







一、TL;DR
- 继承InternVL 2.0核心模型架构的基础上,系统地探索了视觉编码器、语言模型、数据集大小以及测试时配置的性能趋势,应该还有一个(预)训练策略
- 第一个在MMMU基准测试中超过70%的开源MLLM,通过链式思维(CoT)推理实现了涨点3.7%
- 探索了一种data filter的数据方式,确保数据的高质量(MLLM去重,filter+人工)
二、方法和贡献
2.1 为什么要提出InternVL2.5?
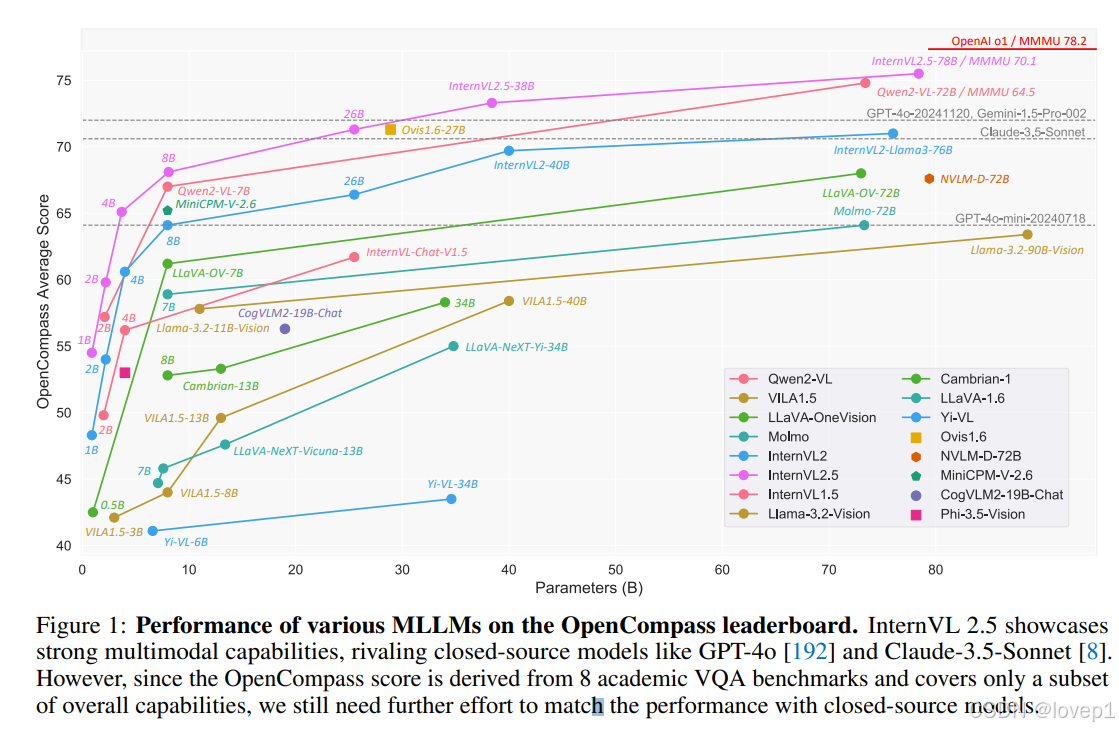
闭源商业模型等GPT-4o[和Claude-3.5-Sonnet的表现一骑绝尘,InternVL系列和Qwen-VL在性能和效率方面仍未达到理想水平。
2.2 整体方法和贡献
在InternVL 2.5中,系统地研究了MLLM中的各种因素,包括视觉编码器、语言模型、数据集大小和推理时间的变化如何影响模型的整体性能,揭示了多模态模型中扩展与性能之间的关系。具体来说:
- 大型视觉编码器在扩展MLLMs时显著减少了对训练数据的依赖。Qwen2-VL-72B是0.6B,InternVL2.5-78B的视觉编码器是6B,仅使用1/10训练token就能实现更好的性能
- 数据质量至关重要。InternVL的数据集翻了一倍(InternVL2.0 -> 2.5),但严格的筛选极大地提高了质量
- 测试时扩展对复杂的多模态问答有益。对于像MMMU这样的艰巨任务,配备CoT的InternVL2.5-78B达到了70.1%,比直接回答高出3.7个百分点。随后,我们成功验证了CoT可以进一步与多数投票相结合,带来额外的改进。
我们的贡献可以总结如下:
- 将InternVL 2.5开源(包括代码、模型和训练方式等)。
- 研究了扩展MLLMs的不同组成部分(如视觉编码器、语言模型、数据集大小和推理时间)如何影响性能。
- 通过在多种基准测试,InternVL 2.5效果比肩GPT-4o和Claude-3.5-Sonnet等闭源模型,是第一个MMMU验证集超过70%的MLLM
- 评估领域包括多学科推理、文档理解、多图像/视频理解、现实世界理解、多模态幻觉检测、视觉定位、多语言能力和纯语言处理
三、模型结构
3.1 总体结构
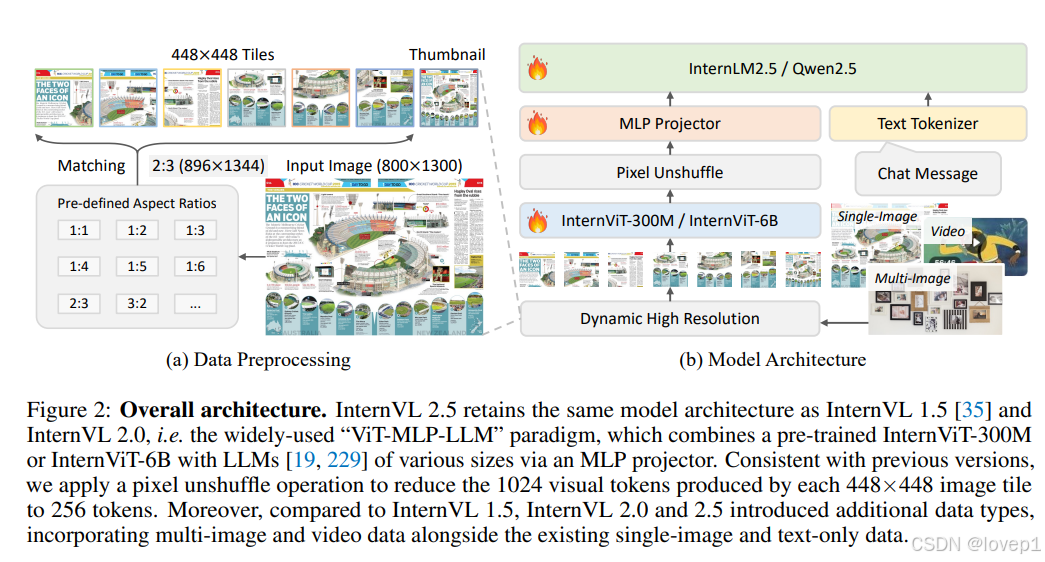
InternVL 2.5保留了InternVL 1.5 和InternVL 2.0的相同模型架构,遵循了广泛采用的“ViT-MLP-LLM”范式,视觉encoder使用了预训练的InternViT-6B或InternViT-300M,并与不同大小和类型包括InternLM 2. 5和Qwen 2.5的LLM进行组合。
从InternVL 2.0开始,关键区别是额外引入了对多图像和视频数据的支持,如图下图右边所示。不同类型的数据对应不同的预处理配置,后文详细说明。
