







《imageNet classification with Deep Convolutional Neural Network》
基于卷积神经网络的图像分类(经典网络)
作者:Alex Krizhevsky(第一作者)
单位:加拿大多伦多大学
发表会议时间: NIPS 2012
NIPS是机器学习会议上的顶级会议,是CV方向算法工程师青睐的顶会。
一:论文研究背景,成果及意义
AlexNet简介
AlexNet是在2021年被发表的一个经典之作,并在当年取得了imageNet最好成绩,论文的全称是《imageNet Classification with Deep convolutional neural network》,论文的名字可以看出此网络主要用于图像的分类任务,为什么它叫AlexNet网络,因为论文的第一作者为Alex Krizhevsky,因此命名为AlexNet。
注意: AlexNet为经典中的经典,虽然现在用的比较少,但是里面用到的一些网络训练技巧,以及预防过拟合技巧现在一直在使用,所以非常有必要去学习。
研究背景

神经网络的火爆离不开两个重要条件:
1.LabelMe, imageNet等大的标注数据集的出现,为神经网络提供了数据基础,神经网络包含了大量的权重参数,如果训练数据不够大的话会存在过拟合的问题。
2.硬件的计算能力的提升(算力较强的GPU等),因为神经网络包含大量的权重参数,如果算力不够强,训练的就很慢,基本难以实现。
所以大数据集的出现和强性能的算力硬件为神经网络的发展提供了必要的条件。
AlexNet取得的成果
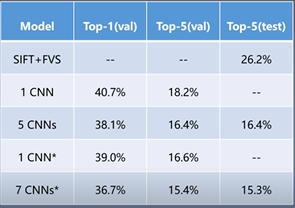
该图展示的是Alexnet在Lsvre-2012图像分类大赛中取得的成果,它以15.3%的错误率,取得了冠军,错误率远低于当时最好的学习算法SIFT+FVS。
1cc表示训练一次AlexNet取得的准确率
5CNNs 表示在五次AlexNet取平均值的准确率
CNN*在最后一个池化层之后,额外添加第六个卷积层使用imageNet 2011(秋)数据集上预训练然后使用ILSVRC-2012微调准确率
7CNNs两个网络进行了预训练微调,与5CNNs 取平均值的准确率。

在现实环境中的物体展示出多样性,这个多样式表现颜色,形状等。
比如猫存在不同品种的猫,不同品种的猫颜色大小均不一样,相同的物体在不同的光照下,不同角度看上去也会有所差别。
所以要想获得更好的识别能力需要更加庞大的训练数据和更复杂的拟合参数。
人可能认为这就是一个球,但是机器学习出来的模型,由于环境的影响,机器学习算法可能认为它是鸡蛋,或者是篮球出现了误判。神经网络相对于机器学习来说具有多个隐藏层,非线性变化所以它有更强的拟合能力。
图像分类问题简介(CNN)
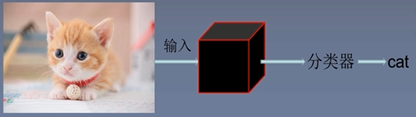
图像物体分类:
是计算机视觉中非常重要的基本问题,也是图像分割,物体追踪,行为分析等其他高层视觉任务的基础。
深度学习分类两个阶段
第一阶段:训练阶段:使用大量的有标签数据来训练网络,通过优化算法不断迭代网络,使网络达到收敛
第二阶段:测试阶段 :就是使用测试数据来测试训练出来的网络性能的好坏。
上图所示:将一张图片放到训练好的神经网络中去,经过一系列的卷积池化层来提取图像的特征,然后将提取出来的特征输入到分类器中,来匹配属于哪种类别。
图像分类的应用
活跃领域:计算机视觉,模式识别与机器学习领域等
应用领域:安防领域的人脸识别,行人检测,智能视频分析,行人追踪等,交通领域的交通场景物体的识别,车辆计数,逆行检测,车牌检测与识别,以及互联网领域的基于内容的图像检索,相册自动归类等。
图像分类的发展历史
趋势:让机器更“自主”地学习如何对图像进行分类

