






频域+特征融合是一种在深度学习领域中非常重要的技术,它通过结合频域分析和特征融合的优势,能够显著提升数据处理的准确性和效率。这种技术能够捕捉到传统时域分析难以揭示的频率特性,从而帮助构建更加复杂和精细的模型,尤其在信号处理、图像识别等任务中显示出其高效性。
今天就这两种技术整理出了论文+开源代码,以下是精选部分论文
更多论文料可以关注 :AI科技探寻,发送:111 领取更多[论文+开源码】
:AI科技探寻,发送:111 领取更多[论文+开源码】
论文1
Frequency-aware Feature Fusion for Dense Image Prediction
用于密集图像预测的频率感知特征融合
方法:
-
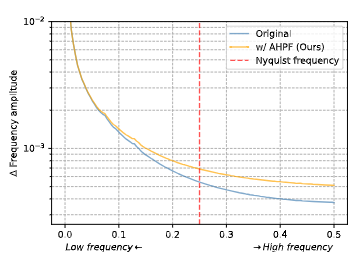
频率感知特征融合(FreqFusion):提出了一种新的特征融合方法,通过集成自适应低通滤波器(ALPF)生成器、偏移生成器和自适应高通滤波器(AHPF)生成器来改善特征一致性和清晰度。
-
自适应低通滤波器(ALPF)生成器:预测空间变化的低通滤波器,旨在减少对象内部的高频成分,减少上采样过程中的类内不一致性。
-
偏移生成器:通过重采样附近具有高类内一致性的特征来替换不一致的特征,从而优化大范围不一致特征和细边界区域。
-
自适应高通滤波器(AHPF)生成器:从低层特征中提取高频细节信息,增强下采样过程中丢失的高频信息,以锐化边界。
创新点:
-
频率感知特征融合(FreqFusion):通过自适应低通滤波器减少类内不一致性,通过偏移生成器优化特征替换,以及通过高通滤波器增强边界细节,显著提升了特征融合的效果。在语义分割任务中,FreqFusion提升了SegFormerB1和SegNeXt-T的性能分别达2.8 mIoU和2.0 mIoU。
-
特征相似性分析:引入了特征相似性分析来量化特征融合过程中的问题,为新特征融合方法的开发提供了定量的测量方法,并可能激发相关领域的发展。
-
综合性实验验证:在包括语义分割、目标检测、实例分割和全景分割等多种密集预测任务中,FreqFusion均显示出显著的性能提升,超越了之前的最佳方法。
论文2
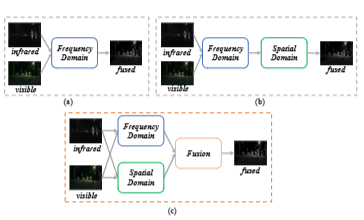
SFDFusion: An Efficient Spatial-Frequency Domain Fusion Network for Infrared and Visible Image Fusion
SFDFusion:用于红外和可见光图像融合的高效空间-频率域融合网络
方法:
-
双模态精炼模块(DMRM):在空间域中提取红外和可见光模态的互补信息,并增强细节空间信息。
-
频率域融合模块(FDFM):通过快速傅里叶变换(FFT)将空间域转换为频率域,然后整合频率域信息。
-
频率域融合损失:设计了一种频率域融合损失,为融合过程提供指导。
创新点:
-
双模态精炼模块(DMRM):通过消除空间域中的冗余信息同时保留梯度信息和纹理细节,提高了融合图像的质量。
-
频率域融合模块(FDFM):通过捕捉两个模态在频率域中的有效信息,增强了模型对图像的全面理解能力。
-
高效的融合性能:在公共数据集上的广泛实验表明,SFDFusion方法在各种融合指标和视觉效果上产生具有显著优势的融合图像,并且在图像融合效率和下游检测任务性能上表现出色,满足了高级视觉任务的实时需求。在M3FD数据集上,SFDFusion在目标检测的mAP指标上达到了0.795的优秀性能,显示出在生成高质量融合图像的同时,对下游目标检测任务的准确性有显著提升。
论文3
