







0. 概述与简介
关于UCloud(优刻得)旗下的compshare算力共享平台
UCloud(优刻得)是中国知名的中立云计算服务商,科创板上市,中国云计算第一股。
Compshare GPU算力平台隶属于UCloud,专注于提供高性价4090算力资源,配备独立IP,支持按时、按天、按月灵活计费,支持github、huggingface访问加速。
使用下方链接注册可获得20元算力金,免费体验10小时4090云算力,此外还有3090和P40,价格每小时只需要8毛,赠送的算礼金够用一整天。
https://www.compshare.cn/?ytag=GPU_lovelyyoshino_Lcsdn_csdn_display
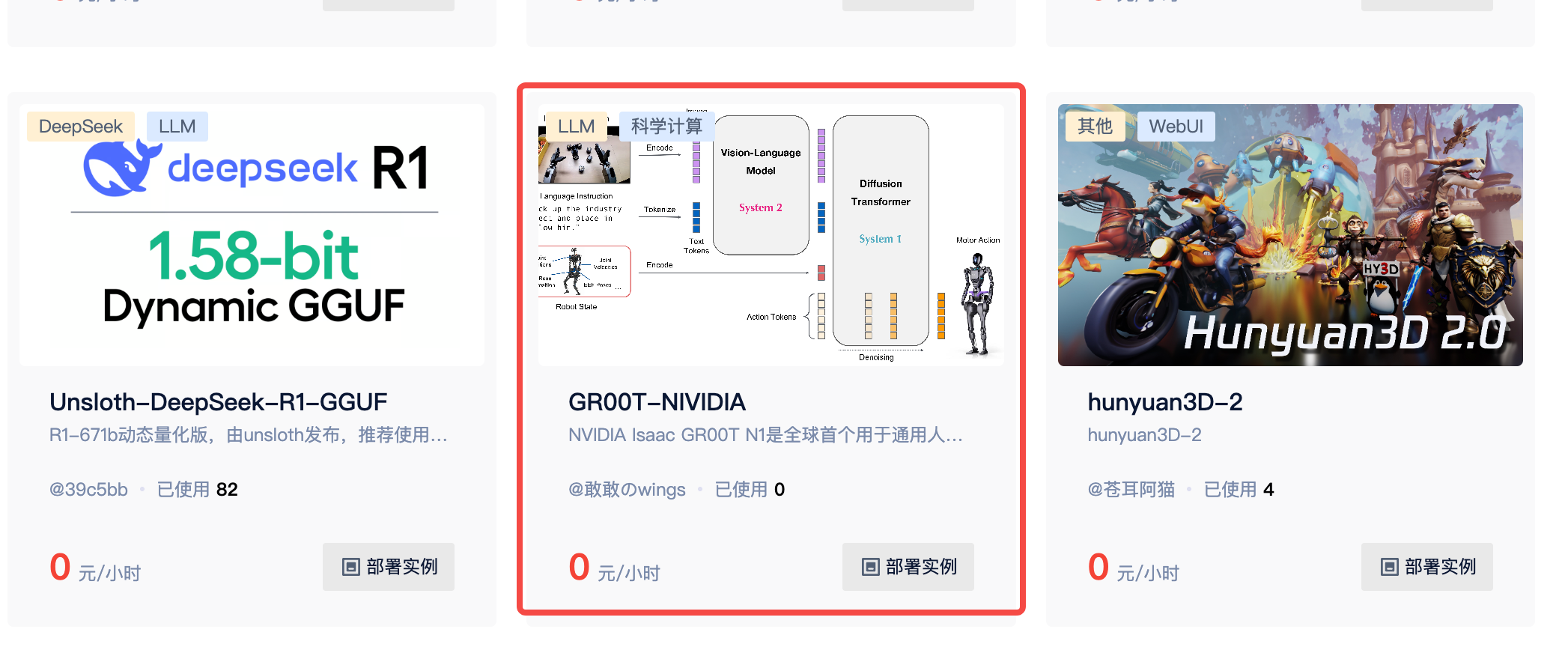
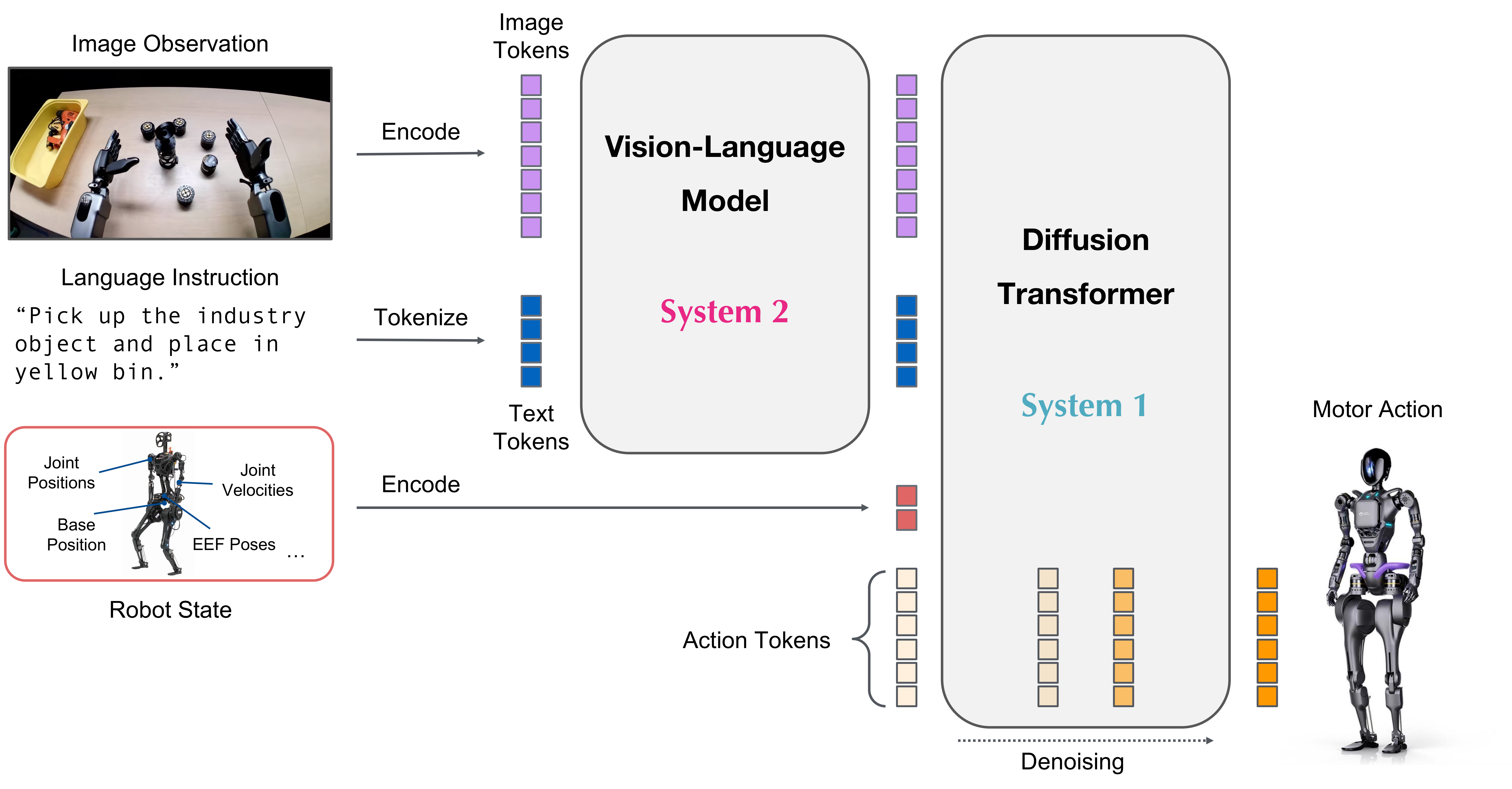
NVIDIA Isaac GR00T N1是全球首个用于通用人形机器人推理和技能的开源基础模型。这种跨实体模型可以接收多模态输入,包括语言和图像,以在各种环境中执行操作任务。GR00T的名称源自"Generalized Robot Operations and Telemetry",代表着其通用化的操作能力和遥测数据处理能力。
GR00T N1 基于广泛的人形机器人数据集进行训练,这些数据集包括真实捕获的数据、使用NVIDIA Isaac GR00T Blueprint组件生成的合成数据,以及互联网规模的视频数据。通过训练后的适应过程,它可以针对特定的机器人实体、任务和环境进行优化。

作为一个真正的基础模型,GR00T N1不仅限于特定的机器人平台或任务,而是提供了一个通用框架,可以通过少量的特定任务数据进行微调,从而适应各种不同的机器人系统和应用场景。这种通用性和适应性使其成为机器人研究和应用开发的强大工具。
目前相关镜像已经存入GR00T-NIVIDIA中了。
1. 模型架构与工作原理
GR00T N1的神经网络架构是视觉-语言基础模型与扩散变换器头部的结合,后者用于对连续动作进行去噪。整体架构如下:
- 多模态输入处理:
- 视觉模块处理视频和图像输入
- 语言模块处理文本指令和描述
- 状态编码器处理机器人的当前状态信息
- 基础模型核心:
- 结合了大型视觉-语言模型的架构
- 具有跨模态注意力机制,能够在不同输入模态之间建立关联
- 扩散变换器头部:
- 采用扩散模型,通过逐步去噪过程生成精确的连续动作
- 实现从高层次指令到低层次动作的有效映射
- 跨实体适应层:
- 允许模型适应不同的机器人形态和配置
- 通过特定的标记和参数,实现跨机器人平台的知识迁移
GR00T N1的工作流程如下:
- 用户需要收集机器人演示数据,格式为(视频、状态、动作)三元组