在机器学习领域图像识别的步骤分为:特征提取,特征筛选,输入分类器的三个步骤。对于深度学习的步骤把特征的提取,筛选和分类集成于一体。机器学习特征的提取是人为的提取很需要经验,深度学习所需要的特征是通过自助学习获得的,所以使用深度学习算法可以节省大量人力。
小知识点

鸢尾花的图片
机器学习的特征
花萼宽度 X
花萼长度 Y
花瓣长度 M
花瓣宽度 N
将XYMN输入到机器学习模型中,模型就会知道这是哪一种鸢尾花。
深度学习的特征
比较抽象难以理解
对于深度学习来说,它的特征是自主学习出来的,具体是什么难以得知。
二:未来技术研究趋势
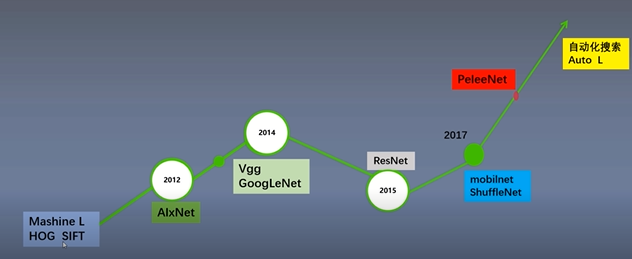
在deeplearning火爆之前一般使用机器学习方法来处理图像分类问题,2012AlexNet出现以后,使用神经网络处理图像分类问题开始流行,之后不断尝试改变网络的结构,2014年出现了Vgg GoogleleNet 等一系列优秀网络结构,这些网络的特点是使用小卷积核,并且结构变的更深更复杂,效果也更高,其中Vgg表明网络深度越深,网络的性能就越好,但是网络太深还是会有问题,当深度达到一定程度会出现梯度难以传播的问题,在2015年何凯明大佬提出的restnet成功解决了这个问题,通过实践证明,神经网络处理图像分类问题效果显著,为了方便在嵌入式设备上使用神经网络诞生了一批轻量级网络比如mobilnet & shuffleNet等,这些网络不仅计算参数少,而且效果也很好。Vgg GoogleleNet fastRNN都是大佬设计出来的,设计一个网络非常耗费人力物力,而且需要大量的专业知识,对于大部分人设计一个网络是非常困难的问题,那么如何解决这个问题呢? 自动化搜索(Auto ML)出现了,使用AutoML算法网络参数及结构可以通过学习算法来得到,这样就不需要人为去设计网络结构和参数了,有了AutoML每个人都可以成为网络设计大师。
三:前期知识储备
一:了解tensorflow的使用,以及语法特点。
二:了解CNN,Relu,Poling 的结构,掌握CNN的基本工作原理
因为网络的主要功能就是这些层的堆积。
三:了解图像分类的概念,掌握神经网络图像分类的流程
四:了解softmax如何计算,掌握softmax应用于多分类的原理。
四:学习
实践结合理论
建立知识框架修补知识漏洞
采取并行学习法
五:论文详解
1. 复习回顾
之前的学习从论文的研究背景成果及意义,图像分类发展的趋势,和前期知识储备来开始阅读论文。大数据和硬件的提升为使用神经网络处理图像分类任务提供了基础,图像分类的流程可以分为训练阶段和测试阶段,图像分类计数发展趋势是自动化趋势,和轻量化趋势,自动化趋势就是使用网络算法,自动设计网络结构,轻量化趋势就是网络所含的参数越来越少。
2.论文整体框架
摘要(abstract)
简单介绍了alexnet网络结构贡献以及取得的成果(paper的创新点)
我们训练了一个大型深度卷积神经网络来将imageNet ILSVR-2010竞赛的120万张,高分辨率图像分到1000不同的类别中,在测试数据上,我们得到了top-1, 37.5%, top-5, 17.0%d的错误率,这个结果比目前最好结果好很多。
这个神经网络有6000万超参数和650000个神经元包含了5个卷积层和3个全连接层,最后是一个1000维的softmax。为了训练的更快,我们使用非饱和神经元(Relu)并对卷积操作进行了非常有效的GPU实现,为了减少全连接层的过拟合,我们采用了一个最近开发的名为dropout的正则化方法,结果证明是非常有效的。
我们也使用这个模型的一个变种参加了ILSVRC-2012竞赛,赢得了冠军并且与第二名top-5 26.2%的错误率相比,取得了top-5 15.3%的错误率。
Relu
非线性单元Relu
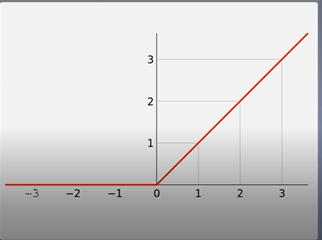
Relu变量值大于0的时候函数值为它本身,当变量值小于等于0的时候,函数值为0.
