






目录
1 概述
“由于数据列的离散性,信息时区内将出现空集(不包含信息的定时区),因此只能按近似的微分方程条件,建立近似的,不完全确定的微分方程模型”
我们应该怎么理解呢?简而言之,我们就是要对数列建立近似的微分方程模型,但是由于微分方程的适合函数首先要满足可微的条件,但是一个时间序列的数据不是连续的,可导不一定连续,连续一定不可导!,参照高数的概念理解我们知道可导和可微是大致一致的。不可导的函数也就不可微分。
因此我们要想建立灰色预测模型,得到的只能是一个近似的微分方程。在《灰色系统理论教程》中我们称之为"灰色微分方程"。
灰色预测模型是通过少量的、不完全的信息,建立数学模型并做出预测的一种预测方法。灰色系统理论建模采用的是先对原始数据列做生成处理再成立微分方程模型。是处理小样本(4个就可以)预测问题的有效工具,而对于小样本预测问题回归和神经网络的效果都不太理想。
最简单的模型是GM(1,1),G:Grey(灰色);M:模型;(1,1):只含有单变量的一阶微分方程模型。
GM(1,1)首先对原始非负离散数据进行一个一阶累加处理(白化过程),然后对这组数据利用最小二乘法(和线性回归的方式十分类似)求解灰色系数,利用灰色系数构建灰色微分方程,求解微分方程既可以得到拟合公式。
灰色预测适用条件:用于时间短、数据资料少、数据不需要典型的分布规律、计算量较低、对短期预测有较高精度。不适合随机波动较大的数据。gm(1,1)适合白化后是指数趋势的数据(这样构建的微分方程的解才更适合拟合指数数据),灰色预测是利用趋势建模。
2 流程图
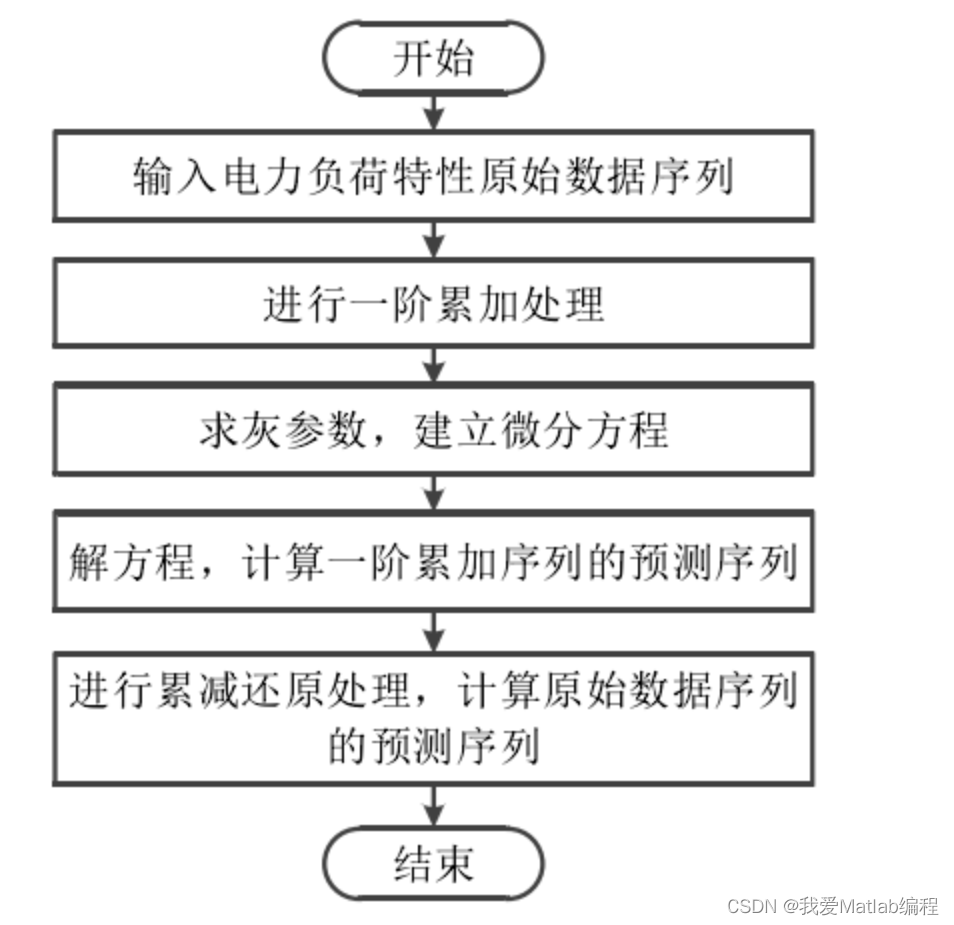
3 入门算例
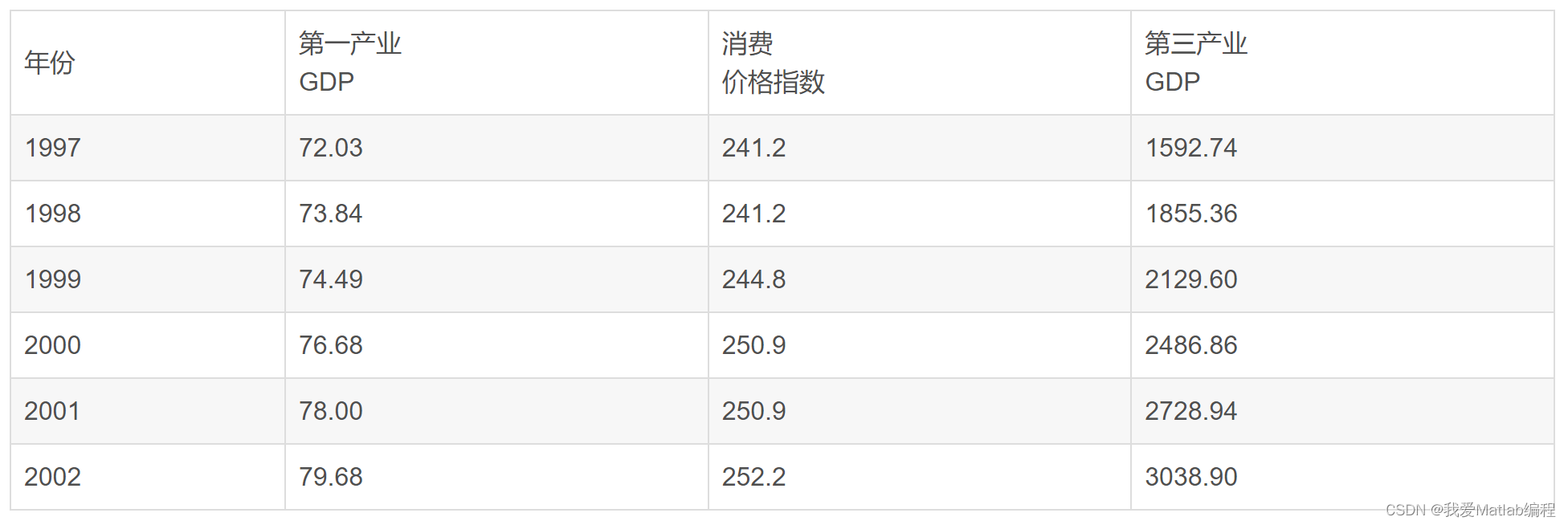
现有1997—2002年各项指标相关统计数据如下表:
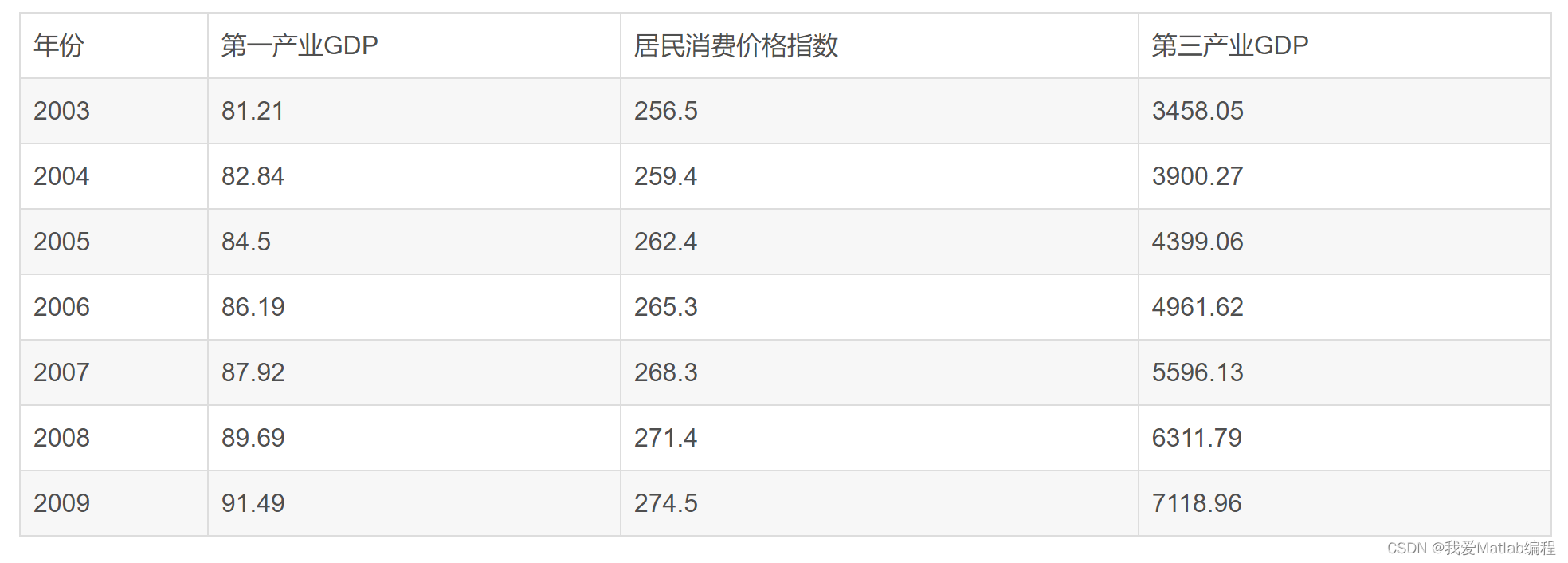
用灰色预测方法预测2003—2009年各项指标的数据。且已知实际的预测数据如下:将预测数据与实际数据进行比较
import numpy as np
import matplotlib.pyplot as plt
import math
# 解决图标题中文乱码问题
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
#原数据
data=np.array([[72.03,241.2,1592.74],[73.84,241.2,1855.36],[74.49,244.8,2129.60],[76.68,250.9,2486.86],[78.00,250.9,2728.94],[79.68,252.2,3038.90]])
#要预测数据的真实值
