







此篇是我在学习中做的归纳与总结,其中如果存在版权或知识错误或问题请直接联系我,欢迎留言。
PS:本着知识共享的原则,此篇博客可以转载,但请标明出处!
目录
0. 8B/10B编码
0.0 8B/10B编码原理
8B/10B编码是由IBM公司在1983年所提出的一种编码方式。该编码根据对应的映射码表和极性取值规则把8bit码字编码成10bit来传输。使编码后的二进制序列中,0、1的个数基本均衡。创造这种编码的目的在于解决在高速串行数据传输时,若出现有多个连0或连1,接收端就会出现时钟漂移或同步丢失的问题。而且8B/10B编码可以根据其特定的编码规则,在接收端检测出传输过程中出错的信息。
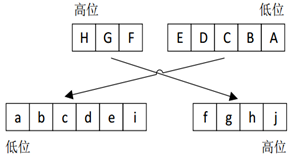
图1 编码规则
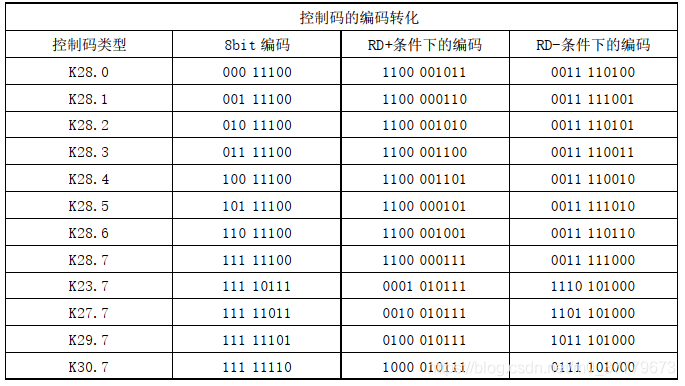
在编码过程中,8bit原始码字被分成两部分:低位5bit记为EDCBA(设其十进制数值为X)和高位的3bit记为HGF(设其十进制数值为Y),则该8bit数据码记为D.x.y,与数据码的记法类似,控制码记为K.x.y。
如图1所示:在8B/10B编码时,低5位的EDCBA经过5B/6B编码成为6位的abcdei,高3位的HGF经3B/4B成为4位fghj,最后再将两部分组合起来形成一个10bit码abcdeifghj。10bit码在发送时,按照先低位再高位的顺序发送。
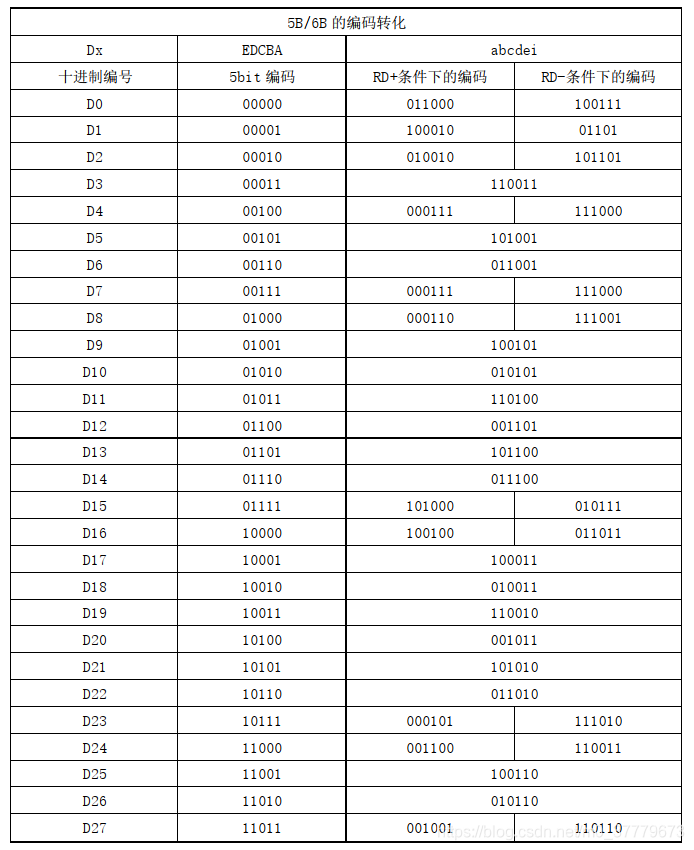
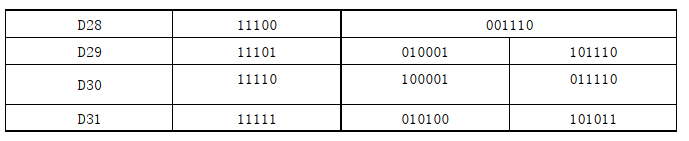
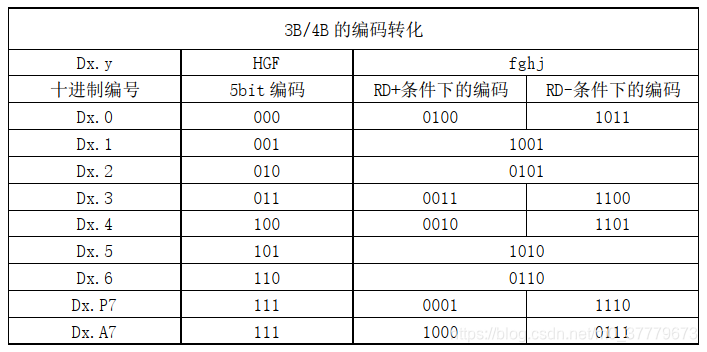
在8B/10B编码中使用 “不一致性(Disparity)”来描述编码中"1"的位数和"0"的位数的差值。如图2中所示,在所有的6B或4B编码中,要么0比1多两个、要么0、1个数相等,要么1比0多两个。对应的“不一致性(Disparity)”就只有D=+2、D=-2、D=0这三种状况。由于比特流不停地从发送端向接收端传输,前面所有已发送数据的不一致性累积产生的状态被称为“运行不一致性(Runing Disparity,RD)”。而RD仅会出现+1与-1两种状态,分别代表位"1"比位"0"多或位"0"比位"1"多,其初始值是-1。
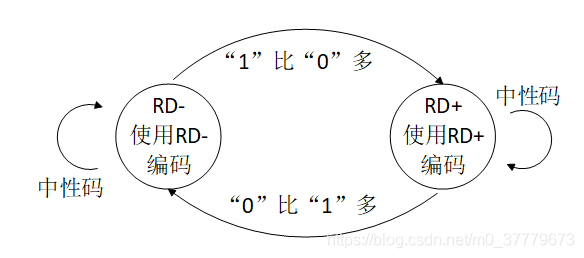
图2 RD值转换规则
当目前已编码序列整体为RD=-1时,表示之前传输的数据中"0"的个数多于"1"的个数,若下一个要选取的6B或4B编码的不一致性(Disparity)为0,则编码后序列整体的运行不一致性依然为RD=-1;若下一个要选取的6B或4B编码的为Disparity=+2,则编码后序列整体的运行不一致性就变为RD=+1。反之亦然,当目前已编码序列整体的RD为RD+时,下一位就选择RD-的编码,序列整体的RD就变为RD+,以此来平衡整个序列的运行不一致性(即0、1的平衡)。
通过8B/10B编码以后,整个编码序列最多只会出现连续的5个“1”或“0”,绝对不会超过5bit。显然,理论上8B/10B编码可以起到均匀比特序列中的0和1分布的作用。
0.1 8B/10B编码的FPGA实现
为了验证8B/10B编码的可靠性与合理性,对编码电路在Vivado2017.4中使用VerilogHDL语言进行编程仿真,并且在A7系列FPGA(型号:XC7A35TFTG256)开发板上测试,通过开发板的IO口串行输出编码后的数据。
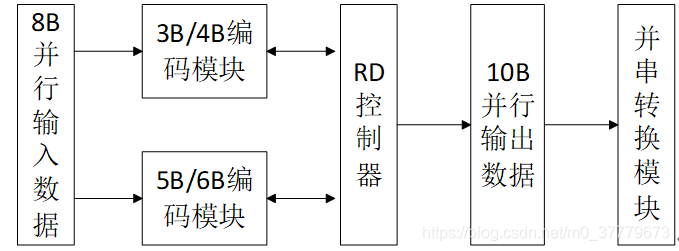
图3 FPGA编码输出系统逻辑框图
图3所示为本文中FPGA实现8B/10B编码并串行输出数据的系统逻辑框图,在此系统中8bit并行数据先进行编码,并行输出10bit编码后数据,通过并串转换模块最终在IO口输出。
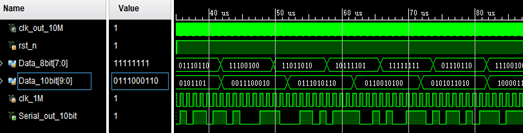
图4 FPGA系统时序仿真图
FPGA设计后,仿真结果如图4所示。其中Data_8bit是8bit原始数据,Data_10bit是经过8B/10B编码器编码后的10bit数据,Serial_out_10bit是并串转换模块输出的串行数据。从仿真结果可以看出,整个编码输出过程准确无误。
0.2 编码功能模块实现代码
`timescale 1ns / 1ps
//
// Company:
// Engineer:
//
// Create Date: 2019/04/19 12:00:00