- 将演示数据转换为LeRobot兼容的数据模式
- 使用提供的配置示例为不同机器人实体设置不同的训练配置
- 利用提供的脚本微调预训练的GR00T N1模型
- 将
Gr00tPolicy连接到机器人控制器,在目标硬件上执行动作
这种架构使GR00T N1能够理解复杂的场景和指令,并将其转化为精确的机器人动作序列,实现高度灵活和适应性强的机器人控制。
2. 系统要求与环境准备
在开始使用NVIDIA Isaac GR00T N1之前,请确保您的系统满足以下要求:
2.1 硬件要求
- GPU:
- 微调:推荐使用H100、L40、RTX 4090或A6000 GPU
- 推理:RTX 4090或A6000已经过测试并能良好运行
- 内存:建议至少16GB RAM,对于大型数据集的处理推荐32GB或更高
- 存储:至少50GB可用空间用于模型、代码和示例数据
2.2 软件要求
- 操作系统:已在Ubuntu 20.04和22.04上测试
- CUDA版本:12.4(这是确保flash-attn模块正常工作的关键)
- Python版本:3.10
- 系统依赖:ffmpeg、libsm6、libxext6
2.3 准备工作
在开始安装之前,请确保:
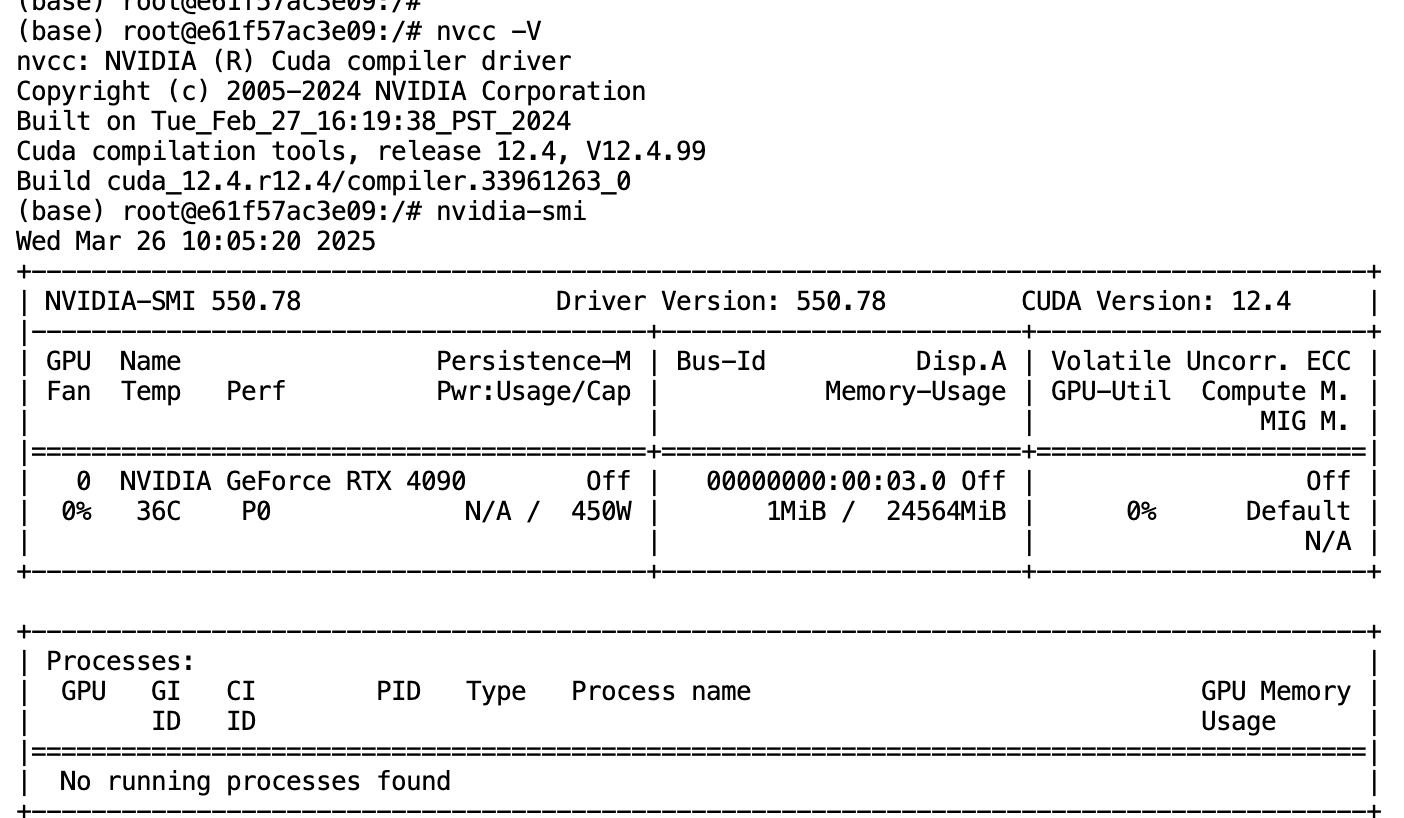
- 检查您的CUDA版本,如果尚未安装CUDA 12.4,请按照NVIDIA官方指南进行安装:
# 检查当前CUDA版本 nvcc --version # 如果需要安装或更新CUDA,请按照NVIDIA官方指南操作 wget https://developer.download.nvidia.com/compute/cuda/12.4.0/local_installers/cuda_12.4.0_550.54.14_linux.run sudo sh cuda_12.4.0_550.54.14_linux.run - 安装必要的系统依赖:
sudo apt-get update sudo apt-get install ffmpeg libsm6 libxext6 -y - 确保您的GPU驱动程序是最新的,并且与CUDA 12.4兼容。可以使用以下命令检查GPU驱动程序版本:
nvidia-smi
遵循这些准备工作将确保您的系统已准备好安装和运行NVIDIA Isaac GR00T N1。
3. 详细安装指南
以下是安装NVIDIA Isaac GR00T N1的详细步骤:
3.1 克隆代码库
首先,从GitHub上克隆Isaac-GR00T代码库:
git clone https://github.com/NVIDIA/Isaac-GR00T
cd Isaac-GR00T
3.2 创建并配置Conda环境
