







 文章提出了一种名为SRG-Net的新型网络,用于解决兵马俑3D点云数据的无监督分割问题。通过结合种子区域生长算法和卷积神经网络,该方法能有效分割点云并学习其特征,提高考古学家修复兵马俑的效率。实验结果显示,SRG-Net在准确性和速度方面优于现有方法。
文章提出了一种名为SRG-Net的新型网络,用于解决兵马俑3D点云数据的无监督分割问题。通过结合种子区域生长算法和卷积神经网络,该方法能有效分割点云并学习其特征,提高考古学家修复兵马俑的效率。实验结果显示,SRG-Net在准确性和速度方面优于现有方法。
我们希望自动分割兵马俑的3D点云数据,并将碎片数据存储在数据库中,以帮助考古学家将实际碎片与数据库中的碎片进行匹配,从而提高兵马俑的修复效率。此外,现有的3D神经网络研究主要集中在监督分类,聚类,无监督表示和重建。很少有研究集中在无监督点云部分分割上。在本文中,我们提出了用于兵马俑3D点云的SRG-Net来解决这些问题。首先,我们采用定制的种子区域生长算法对点云进行粗分割。然后,我们提出了一个有监督的分段和无监督的重建网络,以学习3D点云的特征。最后,我们使用细化方法将SRG算法与改进的CNN (卷积神经网络) 结合起来。该管道称为SRG-Net,旨在对兵马俑进行分割任务。通过测量准确性和延迟,在兵马俑数据和ShapeNet数据集上评估了我们提出的srg-net。实验结果表明,我们的srg-net优于最新方法。我们的代码可在https://github.com/hyoau/SRG-Net获得。
关键词点云·无监督分割·兵马俑·卷积神经网络·种子区域生长
1引言
我们可以分割兵马俑的3D对象,并将碎片存储在数据库中。我们的工作旨在简化博物馆研究人员的工作,使从现场挖掘的碎片与数据库中预先分割的碎片很容易匹配。为了提高修复工作的效率,提出了一种基于卷积神经网络的兵马俑数据无监督三维点云分割方法。通过本文提出的分割方法,可以将完整的兵马俑自动分割成与各个部分相对应的碎片,例如头,手和脚等。与传统的手工分割相比,本文提出的方法可以显着提高效率和准确性。
最近,有很多研究集中在如何对点云进行voxelize,以使它们均匀地分布在规则的3D空间中,然后在它们上实现3D-CNN。但是,体素化具有很高的空间和时间复杂度,并且在体素化过程中可能存在量化误差,从而导致精度较低。与其他数据格式相比,点云是一种适用于兵马俑三维场景计算的数据结构。我们选择以点云的形式分割兵马俑 (参见图1中的样本)。
兵马俑数据:
R:特征空间
Xn:某一点的特征
N:兵马俑3D对象中的点数
设计函数f:使R->L;其中Cn∈L
L:分割映射标签
Cn:分割后每一点的标签
问题的设计=设计算法预测最优L+设计网络学习标签Cn。
为了获得最优的集群标签 {cn},我们认为一个好的点云分割就像人类所做的那样。直观地说,具有相似特征或语义含义的点更容易分割到同一簇。在2D图像中,空间连续的像素往往具有相似的颜色或纹理。在3D点云中,对具有相似正常值或颜色的空间连续点进行分组,在3D点云分割中给予相同的标签是合理的。此外,具有相同标签的点之间的欧几里得距离不会很长。总之,我们设计了两个标准来预测 {cn}:【june:相似特征的合并上,可以改进】