// Design Name:
// Module Name: encode_8b10b
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//
module encode_8b10b(
input [9:0] dtin,
input clk,
input rst_n,
output[9:0] dtout
);
wire reset=~rst_n;
wire [9:0] dtout;
reg Out_Flag;
//局部变量
reg rd_flg, rd_buf; //RD极性标志,0表示为RD-,1表示为RD+
reg[10:0] k_temp; //特殊字符编码中间变量
reg[9:0] d_code; //数据字符编码中间变量
reg[6:0] d6b_temp; //5B到6B码表的中间变量
wire rd_temp, rd_st; //RD极性标志,0为RD -,1为RD+
initial rd_flg= 0; //RD极性初值为RD-
assign rd_st=(dtin[9] & dtin[8] & dtin[7]) ? 1 :((dtin[9] & dtin[8] & ~dtin[7]) ? 0:rd_flg);//RD极性控制
assign rd_temp= (dtin[8] & ~dtin[9]) ? ~rd_st:rd_st; //插入的错误RD极性
assign dtout[9:0]= {d_code[0],d_code[1],d_code[2],d_code[3],d_code[4],
d_code[5],d_code[6],d_code[7],d_code[8],d_code[9]}; //调整编码输出值的顺序
always @(dtin or rd_temp)
begin
if(dtin[9:8]==2'b10) //特殊字符编码表
case(dtin[4:0])
5'h0:k_temp=11'b00011110100;
5'h1:k_temp=11'b10011111001;
5'h2:k_temp=11'b10011110101;
5'h3:k_temp=11'b10011110011;
5'h4:k_temp=11'b00011110010;
5'h5:k_temp=11'b10011111010;
5'h6:k_temp=11'b10011110110;
5'h7:k_temp=11'b00011111000;
5'h8:k_temp=11'b01110101000;
5'h9:k_temp=11'b01101101000;
5'ha:k_temp=11'b01011101000;
5'hb:k_temp=11'b00111101000;
default:k_temp=11'b00111110100; //错误状态
endcase
else //5B到6B的转换码表
case(dtin[4:0])
5'h00: d6b_temp= 7'b1100111;
5'h01: d6b_temp= 7'b1011101;
5'h02: d6b_temp= 7'b1101101;
5'h03: d6b_temp= 7'b0110001;
5'h04: d6b_temp= 7'b1110101;
5'h05: d6b_temp= 7'b0101001;
5'h06: d6b_temp= 7'b0011001;
5'h07: if(rd_temp)
d6b_temp= 7'b0000111;
else
d6b_temp= 7'b0111000;
5'h08: d6b_temp= 7'b1111001;
5'h09: d6b_temp= 7'b0100101;
5'h0a: d6b_temp= 7'b0010101;
5'h0b: d6b_temp= 7'b0110100;
5'h0c: d6b_temp= 7'b0001101;
5'h0d: d6b_temp= 7'b0101100;
5'h0e: d6b_temp= 7'b0011100;
5'h0f: d6b_temp= 7'b1010111;
5'h10: d6b_temp= 7'b1011011;
5'h11: d6b_temp= 7'b0100011;
5'h12: d6b_temp= 7'b0010011;
5'h13: d6b_temp= 7'b0110010;
5'h14: d6b_temp= 7'b0001011;
5'h15: d6b_temp= 7'b0101010;