非线性单元Relu例子
# 引入tensorflow
import tensorflow as tf
# 定义恒定值的tensor(张量) a
a = tf.constant([-1.0,2.0])
#创建会话
with tf,Session() as sess:
#进行relu操作
b = tf.nn.relu(a, name='relu')
#运行输出结果
print sess.run(b)
print结果为[0.2.]tf.nn.relu API的参数有两个 features, name = None
features就是需要进行Relu操作的张量,必须要赋值。
name:给操作命名一个名称,不是必须要赋值的。
对上面代码的解释:导入tensorflow包,定义一个恒定的张量a其中有两个数值-1 和 2 ,将张量a进行relu操作,-1 小于 0 所以最终的到 0 ,而 2.0大于0 最终得到 2。
为什么使用relu作为激活函数?
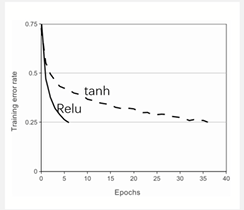
将神经元输出f建模为输入x的函数的标准方式是用f(x) = tanh(x) or f(x) = sigmoid(x)
考虑到梯度下降的训练实践,这些饱和的非线性激活函数比非饱和线性激活函数f(X) = max(0,x)训练的更慢。
根据Nair和Hinton[20]的说法,我们将这种非线性神经元称为修正性单元(RELU)
采用RELU的深度卷积神经网络训练时间比等价的tanh单元要快几倍。
relu的优点:
- 可以使网络训练更快
- 增加网络的非线性
- 防止梯度消失(弥散)
- 使网络具有稀疏性
在上图中可以看到,在训练错误率达到0.25的Relu需要5个epoch,同样的训练错误率如果使用tanh则需要使用35个epoch。由此可知使用非饱和Relu训练网络更快.
解释
-
训练快是因为相比于tanh,sigmod而言,relu的导数更好求,神经网络会用到反向传播,反向传播会涉及到激活函数的求导,tanh与sigmod包含指数且表达式复杂,他们函数的 导数会求得慢一些。
2. 增加网络非线性
卷积操作与全连接操作和pooling操作均为线性操作
relu为非线性函数,加入到神经网络中可以使网络拟合非线性的映射,因此增加网络的非线性。
3. 防止梯度消失(弥散)
表达式:
导数:
tf.math.sigmoid
Aliases:
tf.math.sigmoid
tf.nn.sigmoid
tf.sigmoid
tf.math.sigmoid(
x,
name=None
)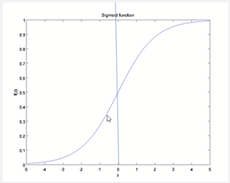
sigmod函数图像可以看出,当自变量过大或者过小的时候,sigmod函数的斜率接近0,由高等数学的知识可知函数的斜率为函数的一阶导数,所以当数值过大过小,一阶导数都接近于0.