- 具有相似空间特征的点需要被赋予相同的标签。
- 空间连续点之间的欧几里得距离不应该很长。
我们设计了一种SRG算法,用于尽可能学习点云的正常特征。实验Tao [2020] 表明,FoldingNet Yang等 [2018] 的编码器-解码器结构确实有助于神经网络从点云中学习。而DG-CNN擅长学习地方特色。因此,我们提出了受FoldingNet Yang等人 [2018] 和dg-cnn Wang等人 [2019] 启发的srg-net,以更好地了解兵马俑的部分特征。文章贡献:
- 设计了一种新颖的SRG算法用于点云分割,以通过估计正常特征来充分利用点云xyz坐标。
- 我们提出了受dg-cnn和FoldingNet启发的CNN,以更好地学习3D点云的局部和全局特征。
- 我们将SRG算法和CNN神经网络相结合通过我们的改进方法,并在兵马俑数据上实现了最先进的分割结果。
- 我们的端到端模型不仅可以在兵马俑点云中使用,而且可以在其他点云上获得相当好的效果。我们还评估了ShapeNet数据集上的SRG-Net。
2 Related Work
2D:将标签分配给一个图像中的所有像素,并将其特征聚类。
点云:为点云中的所有点分配标签。预期的结果是具有相似特征的点用相同的标签给出。
就图像分割而言,k均值是2D和3D中的经典分割方法,它导致将n个观测值划分为k个具有最接近均值的聚类。基于图的方法是另一种流行的方法,如Prim和Kruskal Kruskal [1956],它在分割中实现简单的贪婪决策。上述方法侧重于全局特征,而不是局部区分特征,因此当涉及到复杂的上下文时,它们通常无法获得有希望的结果。在无监督的深度学习方法中,有许多使用生成方法的学习特征,例如Lee等人 [2009a],Le [2013],Lee等人 [2009b]。他们遵循神经科学的模型,其中每个神经元代表特定的语义含义。同时,CNN广泛用于无监督图像分割。例如,在Kanezaki [2018a] 中,Kanezaki结合了超像素Achanta等 [2012] 方法和CNN,并采用超像素反向传播来调谐无监督分割结果。此外,Kim等人 [2020] 使用空间连续性损失作为解决前工作Achanta等人 [2012] 的局限性的替代方案,其方法对于3D点云特征学习也非常有价值。
在3D点云分割领域,用于2D图像的最新方法不太适合直接在点云上使用。3D点云分割方法需要了解每个点的全局特征和几何细节。三维点云分割问题可以分为语义分割、实例分割和对象分割。语义分割侧重于场景级分割实例,分割强调对象级分割,对象分割以部分级分割为中心。