5'h16: d6b_temp= 7'b0011010;
5'h17: d6b_temp= 7'b1111010;
5'h18: d6b_temp= 7'b1110011;
5'h19: d6b_temp= 7'b0100110;
5'h1a: d6b_temp= 7'b0010110;
5'h1b: d6b_temp= 7'b1110110;
5'h1c: d6b_temp= 7'b0001110;
5'h1d: d6b_temp= 7'b1101110;
5'h1e: d6b_temp= 7'b1011110;
5'h1f: d6b_temp= 7'b1101011;
endcase
end
//组合10bit的逻辑电路实现
always@(posedge clk or posedge reset)
if(reset)
rd_flg <= 0;
else
if(dtin[9] & ~dtin[8])
begin //特殊字符的取值及RD极性的确定
if(rd_temp)
d_code <= ~ k_temp[9:0];
else
d_code <= k_temp[9:0];
rd_flg <= rd_st ^ k_temp[10];
end
else
begin
case(dtin[7:5]) //数据字符的10 -bit组合
3'b000:d_code<=code_differ(d6b_temp,4'b0100);
3'b001:d_code<=code0_same(d6b_temp,4'b1001);
3'b010:d_code<=code0_same(d6b_temp,4'b0101);
3'b011:d_code<=code1_same(d6b_temp);
3'b100:d_code<=code_differ(d6b_temp,4'b0010);
3'b101:d_code<=code0_same(d6b_temp,4'b1010);
3'b110:d_code<=code0_same(d6b_temp,4'b0110);
3'b111:d_code<=code7_differ(d6b_temp);
endcase
rd_flg <= rd_st ^ rd_buf; //确定RD极性
end
//3b到4-bit编码分为四种情况,采用下列的四个函数实现,
//3-bit值为1、2、5和6情况,编码后" 1"和" 0"个数相同。 RD+和RD-取值相同
function[9:0] code0_same;
input[6:0] in1; //码表中6-bit编码的对应值
input[3:0] in2; //4-bit编码的对应值
case({rd_temp,in1[6]})
2'b00:
begin //rd -, in1[6]= 0
code0_same= {in1[5:0],in2};
rd_buf=0;
end
2'b01:
begin //rd -, in1[6]= 1
code0_same= {in1[5:0],in2};
rd_buf=1;
end
2'b10:
begin //RD+, in1[ 6]= 0
code0_same= {in1[5:0],in2};
rd_buf=0;
end
2'b11:
begin //RD+, in1[ 6]= 1
code0_same= {~in1[5:0],in2};
rd_buf=1;
end
endcase
endfunction
//3b值为3时,编码后" 1"和" 0"个数相同,但RD+是RD-取值不同。
function[9:0] code1_same;
input[6:0] in1; //码表中6B码元取值
case({rd_temp,in1[6]})
2'b00:
begin //rd -, in1[ 6]= 0
code1_same={in1[5:0],4'b1100};
rd_buf=0;
end
2'b01:
begin //rd -, in1[ 6]= 1
code1_same={in1[5:0],4'b0011};
rd_buf=1;
end
2'b10:
begin //RD+, in1[ 6]= 0
code1_same={in1[5:0],4'b0011};
rd_buf=0;
end
2'b11:
begin
code1_same={~in1[5:0],4'b1100};
rd_buf=1;
end
endcase
endfunction
//3b值为0和4,编码后" 1"和" 0"个数不相同,而RD+和RD -取值互为反码情况。