data_T=np.array([[81.21,256.5,3458.05],[82.84,259.4,3900.27],[84.5,262.4,4399.06],[86.19,265.3,4961.62],[87.92,268.3,5596.1],[89.69,271.4, 6311.79],[91.49,274.5,7118.96]])
#累加数据
data1=np.cumsum(data.T,1)
print(data1)
[m,n]=data1.shape #得到行数和列数 m=3,n=6
#对这三列分别进行预测
X=[i for i in range(1997,2003)]#已知年份数据
X=np.array(X)
X_p=[i for i in range(2003,2010)]#预测年份数据
X_p=np.array(X_p)
X_sta=X[0]-1#最开始参考数据
#求解未知数
for j in range(3):
B=np.zeros((n-1,2))
for i in range(n-1):
B[i,0]=-1/2*(data1[j,i]+data1[j,i+1])
B[i,1]=1
Y=data.T[j,1:7]
a_u=np.dot(np.dot(np.linalg.inv(np.dot(B.T,B)),B.T),Y.T)
# print(a_u)
#进行数据预测
a=a_u[0]
u=a_u[1]
T=[i for i in range(1997,2010)]
T=np.array(T)
data_p=(data1[0,j]-u/a)*np.exp(-a*(T-X_sta-1))+u/a #累加数据
# print(data_p)
data_p1=data_p
data_p1[1:len(data_p)]=data_p1[1:len(data_p)]-data_p1[0:len(data_p)-1]
# print(data_p1)
title_str=['第一产业GDP预测','居民消费价格指数预测','第三产业GDP预测']
plt.subplot(221+j)
data_n=data_p1
plt.scatter(range(1997,2003),data[:,j])
plt.plot(range(1997,2003),data_n[X-X_sta])
plt.scatter(range(2003,2010),data_T[:,j])
plt. plot(range(2003,2010),data_n[X_p-X_sta-1])
# plt.title(title_str[j])
plt.legend(['实际原数据','拟合数据','预测参考数据','预测数据'])
y_n=data_n[X_p-X_sta-1].T
y=data_T[:,j]
wucha=sum(abs(y_n-y)/y)/len(y)
