




 本文提出一种基于几何特征的停车位标记检测方法,通过线聚类和多视图融合学习,实现在复杂光照和地面条件下的精准停车位检测,准确率高达97.4%。
本文提出一种基于几何特征的停车位标记检测方法,通过线聚类和多视图融合学习,实现在复杂光照和地面条件下的精准停车位检测,准确率高达97.4%。
摘要:本文提出了一种基于停车位几何特征的停车位标记检测方法。提出的系统主要由分线检测和停车位入口检测两步组成。
首先,在分离线检测阶段,我们提出了一种基于线段检测(LSD)算法的线聚类方法。
we propose a line-clustering method based on the line segment detection (LSD) algorithm
我们的检测和行聚类算法可以在鸟瞰图(BEV)图像中检测包含一对固定距离的平行线的分隔线,在不同的光照和地面条件下。
通过根据停车位的宽度将分隔线配对来生成停车位候选。
在停车位入口检测过程中,我们提出了一种基于多视图融合的学习方法,该方法可以通过对获取的BEV图像执行透视变换来增加训练样本的数量。
用353个BEV图像覆盖了不同的停车槽标记对该方法进行了评价,实验表明该方法可以识别典型的垂直和平行矩形停车槽,准确率达97.4%,召回率达96.6%。
1. Introduction
自动泊车系统[1-3]包括目标位置指定,路径规划和路径跟踪三个部分,目标位置指定是智能交通的最重要组成部分。
文献中已经提出了多种识别目标位置设计的方法,它们可分为四类:
基于自由空间的[4-11],
基于停车位标记的[12-25],
基于接口的[26–28]
和基础架构。
free space-based [4–11], parking slot marking-based [12–25], interface-based [26–28] and infrastructure-based.
其中,基于自由空间的方法得到了广泛的研究
但是有麻烦
如果没有相邻的车辆,则该方法无效。
停车位标记
与其他方法相比,基于停车位标记的方法可以更准确地识别停车位,因为其识别过程不取决于相邻车辆的存在,而是取决于停车位标记。
何时,它不需要辅助传感器,例如短程雷达和扫描激光雷达。
先前的方法可以大致概括如下。
文献[12]中提出的方法可以全自动识别各种类型的停车位标记。
首先,该方法同时找到平行线对,这些平行线对的倾斜方向与检测分隔线时相反。
接下来,该方法利用线检测器和哈里斯角检测器来识别入口位置。
但是,当环视监视器(AVM)图像中的线条或拐角模糊不清时,传统的基于视觉的功能会对噪声敏感。
文献[13,14]中的方法不够鲁棒,无法在复杂的光照强度和地面条件下给出理想的结果。
[15]中的方法还使用基于边缘图像的线段检测(LSD)查找具有固定距离的平行线,
但是,存在将直线分成许多小段的麻烦,导致错误检测的增加。
[16]中的方法是一种基于数据驱动的基于学习的方法,称为PSDL,该方法首先检测标记点,然后使用六个高斯线模板推断有效的分离标记线。如果错误地检测到标记点,则停车无法正确找到插槽,检测精度将降低。
