







 本文介绍了图形渲染中不同类型的抗锯齿技术,包括超采样抗锯齿(SSAA)、多重采样抗锯齿(MSAA)、覆盖采样抗锯齿(CSAA)、快速近似抗锯齿(FXAA)、形态学抗锯齿(MLAA)、SMAA、时间抗锯齿(TAA)和TXAA。重点讨论了它们的实现原理、优缺点及性能占用。此外,还提到了基于深度学习的DLSS和DLAA技术,以及各种抗锯齿方案的优劣对比。
本文介绍了图形渲染中不同类型的抗锯齿技术,包括超采样抗锯齿(SSAA)、多重采样抗锯齿(MSAA)、覆盖采样抗锯齿(CSAA)、快速近似抗锯齿(FXAA)、形态学抗锯齿(MLAA)、SMAA、时间抗锯齿(TAA)和TXAA。重点讨论了它们的实现原理、优缺点及性能占用。此外,还提到了基于深度学习的DLSS和DLAA技术,以及各种抗锯齿方案的优劣对比。
笔记
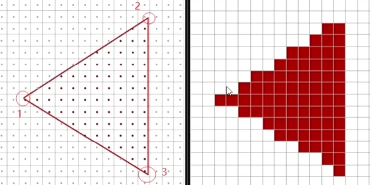
锯齿是怎么产生的
左图:想要的效果
右图:表现的效果
抗锯齿分类
● 前向渲染: SSAA、MSAA、CSAA、RGSS等
● 延迟渲染: FXAA、MLAA、SMAA等
● 时域上的抗锯齿: TAA、TXAA等
● 基于深度学习: DLSS、DLAA等
前向渲染——抗锯齿
超采样抗锯齿(SSAA)
● 全称 Super Sample Anti-aliasing
● 实现:先渲染到分辨率x4的buffer上,然后再采样至屏幕
● 相当于所有计算都乘了4,以致计算量大,带宽消耗大

● 采样点的分布,参考。有两种方法:均匀分布(OGSS,ordered Grid)和旋转分布(RGSS,Rotated Grid)
多重采样抗锯齿(MSAA)
● 全称 Multisample Anti-aliasing
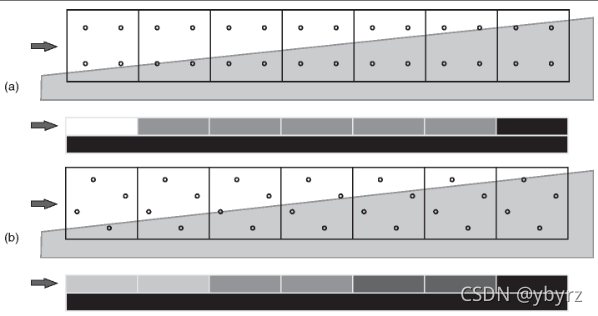
● 实现:光栅化阶段,像素去判断与三角形的关系时,用4个点来判断,得到百分比;着色器通过百分比进行着色
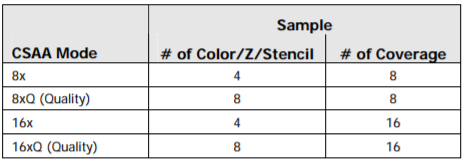
● 一般是4x的,也就是分为四个点。也有8x,16x的。
● 相比于SSAA,MSAA是得到百分比后再进行光照计算的,计算量节省了不少,但是内存占用其实跟SSAA相同
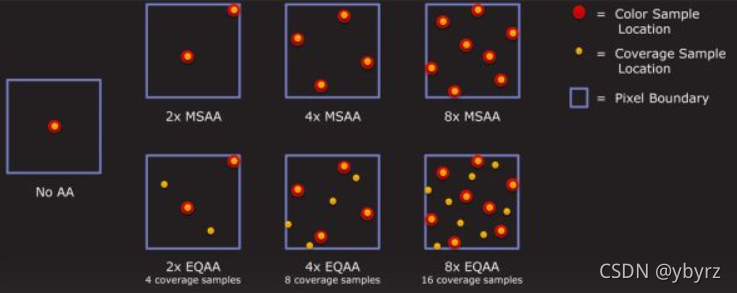
覆盖采样抗锯齿(CSAA)
● 全称Coverage Sampled Anti-aliasing
● NVIDA上叫CSAA,AMD上叫EQAA;两者原理相同
● MSAA是对每一个采样点计算颜色、深度、遮挡,先解析,然后一个像素计算一次光照;而CSAA是基于MSAA上的改进,相当于把该过程再解耦。因为检查像素是否覆盖的操作比color/z/stencil的获取消耗小,因此,对于N个采样点,会做N次像素覆盖检查,但只用N/2或 N/4个 color/z/stencil buffer,从而减少带宽和内存占用。
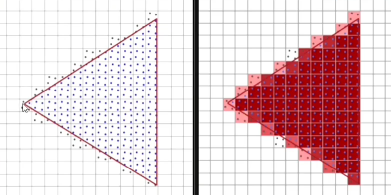
例如相对于16x MSAA,只用了1/4倍的color/z/stencil buffer的数量。
● 左图为4x MSAA, 右图为 16x CSAA。可以看出16x CSAA的效果是能比4x MSAA更准确的,而使用的带宽却更少了