当数值过大或者过小时,sigmod,tanh导数接近0,会导致反向传播的时候梯度消失的问题,relu为饱和激活函数不存在此问题。
4.使网络具有稀疏性
relu可以使用一些神经元输出为0,因此可以增加网络的稀疏性。
sigmoid 非线性单元
tensorflow非线性激活函数还有leaky relu, relu 6 等。
(1) introduction
神经网络有了算力更好的GPU与更大的数据集合会取得更好的效果
(2) The Dataset
ILSVRC与imagenet数据集合的介绍
(3) The Architecture
(网络的组成)
Relu 两个GPU训练 LRN overlapping polling网络整体结构
(4) Reducing Overfitting
防止过拟合计数,数据增强dropout
dropout
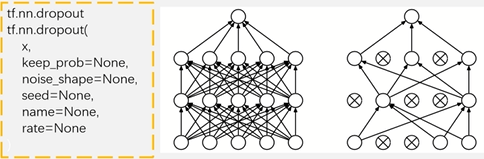
作用: 随机将一定比例的神经元置为0(随机使一批神经元输出为0)
由右图看出dropout就是随机干掉一些神经元的连接。dropout经常用在
对于一个有N个节点的神经网络,有了dropout后,就可以看作是2n个模型的集合了。
相当于机器学习中的模型融合ensemble,可以提高网络精度和泛化能力,dropout的API包含了x, keep_prob,noise_shape,seed,name,rate参数,其中keep_prob的意思是每个元素被保留下来的概率,rate是每个元素被丢弃的概率,其中的关系有:rate = 1- keep_prob
(5)Details of learning
网络超参数的设置,权重及偏置的初始化
(6) Result
详细介绍了alexnet网络在比赛中取得的结果
(7) Qualitative Evaluations
给出来做的实验,展示了卷积核学习到的内容,同一类的图像特征的欧式距离更近
(8) Discussion
结论说明了,神经网络可以很好的完成图像分类的任务
3.神经网络处理图像分类问题流程(原理角度)
训练阶段
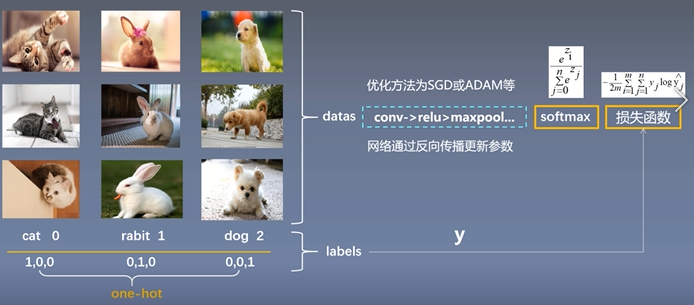
训练网络需要大量的带标签的图像,上图是部分训练数据展示,图中展示了这张图片是猫,兔子,狗的标签对,因为训练数据中含有标签,所以神经网络属于有监督学习,图像数据可以发现每个类别包含多长图片,因为这样可以让网络更好的学习到识别物体的特征,让网络的泛华能力更强,它以及学会了dog的共同特征,数据集可以分为训练集,测试集,和验证集,训练集合就是让网络进行参数学习,验证集合就是验证网络训练的效果,看看有没有过拟合,或者欠拟合,可以根据验证集的表现调整网络参数和结构,测试集合主要是测试网络的精确度和泛化能力。
训练集合的label,label有两种形式,一种为阿拉伯数字0,1,2,一种为独热编码形式对应位置的类别为1,例如上图中猫的话就是第0位为1,兔子的话是第1位为1,狗的话是第二位为1.网络训练的的时候使用这两种方法都可以,在tensorflow使用的是不同的交叉熵。
将一个batch size的数据送入到神经网络之中,经过一系列的卷积,relu,maxpooling,全连接层得到一个未归一化的概率向量,一般有几个类别,最后一层的尺寸就是1*类别数,将向量作为一个参数输入到交叉熵的API中进行损失计算。
为什么使用交叉熵计算损失函数呢?
因为交叉熵可以衡量两个概率分布的相似度,当图像输入某一类时,我们希望对应位置类别的数据越接近于1越好,cat为例,希望第一个数字越大越好,后面两个数字越小越好,这样就可以和猫的标签100越接近,得到的交叉熵就会比较小,当得到的分布与标签的分布相差较大时,此时交叉熵也较大,然后我们将交叉熵得到的损失误差进行反向传播,对网络进行参数更新,网络的优化方式可以选择SGD or ADAM等,经过参数更新,就会在下次预测cat的时候score的分布更接近label的概率分布,经过多次迭代之后,网络就可以很好的区分cat dog rabit的图片了。
softmax 与 cross enttrop
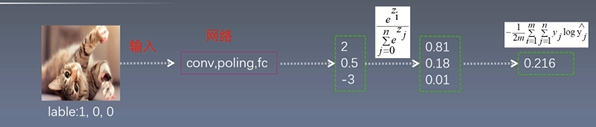
将一张猫的图片输入到网络之中,假设最后连接层输出的数据为[2, 0.5, -3], 经过softmax计算数据分布变为了概率分布[0.81 , 0.18, 0.01] 然后和label[1, 0, 0 ]计算交叉熵损失得到结果为0.216.