function[9:0] code_differ;
input[6:0] in1; //6B编码取值
input[3:0] in2; //4B编码取值
case({rd_temp,in1[6]})
2'b00:
begin //rd -,d6b_temp[ 6]= 0
code_differ={in1[5:0],~in2};
rd_buf=1;
end
2'b01:
begin //rd -,d6b_temp[ 6]= 1
code_differ={in1[5:0],in2};
rd_buf=0;
end
2'b10:
begin //RD+,d6b_temp[ 6]= 0
code_differ={in1[5:0],in2};
rd_buf=1;
end
2'b11:
begin //RD+,d6b_temp[ 6]= 1
code_differ={~in1[5:0],~in2};
rd_buf=0;
end
endcase
endfunction
//3b值为7时,编码后" 1"和" 0"个数不相同,有4种选择,见表1。
function[9:0] code7_differ;
input[6:0] in1; //6B码元取值
case({rd_temp,in1[6]})
2'b00:
begin //rd -,d6b_temp[ 6]= 0
if(in1[0] & in1[1])
code7_differ={in1[5:0],4'b0111};
else
code7_differ={in1[5:0],4'b1110};
rd_buf=1;
end
2'b01:
begin
code7_differ={in1[5:0],4'b0001};
rd_buf=0;
end
2'b10:
begin //RD+,d6b_temp[ 6]= 0
if(~(in1[0] | in1[1]))
code7_differ={in1[5:0],4'b1000};
else
code7_differ ={in1[5:0],4'b0001};
rd_buf=1;
end
2'b11:
begin
code7_differ={~in1[5:0],4'b1110};
rd_buf=0;
end
endcase
endfunction
endmodule
1. 8B/10B解码
1.0 8B/10B解码原理
8B/10B编码解码最简单的实现方案就是直接查表法,该方案虽然简单,但是需要256个数据以及12个特殊字符共268个单元。因为每个编码都有RD+和 RD-两种情况,所以每个单元用20位,其中 10位是 RD-,另10位是 RD +。
如果采用逻辑电路直接实现 8B/10B 编码,则逻辑资源开销太大,而且编码效率较低。所以,传统的编码方案采用将 8bit 数据分为低 5位和高 3 位分开查表,以降低直接查表的编码效率和资源开销。但是在满足编码规则的情况下, 研究人员发明了很多编码方式也能实现8B/10B 编解码,而且有更高的编码效率和更少的资源开销,实现方案主要有逻辑电路和更高效的查表法两大类。
编码模块一个输入码字可能对应两个输出码字,而且还要在编码过程中控制整个序列的不一致性,较为复杂。相对于编码模块来说,解码就较为简单,一个输入码字只对应一个输出码字。为了检验在传输过程中是否出错,在解码模块需要加入检错功能,出错的情况主要有两种,一是收到的 10bit 码为无效码,二是检查出的收到的 10bit 码不一致性超出为+2、 -2 或 0。本次设计的解
码模块直接采用了一种逻辑组合电路,这种这设计更能节省逻辑资源,而且电路的可靠性更高。
输入端口有 rst_n 和 10bit 的 datain,输出端口为 10bit 的 dataout,code_err和 kout。其中 rst_n 是复位信号; 10bit 的 datain 是接收到的 10bit 编码;code_err是编码检测信号,若检测到编码不一致性出错,输出高位; kout 是控制码检测信号,若检测到收到的 10bit 编码是控制码,则输出高位。具体的设计思路是首先将收到的 10bit 编码分为 6bit 高位和 4bit 低位。通过观察编码映射表,可以得出如下规律:
5bit 码共有32个,其中13个对应的 6bit 码是不平衡码,19个对应的 6bit码是完美平衡码。而这 19 个完美平衡码中 18 个编码的的 RD- 和 RD+ 是同一个编码,只有 1 个编码的的 RD-和 RD+不一样(即编码 7)。而这 18 个编码的 6bit 码的 abcde 和 5bit 码的 ABCDE 一一对应,可以直接根据 A=a、B=b、C=c、D=d、E=e 的关系解码输出。而编码 7 的 RD-码与其 5bit 码有同样的对应关系。