EchoTrack: Auditory Referring Multi-Object Tracking for Autonomous Driving
EchoTrack:自动驾驶中的听觉指代表多目标跟踪
方法:
-
双流视觉变换器:提出了一个端到端的听觉指代表多目标跟踪(AR-MOT)框架EchoTrack,该框架采用双流视觉变换器。
-
双向频域交叉注意力融合模块(Bi-FCFM):设计了Bi-FCFM以促进基于变换器的信息聚合,考虑音频数据的频域信息,提供有价值的参考。
-
音频-视觉对比跟踪学习(ACTL):提出了ACTL,通过引入音频指代特征,构建对比学习,通过对比学习引入音频指代特征。
创新点:
-
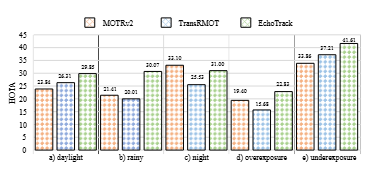
Bi-FCFM性能提升:Bi-FCFM在Echo-KITTI数据集上相比于其他融合模块(如Vanilla-CAtt、Bi-XAtt、DWT-CAtt、FFT-CAtt)在HOTA、DetA、AssA、MOTA和IDF1等指标上分别提升了3.08%、0.47%、0.44%、0.99%和4.71%。
-
ACTL性能提升:EchoTrack在Echo-KITTI数据集上相比于TransRMOT在HOTA、MOTA和IDF1指标上分别提升了3.56%、4.72%和5.24%。
-
音频-视觉特征融合:EchoTrack通过Bi-FCFM和ACTL模块,有效地融合了音频和视频特征,提升了在复杂环境下的跟踪性能。
-
大规模AR-MOT基准测试集:建立了首个大规模AR-MOT基准测试集,包括Echo-KITTI、Echo-KITTI+和Echo-BDD,为自动驾驶领域提供了丰富的参考视觉属性和音频表达。
论文4
STeInFormer: Spatial-Temporal Interaction Transformer Architecture for Remote Sensing Change Detection
STeInFormer:用于遥感变化检测的空间-时间交互变换器架构
方法:
-
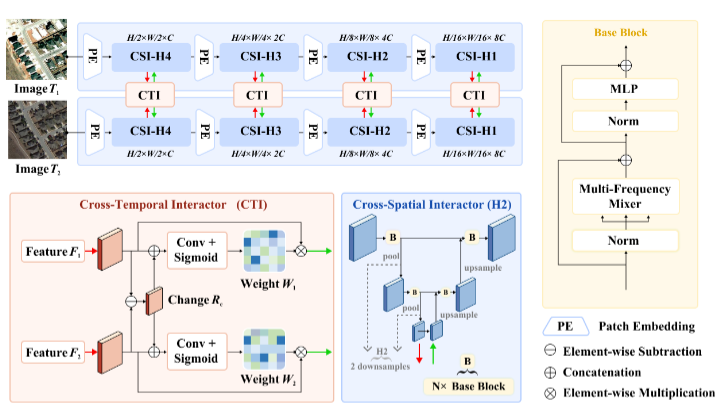
跨时间交互器(CTI):采用门控机制来强调变化区域的特征差异,同时抑制非变化区域的特征差异。
-
跨空间交互器(CSI):基于U形架构的编码阶段,用于整合高层特征的语义信息和低层特征的空间细节。
-
多频率混合器:基于离散余弦变换(DCT),结合先前的频率值来整合令牌信息,具有线性复杂度。
创新点:
-
空间-时间交互变换器架构:首次提出专门针对遥感变化检测(RSCD)的通用骨干网络,通过整合特征提取中的时间空间交互,提高了特征的鲁棒性和区分性。在三个数据集上的实验结果表明,STeInFormer在效率-准确性权衡方面超越了现有的最先进方法,例如在WHU-CD数据集上,相比于DMATNet方法,F1分数提升了3.5%,达到了89.61%。
-
跨时间交互器(CTI)和跨空间交互器(CSI):引入门控机制和U形架构来分别实现跨时间交互和跨空间交互,这有助于模型更好地识别和区分变化和非变化区域。在LEVIR-CD数据集上,相比于ChangeFormer方法,F1分数提升了1.1%,达到了91.47%。
-
多频率混合器:首次从频率域的角度解决RSCD问题,并且使用先前的频率值,实现了线性时间复杂度的特征提取。在CLCD数据集上,相比于DMINet方法,F1分数提升了0.9%,达到了73.83%。
更多论文料可以关注:AI科技探寻,发送:111 领取更多[论文+开源码】

















 1043
1043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