softmax 作用
将神经网络的输出变为概率分布
1. 数据之和为1
2. 负数变为正数
[2,0.5 ,-3]------->约等于[0.81, 0.18, 0.01]
cross entropy
交叉熵衡量两个概率分布的距离
1.值越小,两个概率就越接近
2.值越大,两个概率就越不接近
网络的输出经过softmax变化,变为概率分布,就可以用交叉熵来计算损失了。在这里令label=[1,0,0]
模型1预测的概率分布为[0.81,0.18,0.01]
loss 1 = -[1 * log(0.81) + 0 * log(0.18) + 0*log(0.01) ] = 0.21
模型2月测的概率分布为[0.5,0.3, 0.2]
losss 2 = -[1*log(0.5)+0*log(0.3)+0*log(0.2)] = 0.69
因为[0.81,0.18,0.01]更接近label的概率分布,所以交叉熵损失更小。
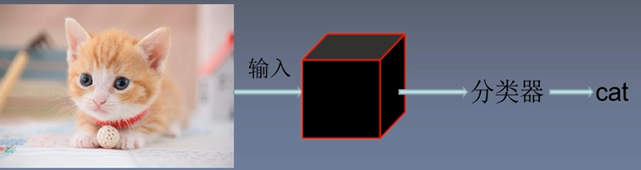
测试阶段不同于训练阶段,它只需要输入测试图片不需要标签数据。
验证时,与测试一样,只需要验证图像,不需要验证标签。
如上图,将一只cat送入到网络中,得到一个score(0.9, 0.05,0.05)我们取最大值的索引作为它的类别,这里的最大值为0.9,0.9的索引为0查看0对应的类别为猫,可以看到该网络可以正确预测图片。
模型衡量标准
在实际的测试集中会包含多张图片,有预测正确的也有预测错误的。
常用的评判标准有:准确率,召回率,top-1错误, top-5错误
top-1 错误率 top-5 错误率
top-1 错误率:
取概率向量里面最大的哪一个作为预测结果,如果结果分类正确,则预测正确否则预测错误
top-5 错误率:
取概率向量里前面五个大的作为预测结果,预测结果中只要出现了正确类别即为预测正确,否则预测错误。
eg:(0.1, 0.15, 0.11, 0.14, 0.2, 0.3)
最大为0.3,即为第五类,如果标签为第五类则预测正确
前五最大0.3, 0.2, 0.15, 0.14,0.11 预测为第五,四,一, 三,二类有一个正确则正确
假如有100个样本,取概率向量里的最大值,正确的分类有80张,则top-1错误率为20%
取概率向量里面前五个最大值,正确分类有90张,则top-5错误率为10%
4.网络参数及部分参数计算(Alexnet具体参数)
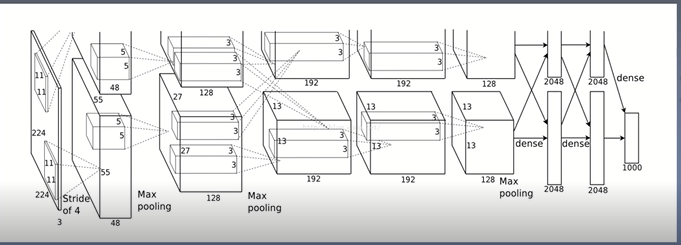
论文给出AlexNet网络机构图可以看出一共包含了5个(长方体)卷积层,三个全连接层,三个maxpooling层,需要注意的是,论文中标注的输入图片的大小为224*224,而实际上输入图像的大小为227*227,可以看到网络的计算分为了两个通道,在特定的通道上进行通信,之前的GPU的不支持在同一个通道上计算,所以使用了两块GPU,每块GPU负责一部分的计算,
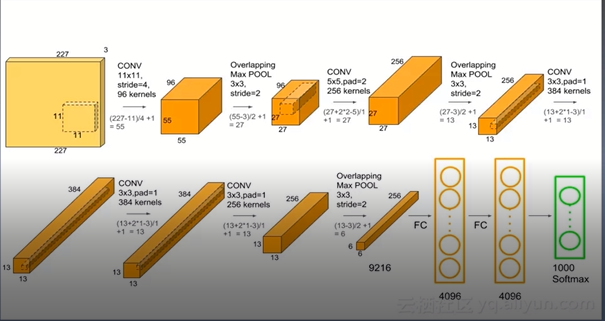
由于论文中的图片较为抽象,所以引用其他位置的图片
由上图可知,第一层为11*11*4的卷积核,第二层为大小为3*3的最大池化,第三层为5*5*256的卷积,,第四层为3*3的最大池化,第五层为3*3*384的卷积层,第六层为3*3*384的卷积层,第七层为3*3*256的卷积层,第八层是3*3的最大池化层,最后三层为全连接层,他们的尺寸为4096,4096,1000,最后一层为1000的原因是imagenet一共有1000类,一般数据中有几类,最后一层数据连接层的大小就是1*类别数。