3.2 视觉编码器
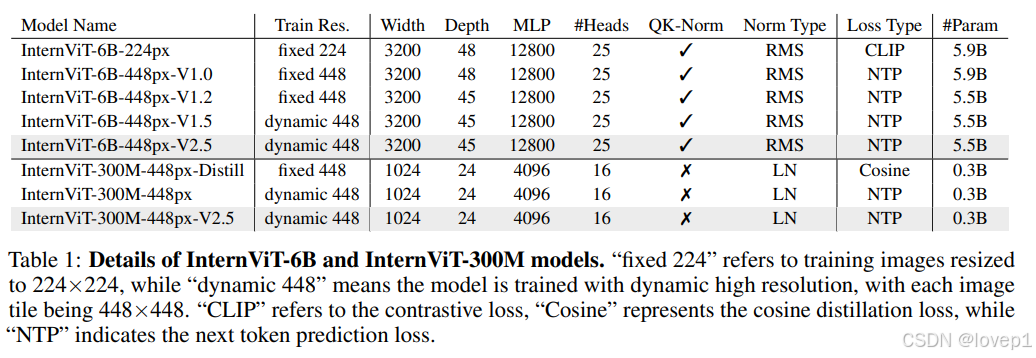
InternVL使用InternViT [36]作为视觉编码器。为了更好地记录InternViT的训练进展,我们在表1中提供了详细信息。InternViT就只有2种vision encode:InternViT-6B和InternViT-300M。
InternViT-6B
stage1-1.5:将InternViT-6B通过MLP投影器连接到一个LLM,并在短暂的MLP模块warm up之后,使用下一个token预测损失(如图(a)所示)联合训练InternViT-6B,以增强其视觉特征提取能力。
如InternVL 1.5所述,移除了InternViT-6B-448px-V1.2的最后三层,将其深度从48层减少到45层,因为这些层更多地被调整到CLIP损失目标上,优先考虑全局对齐而非局部信息。因此,包括最新的InternViT-6B-448px-V2.5在内的所有后续版本,都拥有45层和55亿参数。
InternViT-300M
InternViT-300M-448px-Distill是teacher模型InternViT-6B-448px-V1.5的蒸馏变体,使用余弦蒸馏损失。该模型包含3亿参数、24层、隐藏层大小为1024,以及16个注意力头。
与6B版本不同,3亿参数版本使用标准的LayerNorm ,而不是QK-Norm。为了降低蒸馏成本,使用CLIP-ViT-Large-336px 初始化该模型,尽管存在一些架构差异。
经过蒸馏后,将该模型与LLM整合,并按照上述类似流程,使用动态高分辨率和下一个token预测损失训练视觉编码器。然后,我们提取视觉编码器并将其发布为InternViT-300M-448px。在本报告中,我们通过在更多样化的数据混合上使用下一个token预测损失增量预训练之前的权重,进一步优化了InternViT-300M,从而得到了增强版的InternViT-300M-448px-V2.5。(听paper的意思是说:蒸馏一把得到基础版300M模型后,再和LLM一起混合训练,最终release得到VIT-300M模型)
3.3 大语言模型
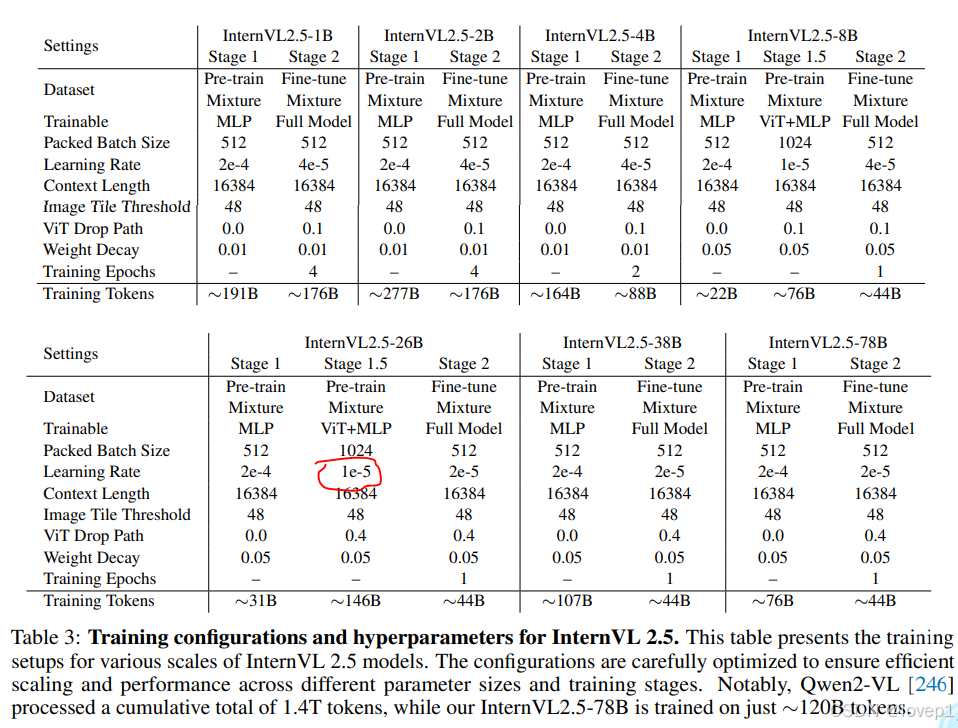
在下表2中,提供了不同版本InternVL1.5/2.0/2.5所使用的大语言模型的概览。如表所示,早期版本主要基于InternLM 2 、Qwen 2、Phi 3 、Yi 和Llama 3等语言模型构建。但在InternVL 2.5系列中,只使用了InternLM 2.5 和Qwen 2.5 (最SOTA)。

3.4 训练策略
3.4.1 多模态数据的动态高分辨率
在InternVL 2.0和2.5中,我们扩展了InternVL 1.5 中引入的动态高分辨率训练方法,增强了其处理多图像和视频数据集的能力。该过程主要包括以下步骤(真的是晦涩难懂):