相比之下,离线检测模型始终提供非常准确的结果。
但是,基于学习的方法通常非常耗时,因为它训练了多个检测器并且标记点可以在任何方向上。
我们将在下一部分中更详细地回顾文献。
因此,为了解决上述问题,本文提出了一种基于几何特征的方法,即使在各种灯光(昏暗,强烈)下显示停车位标记,也可以取得更好的结果。和地面条件(砖化,弯曲,模糊标记)以全自动的方式。
所提出的方法首先利用基于先前的LSD算法的行聚类方法来检测分隔线。
通过根据停车位的几何特征将分隔线配对来形成候选停车位。
最后,本文采用基于直线和基于学习的方法对入口进行检测,如果基于直线的方法引导线的数量大于1,则使用基于学习的方法重新检测引导线。
该方法在包含各种复杂条件的数据库中进行了评估,其召回率达到96.6%,准确度达到97.4%。
The contributions of this paper are as follows:
(1)提出了一种line-clustering method聚类方法,与以前的包括距离变换和霍夫线检测器在内的行检测方法相比,它在变化的照明条件下具有更强大的检测能力。
(2)由于仍缺乏大规模数据集,我们提出了一种多视图融合方法来增加训练集。
(3)以前的基于学习的方法需要训练多个标记点检测器,在本文中,我们仅训练一个检测器,并使用convex defect algorithm凸缺陷算法识别停车标记点的形状,
这会增加真实阳性的数量,并提供更可靠的检测结果。
本文的其余部分安排如下:第2节介绍了相关研究;第3节介绍了所提出的方案;第4节介绍了实验结果;最后,第5节总结了本文。
2.相关研究
鉴于本文与基于视觉的方法有关,本节中的文献综述集中于基于车位标记的方法。
使用此方法的所有方法均使用可检测在地面上绘制的停车位标记的摄像机。
这些方法分为两个流,即半自动流和自动流。
在2000年,Xu等人[17]利用停车位标记的颜色从图像中识别出这些标记的像素。
在2006年,Jung等人[18]在从种子点到相机的线上使用方向强度梯度识别了标记线段。
此方法是半自动的,需要手动选择停车位。
我们的方法是全自动的,不需要手动选择停车位。
Schmidetal [19]在2011年提出使用分层的三维占用栅格来检测停车位。
所提出的方法得出到障碍物和墙壁的距离,因此能够表示形成停车位的自由空间。
Suhretal [20]在2012年提出了一种新颖的自动方法,用于识别由AroundViewMonitor(AVM)系统获取的图像序列中的各种插槽标记。
2013年,Suhretal [21]通过以全自动方法将它们建模为分层树结构来识别各种类型的停车位标记。
2014年,Wang等人[14]提出了一种通过鸟瞰视觉系统自动停车的方法,该方法使用基于Radontrans形式的方法提取停车位的特征,然后进行双圆轨迹规划和预览控制策略。用于实现自动泊车。