关于语义分割,语义分割的目的是将点云分成几个部分,并具有每个点的语义含义。语义分割主要有四种范式,包括基于投影的方法、基于离散化的方法、基于点的方法和混合方法。基于投影的方法总是将3D点云投影到2D图像,例如多视图Lawin等人 [2017],Boulch等人 [2017],球形Wu等人 [2018],Milioto等人 [2019]。基于离散化的方法通常将点云投影到离散表示中,例如体积Graham等人 [2018] 和稀疏的置换面体晶格Dai和nie ß ner [2018],Jaritz等人 [2019]。几种方法不是在3D扫描上学习单个特征,而是试图从3D扫描中学习不同的部分,例如Dai和nie ß ner [2018],Wang等 [2018a],Jaritz等 [2019]。
基于点的网络可以直接学习点云上的特征,并将它们分成几个部分。点云是不规则的、无序的、非结构化的。PointNet Qi等 [2017a] 可以直接从点云学习特征并保留具有对称函数 (如最大函数和求和函数) 的点云置换不变性。PointNet可以通过多个MLP层和一个最大池化层的组合来学习逐点功能。PointNet是直接在点云上学习的先驱。基于PointNet提出了一系列基于点的网络。但是,PointNet只能学习每个点上的特征,而不是本地结构上的特征。因此,提出了用层次网络Qi等人 [2017b] 从邻域中获得局部结构的PointNet。PointSIFT Jiang等人 [2018] 提出了编码定向和达到规模意识。代替使用K-means聚类和KNN生成邻域像分组方法PointNet,PointWeb Zhao等人 [2019] 被提出来获得在本地全连接web中构建的所有点之间的关系。至于基于卷积的方法。Rs-cnn以本地点云子集作为其输入,并将低级关系映射到高级关系,以更好地学习该功能。PointConv Wu等人 [2019] 使用现有算法,使用蒙特卡洛估计来定义卷积。PointCNN Li等人 [2018] 使用 χ − conv变换将点云转换为潜在和规范顺序。关于点卷积方法,提出了基于参数连续卷积层的参数连续卷积神经网络 (PCCN) Wang等 [2018b],其核函数由MLPs参数化,跨越连续向量空间。基于图的方法可以更好地学习点云中的形状和几何结构等特征。图注意卷积 (GAC) veli forckovi'c等人 [2017] 可以通过动态地将注意权重分配给不同邻域和特征通道中的点,从本地邻域学习几个相关特征。动态图CNN (dg-cnn) Wang等人 [2019] 在邻域中构造了几个动态图,并将局部和全局特征串联起来,以提取更好的特征并动态更新网络各层后的每个图。FoldingNet采用自动编码器结构,将点云N × 3编码为1 × 512,并借助倒角损耗将其解码为m × 3,以构建自动编码器网络。
零件分割比语义和实例分割更复杂,因为具有相同标签的点之间存在显着的几何差异,并且具有相同语义含义的零件数量可能会有所不同。Z。Wang等。Wang和Lu [2019] 提出了VoxSegNet,以在3D体素化数据上实现有希望的零件分割结果,它提出了一种空间密集提取 (SDE) 模块,用于从体积数据中提取多尺度特征。同步谱CNN (SyncSpecCNN) Yi等人 [2017] 提出了用卷积实现不规则性和非同构形状图的细粒度部分分割。