我们推荐使用Conda来管理Python环境,这有助于避免依赖冲突:
# 安装Miniconda(如果尚未安装)
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
# 按照提示完成安装
# 创建新的Conda环境
conda create -n gr00t python=3.10
conda activate gr00t
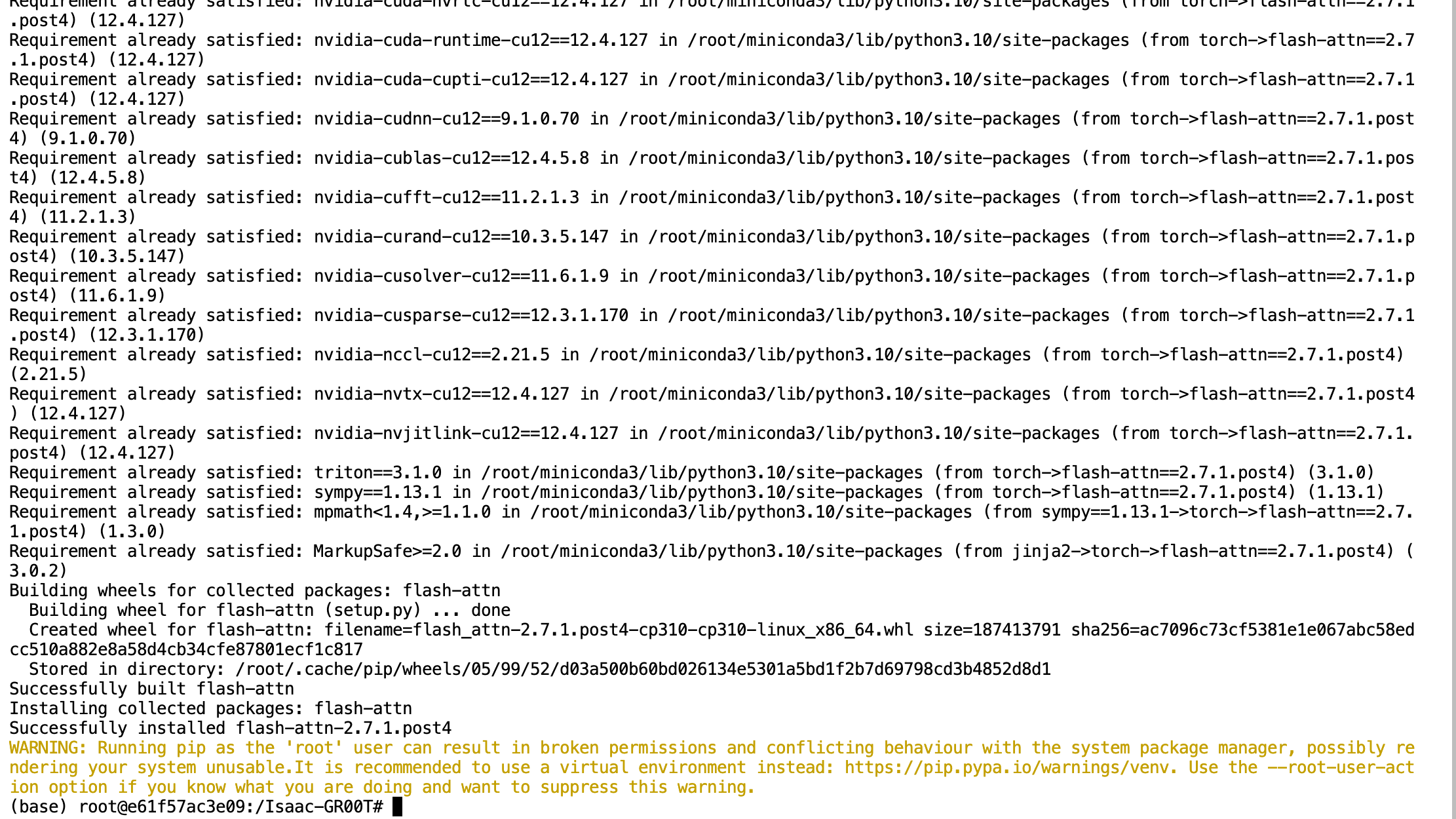
3.3 安装项目依赖
现在,在激活的Conda环境中安装GR00T所需的依赖项:
# 升级setuptools
pip install --upgrade setuptools
# 安装项目及其依赖
pip install -e .
# 特别注意:安装flash-attn时禁用构建隔离,以确保与CUDA正确兼容
pip install --no-build-isolation flash-attn==2.7.1.post4
特别提示:
flash-attn的安装可能会比较耗时,因为它需要编译CUDA扩展- 如果遇到与CUDA相关的错误,请确保您的CUDA版本正确,并且已经按照上述说明安装了正确的版本
- 对于某些系统,可能需要安装额外的编译工具,如
build-essential和ninja-build
3.4 下载示例数据(可选)
为了方便开始尝试,您可以下载提供的示例数据集:
# 如果您希望使用更完整的数据集,可以从huggingface下载
huggingface-cli download nvidia/PhysicalAI-Robotics-GR00T-X-Embodiment-Sim \
--repo-type dataset \
--include "gr1_arms_only.CanSort/**" \
--local-dir $HOME/gr00t_dataset
也可以直接使用代码库中包含的小型示例数据集(位于demo_data/robot_sim.PickNPlace目录)。

至此,您已经完成了NVIDIA Isaac GR00T N1的安装。下一步可以开始探索如何使用模型进行推理和微调。
4. 入门指南
4.1 数据格式与加载
GR00T N1使用特定的数据格式进行训练和推理,了解这种格式对于成功应用模型至关重要。
LeRobot兼容数据架构
GR00T N1使用基于Huggingface LeRobot的扩展数据模式,加入了更详细的模态和注释。这种格式的主要特点包括:
- 数据组织:数据以(视频、状态、动作)三元组的形式组织
- 文件结构:遵循特定的目录结构,包括元数据和每个示例的数据
- 模态定义:通过
modality.json文件明确定义不同的输入和输出模态
示例数据结构:
.