E=e2&i2&!d+(rd3+111000)&e+000111&!e;
D=e2i2(b2 xor c2)+e2&!i2&d2+(e2 nor d2)i2+(rd3+111000)d+000111&!d;
C=e2&i2&a2_s_c2+e2&!i2&c2+(e2 nor c2)i2+(rd3+111000)c+000111&!c;
B=e2&i2&a2_s_c2+e2&!i2&b2+(e2 nor b2)i2+(rd3+111000)b+000111&!b;
A=e2&i2&a2_s_c2+e2&!i2&a2+(e2 nor a2)i2+(rd3+111000)a+000111&!a;
令: a2=rd4&a+rd2&!a; b2=rd4&b+rd2&!b; c2=rd4&c+rd2&!c;
d2=rd4&d+rd2&!d; e2=rd4&e+rd2&!e; i2=rd4&i+rd2&!i;
a2_s_c2=a2&c2+!a2&!c2;
3B/4B 解码可根据下表所示 fghj 到 HGF 的对应关系, 经推导得:
F=f&!j+!g&!h&j+!f&h&j;
G=!f&j+g&h&!f+f&!h&!j;
H=h&!j+f&g&!h&j+!f&g&h+f&(g nor j)+(f nor g)&!h&j对剩余的13个不平衡码按 ei 的值分为 00、01、10、11 四组。若 ei=10 则E=1, D=d, C=c, B=b, A=a;若 ei=01 则 E=0, D=!d, C=!c, B=!b, A=!a;若 ei=11则 E=!d, D=b xor c, C=ac+!a&!c, B= ac+!a&!c, A= ac+!a&!c;而当 ei=00 时,没有许用码组,视为传输出错。
对于控制码,也符合上述规律。
1.1 解码功能模块实现代码
`timescale 1ns / 1ps
//
// Company:
// Engineer:
//
// Create Date: 2019/05/06 14:44:43
// Design Name:
// Module Name: decode_8b10b
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//
module decode_8b10b(
input [9:0] in,
input clk,
input rst,
output reg ko,
output [7:0] out
);
reg ai,bi,ci,di,ei,ii;
reg fi,gi,hi,ji;
//wire ko;
reg ho,go,fo;
reg eo,do,co,bo,ao;
wire aneb,cned;
wire p13,p31,p22;
wire ika,ikb,ikc;
wire eei;
wire or121,or122,or123,or124,or125,or126,or127;
wire xa,xb,xc,xd,xe;
wire ior134;
wire or131,or132,or133,or134;
wire xf,xg,xh;
wire [7:0] out;
always @ (posedge clk or negedge rst) begin
if (!rst) begin
ai<=1'b0;
bi<=1'b0;
ci<=1'b0;
di<=1'b0;
ei<=1'b0;
ii<=1'b0;
fi<=1'b0;
gi<=1'b0;
hi<=1'b0;
ji<=1'b0;
end else begin
ai<=in[0];
bi<=in[1];
ci<=in[2];
di<=in[3];
ei<=in[4];
ii<=in[5];
fi<=in[6];
gi<=in[7];
hi<=in[8];
ji<=in[9];
end
end
assign aneb = ai ^ bi ;
assign cned = ci ^ di ;
assign p13 = (aneb & (~ ci & ~ di)) | (cned & (~ ai & ~ bi)) ;
assign p31 = (aneb & ci & di) | (cned & ai & bi) ;
assign p22 = (ai & bi & (~ ci & ~ di)) | (ci & di & (~ ai & ~ bi)) | (aneb & cned) ;