Liu和Xiong [2008] 提出了通过提取高斯球面上的点簇来自动分割无组织的噪声点云。Di Angelo和Di Stefano [2015] 使用三个形状指标: 基于模糊参数化的平滑度指标,形状指标和平坦度指标。Benk paro和v á rady [2004] 提出了一种基于各种几何特征的局部估计的常规工程对象的分割方法。提出了分支自动编码器网络 (BAE-NET) Chen等人 [2019] 来执行无监督和弱监督的3D形状共分割。网络的每个分支都可以从特定零件形状中学习特征,用于具有基于自动编码器结构的表示的特定零件形状。
3 Proposed Method
在本文中,我们对兵马俑的输入数据采用3D点云的形式 (参见图1中的样本)。点云数据表示为一组3D点 {Pi | i = 1、2、3...n},其中每个点是一个向量Rn,其中包含坐标x,y,z和其他特征,例如法线,颜色。我们的方法包含三个步骤:
- 我们用xyz坐标计算正常值。
- 我们使用seed-region-growing(种子区域生长 ,SRG) 方法对点云进行预分段。
- 我们使用pointwise CNN称为SRG-Net的自我训练来对点云进行分段,并对分段前的结果进行细化。
鉴于点云仅具有3D坐标,有几种有效的正态估计方法,如欧阳和冯 [2005] Zhou等 [2020] Wang等 [2013]。在我们的方法中,我们遵循Rusu和Cousins [2011] 中最简单的方法,因为它具有较低的平均情况复杂度和相当高的准确性。通过将种子区域生长聚类方法与称为SRG-Net的3D逐点CNN相结合,我们提出了一种无监督的兵马俑点云分割方法。该方法包含SRG分割和分割网络两个阶段。我们要解决的问题可以描述如下。首先,在点云上实现SRG算法进行预分割。其次,我们使用SRG-Net进行带有预分割标签的无监督分割。
3.1 Seed Region Growing(SRG)【june:查查网上点云是怎么区域生长的】
与2D图像不同,并非所有点云数据都具有颜色和(normal)法线等功能。例如,我们的兵马俑3D对象没有任何颜色特征。然而,法向量可以通过点坐标来计算和预测。值得注意的是,2D中的颜色与3D中的normal特征之间存在许多相似之处和不同之处。对于2D图像中的颜色特征,如果像素在语义上是相关的,则邻域中像素的颜色通常不会有很大变化。对于3D点云正态特征,与2D图像中的颜色特征相比,点云附近点的正常值通常不同。一个点云中的邻域点共享相似的功能。基于上述点云normal特征的特征,我们设计了一种种子区域生长方法来对点云进行预分割。
首先,我们将KNN实现到点云,以获取每个点的最近邻居。然后,我们将随机点初始化为开始种子,并添加到可用点以启动算法。然后,我们从可用列表中选择第一个种子来判断其附近的点。如果normal值和欧几里得距离在我们设定的阈值内,我们认为这两个点在语义上是连续的,我们可以将两个点分组为一个簇。算法1给出了SRG的概述。算法的描述如下:

1.输入
(a)xyz每个点的坐标Pn
(b)每个点的normal值n
