







 本文详细介绍了多目标跟踪(MOT)中的Tracking-by-detection方法,特别是数据关联技术,包括关系图、流行的关联方法如SORT、DeepSORT和MOTDT,以及GNN在数据关联中的应用。重点讨论了卡尔曼滤波、运动相似性、Re-ID和不同匹配策略。文中还比较了Hungarian算法、GNN和贪婪算法在数据关联中的作用。
本文详细介绍了多目标跟踪(MOT)中的Tracking-by-detection方法,特别是数据关联技术,包括关系图、流行的关联方法如SORT、DeepSORT和MOTDT,以及GNN在数据关联中的应用。重点讨论了卡尔曼滤波、运动相似性、Re-ID和不同匹配策略。文中还比较了Hungarian算法、GNN和贪婪算法在数据关联中的作用。
这个领域有一些专有名词需要大家清楚!
文章目录
1 Tracking-by-detection multi-object tracking(MOT) 范式跟踪器是什么?
- 视频序列中目标的检测和跟踪,带有id。
- 集成目标检测和数据关联技术
1.1 关系图(个人理解,如有错误请指正)
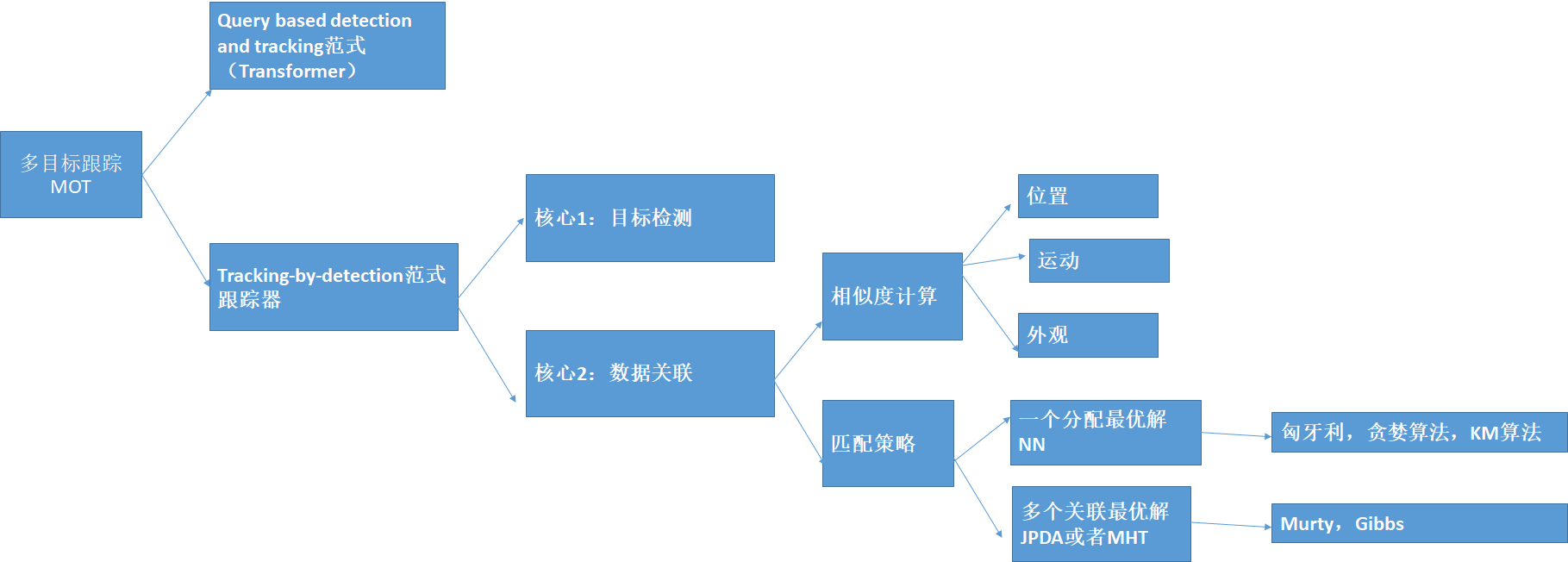
1.2 跟踪器有哪些?