├── data
│ └── chunk-000
│ ├── episode_000000.parquet
│ ├── episode_000001.parquet
│ ├── episode_000002.parquet
│ ├── episode_000003.parquet
│ └── episode_000004.parquet
├── meta
│ ├── episodes.jsonl
│ ├── info.json
│ ├── modality.json
│ ├── stats.json
│ └── tasks.jsonl
└── videos
└── chunk-000
└── observation.images.ego_view
├── episode_000000.mp4
├── episode_000001.mp4
├── episode_000002.mp4
├── episode_000003.mp4
└── episode_000004.mp4
完整的数据架构说明可在getting_started/LeRobot_compatible_data_schema.md中找到。这里我们也帮助梳理一下
1. meta/episodes.jsonl
{ "episode_index": 0, "tasks": ["pick the squash from the counter and place it in the plate", "valid"], "length": 416 }
- 记录每个操作场景的基本信息
length: 场景持续的帧数tasks: 包含任务描述和有效性标记2. meta/tasks.jsonl
{ "task_index": 0, "task": "pick the squash from the counter and place it in the plate" }
- 存储所有任务的详细描述
- 与 parquet 文件中的 task_index 对应
3. data/chunk-000/episode_*.parquet
每个 parquet 文件包含以下字段:
{ "observation.state": [...], // 状态数组 "action": [...], // 动作数组 "timestamp": 0.049999, // 时间戳 "annotation.human.action.task_description": 0, // 任务描述索引 "task_index": 0, // 任务索引 "annotation.human.validity": 1, // 有效性标记 "episode_index": 0, // 场景索引 "index": 0, // 全局观测索引 "next.reward": 0, // 下一步奖励 "next.done": false // 场景是否结束 }4. meta/modality.json