assign ika = (ci & di & ei & ii) | (~ ci & ~ di & ~ ei & ~ ii) ;
assign ikb = p13 & (~ ei & ii & gi & hi & ji) ;
assign ikc = p31 & (ei & ~ ii & ~ gi & ~ hi & ~ ji) ;
always @ (posedge clk or negedge rst) begin
if (!rst) begin
ko <= 0;
end else begin
ko <= ika | ikb | ikc;
end
end
assign eei = ei ^~ ii ;
assign or121 = (p22 & (~ ai & ~ ci & eei)) | (p13 & ~ ei) ;
assign or122 = (ai & bi & ei & ii) | (~ ci & ~ di & ~ ei & ~ ii) | (p31 & ii) ;
assign or123 = (p31 & ii) | (p22 & bi & ci & eei) | (p13 & di & ei & ii) ;
assign or124 = (p22 & ai & ci & eei) | (p13 & ~ ei) ;
assign or125 = (p13 & ~ ei) | (~ ci & ~ di & ~ ei & ~ ii) | (~ ai & ~ bi & ~ ei & ~ ii) ;
assign or126 = (p22 & ~ ai & ~ ci & eei) | (p13 & ~ ii) ;
assign or127 = (p13 & di & ei & ii) | (p22 & ~ bi & ~ ci & eei) ;
assign xa = or127 | or121 | or122 ;
assign xb = or122 | or123 | or124 ;
assign xc = or121 | or123 | or125 ;
assign xd = or122 | or124 | or127 ;
assign xe = or125 | or126 | or127 ;
always @ (posedge clk or negedge rst) begin
if (!rst) begin
ao<=1'b0;
bo<=1'b0;
co<=1'b0;
do<=1'b0;
eo<=1'b0;
end else begin
ao<=xa ^ ai;
bo<=xb ^ bi;
co<=xc ^ ci;
do<=xd ^ di;
eo<=xe ^ ei;
end
end
assign ior134 = (~ (hi & ji)) & (~ (~ hi & ~ ji)) & (~ ci & ~ di & ~ ei & ~ ii) ;
assign or131 = (gi & hi & ji) | (fi & hi & ji) | (ior134);
assign or132 = (fi & gi & ji) | (~ fi & ~ gi & ~ hi) | (~ fi & ~ gi & hi & ji);
assign or133 = (~ fi & ~ hi & ~ ji) | (ior134) | (~ gi & ~ hi & ~ ji) ;
assign or134 = (~ gi & ~ hi & ~ ji) | (fi & hi & ji) | (ior134) ;
assign xf = or131 | or132 ;
assign xg = or132 | or133 ;
assign xh = or132 | or134 ;
always @ (posedge clk or negedge rst) begin
if (!rst) begin
fo<=1'b0;
go<=1'b0;
ho<=1'b0;
end else begin
fo<=xf ^ fi;
go<=xg ^ gi;
ho<=xh ^ hi;
end
end
assign out = {ho,go,fo,eo,do,co,bo,ao};
endmodule



















 1062
1062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