Suhretal [22]提出了一种空置的停车位检测和跟踪系统,该系统融合了AroundViewMonitor(AVM)系统和基于超声波传感器的自动停车系统的传感器。
Lee等[23]在2016年提出了一种基于线段级聚类的鲁棒停车位检测算法。
所提出的算法包括使用所提出的基于方向密度的空间聚类算法(Directional-DBSCAN)的线段检测和使用时隙模式识别的时隙检测。
Directional-DBSCAN算法即使线条短而微弱也能可靠地提取线条。
Lee等人[24]提出了一种基于摄像机的基于停车位上下文分析的停车位识别算法。
该方法可以处理各种可用的停车位条件。该方法提出了一种提取和关联线标记以识别停车位的新方法,
并通过梯度和频率幅度特征的直方图可以对时隙占用进行分类。
Suhr等人[25]提出了一种基于并行线的方法,该方法可检索基于随机样本共识(RANSAC)和基于距离变换(DT)的倒角匹配,以检测停车位标记。
所提出的方法是完全自动的方法。它可以在不同的光照和地面条件下可靠地识别停车位标记。所提出的基于多视点融合的学习方法也可以增加训练样本的数量并减少错误检测的结果
3. Proposed Scheme
如图1所示,停车位标记由一条导向线和几条平行的固定距离的分隔线组成。
每个停车位由两条垂直于指南线的分隔线隔开。
此外,还有两种指导线:连续的直线和T形或L形标记点。
根据停车位的固有几何约束,所提出的方法使用线聚类[29-32]来检测分隔线,这可以去除假线,然后使用基于学习的方法来检测引导线。
图1的第一行显示了垂直的停车位。
图1的第二行显示了与图像相对应的平行停车位,具有与图1的第一行相同的指导线。与之前的方法相比,该方法在复杂的照明条件下更加鲁棒
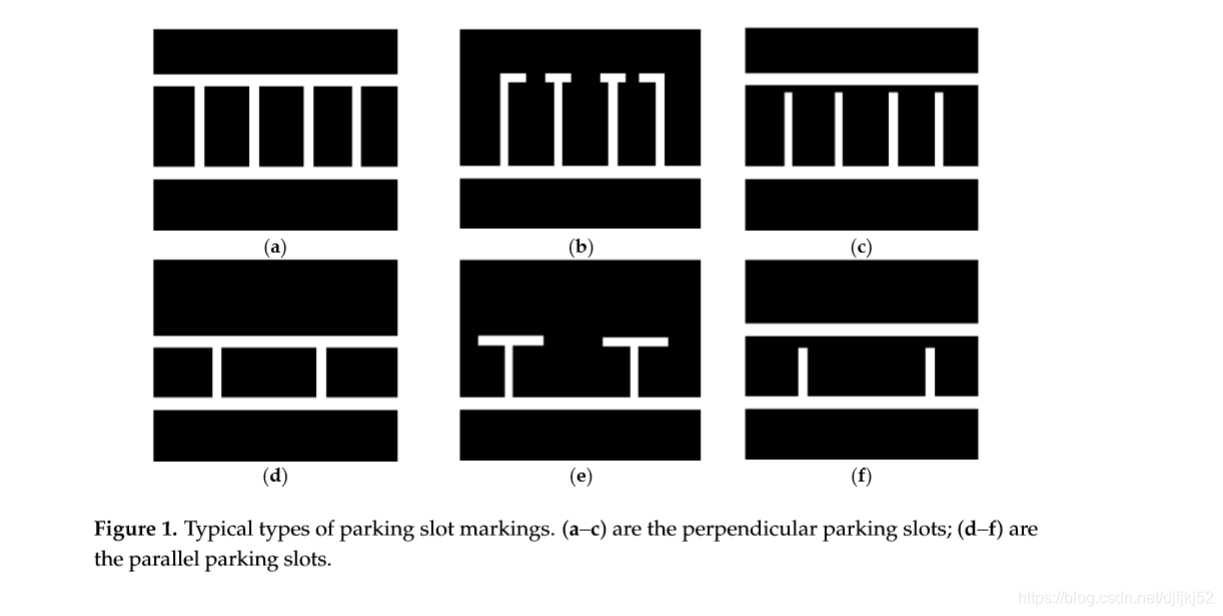
图2示出了所提出的方案的整体框图。
对于给定的鸟瞰(BEV)图像,我们首先进行预处理。
在正常情况下,当驾驶员在停车位中行驶时,停车位标记将显示在驾驶员左侧和右侧。
因此,我们提出了一种获取感兴趣区域(ROI)的方法,而不是在整个图像上检测停车位标记,这可以减少我们的总体处理时间。
图3说明了定义ROI的方法。
w1表示AVM图像中汽车的宽度,
w2表示AVM图像的宽度,
w3和w4分别是左ROI和右ROI的宽度。
几何约束如下:w3 = w4 =(w2-w1)/ 2。
他提议的方法主要步骤如下:
第一部分是检测停车分隔线,它们在环视图像中具有一对固定距离的平行线。
接下来是检测停车位入口。
该过程检索基于多视图融合的学习方法,而不是先前在[12]中使用的Harris角点检测器方法。
对于占用率分类,我们使用[15]中提出的方法。
一种基于AVM [33]系统的方法转换。 该系统在车辆顶部提供了所谓的``鸟瞰图’'图像。由于AVM系统非常成熟,因此在此不对其进行详细描述,该系统如图4所示。

3.1. Image Preprocessing
图像预处理
图像质量直接影响识别算法的准确性,因此在停车位检测之前需要进行预处理。
图像预处理的目的是消除图像中不相关的信息,恢复有用的信息,并增强相关信息的可检测性。
