







差速机器人走行模型讲解
两轮差速机器人是轮式机器人中比较常见的,这种结构的机器人只能实现一种走行方式:机器人中心绕轴线上任意一点的旋转。有人会拿直线运动来质疑,先别慌,直线也是一种旋转运动,只不过旋转半径很大
轴线,两个轮子所在圆心所在的直线
机器人中心,两个轮子圆心连线的中心点
旋转运动模型,如下图,机器人中心绕o绕轴线右侧一点O以半径R做旋转运动,此时左右轮速比为
V1/V2 = r1/r2 (1)
r1 = R + L/2, r2 = R - L/2 (2)
由(1)(2)得,
V1/V2 = (R + L/2)/(R - L/2) (3)
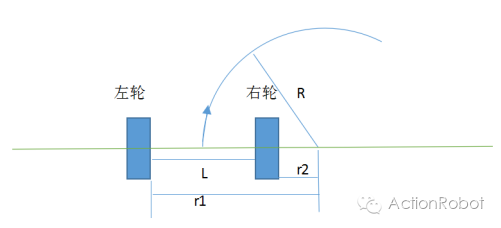
式(3)中,L为轮间距,为常量,当旋转半径R趋向于无穷大时,式(3)比值趋向于1,也就是直线运动
可以规定圆心O在机器人中心o右侧时,R为正,反之为负,这样式(3)对于其他情况仍然适用。
关于轮子的方向,规定轮子逆时针旋转时速度为正,结合(3)可以通过程序实现任意的运动(可实现的)
举个栗子,让机器人顺时针旋转,旋转中心在靠近右轮1/4L处。
根据(3)V1/V2 = 3:1,左轮逆时针故为正,右轮子也是逆时针也为正,所以只要保持速度都为正,比例为3:1,即可按照给定弧线运动。
问题来了,比例和正负确定了,大小给定呢?我们来说说角速度和线速度的关系
V = ω*r (4)
线速度V是角速度ω的r(半径)倍。对于上述栗子中,想让机器人一秒钟转一周也就是2π,那么线速度V1 = 2π*r1, V2 = 2π*r2,就这!

















 7453
7453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