网络结构:conv1 relu1 norml-->pool1-->conv2 relu2 norm2 --> pool2-->conv3relu3-->conv4 relu4-->conv5 relu5-->pool5-->fc6 relu6 dropout6 -->fc7 relu7 dropout7-->fc8(logits)-->softmax
一般我们称最后一个全连接层fc8为logits,意思是没有经过归一化的概率分布,也就是神经网络提取出来最终的分布。
卷积的细节
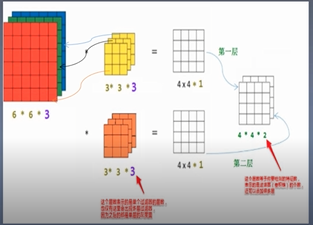
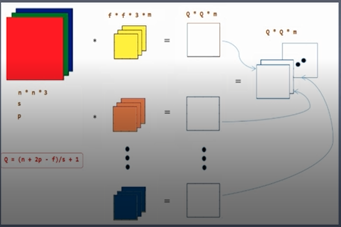
左图:先忽略到特征图和卷积核的尺寸可以看到,输入的特征通道为3,则使用的卷积核通道也为3,一般情况下,这两个值必须一致,若输入的特征图的通道数为4的话,那么卷积核的通道数也应该为4,若不一致的话在tensorflow中会报错,卷积核个数与输出特征map的个数可以看到两个卷积核最终输出两个特征map.右图中一共有m个卷积核,那么一共输出m个featuremaps。
1.输入特征map的通道数的多少,卷积核的通道就是多少,这个数值一般情况是相等的。
2.有多少个卷积核就有多少输出特征Map
网络每层特征map的大小,即网络参数以及连接计算
特征map的计算方式:卷积有两种计算方式一种为VALID一种为SAME计算方式
卷积的通用计算方式为
输出特征map = (输入特征map+二倍的padding-卷积核的大小)/ strids 如果除不尽就进行下取整+1
为什么是2p? 因为我们对图像进行填充的时候是对图像的上下左右个填充p个像素,所以是2p.
在tensorflow中若源码的卷积方式为VALID的时候
输出特征map = (输入特征图的尺寸-卷积核的大小+1)/strids,如果除不尽则进行上取整。
当卷积特征为SAME的时候:
输出特征map = (输入特征图尺寸/strids),如果除不净就进行上取样。
网络参数量的计算公式为:
卷积核尺寸乘以卷积核的通道数加一乘以输出特征图的通道数
有多少个卷积核就有多少个feature Map所以上面的公式也可以写成
参数量计算的时候也可以去掉1,因为这个1很小可以忽略不计。
连接数量计算公式:
输出特征图尺寸X(卷积核大小X卷积核通道+1)X 输出特征图通道数
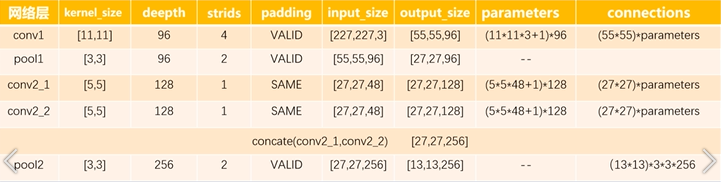
如图第一层为卷积层:输入特整图的尺寸为227*227*3包含了96个大小为11*11通道数为3的卷积核,卷积核的通道数=输入特征图map的通道为3,卷积方式为VALID ,strids = 4,带入公式为(277-11+1)/4 = 54.25,上去整为55,所以第一层的输出特征map为[55,55,96] parameters = (11*11*3+1)*96 连接数为:(55*55)*parameters。
第二层为最大池化层,池化也是一种卷积操作,卷积方式默认为VALID,池化操作会改变特征图的大小,而不会改变它的通道数,该层池化层的尺寸为3*3,strids = 2,它输入特征图的大小为[55,55,96]经过池化操作以后特征图的大小为(55-3+1)/2=26.5经过上取样为27,最终得到27+27+96的特征图。
第三层与第四层各负责一半特征图的处理
第三层:27/1=27最终得到的特征图的大小为[27*27*128]
第四层与第三层一样
然后将conv2_1与conv2_2进行拼接操作得到(27*27*256)
pool2层 (27-3+1)/2=12.5上取样等于13,所以得到特征图的大小为[13,13,256]
其他计算量FLOATS用来衡量计算的复杂度。
5.网络超参数及训练(具体数值介绍,策略)
训练数据