在这项研究中,预处理过程如下:
首先,提出的方法获得了ROI,我们不需要关注非ROI,并且该方法减少了整体处理时间,此外,彩色图像被转换为其灰度版本。
最后,为了更准确地检测停车位标记,有必要执行morphological filtering 形态学滤波和图像边缘检测,
因为morphological filtering 形态学滤波可以产生更平滑的边缘。
在这项研究中,边缘图像是由Canny检测器生成的,图5显示了预处理结果

形态学,即数学形态学(mathematical Morphology)
链接:https://blog.csdn.net/whuhan2013/article/details/53956606
形态学是图像处理中应用最为广泛的技术之一,主要用于从图像中提取对表达和描绘区域形状有意义的图像分量,使后续的识别工作能够抓住目标对象最为本质〈最具区分能力-most discriminative)的形状特征,如边界和连通区域等。同时像细化、像素化和修剪毛刺等技术也常应用于图像的预处理和后处理中,成为图像增强技术的有力补充。
本文主要包括以下内容
- 二值图像的基本形态学运算, 包括腐蚀、膨胀、开和闭。
- 二值形态学的经典应用, 包括击中击不中变换、边界提取和跟踪、区域填充、提取连通分量、细化和像素化, 以及凸壳
- 灰度图像的形态学运算, 包括灰度腐蚀、灰度膨胀、灰度开和灰度闭
- 本章的典型案例分析
- 在人脸局部图像中定位嘴的中心
- 显微镜下图像的细菌计数
- 利用顶帽变换(top-hat)技术解决光照不均问题
原文链接:https://blog.csdn.net/whuhan2013/article/details/53956606

3.2 分隔线检测
在本节中,我们首先使用LSD方法来检测分隔线,因为它比Hough变换方法更快.LSD算法主要分为三个部分:
提取线支撑区域,
矩形近似
和线段验证。
然而,LSD是用于局部提取线的算法,并且局部算法有一些缺点:两条相交的线在相交处将被分成四个段,并且由于局部检测算法的自增长特性,它由于诸如长线段的遮挡和局部模糊之类的原因,通常将其分为多条直线。
为了解决上述问题,我们提出了一种基于LSD检测结果的线聚类方法,该方法可以在各种光照和地面条件下准确识别停车位标记。
停车槽有两个主要的几何特征,如图6所示。一个是分隔线由两条固定距离为w2的平行线组成。
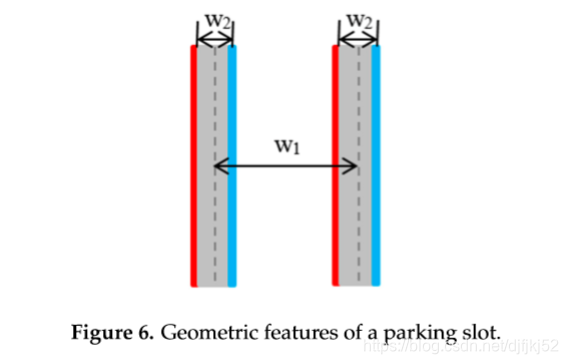
如果红线和蓝线的方向角相同,并且红线和蓝线之间的距离在w2的范围内,则将检测到分隔线。
另一个是如果两条分隔线之间的距离在w1的某个范围内,则它们可以形成一个停车位。
与[12]中的方法不同,所提出的方法忽略了两条平行线的坡度相反的性质。
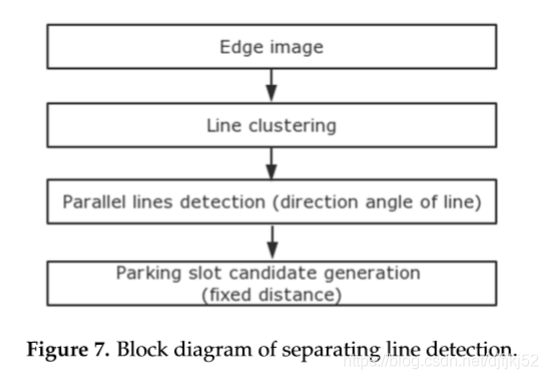
该过程利用基于先前预处理结果的行聚类方法,它包含四个主要步骤。图7显示了此过程的框图。
对于给定的边缘图像,如图8a所示,首先对其执行LSD算法。
