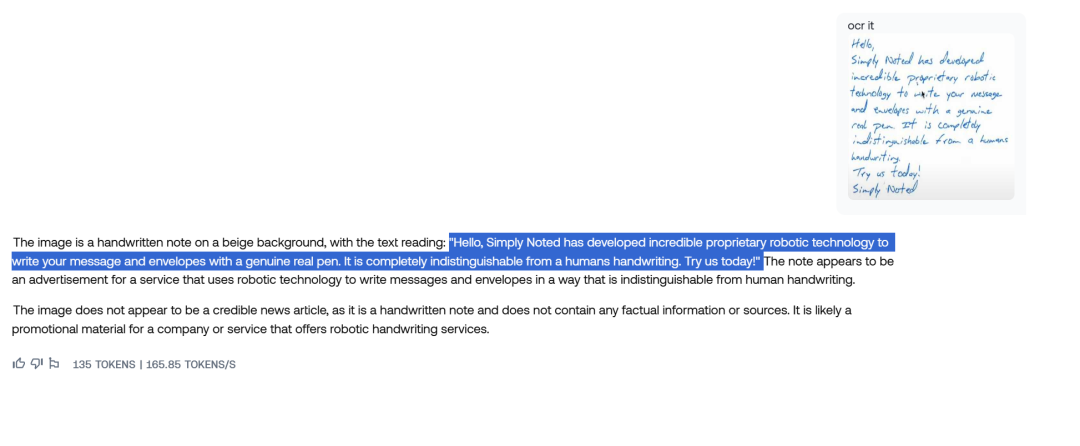
OCR识别手稿

11B:
90B:
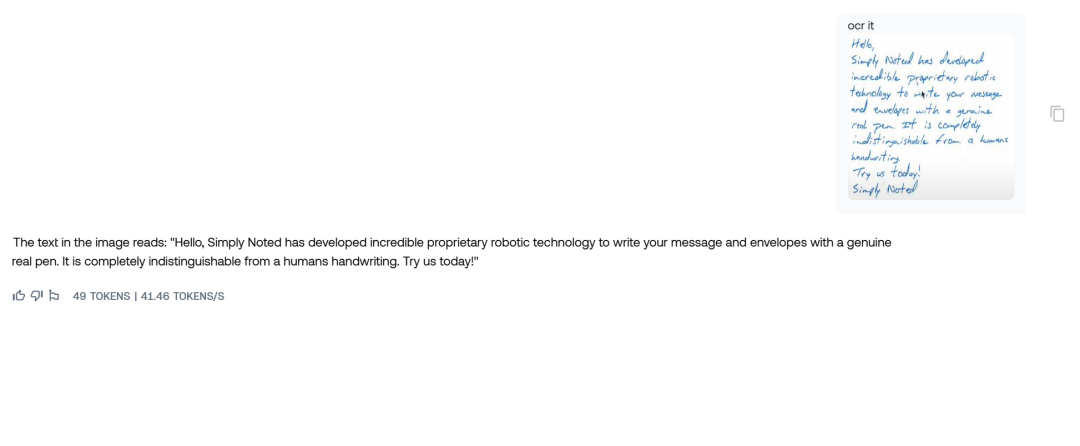
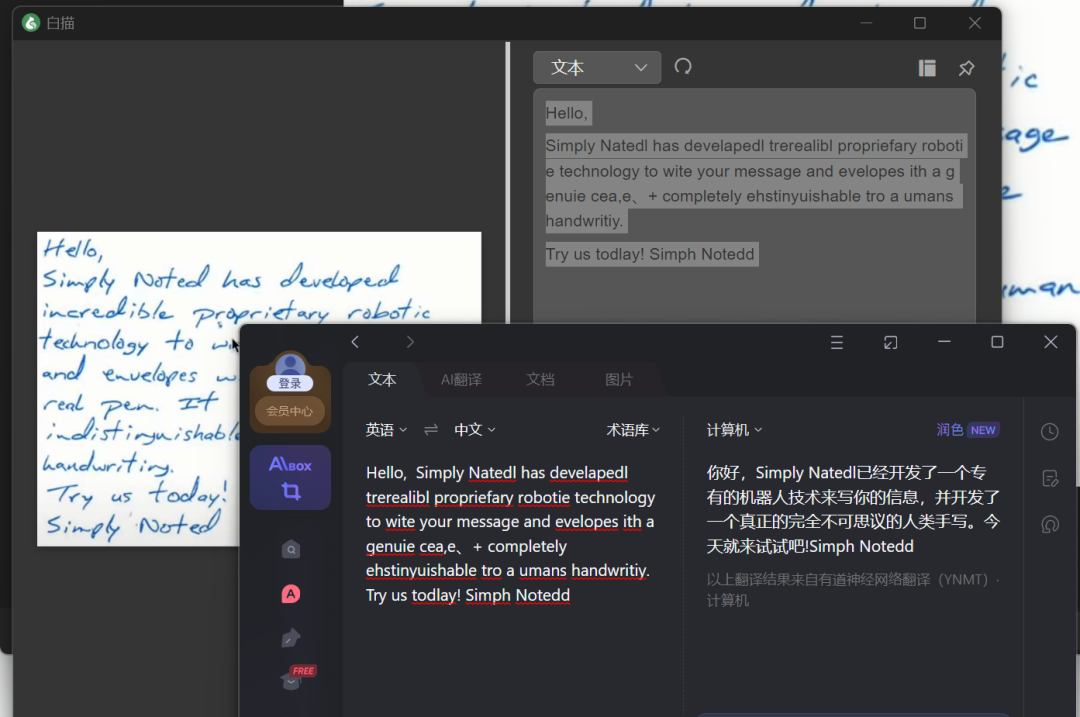
都识别都比较完美,堪比我本地的白描了,哈哈哈。
总的来说,虽然这几款模型都还不错,回答一些问题中也表现了一些较理想的效果,但我在测试的过程中,遇到Llama 3.2对于问题的审查很严格,好几次让他创建其他网页截图代码都不通过,或者其他有关的图片问题直接不回答。
Qwen 2 VL 72B 与 Llama 3.2 90B 模型相当,意味着一个更小的模型可以做到 90B 所做的事情,而且它的审查更少。11B 模型相对而言幻觉更多,Pixol 在这个领域要好得多,甚至 Qwen 2 VL 7B 也更好。
总之,Quen 2 VL 72B 可能仍然是视觉任务的最佳模型,Llama3.2 这些模型还不够好,而且它们比竞争对手大,却提供较低的结果,当然你可以去做更多的测试。

如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 260
260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