titlestr1=[title_str[j],'预测相对误差:',wucha]
plt.title(titlestr1)
plt.show()4 基于灰色预测算法的负荷预测(Python代码实现)
数据全部代码数据需要的自行下载:
链接:https://pan.baidu.com/s/11T39K3XO3iOqqnhYeHFJpA
提取码:139v
--来自百度网盘超级会员V2的分享
'''1导入相关库'''
import pandas as pd
import numpy as np
import seaborn as sns
import os
import datetime
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei'] #黑体换成SimHei
mpl.rcParams['axes.unicode_minus'] = False
from decimal import * #精确计算
'''2 创建灰色预测函数类'''
class GM11():
def __init__(self):
self.f = None
def isUsable(self, X0):
'''判断是否通过光滑检验'''
X1 = X0.cumsum()
rho = [X0[i] / X1[i - 1] for i in range(1, len(X0))]
rho_ratio = [rho[i + 1] / rho[i] for i in range(len(rho) - 1)]
# print(rho, rho_ratio)
flag = True
for i in range(2, len(rho) - 1):
if rho[i] > 0.5 or rho[i + 1] / rho[i] >= 1:
flag = False
print("rho[-1]:"+str(rho[-1]))
if rho[-1] > 0.5:
flag = False
if flag:
print("数据通过光滑校验")
else:
print("该数据未通过光滑校验")
'''判断是否通过级比检验'''
lambds = [X0[i - 1] / X0[i] for i in range(1, len(X0))]
X_min = np.e ** (-2 / (len(X0) + 1))
X_max = np.e ** (2 / (len(X0) + 1))
for lambd in lambds:
if lambd < X_min or lambd > X_max:
print('该数据未通过级比检验')
return
print('该数据通过级比检验')
def train(self, X0):