根据LSD的检测结果,设置一个长度阈值,如果直线段的长度小于给定的阈值,则不保留直线,从而可以提高后期处理的效率。图8b示出了通过LSD方法的检测结果。
下一步是线聚类。
现有的聚类方法主要用于解决复杂轨迹的匹配和模式识别。
[29]中的方法解决了机器对机器通信类型设备之间的联盟形成和资源管理的问题。
[30,31]中的方法适用于无线电网络架构。
在[32]中,提出了一种简单的线聚类方法,它采用熵理论和概率分布函数进行参数选择,以获得聚类结果。
在本文中,我们提出了一种线聚类方法,并且在算法1中给出了线聚类规则。算法1的平均运行时间为0.4 s。
在这里,{L}表示通过LSD方法检测到的所有直线,ε和θ分别是距离和角度阈值。根据图8c所示的线聚类结果,我们计算出每条直线的方向角。
在实践中,为了实验的有效性,如果方向角在−8至8度之间,则将直线视为平行线。几何约束,我们可以消除错误的分隔线。与之前的[15]中的LSD方法相比,行聚类方法获得了更准确和鲁棒的检测结果


Parking Slot Entrance Detection
停车位入口检测
由于候选停车位不包含停车方向信息,因此它们无法帮助驾驶员方便,安全地停车。 对于停车位,我们首先利用基于线聚类的算法来检测垂直于分隔线的引导线。
如果检测到的指导线的数量大于1,我们将使用基于学习的方法来重新检测指导线的T形或L形标记点。
通过标记点的位置,我们可以获得真实的指导线,并去除了错误的指导线,如图9所示。

标记点识别系统的一种典型的基于学习的方法如图10所示。
系统以T形或L形标记点为输入,并以分类结果为输出。
从复杂的背景对停车位的标记点进行检测和细分。
通常,需要对其进行预处理,并且这种预处理
在识别性能上有相当大的飞跃。
预处理主要需要规范化所获得的正方形区域的大小,并将彩色图像转换为灰度图像以加快处理速度。
特征提取和类别识别识别是整个系统的核心,直接决定最终识别的性能。
通常,特征提取实际上是对图像块进行线性或非线性变换编码的过程。
这使得图像块由低维数据表示,以减少计算成本,并导致维数减少。
分类识别用于为目标分类或识别选择一种或多种分类算法。
提出的机器学习方法是一种模式识别技术,用于对数据进行分类
训练样本和可涵盖各种情况的测试样本。然后,使用统计方法对训练样本进行分析,这主要包括分析样本的特征和样本特征值的分布,最后对样本进行正确分类。
训练样本分为正样本和负样本。
正样本是一个包含要测量的标记点的图像,可以从包含要测量的对象的图片中生成该图像,也可以从一系列标记的图形中创建该图像。
负样本是指任何不包含要测量的标记点的图像,必须手动准备负样本。
测试样本用于检查分类器的合理性问题。
他们需要根据测试样本的结果修改分类器。
这是一个反复的过程,但是由于该领域缺少样本集,并且以前的研究都基于AVM图像,因此它们只能处理一种视图。
因此,我们提出了一种多视图融合方法,其中对鸟瞰图像执行向后透视变换,这大大增加了训练样本的数量。
所提出的方法比以前的研究具有更高的适用性。