上图给的是MLLMs的训练集的json格式:
- 对于单图像数据集,最大块数nmax被分配给单个图像,确保输入的最大分辨率。
- 对于多图像数据集,总块数nmax在样本中的所有图像中按比例分配(nmax1,nmax2.等)。
- 对于视频数据集,通过设置nmax = 1来简化方法,将各个帧调整为固定的448×448分辨率。
我的理解:
- 先将图片resize到最佳尺寸,什么叫最佳尺寸参考我上一篇InternVL1.5
- 然后ibest = Wnew/S, jbest=Hnew/S,将图像大小分为SxS的patch,patch的数量是ibest*jbest
- 最后再加上缩略图Ithumb
- 视频和图片list参照上文的编写
参考mmlab自己写的博客:https://zhuanlan.zhihu.com/p/12309812997

3.4.2 单模型训练流程
InternVL 2.5中单个模型的训练流程分为三个阶段,旨在增强模型的视觉感知和多模态能力。每个阶段逐步整合视觉和语言模态,平衡性能优化与训练效率。
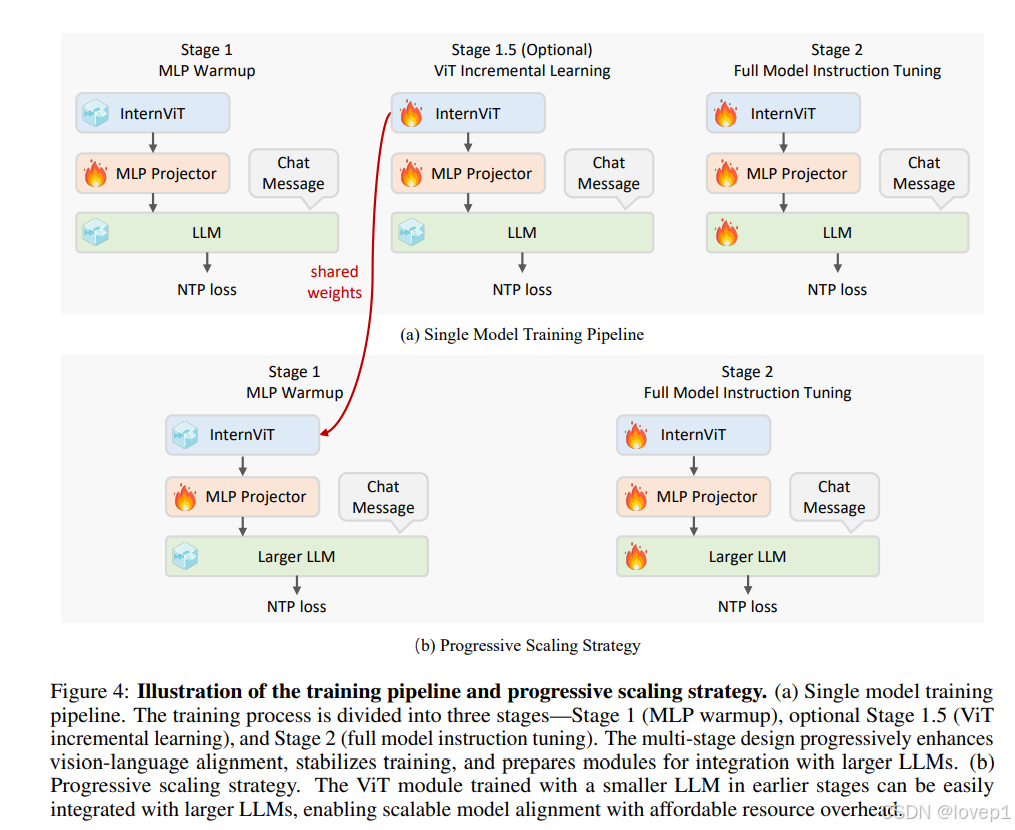
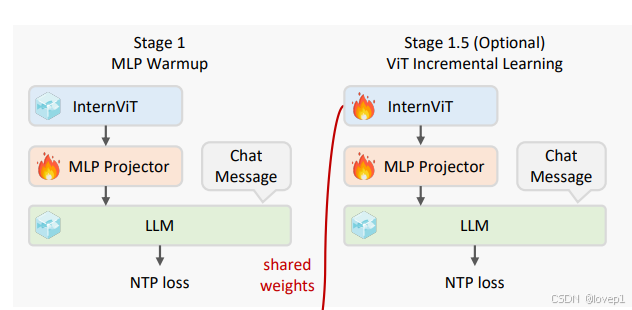
阶段1:MLP warm up
如图4(a)所示,只有MLP投影器被训练,并使用动态高分辨率训练策略,在这个阶段,我们使用表4中概述的预训练数据混合。数据以结构化的ChatML风格格式化,并通过NTPloss(Next token prediction)进行优化。此外,应用较高的学习率以加速收敛,使MLP能够快速适应LLM的输入空间
阶段1.5:ViT增量学习(可选)
如图4(a)所示,阶段1.5引入了视觉编码器的增量学习。在这个阶段,视觉编码器和MLP投影器都是可训练的,训练使用与阶段1相同的预训练数据混合和NTP损失。
该阶段的目标是增强视觉编码器提取视觉特征的能力,使其能够捕捉更全面的信息,特别是对于在网络规模数据集(例如LAION-5B )中相对罕见的领域,如多语言OCR数据和数学图表等。
如表3所示,这个阶段使用较低的学习率,以防止灾难性遗忘,确保编码器不会失去之前学到的能力。
此外,除非引入新的领域需求或数据,否则视觉编码器只需训练一次。一旦训练完成,它可以与不同大小的LLM重复使用而无需重新训练(见图4(b)和本章第三节),这使得阶段1.5成为可选的。当编码器已经针对某些特定任务进行了优化时,这一点尤其有利,允许它与各种大小的LLM集成,而无需显著增加额外成本。
阶段2:全模型指令微调
在最后阶段,如图4(a)所示,全模型微调。在这个阶段,数据质量尤为重要,因为负责生成最终面向用户输出的LLM现在是可训练的。即使少量的噪声数据(例如几千个样本)也可能导致模型行为异常,如重复输出或特定错误结果。为了减轻LLM的退化,我们在这一阶段实施严格的数据质量控制。