X1 = X0.cumsum(axis=0) # [x_2^1,x_3^1,...,x_n^1,x_1^1] # 其中x_i^1为x_i^01次累加后的列向量
Z = (np.array([-0.5 * (X1[:, -1][k - 1] + X1[:, -1][k]) for k in range(1, len(X1[:, -1]))])).reshape(
len(X1[:, -1]) - 1, 1)
# 数据矩阵A、B
A = (X0[:, -1][1:]).reshape(len(Z), 1)
B = np.hstack((Z, X1[1:, :-1]))
# 求参数
u = np.linalg.inv(np.matmul(B.T, B)).dot(B.T).dot(A)
a = u[0][0]
b = u[1:]
print("灰参数a:", a, ",参数矩阵b:", b)
self.f = lambda k, X1: (X0[0, -1] - (1 / a) * (X1[k, ::]).dot(b)) * np.exp(-a * k) + (1 / a) * (X1[k, ::]).dot(
b)
def predict(self, k, X0):
'''
:param k: k为预测的第k个值
:param X0: X0为【k*n】的矩阵,n为特征的个数,k为样本的个数
:return:
'''
X1 = X0.cumsum(axis=0)
X1_hat = [float(self.f(k, X1)) for k in range(k)]
X0_hat = np.diff(X1_hat)
X0_hat = np.hstack((X1_hat[0], X0_hat))
return X0_hat
def evaluate(self, X0_hat, X0):
'''
根据后验差比及小误差概率判断预测结果
:param X0_hat: 预测结果
:return:
'''
S1 = np.std(X0, ddof=1) # 原始数据样本标准差
S2 = np.std(X0 - X0_hat, ddof=1) # 残差数据样本标准差
C = S2 / S1 # 后验差比
Pe = np.mean(X0 - X0_hat)
temp = np.abs((X0 - X0_hat - Pe)) < 0.6745 * S1
p = np.count_nonzero(temp) / len(X0) # 计算小误差概率
print('============= evaluate =============')
print("原数据样本标准差:", S1)
print("残差样本标准差:", S2)
print("后验差:", C)
print("小误差概率p:", p)
'''3 构建模型,进行测试集数据预测'''