{ "state": { "left_arm": { "start": 0, "end": 7 }, // ... 其他状态定义 }, "action": { "left_arm": { "start": 0, "end": 7 }, // ... 其他动作定义 }, "video": { "ego_view": { "original_key": "observation.images.ego_view" } }, "annotation": { "human.action.task_description": {}, "human.validity": {} } }
- 定义了状态和动作数组的结构
- 指定视频观测的映射关系
- 声明数据集中的注释类型
特点
- 标准化数据格式:遵循 LeRobot V2.0 规范。其他内容可以参考LeRobot 机器人大脑的输入输出、(五)lerobot开源项目的主从臂采集数据(操作记录)。
- 完整的任务记录:包含状态、动作、视觉和注释信息
- 模块化组织:清晰的目录结构便于管理和访问
- 丰富的元数据:通过 modality.json 提供详细的数据解释
数据加载示例
以下是加载数据集的Python代码示例:
from gr00t.data.dataset import LeRobotSingleDataset
from gr00t.data.embodiment_tags import EmbodimentTag
from gr00t.experiment.data_config import DATA_CONFIG_MAP
# 获取数据配置
data_config = DATA_CONFIG_MAP["gr1_arms_only"]
# 获取模态配置和转换
modality_config = data_config.modality_config()
transforms = data_config.transform()
# 创建LeRobotSingleDataset对象加载数据
dataset = LeRobotSingleDataset(
dataset_path="demo_data/robot_sim.PickNPlace",
modality_configs=modality_config,
transforms=None, # 可以选择不应用任何转换
embodiment_tag=EmbodimentTag.GR1, # 使用的实体标签
)
# 访问数据示例
sample = dataset[5]
为了更深入地了解数据加载过程,您可以:
- 查看交互式教程:
getting_started/0_load_dataset.ipynb - 或运行示例脚本:
python scripts/load_dataset.py
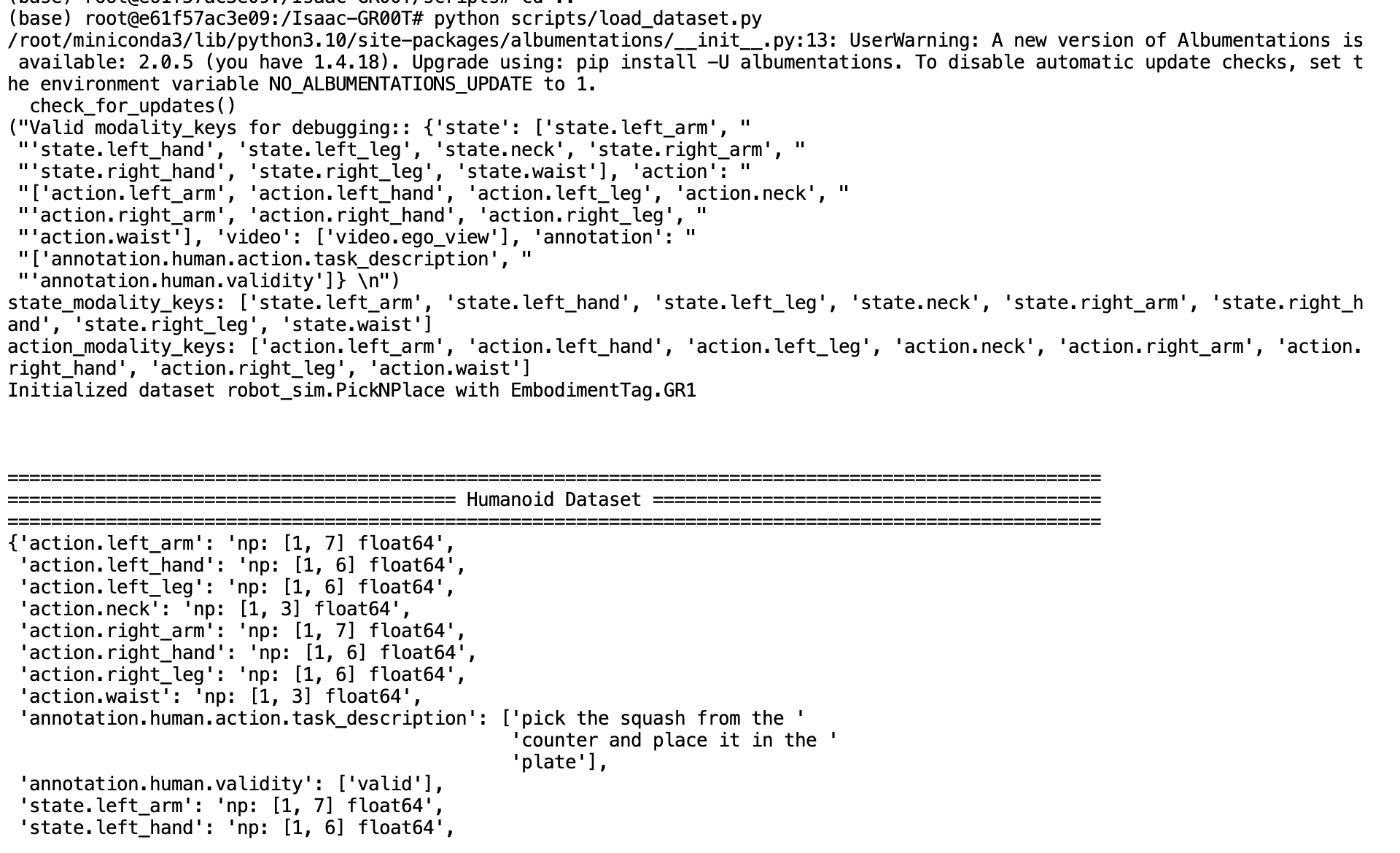
关键概念解释
- 模态配置(Modality Config):定义数据集中使用的模态(例如视频、状态、动作)的配置对象
