






视觉slam的作业越来越难了...通过这次作业,熟悉了
1. 从3d坐标到重投影误差的建立过程
2. 高斯牛顿法建模的过程
3. 用se3/SE3进行优化和迭代更新的过程
今天来记录一下用高斯牛顿法用于估计相机位姿这道题.
来捋一下高斯牛顿的流程,首先,我们需要明确优化量
在这里,就是对于相机位姿进行优化.
注意,相机位姿采用SE3的形式表达==>为了便于更新迭代
而我们这里的误差项的表达就是对应的重投影误差,就是每个点的三维坐标投影到相机平面(预测值)与在相机平面的观测位置的差.
注意,为了将三维观测投影到相机平面,
1. 将三维坐标进行变换转移到相机坐标系
这里注意,我一开始的思路是从SE3得到对应的homogeneous Transform(一个4*4的矩阵),再和三维点的Homogeneous坐标相乘...但是,这样反复转换向量维度实在麻烦,而实际上,se3提供了更简单的方法,查了sophus::se3的头文件,实现了乘法的重载,
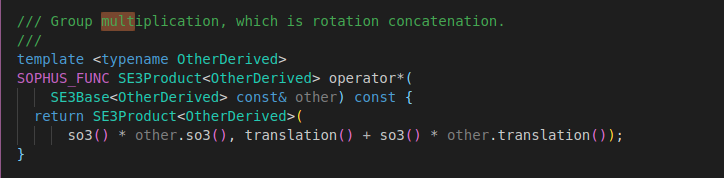
这样,一行代码就可以解决繁琐的转换/得到了目标函数后,我们接下来需要计算对应的雅克比,这里因为target function包含两个参数(u,v),而需要优化的变量se3则包括6个参数,所以,对应的雅克比矩阵维度就是2*6
雅克比的具体形式在slam十四讲 187页有明确形式,这里要注意的是,雅克比的正负性和我们定义的error function有关系===>到底是观测量 - 预测量还是反过来
得到雅克比后,通过normal function,我们就可以得到迭代量dx

注意,这里李代数的更新,我刚开始是直接和小量进行相加,但是,这样的结果首先是错的==>迭代后误差反而增加了,而一般的处理方法是exp(dt)*T,根据se3文档的解释,exp将se3转化到对应的SE3,(从而一个旋转矩阵),然后实现迭代
而这个问题的本质原因是 exp(a)*exp(b)不等于exp(a+b) [a,b都是向量,exp是它们的指数映射]
摘取一段sophus上对于exp的注释

这样,不断迭代,不断优化,不断减少cost,最后,得到的估计是
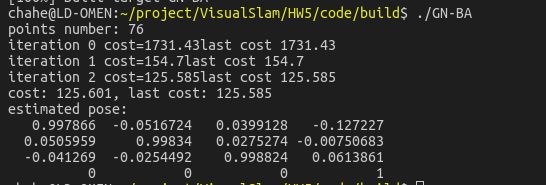
Lee Algebra相关转换
















 1843
1843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









