







01 算法介绍
自主泊车是智能驾驶领域中的一项关键任务。传统的泊车算法通常使用基于规则的方案来实现。因为算法设计复杂,这些方法在复杂泊车场景中的有效性较低。
相比之下,基于神经网络的方法往往比基于规则的方法更加直观和多功能。通过收集大量专家泊车轨迹数据,基于学习的仿人策略方法,可以有效解决泊车任务。
在本文中,我们采用模仿学习来执行从 RGB 图像到路径规划的端到端规划,模仿人类驾驶轨迹。我们提出的端到端方法利用目标查询编码器来融合图像和目标特征,并使用基于 Transformer 的解码器自回归预测未来的航点。
我们在真实世界场景中进行了广泛的实验,结果表明,我们提出的方法在四个不同的真实车库中平均泊车成功率达到了 87.8%。实车实验进一步验证了本文提出方法的可行性和有效性。
输入:1.去完畸变的 RGB 图 2.目标停车位
输出:路径规划

论文精读博客参考链接:https://blog.csdn.net/qq_45933056/article/details/140968352
源代码:https://github.com/qintonguav/ParkingE2E
02 算法部署后的 demo 效果展示
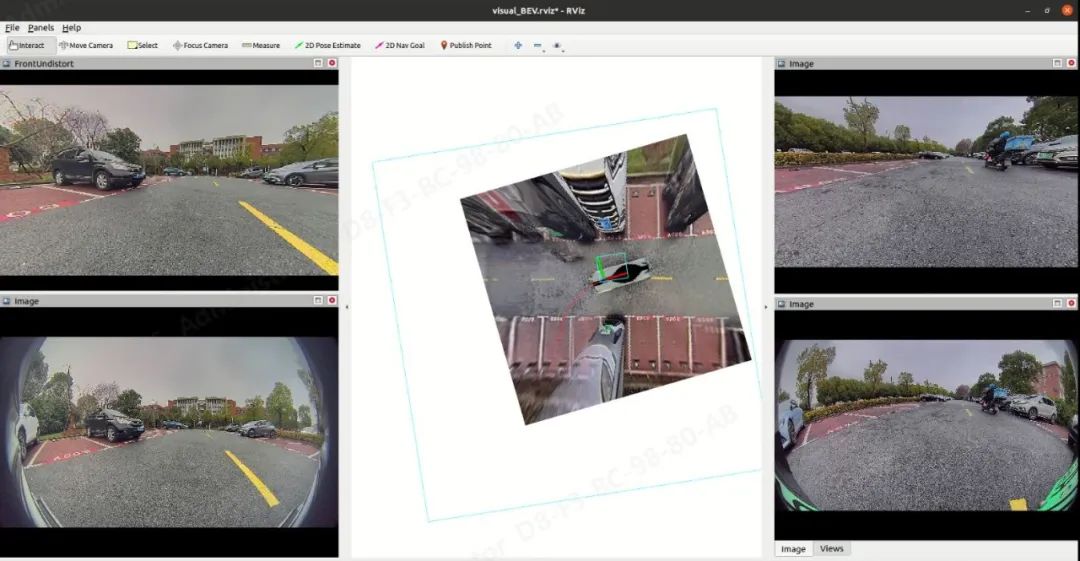
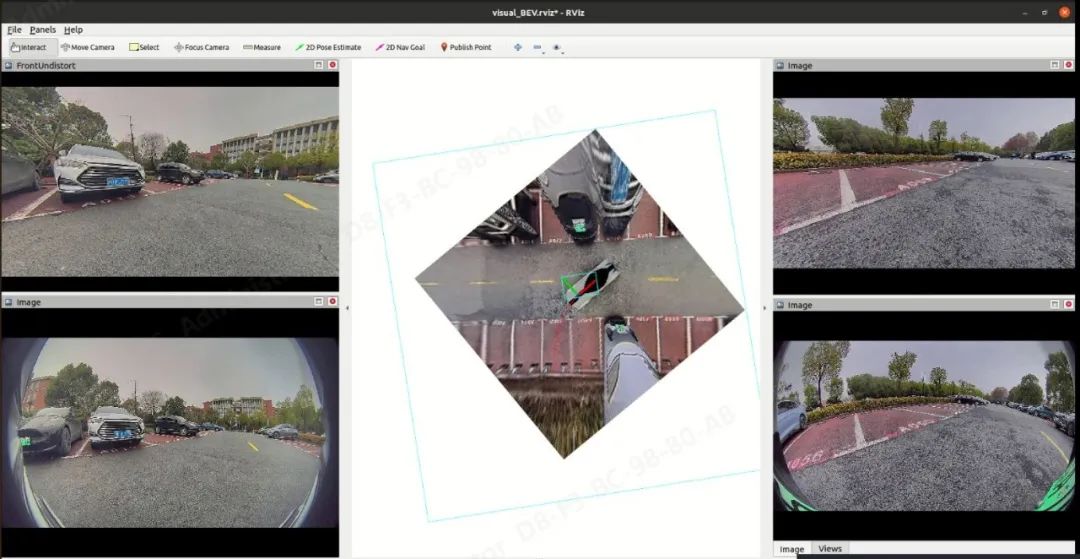
03 实现过程
3.1 算法整体架构
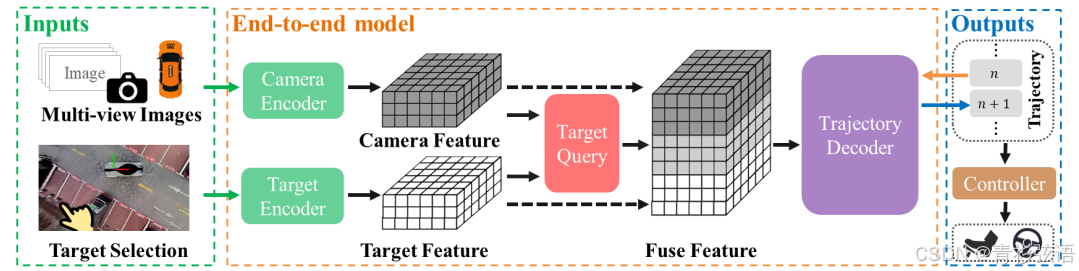
多视角 RGB 图像被处理,图像特征被转换为 BEV(鸟瞰图)表示形式。使用目标停车位生成 BEV 目标特征,通过目标查询将目
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3001
3001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