此外,这一阶段的训练超参数保持简单,对整个模型应用统一的学习率,而不是为不同组件设置不同的学习率。完成这一阶段后,InternVL 2.5的完整训练过程结束。进一步改进模型可以通过阶段3——使用更高质量的数据进行后训练或其他训练方法(例如偏好优化).
3.4.3 逐步扩展策略
如图4所示,我们提出了一个逐步scale策略,以高效地将视觉编码器(例如InternViT)与LLM对齐。这种策略采用分阶段训练方法,从较小、资源高效的LLM开始,逐步扩展到更大的LLM。这一方法源于我们的观察:即使使用NTP损失联合训练ViT和LLM,得到的视觉特征也是可泛化的表示,其他LLM可以轻松理解。
- 在阶段1.5中,InternViT与较小的LLM(例如20B)一起训练,训练完后,可以跳过stage1.5与其他所有LLM进行组合参与最后阶段的微调
通过采用这种逐步扩展策略,我们以远低于大规模MLLM训练通常成本的代价实现了可扩展的模型更新(其实就是预训练顶大用了)。例如,Qwen2-VL 处理了总计1.4万亿个token,而我们的InternVL2.5-78B仅在大约1200亿个token上进行训练——不到Qwen2-VL的十分之一。
3.4.4 训练增强
为了增强模型对现实场景的适应性和整体性能,引入了随机JPEG压缩和损失重加权。
随机JPEG压缩
应用JPEG压缩避免训练过程中的过拟合并增强模型的现实性能,我们应用了一种保留空间信息的数据增强技术JPEG压缩:
- 应用质量level在75到100之间的随机JPEG压缩,以模拟网络来源图像中常见的退化,这种增强提高了模型对噪声和压缩图像的鲁棒性,并通过确保在各种图像质量下的更一致性能来提升用户体验。
损失重加权。
Token平均和样本平均是两种广泛应用于加权NTP损失的策略。Token平均计算所有token的平均NTP损失,而样本平均首先在每个样本内(跨token)计算NTP损失的平均值,然后再对样本数量进行平均。

- 当使用Token平均时,每个token对最终损失的贡献是相等的,这可能导致梯度偏向于token数量更多的响应,从而导致基准性能下降。
- 样本平均确保每个样本的贡献是相等的,但它可能导致模型倾向于更短的响应,从而对用户体验产生负面影响。
- 为了减少训练过程中对较长或较短响应的偏见,我们应用了一种重加权策略,其中wi = 1/x⁰·⁵。这种方法被称为“平方平均”,它平衡了不同长度响应的贡献(直接看代码的实现就好了,其实没有消融实验不太清楚重要性)。
四、数据组织
在InternVL 2.0和2.5中,训练数据的组织通过几个关键参数进行控制训练期间数据集的平衡和分布,如图5所示(数据增强JPEG压缩、最大切片数量、重复因子)。

- 数据增强:为所有图像数据集启用这种增强,而为所有视频数据集禁用,以确保不同视频帧具有相同的图像质量。