考虑到实时性,容错性和可伸缩性要求,我们利用级联分类器,Haar特征[34]和LBP特征[35]。
AdaBoost [36]方法针对不同的训练集训练相同的分类器(弱分类器)
然后结合在不同训练集上获得的这些分类器,形成更强大的最终分类器(强分类器)。
与[12,16]中提出的早期方法相比,
我们仅训练一个分类器,即所有T形和L形拐角都视为正样本,最后使用convex defect method 凸缺陷法判断标记点的形状,如图11所示。
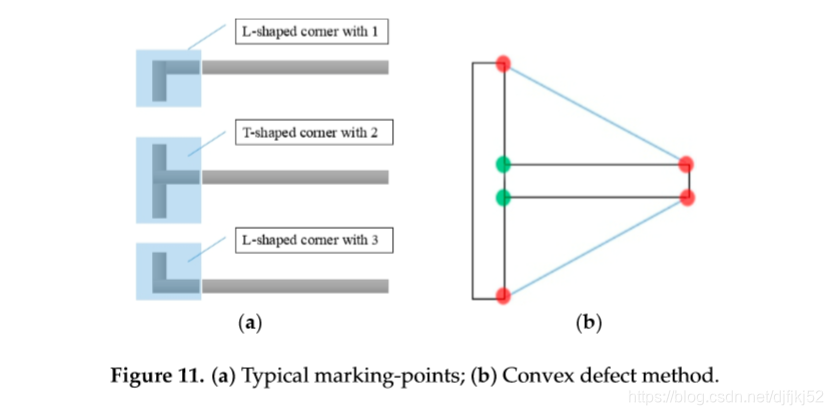
在图11b中,黑线表示检测到的轮廓,蓝线表示凸包,红点表示起点和终点,绿点表示最远的点,蓝线和两者之间的区域黑色垂直线称为缺陷。
判断规则在算法2中给出,算法2的平均运行时间为0.9 s。
此处,i表示缺陷数;defects(i)(0)和defects(i)(1)分别指示起点和终点;defects(i)(2)指示最远点;defects(i )(3)表示最远点到凸包的距离。距离是预定义的阈值。
本文介绍的方法具有更强大的检测结果。在图12中,显示了检测结果

图12中的结果表明,基于机器学习的方法效果很好,它可以正确识别三个标记点的七种标记条件,蓝色框表示标记点的位置,旁边的数字表示拐角的类型,因此1和3表示L -形,2表示T形。

源语言: 英语
826/5000
3.4。停车位占用分类
这是本文提出的方法的最后一步。
目前,大多数基于传统视觉的停车位检测算法尚未对停车位的占用进行分类。
实际上,停车系统的主要目的是找到一个有效的空停车位。
文献[12]中的方法基于超声波传感器对占用率进行分类,与文献[12]不同,文献[15]中的方法采用灰色直方图对停车位占用率进行分类。
在这项研究中,我们没有提出一种新的分类方法;我们利用了灰色直方图。
这个过程不是我们的贡献。图13显示了住宿分类结果。
绿色框表示停车位是空的,红色框表示停车位已被占用

结论
停车位检测是自动停车系统的重要方面,但是尚未开发出精确的基于视觉的停车位检测方法。
在本文中,我们提出了一种基于几何特征的停车位标记检测方法,该方法涉及三个显着方面。
首先,我们提出了一种可以在各种复杂的光照和地面条件下识别停车位标记的直线聚类方法。
其次,我们提出了一种基于多视图融合的方法,可以增加训练样本的数量,提高检测结果的准确性。
在我们的测试数据库上对实验进行了评估,该方法的性能优于单眼视图方法。最后,我们只训练了一个检测器,然后利用convex defect凸形缺陷识别标记点的T形或L形。
由于该方法的运行时间无法满足实时性要求,因此我们将在以后尝试降低方案的复杂度,另外,由于深度学习具有较高的准确检测性能,因此我们打算在停车位检测中使用深度学习。
但是,深度学习需要大量可以在将来累积的标记样本。

















 5559
5559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