- 实体标签(Embodiment Tag):定义使用的机器人实体,预训练模型支持特定标签,如GR1
- 转换配置(Transform Config):定义在数据加载过程中应用于数据的转换
4.2 模型推理
一旦数据准备好,您可以使用预训练的GR00T N1模型进行推理。这一过程涉及加载模型并使用它来预测机器人动作。
基本推理流程
以下是使用预训练模型进行推理的基本代码:
from gr00t.model.policy import Gr00tPolicy
from gr00t.data.embodiment_tags import EmbodimentTag
# 1. 加载模态配置和转换(与上面数据加载部分相同)
modality_config = data_config.modality_config()
transforms = data_config.transform()
# 2. 加载数据集
dataset = LeRobotSingleDataset(
dataset_path="demo_data/robot_sim.PickNPlace",
modality_configs=modality_config,
transforms=None,
embodiment_tag=EmbodimentTag.GR1,
)
# 3. 加载预训练模型
policy = Gr00tPolicy(
model_path="nvidia/GR00T-N1-2B", # Huggingface上的模型路径
modality_config=modality_config,
modality_transform=transforms,
embodiment_tag=EmbodimentTag.GR1,
device="cuda" # 指定运行设备
)
# 4. 执行推理
action_chunk = policy.get_action(dataset[0])
更详细的推理教程可以在getting_started/1_gr00t_inference.ipynb中找到。
推理服务
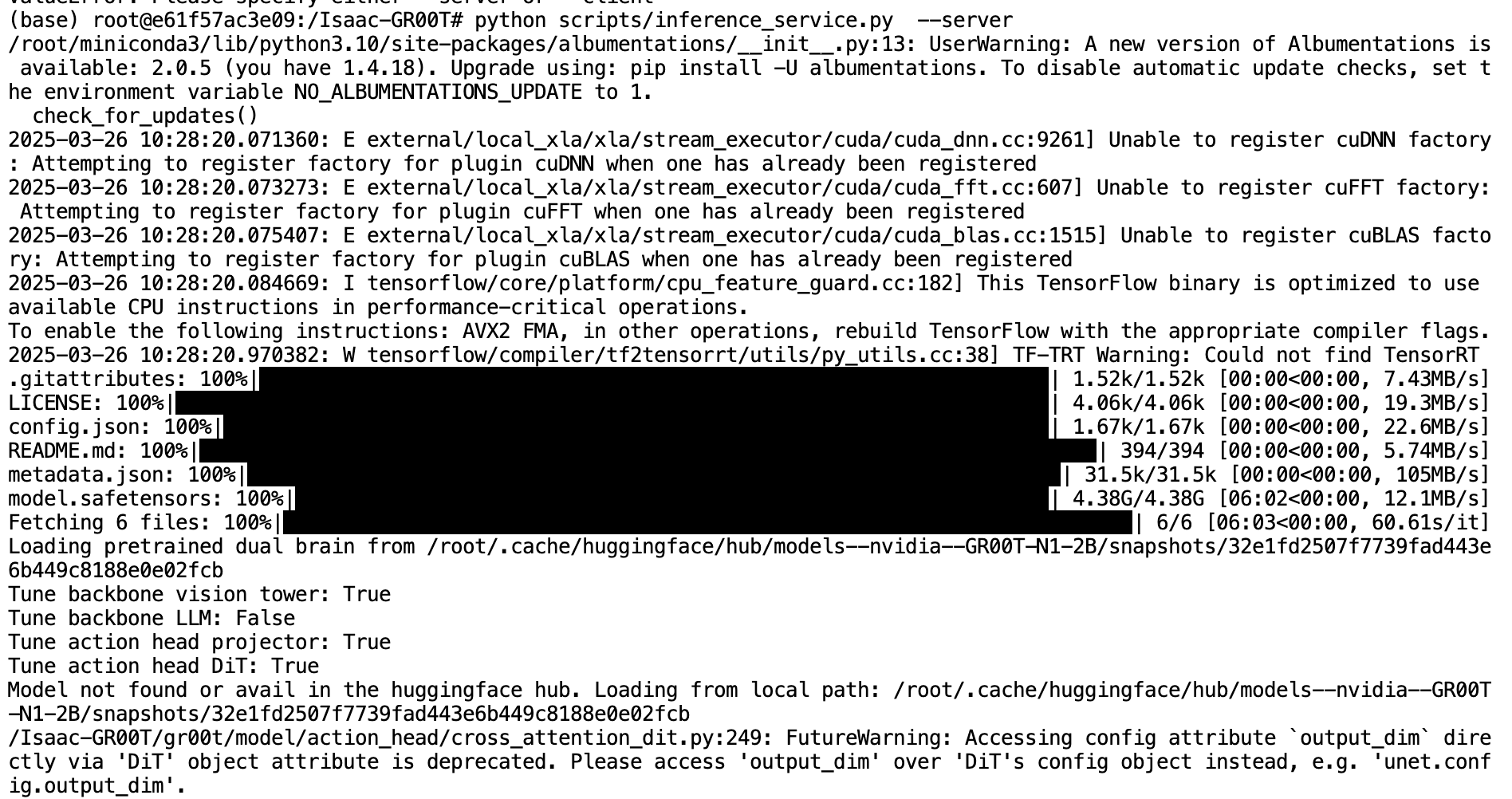
GR00T还提供了一个推理服务,可以在服务器模式或客户端模式下运行:
- 启动服务器模式:
python scripts/inference_service.py --server
- 在另一个终端中运行客户端模式向服务器发送请求:
python scripts/inference_service.py --client
这种服务架构使您能够将模型部署为持久化服务,并从不同的客户端发送请求,这对于实际的机器人应用非常有用。
推理性能
在单个样本处理场景下,GR00T N1的推理速度非常高效:
| 模块 | 推理速度 |
|---|---|
| VLM骨干网络 | 22.92毫秒 |
| 含4步扩散的动作头部 | 4 x 9.90毫秒 = 39.61毫秒 |
| 完整模型 | 62.53毫秒 |