(c)两个点之间的欧几里得距离e
(d)每个点的邻域b
2.随机选择的点添加到集合A中,我们可以将其称为种子a。
3.对于未转换为种子的其他点:
(a)对普通点a和种子点Na,检查normal距离和欧几里得距离。
(b)设置normal距离和欧几里得距离阈值。如果两个值都小于两个阈值,将其添加到A中。
(c)当前种子将添加到检查列表S中。
3.2 SRG-Net
我们提出了我们的SRG-Net,它的灵感来自DG-CNN中的动态图和FoldingNet中的自动编码器。与经典图CNN不同,我们的图在网络的每一层都是动态的和更新的。与仅关注点之间关系的方法相比,我们还提出了一种编码器结构【完整表达点云特征的编码器结构,可以修改】来更好地表达整个点云的特征,旨在学习点云的结构并优化SRG的预分割结果。我们的网络结构可以如图2所示,它由两个子网络组成,第一部分是从动态图和整个点云生成特征的编码器,第二部分是分割网络。
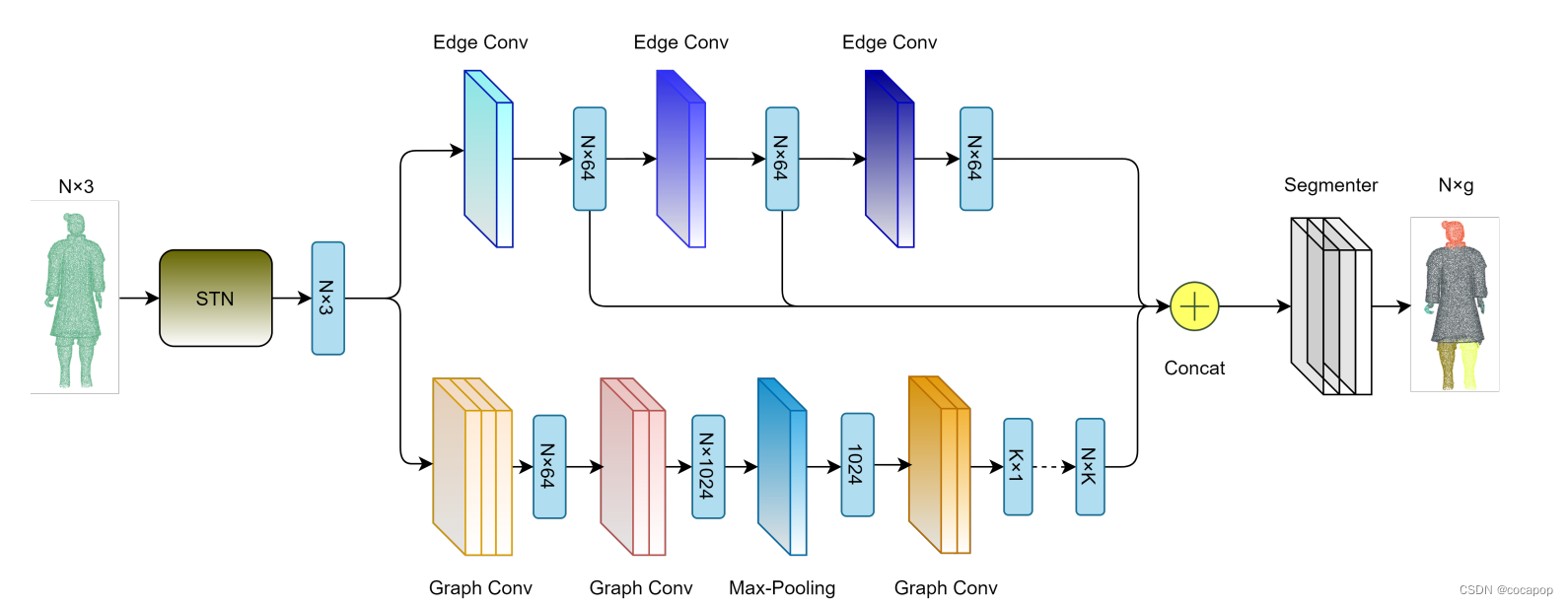
图2: 网络结构。棕色部分代表空间变压器网络,蓝色模块代表边卷积,下部模块代表图卷积。上下模块的张量将被串联,并输入到Segmenter(分段器)中以获得最终的分割结果。
我们将点云表示为S。我们用小写字母表示向量,如x,用大写字母表示矩阵,如A。如果矩阵有m行和n列,我们将其称为m × n或m × n。此外,兵马俑点云数据为N个具有6个特征x,y,z,Nx,Ny,Nz(xyz坐标和normal) 的点,记作X = {x1,x2,x3,...,xn} ⊆R6
3.2.1 Encoder Architecture 编码器结构
SRG-Net编码器遵循Yang等人的类似设计 [2018],SRG-Net的结构如图2所示。与Yang等人 [2018] 相比,我们的编码器连接了几个多层感知器 (MLP) 和几个基于动态图的最大池化层。通过在点云上应用KNN来构造动态图。
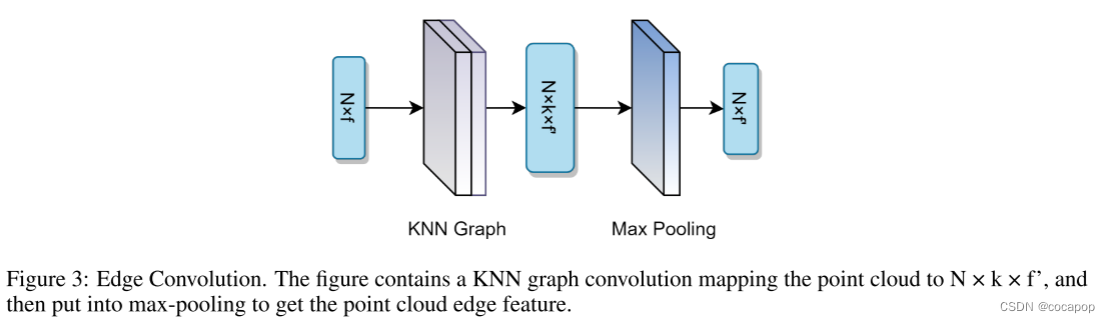
图3:边卷积。该图包含将点云映射到N × k × f 的KNN图卷积,然后放入max-pooling中得到点云边缘特征。
对于整个点云,我们计算一个空间变压器网络【June:可以修改】(棕色部分,STN),并获得3 × 3的变压器矩阵,以保持变换下的不变性。然后,对于变换后的点云,我们分别计算三个dynamic graphs(动态图)并获得graph features(图特征)。在图特征提取过程中,我们采用Le [2013] 中的Edge Convolution(边卷积)来计算每一层的图特征,它使用公式中的asymmetric edge function(非对称边函数):公式1。其中,它将邻域中心xi的坐标与邻域点的减法以及中心点坐标xi − xj结合起来,得到邻域的局部和全局信息。
![]()
然后我们在等式2中定义我们的操作。其中 µ 和 ω 是参数,Θ 是remu函数。等式(2) 实现为具有shared MLP with Leaky ReLU.