#===3.1 划分训练集和测试集=====
data = pd.read_csv('power_consumption.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime'])
# 原始数据X
X = data.values
#按0.7和0.3的比例划分训练集
split_line = int(len(X)*0.7)
# 训练集
X_train = X[:split_line, :]
# 测试集
X_test = X[split_line:,:]
#数据量查看
print(len(X_train),len(X_test)) #out:(1009, 433)
#====3.2 评估模型,训练,并预测==========
# 特征数据集
model = GM11()
'''利用训练集判断模型可行性'''
model.isUsable(X_train[:, -1]) # 判断模型可行性
model.train(X_train) # 训练
'''利用训练集完成后的模型预测训练集的数据'''
X_train_pred = model.predict(len(X_train), X_train[:, :-1]) # 预测
score_train = model.evaluate(X_train_pred, X_train[:, -1]) # 评估
'''利用训练集完成后的模型预测验证集的数据'''
Y_test_pred = model.predict(len(X_test), X_test[:, :-1]) # 预测
score_test = model.evaluate(Y_test_pred, X_test[:, -1]) # 评估
#====3.3 训练集和测试集 原始数据和预测值进行对比================
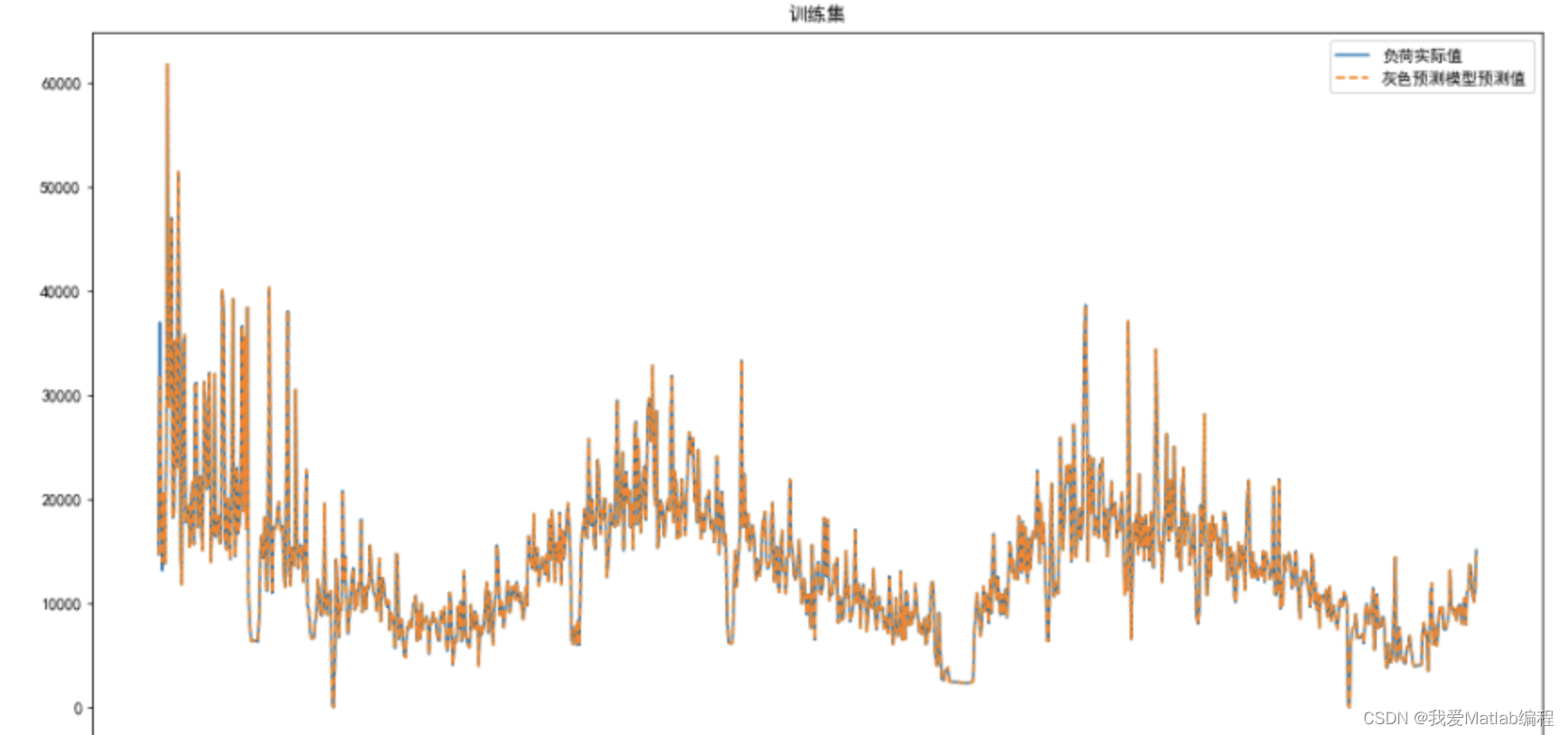
'''训练集可视化'''
plt.figure(figsize=(16,8))
plt.plot(np.arange(len(Y_train_pred)), X_train[:, -1], '-.',color='r')
plt.plot(np.arange(len(Y_train_pred)), Y_train_pred, '--',color='y')
plt.legend(['负荷真实值', '灰色预测负荷预测值'])
plt.title('训练集')
plt.savefig('灰色预测负荷预测值.png', dpi=1000, bbox_inches="tight")
plt.show()
'''验证集可视化'''
plt.figure(figsize=(16,8))
plt.plot(np.arange(len(Y_test_pred)), X_test[:, -1], '-')