值得注意的是,在推理过程中4个去噪步骤通常就足够了,这使得模型能够在大约60毫秒内完成一次完整的推理,适合实时控制应用。
4.3 模型微调
GR00T N1的一个主要优势是它可以通过微调来适应新的任务和环境。微调过程使用您自己的数据来调整预训练模型的参数,使其更好地适应特定任务。
基本微调流程
使用提供的微调脚本可以轻松地在示例数据集上微调模型:
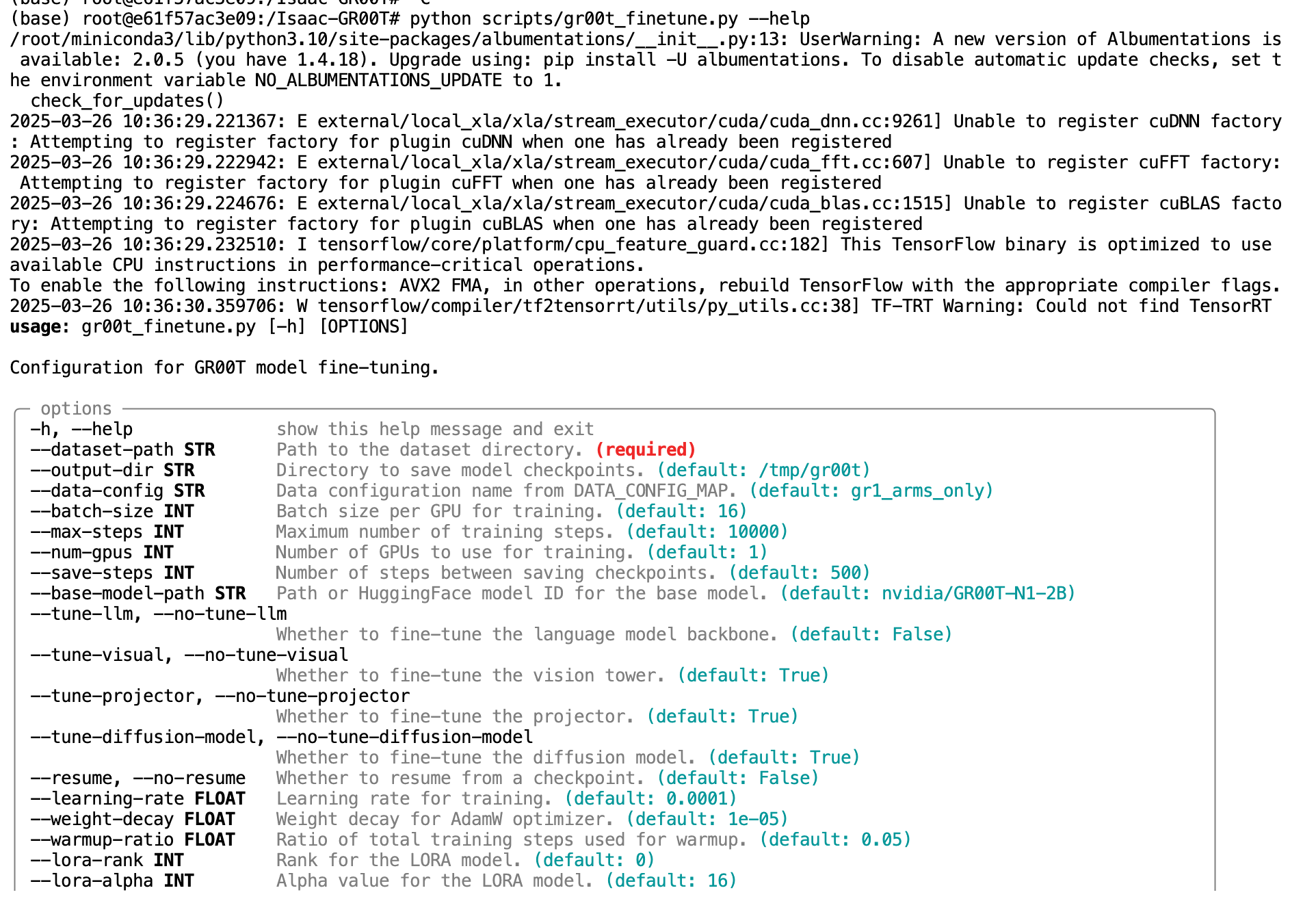
- 查看微调脚本的可用参数:
python scripts/gr00t_finetune.py --help
- 使用标准微调运行脚本:
python scripts/gr00t_finetune.py --dataset-path ./demo_data/robot_sim.PickNPlace --num-gpus 1
- 或者使用LoRA参数高效微调:
python scripts/gr00t_finetune.py --dataset-path ./demo_data/robot_sim.PickNPlace --num-gpus 1 --lora_rank 64 --lora_alpha 128 --batch-size 32
LoRA(Low-Rank Adaptation)是一种参数高效的微调技术,可以显著减少需要更新的参数数量,同时保持良好的性能。这对于计算资源有限的情况特别有用。
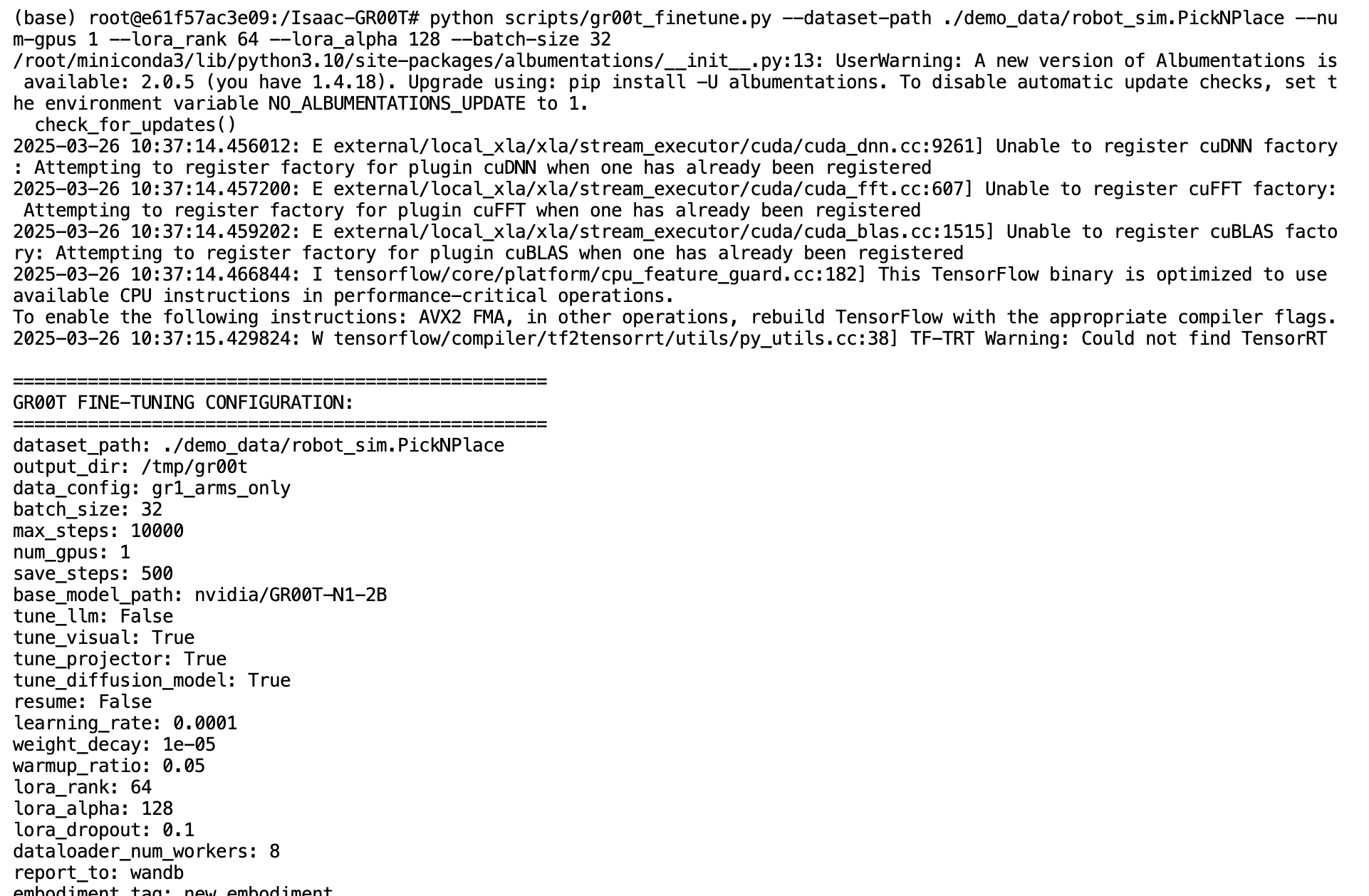
这里我演示的是我的账号,你需要用下面的来切换成你的wandb账号
wandb login --relogin
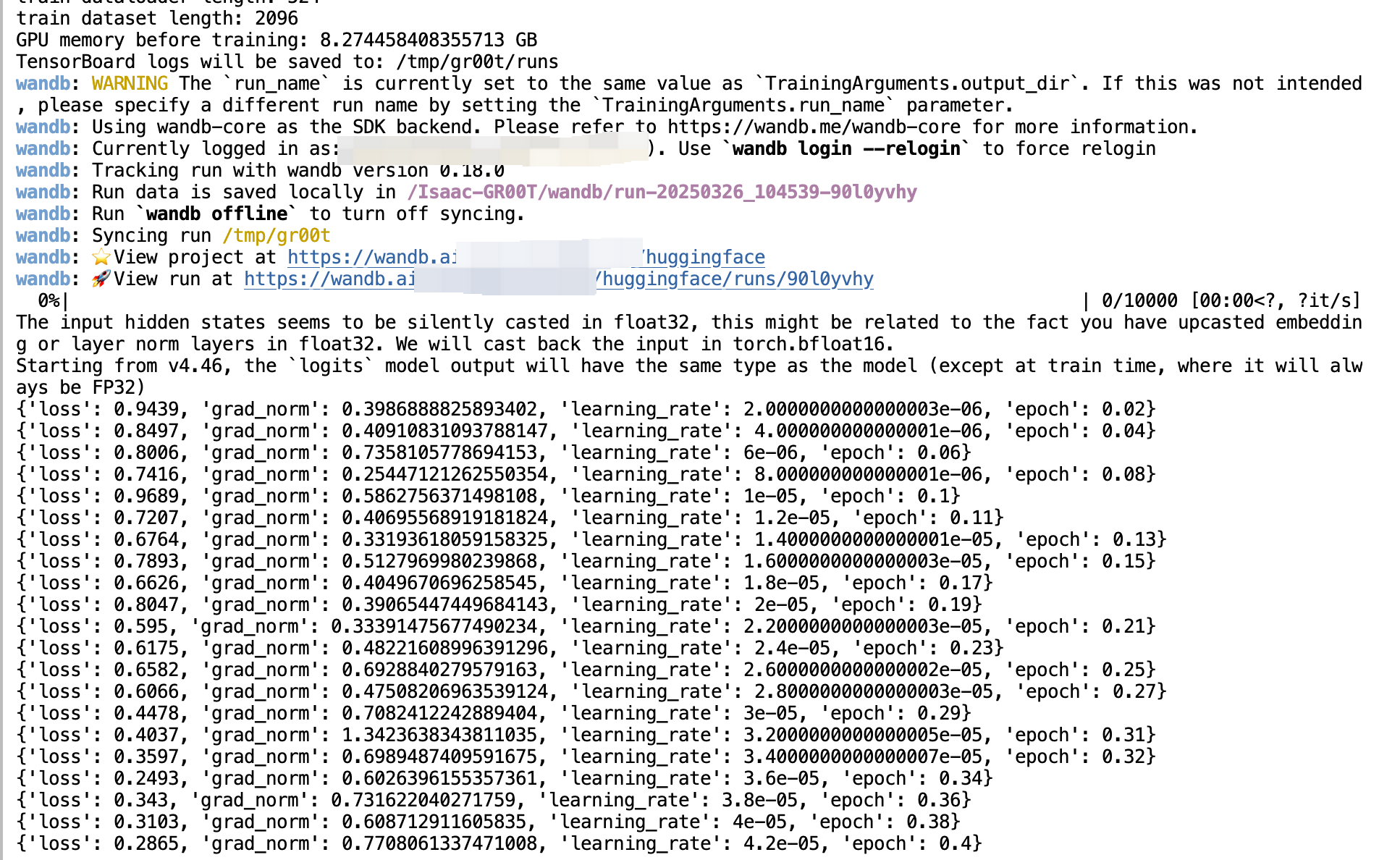
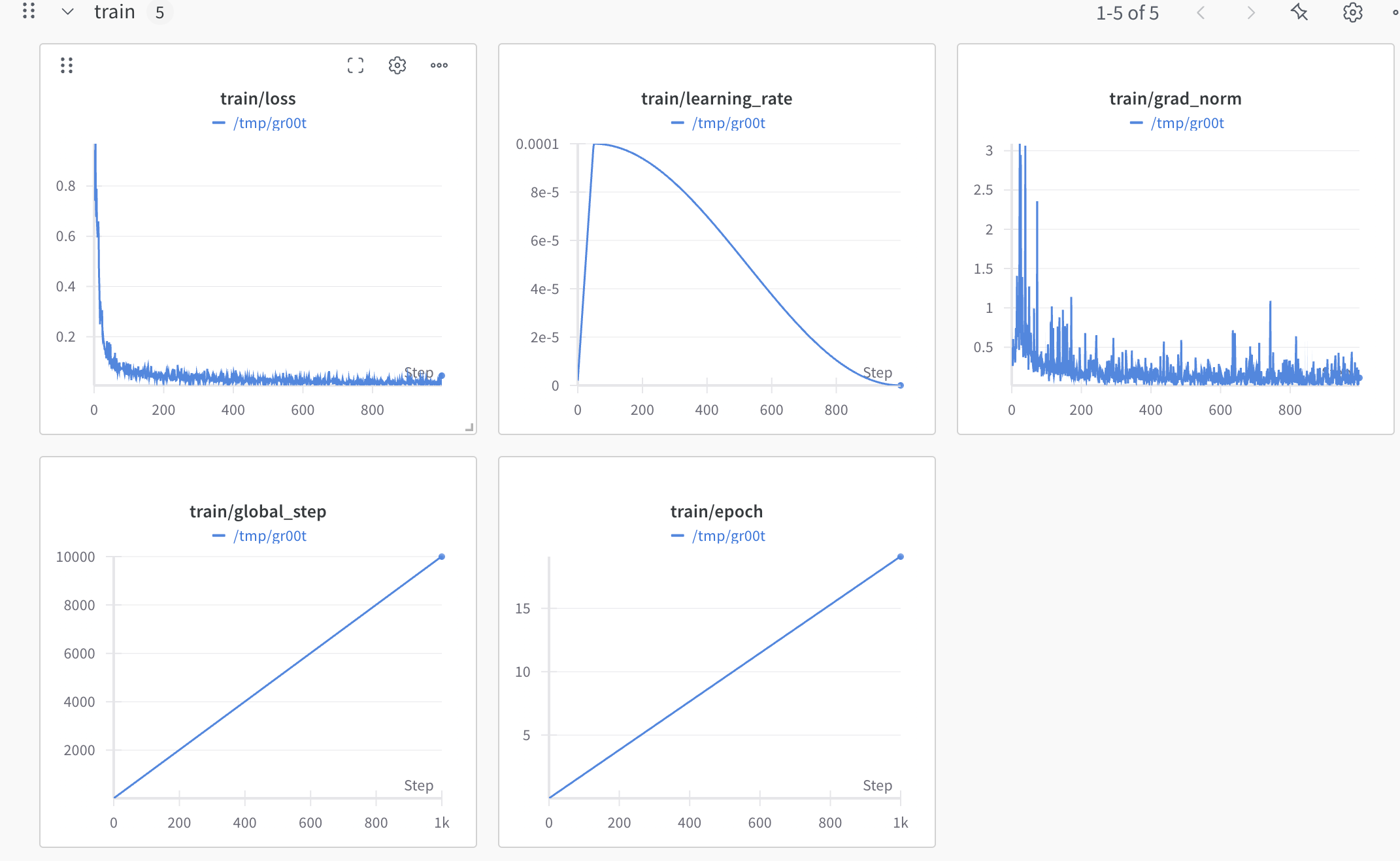
微调配置建议
为了获得最佳微调效果,建议:
- 将批量大小调整到硬件允许的最大值
- 训练约20,000步
- 对于新实体的微调,请参考
getting_started/3_new_embodiment_finetuning.ipynb
使用更大的数据集
您也可以从Huggingface下载更大的模拟数据集进行微调:
huggingface-cli download nvidia/PhysicalAI-Robotics-GR00T-X-Embodiment-Sim \
--repo-type dataset \
--include "gr1_arms_only.CanSort/**" \
--local-dir $HOME/gr00t_dataset
然后使用这个数据集路径进行微调:
python scripts/gr00t_finetune.py --dataset-path $HOME/gr00t_dataset/gr1_arms_only.CanSort --num-gpus 1
4.4 模型评估
评估微调后的模型性能是确保其有效性的重要步骤。GR00T提供了一个离线评估脚本,可以评估模型在数据集上的表现并生成可视化结果。