- 实现MOT的跟踪的具体的方法,属于集成软件包。我们可以把数据关联方法应用进入具体的跟踪器。
- 熟知的9个不同的最先进的跟踪器,包括JDE [69], CSTrack [33], FairMOT [85], TraDes [71], QDTrack [47], CenterTrack [89], Chained-Tracker [48], TransTrack[59]和MOTR[80]。
- 在这些跟踪器中,JDE、CSTrack、FairMOT、TraDes采用了运动相似性和ReID相似性相结合的方法。
- QDTrack仅采用Re-ID相似性。
- CenterTrack和TraDes通过学习网络预测运动相似性。
- chain - tracker采用链式结构,同时输出两个连续帧的结果,并通过借据在同一帧中进行关联。
- TransTrack和MOTR采用注意机制在帧间传播框。
2、核心部分“数据关联”方法是什么?data association method?
2.1 解释
- 数据关联是Tracking-by-detection 多目标跟踪的核心,首先计算轨迹与检测盒之间的相似度,并根据相似度利用不同的策略进行匹配。
- 因此,分为两个层次:相似度计算Similarity metrics 和 匹配策略 Matching strategy。
- 我们熟知的其他的数据关联方法有:包括SORT[6]、DeepSORT[70]和MOTDT[12]
- 继续说,Similarity metrics 包括 Location, motion and appearance are useful cues for association.
- 如果是 location 的相似度,首先采用卡尔曼滤波[29]来预测轨迹的位置,然后计算出检测框与预测框之间的 IoU 作为相似度。
- motion 相似度,最近的一些方法[59,71,89]设计网络来学习目标运动,并在大的摄像机运动或低帧率的情况下获得更稳健的结果。
- 外观相似度,可以通过Re-ID特征的余弦相似度来度量。DeepSORT[70]采用独立的Re-ID模型从检测框中提取外观特征。近年来,联合检测和Re-ID模型[33,39,47,69,84,85]因其简单和高效而越来越受欢迎
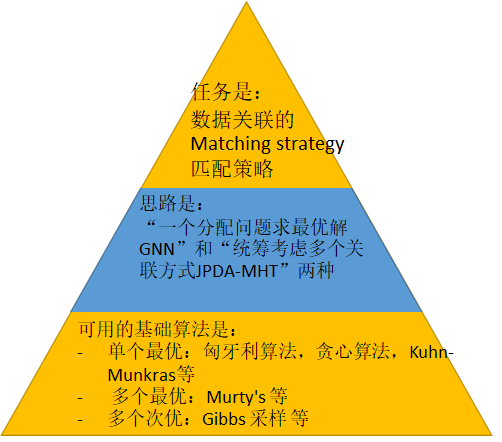
- Matching strategy 分为“一个分配问题求最优解”和“统筹考虑多个关联方式”两种。
- 求解是算法有:
- 单个最优:匈牙利算法,贪心算法,Kuhn-Munkras算法(核心思想是贪心) 等
- 多个最优:Murty’s 等
- 多个次优:Gibbs 采样 等
- 一个分配问题求最优解。在所有可能关联中,找到概率最大的一个或者几个。但很多时候,我们并不需要计算所有的可能性,只需要用一个方法找到最优解即可。从这个角度,问题变成了一个分配问题求最优解的过程。只保留一个最优关联,缺点就是抛弃了除了最优以外的所有信息,例如GNN用贪婪算法的思维,GNN属于具体的实践。
- 统筹考虑多个关联方式。多个关联方式,并且用联合概率的方式融合它们得到一个新的联合概率,以此来利用更多的信息。 最重要的两个传统方法:联合概率数据关联(JPDA)和多重假说追踪(MHT),这都是属于具体的实践。
2.2 流行的关联方法—>BYTE,SORT DeepSORT MOTDT