ALexnet因为包含了许多权重参数,很容易过拟合,所以在训练的时候使用了数据增强计数
1.随机的从256*256的原始图像中截取224*224大小的区域(以及水平翻转及镜像),相当于增加了2*(256-224)^2=2048倍的数据量。可以减少过拟合,提升泛化能力。
2.对图像的RGB数据进行PCA处理,并对主成分做一个标准差为0.1的高斯扰动,增加一些噪声,这个Trick可以让错误率再下降1%。
3.进行预测时,则是取图片的四个角加中间一共5个位置,并运行左右翻转,一共获得10张图片,对它们进行预测并对10次结果求均值作为最后的预测结果。
超参数的设置
批量大小:batchsize = 128
权重衰减: weight decay = 0.0005
学习率:learning rate = 0.01 衰减率为0.1
学习率衰减的规则为:当网络精度不变化时人为的将衰减率衰减0.01,比如初始化为0.01,经过一次衰减学习率就会变为0.001.
轮数:epoches = 90
卷积核初始化方式:均值为0方差为1的高斯分布
偏置初始化方式:2,4,5卷积层及全连接层初始化为1,剩余层数初始化为0
知识补充
datas numbers 数据量
训练数据的总数据量,比如数据一共包含64万图片那么总数据量就是64万
batchsize 批量大小
每次输入到网络的数据量,比如一次输入到网络64万张图片batchsizes = 64
steps迭代次数
网络学习完成所有数据需要的次数,比如batchsize = 64,那么过完所有数据需要网络迭代一万次,steps = 10000.即数据量/批量大小 = 迭代次数
epoch 轮数
网络学习一遍所有数据为一个epoch。
6.网络特点(总结)
(一)成功使用作为CNN的激活函数,并验证其效果在较深的网络超过了sigmoid,成功解决了sigmoid在网络较深的梯度弥散问题。
(二)训练时使用Dropout随机忽略一部分神经元,以避免模型的过拟合。Dropout虽然有单独的论文轮数,但是Alexnet将其实用化,通过实践证明了它的效果,在Alexnet中主要是最后几个全连接层使用了dropout.
(三)在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,alexnet全部使用最大池化,避免品均池化的模糊化效果。并且让步长比该池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升特征的丰富性。
(四)提出了LRN层,对局部神经元的活动创建竞争机制,使得其中影响比较大的值相对更大,并抑制其他反馈较小的神经元,增强模型的泛化能力。(后来的VGG证明这个作用不大)
(五)使用CUDA(多卡训练)加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。Alexnet使用两块 GTX 580 GPU进行训练,同时Alexnet的设计让GPU之间的通信只在网络的某些层进行,控制了通信的性能损耗。
(六)数据增强,随机从256*256的原始图像中截取224*224大小的区域(以及水平翻转的镜像)对图像的RGB数据进行PCA处理,并对主成分做一个标准差为0.1的高斯扰动,增加一些噪音,这个Trick可以让错误率再下降1%。
掌握重点:
A 图像训练的流程(网络训练的过程)
Bfeaturemap尺寸,可训练的参数,连接参数的计算
C防止过拟合技术(数据增强,dropout)以及relu激活函数。

















 1078
1078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