- 最大切片数量:有效控制输入模型的图像或视频帧的分辨率,确保了在处理不同复杂度和类型的数据集时的灵活性,多图像集/高分辨率文档设为24/36,低分辨率设为6/12,视频则设为1,在INternVL1.5中,Nmax=12
- 重复因子:在r < 1时进行下采样,降低数据集在训练中的权重;或在r > 1时进行上采样,确保训练数据的平衡分布,防止任何一个数据集过拟合或欠拟合
4.1 多模态数据打包
InternVL2.0/2.5中,多模态数据打包通过将多个样本拼接成更长的序列来减少填充,从而最大化模型输入序列容量的利用率,数据打包需要考虑两个维度:
- LLM的序列长度,这对应于语言模型中使用的标准输入序列长度。这一维度在多模态任务中仍然至关重要;
- ViT的图像切片数量,这表示视觉编码器处理的图像块数量。高效管理这一维度对于优化训练效率至关重要。
为了高效处理这两个维度,数据打包策略包括以下步骤:
我的理解:
先选择独立数据,确保采样数据是符合Imax和Tmax的,然后从缓冲list中基于规则搜索另一个样本打包,如果超过tmax和Imax,则直接进入训练,如果不够则继续插入缓冲list等待打包(这里不太明白搜索的规则是什么,这样对样本多样性有没有什么影响,这些细节可能不太好理解,最好要有源码能够看一下,比InternVL1.5的动态分辨率更抽象)
原文翻译:
-
选择:在选择阶段,算法类似于没有数据打包的标准数据集,直接采样独立数据。每个采样项被截断成多个较小的项,并作为独立样本处理。这确保了每个样本的序列长度和图像块数量分别在预定义的阈值lmax(上下文长度)和tmax(图像块限制)之内。
-
搜索:对于一个给定的独立样本,算法从缓冲列表中搜索另一个样本进行打包。打包后的样本必须具有小于lmax的序列长度,并且包含少于tmax的图像块。如果多个缓冲项满足这些要求,则选择序列长度最长且图像块数量最多的缓冲项。在实际操作中,缓冲列表按降序维护,并执行二分查找以加速搜索过程。
-
打包:采样数据和选定的缓冲项被打包成一个单一序列。如果在前一步中没有选择缓冲项,则样本保持不变并直接进入下一阶段。值得注意的是,打包数据中的token只能关注其各自样本内的上下文,而不能关注其他打包样本中的token。此外,每个样本的位置索引独立维护。
-
维护:在维护阶段,如果打包后的样本超出lmax或包含超过tmax的图像块,则立即用于训练。否则,打包后的样本被插入缓冲列表。如果缓冲列表超出其容量,则序列长度最长且图像块数量最多的样本被释放,以维持缓冲效率。
4.2 数据过滤pipeline
LLM对噪声的敏感度远超过传统的视觉模型,极小比例的噪声样本也会降低MLLM的性能和用户体验(例如异常值或重复数据)
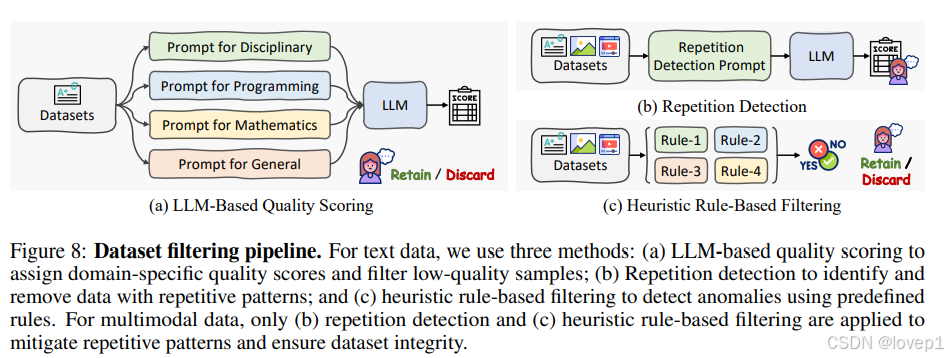
为什么要解决重复生成的问题?
