








deep q-learning,能发现bug,可以把球击到上面,让他可以自己玩;
alphago 文章在2016.2017的nature
alphago zero 扩展到了其他游戏
alphago start 深度强化学习玩星际争霸
今天介绍如何利用深度强化学习用到机器人上
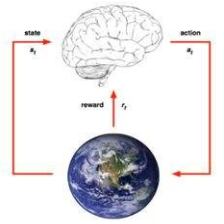
强化学习解决连续决策问题,目标得到最优策略
马尔科夫决策过程概率图,未来只与当下有关
回报有递归的形式,价值函数也有这种递归关系(这里用到的是随机策略),即贝尔曼方程。
actor-critic是基于策略和基于价值的结合
几种不同类型的价值函数的估计:
DQN:
首先设定目标损失函数,y类似监督学习的标签,是TD Target,基础是q的贝尔曼方程。(类似Q-Learning中的更新环境)
损失函数求梯度
完整算法:
每次都是把数据保存在D中,然后用这个batch的数据训练。
从长远利益出发
无法用于连续行为空间,比如机器人运动。因此另一种方法,策略梯度法:
蒙特卡洛策略梯度
Q Actor-Critic比上一个收敛更快,方差更小。
Advantage Actor-Critic,又加了一个神经网络。更快,方差更小。
在机器人领域的研究:
深度强化学习的主要问题:
1、需要很多样本才能收敛;
2、成功案例多来自于仿真环境,样本手机慢
3、显示中训练不能加速
解决方案:
首先在仿真中训练,再应用
或者模仿学习,人为示范,学习环境动态模型
1、仿真-现实转换
论文:
仿真中随机花生成情况;
使用现实采样数据更新仿真分布
采用PPO算法
2、模仿学习
论文:
先捕捉动物运动,然后放到仿真环境。
需要模型转换,然后模仿,然后适应
IK算法,指定仿真模型关键点,再用IK,计算姿态,追踪关键点。
RL也是用PPO reward来自估计与真实的误差
动态参数
3、基于模型的强化学习
paper
用神经网络逼近P,结果是可以较小时间和数据
重点是实现,idea不是那么重要!
深度强化学习在自动驾驶领域应用
自动驾驶仿真器
CARLA
paper















 2919
2919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