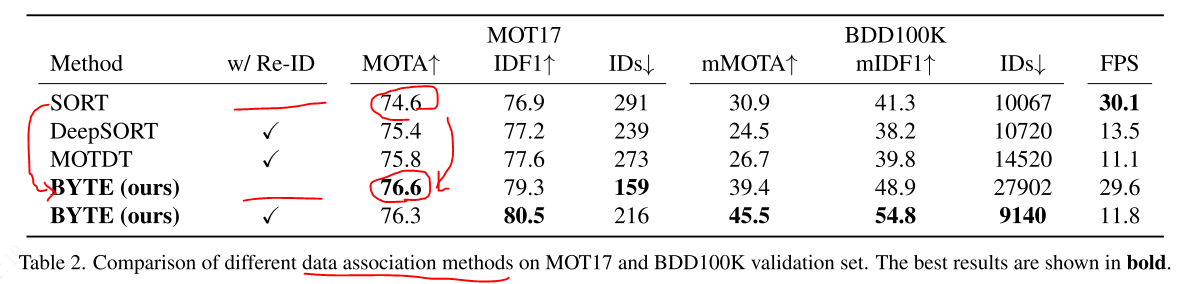
流行的关联方法进行比较,包括BYTE,SORT[6]、DeepSORT[70]和MOTDT[12]。
SORT方法可以看作是我们的基线方法,因为这两种方法都只采用卡尔曼滤波来预测物体运动。我们可以发现BYTE将SORT的MOTA度量从74.6提高到76.6,IDF1从76.9提高到79.3,id从291减少到159。这突出了低分数检测盒的重要性,并证明了BYTE从低分数1恢复对象盒的能力。
DeepSORT利用额外的Re-ID模型来增强远程关联。我们惊奇地发现,与DeepSORT相比,BYTE也有额外的收益。这表明,简单的卡尔曼滤波可以实现远程关联,并在检测框足够准确的情况下实现更好的IDF1和id。我们注意到,在严重闭塞的情况下,Re-ID特征是脆弱的,可能导致身份切换,而运动模型的行为更可靠。
MOTDT集成了运动引导盒传播结果和检测结果,将不可靠的检测结果与轨迹关联起来。尽管有着相似的动机,但MOTDT还是远远落后于BYTE。我们解释了MOTDT使用传播的盒作为轨迹盒,这可能导致跟踪中定位漂移。相反,BYTE使用低分数的检测框来重新关联那些不匹配的轨迹,因此,轨迹框更准确。
2.3 Matching strategy 关系图(个人理解,如有错误请指正)
2.4 补充内容,GNN 和匈牙利什么关系?
20230913:
一般来说,我们讨论GNN、PDA、JPDA 作为一个level讨论。
匈牙利,KM,贪婪算法作为一个level讨论。
个人理解简单来说,数据关联就是解决数据归属的一大类方法的统称,其中就包含了GNN、JPDA和MHT这些关联思想。
要实现这种关联思想,可以进一步转换为图匹配问题,而匈牙利算法就是用来解决图匹配的。
我们看论文《SimpleTrack: Understanding and Rethinking 3D Multi-object Tracking》的表述:

一般来说,检测与轨迹之间的匹配有两种方法:
1)将问题表述为二部匹配问题(图匹配),然后使用匈牙利算法[37]进行求解。
2)采用贪婪算法迭代关联NN-nearest pairs最近的对[10,43]。
在一位吉大同学的博客里面”https://blog.csdn.net/weixin_51415327/article/details/124047853“写到
- 最近邻NN数据关联算法的优点是运算量小,易于硬件的实现,但是只能适用于稀疏目标和杂波环境的目标跟踪系统。
关联矩阵较大时,二维分配问题可Munkre算法或Burgeois算法求解,求解具多项式复杂度,非NP问题
特点:一个目标最多只与跟踪门中一个测量相关,以总关联代价(或总距离)作为关联评价标准,取总关联代价或总距离最小的关联对为正确关联对。
全局最近邻GNN,GNN的一个关键步骤是生成成本矩阵。成本矩阵是指与每次检测匹配的每条轨迹的成本
NN和GNN的不同点:
距离计算方法和NN相同,但是使总的距离或关联代价达到最小
也就是说,匈牙利算法,贪婪算法是在不同的角度去解决NN问题。匈牙利算法是图匹配角度,贪婪算法是迭代关联最近的pairs
[正文完]


















 581
581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