- 重复生成是最有害的问题之一,仅包含几千个样本的重复模式可能会导致模型陷入重复循环,尤其是在长篇输出或链式思维(CoT)推理任务中
解决方案:
- 设计了一个高效的数据过滤流程,以去除低质量样本,从而最小化重复生成的风险
方法:
两个模块完成数据质量过滤(纯文本和多模态数据):
对于纯文本数据,三个关键策略减少重复数据:
-
基于LLM的质量评分:我们首先将数据集分类到不同的领域(例如学科、编程、数学、通用)。然后,使用预训练的LLM 和领域特定的提示,为每个样本分配一个0到10的质量评分。低于指定阈值(例如7)的样本将被移除,以确保数据质量。
-
重复检测:我们使用LLM结合专门的提示来识别重复模式。这些样本随后将接受人工审查,低于阈值(例如3)的样本将被移除,以维持数据质量。
-
基于启发式规则的过滤:我们应用特定规则,例如过滤掉长度异常的句子、过长的零序列、文本中重复行过多等,以识别数据中的异常。尽管这种方法可能会偶尔产生误报,但它提高了异常样本的检测能力。所有标记的样本在最终移除前都会经过人工审查。
对于多模态数据,通过两种策略减少重复模式:
-
重复检测:我们豁免了高质量的学术数据集,并使用特定提示在剩余数据中识别重复模式。这些样本将按照我们对文本数据应用的相同人工审查流程进行移除。
-
基于启发式规则的过滤:应用类似的启发式规则,随后进行人工验证,以确保数据集的完整性。
虽然这一严格的数据过滤流程显著减少了异常行为的发生,但是仅靠数据过滤无法完全消除这些问题。这可能是由于LLM预训练过程中引入的固有噪声,我们的多模态后训练工作只能部分缓解这一问题,而无法从根本上解决重复输出的问题。未来的工作将探索偏好优化和其他策略,以进一步抑制异常行为,并提升模型性能和用户体验。
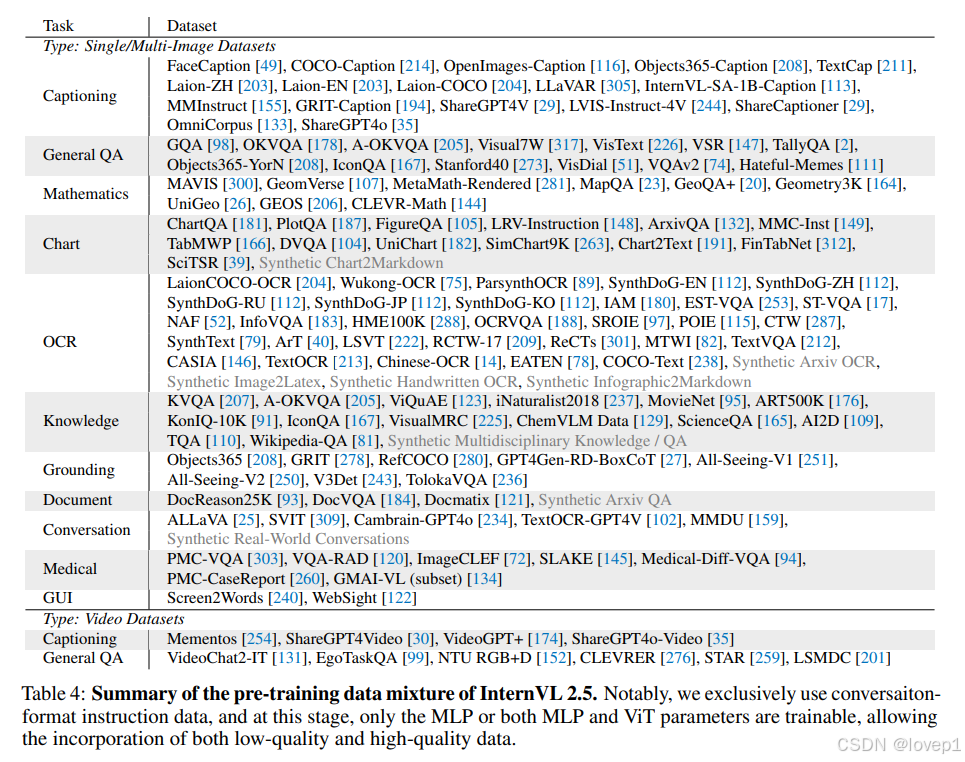
4.3 预训练数据混合
为了提升其在现实场景中处理复杂任务的能力,我们收集了比InternVL 1.5和2.0的训练语料更广泛的领域特定数据。如表4所示,我们的训练语料来自图像描述、通用问答、数学、图表、OCR、知识、定位、文档、对话、医学和GUI任务等多个领域。
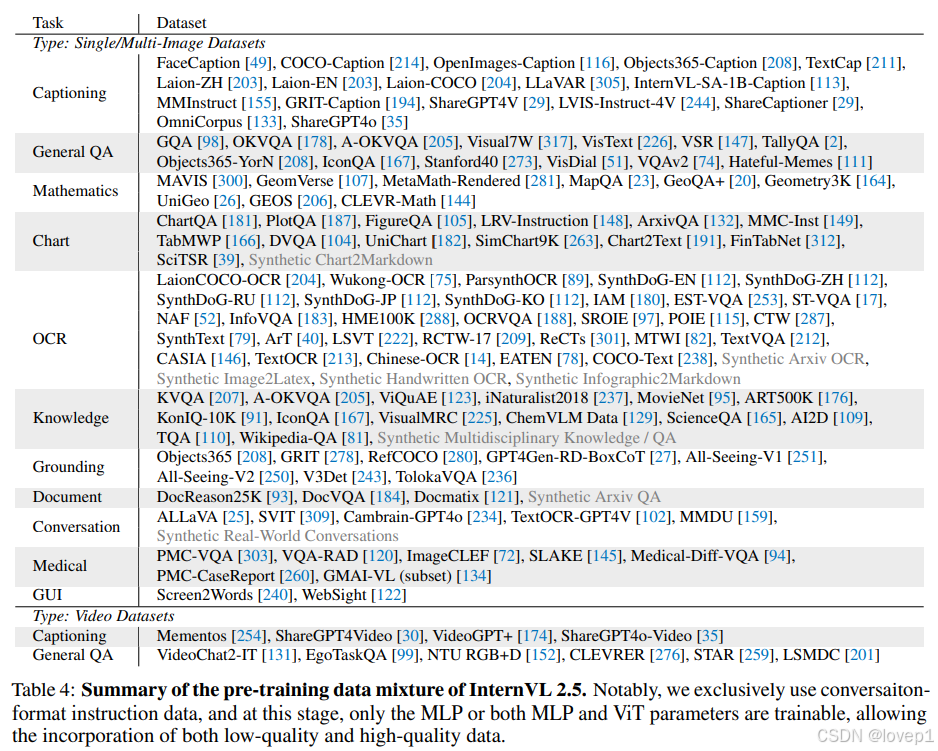
4.4 微调数据混合
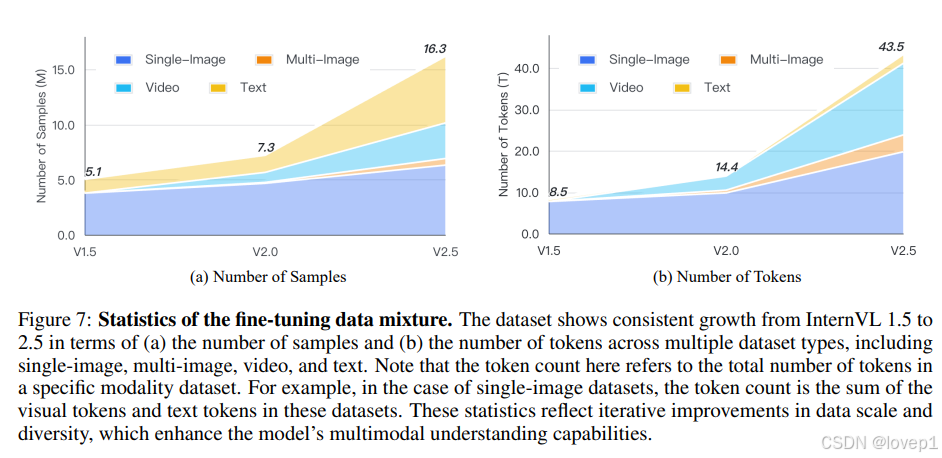