![]()
然后我们在等式(3)中定义我们的最大池化操作。:其中N(i) 表示点i的邻域。
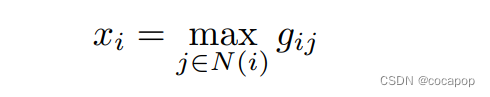
bottleneck(瓶颈)由图形特征提取层计算。结构如图2所示。首先,我们计算每个点的协方差3 × 3矩阵,并将其矢量化为1 × 9。然后将点坐标的n × 3矩阵与n × 9协方差矩阵级联为n × 12矩阵。然后,我们将矩阵放入3层感知器中。然后,我们将感知器的输出馈送到两个后续的图层。在每一层中,max-pooling被添加到每个节点的邻居。最后,我们将3层感知器应用于前一个输出,并获得最终输出。在公式(4)中总结了图特征提取层的整个过程。:
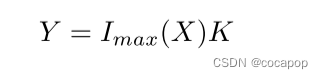
在等式(4)中,X是到图层的输入矩阵,K是特征映射矩阵。Imax(X) 可以用等式(5)表示。公式(5) 中的最大池化操作可以基于图结构得到局部特征,所以图特征提取层不仅可以得到局部邻域特征,还可以得到全局特征。
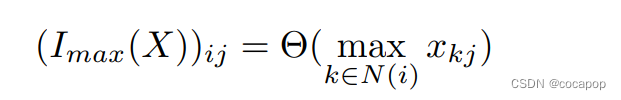
3.2.2 Segmenter Architecture 分段器结构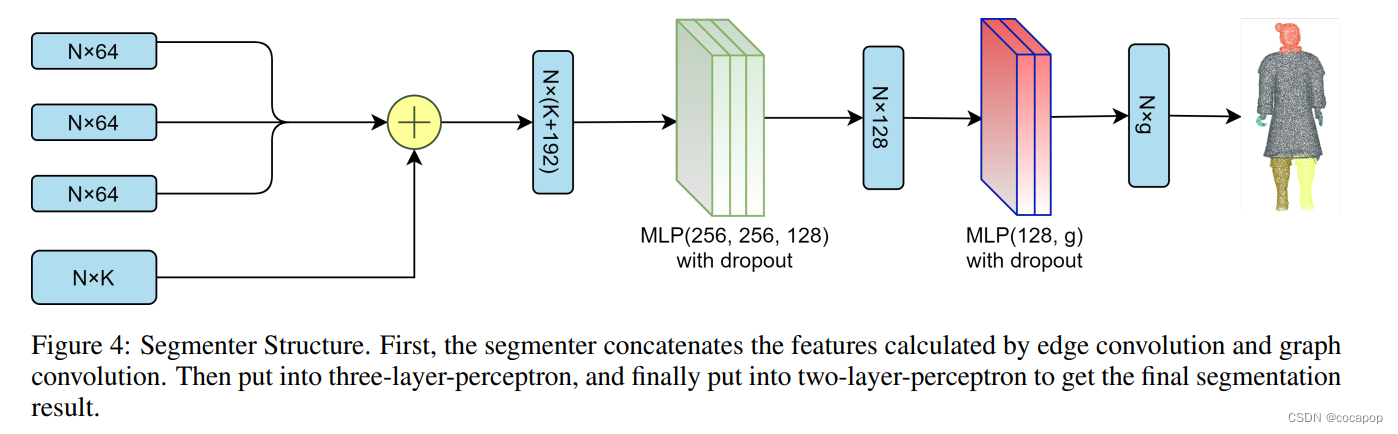
图4 分段器。首先,分段器连接通过边缘卷积和图卷积计算的特征。然后放入三层-感知器,最后放入两层-感知器得到最终的分割结果。
Segmenter获取动态图特征和bottleneck(瓶颈)作为输入,并为每个点分配标签以分割整个点云。分段器的结构如图2所示。首先,在等式(6)中重复瓶颈N次。其中N是点云中的点数,B是瓶颈。
(7)复制的输出与等式中的动态特征连接。其中D1,D2,D3表示动态图特征。
最后,我们将串联的输出馈送到多层感知器,以在等式(8)中分割点云。其中 Ψ 和 Ω 表示线性函数中的参数,Θ 表示ReLU函数。
3.3 Refinement 完善
ps.作者没有给兵马俑数据集


















 915
915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