延迟渲染——抗锯齿
快速近似抗锯齿(FXAA)
● 全称 Fast Approxiamte Anti-Aliasing
● 后期抗锯齿
● 通过后处理卷积描边,提取出边缘后,对边缘进行模糊
形态学抗锯齿(MLAA)
● 全称Morphological AA,参考链接
● 实现:
- 边缘检测。有两种方法,一是根据深度图检测边缘,二是根据 RGB 值的加权得到的亮度 (luminance) 来检测边缘。具体实现是在 Pixel Shader 里面,用当前点的颜色分别减去左边像素和上边像素的值,取绝对值后分别存在一张纹理的 R 和 G 通道,所以得到的 Edges texture 里面的红色点代表其左边为边缘,绿色点代表其上边为边缘,黄色点代表其左边和上边为边缘,如下图所示:

- 计算混合权重。如下图所示:

锯齿主要发生在边缘的转角处,所以比如一条横着的长边缘,中间的点的混合程度就要比两端的点混合程度要弱,并且不同的端点处的形状的混合程度也不一样。混合程度体现为混合权重,所以需要根据边缘的:a)长度 b)形状,来确定混合权重 - 根据权重对颜色进行混合。

● FXAA会导致画面模糊,SMAA几乎解决了这个问题
● 性能消耗仅约为FXAA的2倍左右
SMAA
● 全称Enhanced Subpixel Morphological AA,参考链接1 参考链接2
● 是对MLAA的改进
- 边缘检测的改进。在提取边缘时会严格区分边缘的形状,低质量的边缘提取和高质量的边缘提取结果会有很大的差别。所以 SMAA 在低质量(SMAA 1x)的设定下效果反而不如同等级的 FXAA。
- 提取更多几何信息,保留不该模糊的边缘
- 引入了对角线的边缘检测
- 更改了由面积计算权重的公式
● 除了这四点改进之外,SMAA 还与 MSAA 及 TAA 进行了结合,实现了更为细腻的抗锯齿效果
时域上的抗锯齿
时间抗锯齿(TAA)
● 全称TemporalAA
● 将采样点从单帧分布,转移到多帧上,使得每一帧不需要多次采样增加计算量
● 采样点在像素内是随机偏移的;然后累加权重得到百分比。

● 用motion vector保存每帧移动的偏移,就不用重新计算已算过的部分。但往往会盲目地跟随动物体,从而造成屏幕上的细节模糊不清

TXAA
● 是TAA、MSAA的组合
● 8X MSAA的画质用TXAA 2X仅需花费2X MSAA的性能消耗
● 诸多游戏(巫师3、GTA5、刺客信条3、4、看门狗1、2)都有用TXAA
基于深度学习
DLSS
● DLSS:在图像质量损失最小的情况下提高性能;参考链接
● 本质是渲染更少的像素,用AI重建更高的分辨率。例如:DLSS 强制游戏以较低的分辨率(通常为 1440p)进行渲染,然后使用其经过训练的 AI 算法来渲染更高的分辨率(通常为 4K)。
● 背后使用的技术是 Recurrent CNN,递归神经网络与卷积神经网络的一种结合。因此他能结合时域上的信息保证时域稳定性——像素具有帧间连贯性,不会出现过多闪烁、跳变现象。其次,结合神经网络的强大图形重建能力,DLSS 能够分别对几何边缘以及着色进行重建。
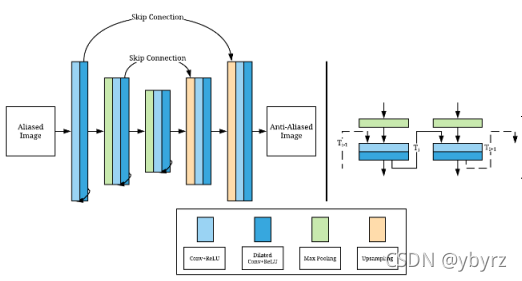
● DLSS 效果优于现有的主流 AA 算法,它能同时在几何、着色、时域上进行反走样;不足之处是神经网络带来的性能开销比较大(需要预学习),仅仅反走样就占用了画面 20% 的渲染时长,相比之下 Temporal AA 开销低了一个量级。
DLAA
● 与DLSS刚好相反,性能受到轻微影响的情况下显著**提高图像质量*
● 与TAA和DLSS相比,能产生更好的图像质量,尤其是在较低的分辨率下。
抗锯齿速度排序
FXAA > TAA > TXAA > MSAA > SSAA
抗锯齿内存占用排序
SSAA > MSAA > CSAA > FXAA > TXAA > TAA
作业
对比各个抗锯齿方案的优劣(效果、效率)
● 效果:
低配下 TAA>FXAA>SMAA
高配开DLSS>MSAA>TAA
TODO!!!
有能力的进行各个方案真机测试(尽量让手机达到瓶颈状态下测试)
TODO!!!
建议使用抓帧软件,比如骁龙的用SnapdragonProfiler,可以告诉每个阶段的性能消耗。
苹果,Xcode抓帧:模拟环境,不准确
挖个坑
TODO!!!
软管线上试着实现几个AA。。。
参考资料
https://www.bilibili.com/video/BV1VR4y1J7KT?p=2
https://zhuanlan.zhihu.com/p/363624370
https://developer.download.nvidia.cn/SDK/10/direct3d/Source/CSAATutorial/doc/CSAATutorial.pdf
https://www.tomshardware.com/reviews/anti-aliasing-nvidia-geforce-amd-radeon,2868-4.html
https://zhuanlan.zhihu.com/p/57503957

















 1087
1087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