- 规模上:InternVL 1.5约510万数据,InternVL 2.0的730万,InternVL 2.5的1630万
- 多样性上:覆盖了多个领域,包括通用问答、图表、文档、OCR、科学、医学、GUI、代码、数学等,同时涵盖了单图像45.92%、多图像9.37%、视频39.79%和文本4.92%等多种模态
- 质量上:通过统一对话模板、使用语言模型对数据进行评分和精炼、去除重复模式、应用启发式规则过滤低质量样本,以及将简短回答改写为高质量且更长的互动。
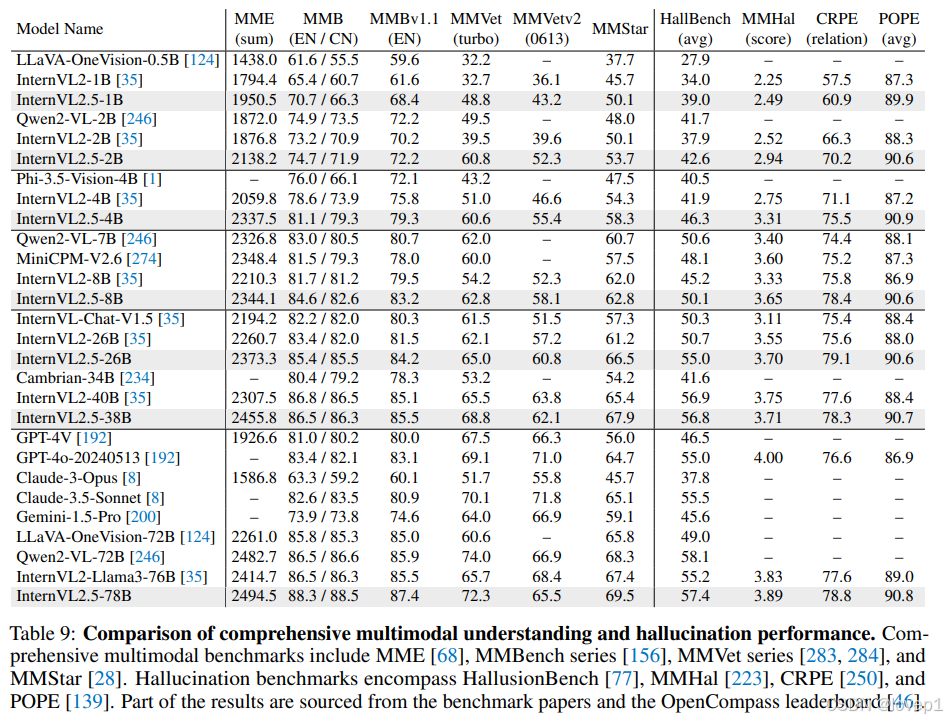
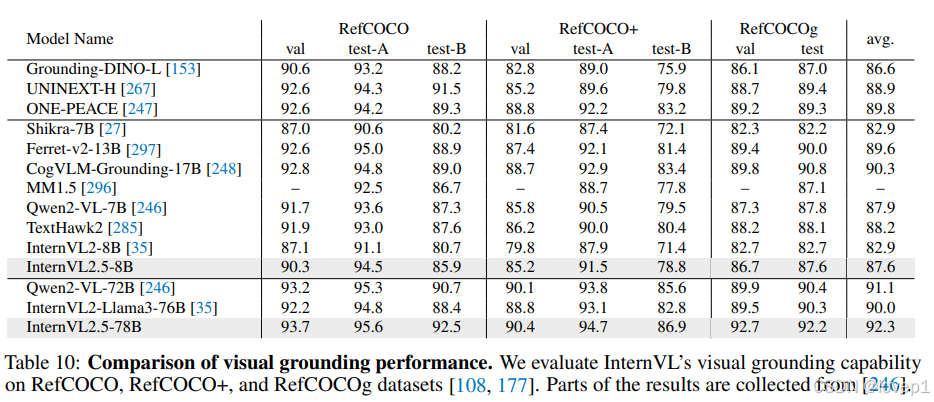
五、benchmark
COT方法对benchmark的有效性:

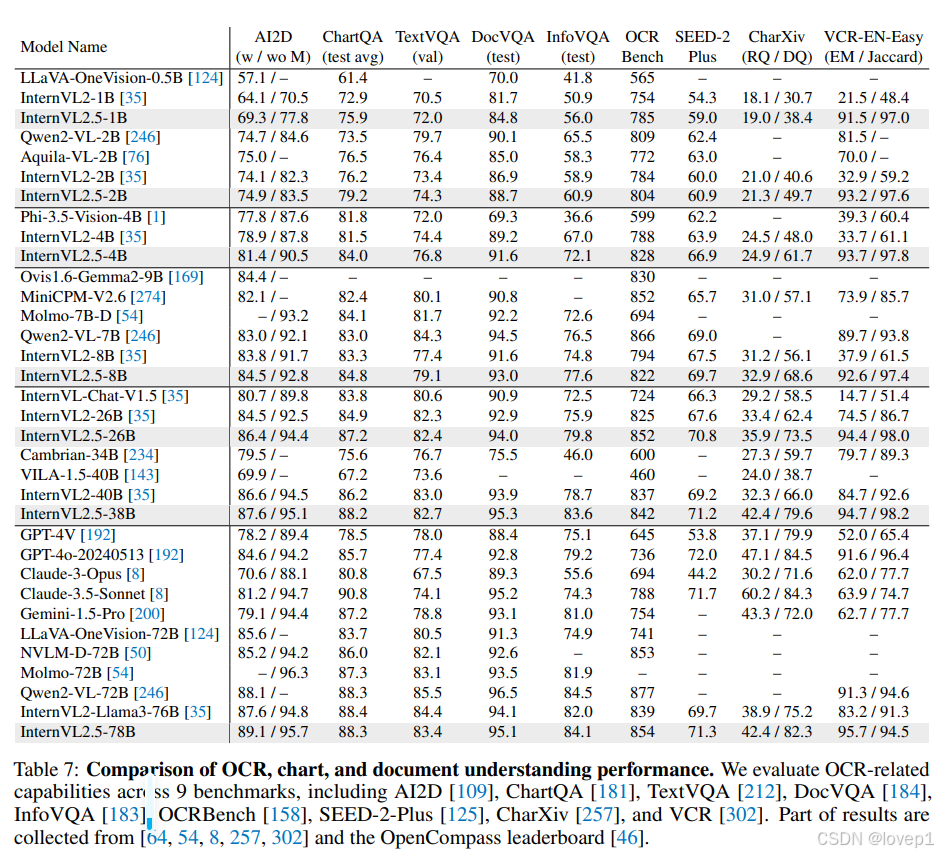
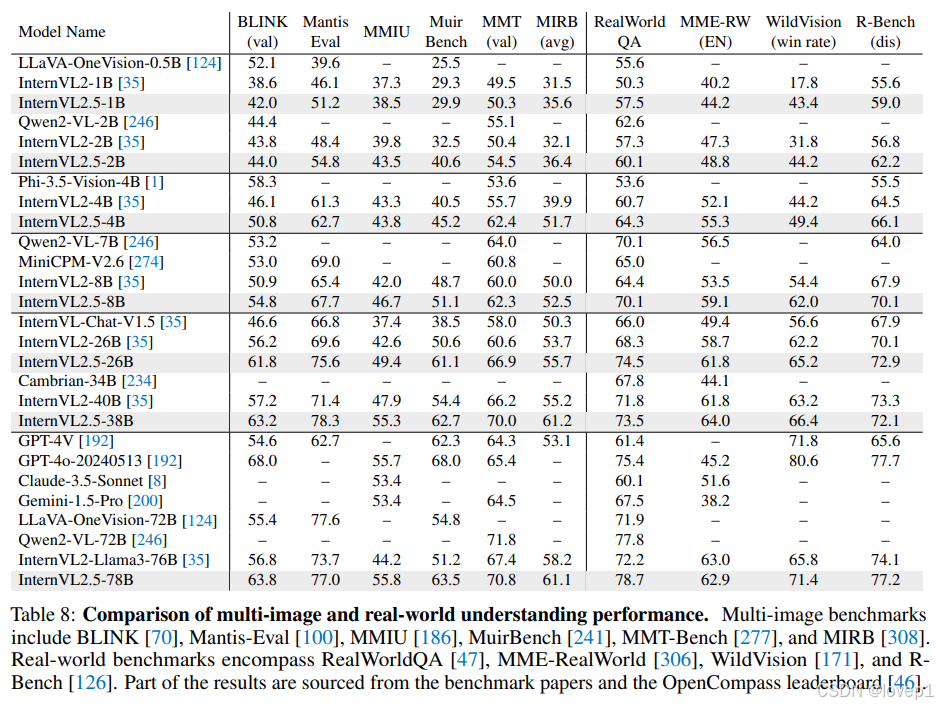

















 2158
2158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