plt.plot(np.arange(len(Y_test_pred)), Y_test_pred, '--')
plt.legend(['负荷真实值', '灰色预测负荷预测值'])
plt.title('测试集')
plt.savefig('灰色预测负荷预测值1.png', dpi=1000, bbox_inches="tight")
plt.show()
#=======3.4 以表格形式对比测试集原始目标数据和预测目标数据======
'''判断数据类型'''
type(X_test[:, -1]),type(Y_test_pred) #out:(numpy.ndarray, numpy.ndarray)
'''预测数据对比'''
## 预测数据对比
compare = pd.DataFrame({
"原数据":X_test[:, -1],
"预测数据":Y_test_pred
})
print(compare)
'''随机编写数据进行测验'''
### 随机编写2个数据,真实目标列值为:16983.666650、11329.833340,参照上表头两行数据
data_random = [[1941.940,154.028,347746.67,8210.4,3712.0,4357.0,7300.0,500],[1636.610,235.964,346675.11,6947.6,2085.0,970.0,12884.0,300]]
X_random = np.array(data_random)
## 对数据进行预测
Y_random_pred = model.predict(len(X_random), X_random[:, :-1]) # 预测
print(Y_random_pred)
#训练集可视化
plt.figure(figsize=(16,8))
plt.plot(np.arange(len(Y_random_pred)), X_random[:, -1], '-',color='m')
plt.plot(np.arange(len(Y_random_pred)), Y_random_pred, '-.',color='b')
plt.legend(['负荷实际值', '灰色预测模型预测值'])
plt.title('训练集')
plt.savefig('灰色预测负荷预测值2.png', dpi=1000, bbox_inches="tight")
plt.show()
# out:[14680.9333193 11805.7573936]
















 2709
2709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