评估流程
- 首先运行推理服务,加载您的模型:
python scripts/inference_service.py --server \
--model_path <MODEL_PATH> \
--embodiment_tag new_embodiment
#python scripts/inference_service.py --server \
# --model_path /tmp/gr00t/checkpoint-10000/ \
# --embodiment_tag new_embodiment

- 然后运行离线评估脚本:
python scripts/eval_policy.py --plot \
--dataset_path <DATASET_PATH> \
--embodiment_tag new_embodiment
# python scripts/eval_policy.py --plot --dataset_path ./demo_data/robot_sim.PickNPlace --embodiment_tag new_embodiment
值得一提,原本代码默认是annotation.human.coarse_action但是实际上数据modality.json当中没有这个json,需要用自己官方的数据需要手动修改,虽然是空的,但是必须要有。
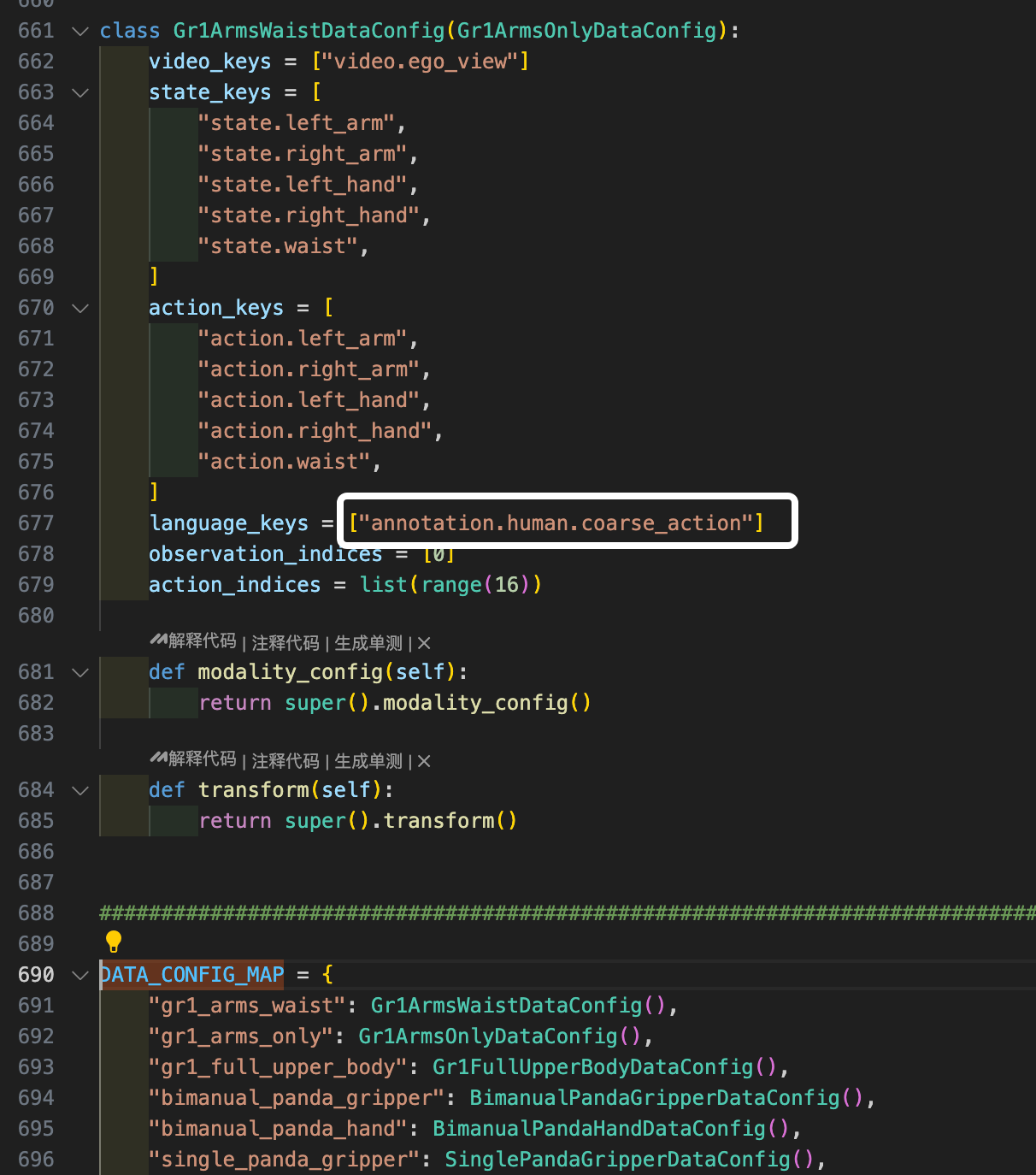
这将生成真实动作与预测动作的对比图,以及动作的非归一化均方误差(MSE)。这些指标可以帮助您判断策略在数据集上的表现如何。

评估指标解读
- 均方误差(MSE):衡量预测动作与真实动作之间的平均差异
- 轨迹对比:直观展示预测轨迹与真实轨迹的吻合度
- 成功率:如果有任务成功/失败的标记,也可以计算成功率
通过这些评估,您可以确定是否需要进一步微调模型,或者模型是否已经准备好部署到实际应用中。
5. 总结
NVIDIA Isaac GR00T N1作为世界首个通用人形机器人基础模型,为机器人领域带来了突破性的进展。它通过创新的多模态架构,将视觉、语言和状态信息有机结合,实现了从高层指令到精确动作的端到端映射。其核心优势在于跨平台适应性强、推理速度快(约60毫秒/次)以及灵活的微调机制,这使得它能够快速适应不同的机器人平台和任务场景。
该模型采用标准化的数据格式和完整的工具链支持,使得从数据收集、模型训练到部署评估的全流程都变得清晰可控。特别是通过LoRA等参数高效的微调技术,即使在计算资源受限的情况下也能实现良好的任务适应。这些特性使GR00T N1不仅适合研究用途,更能在实际应用中发挥重要作用,为推动机器人技术的普及和发展提供了有力支撑。


















 1363
1363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











