








原文
代码
Abstract
大规模NLP模型已被证明可以显著提高语言任务的性能,而不会出现饱和的迹象,他们还展示了像人类一样的惊人的few-shot能力.本论文旨在探索计算机视觉中的大规模模型。
我们解决了大视觉模型训练和应用中的三个主要问题,包括训练不稳定性、预训练和微调之间的分辨率差距以及对标记数据的饥渴
提出了三种主要技术:
1)残差-后范数法结合余弦注意提高训练稳定性;
2)采用对数空间连续位置偏差方法,将低分辨率图像预训练的模型有效地转移到具有高分辨率输入的下游任务中
3)一种自监督预训练方法SimMIM,以减少对大量分类图像的需求
通过这些技术,本文成功训练了一个30亿个参数的Swin Transformer V2模型,这是迄今为止最大的密集视觉模型,并使其能够使用分辨率高达1,536×1,536的图像进行训练
在ImageNet-V2图像分类、COCO目标检测、ADE20K语义分割、Kinetics-400视频动作分类等4项代表性视觉任务上创造了新的性能记录
我们的训练比b谷歌的十亿级视觉模型更有效,后者消耗的标记数据少了40倍,训练时间也少了40倍
Introduction
为了成功地训练大型和通用的视觉模型,我们需要解决几个关键问题
不稳定性问题
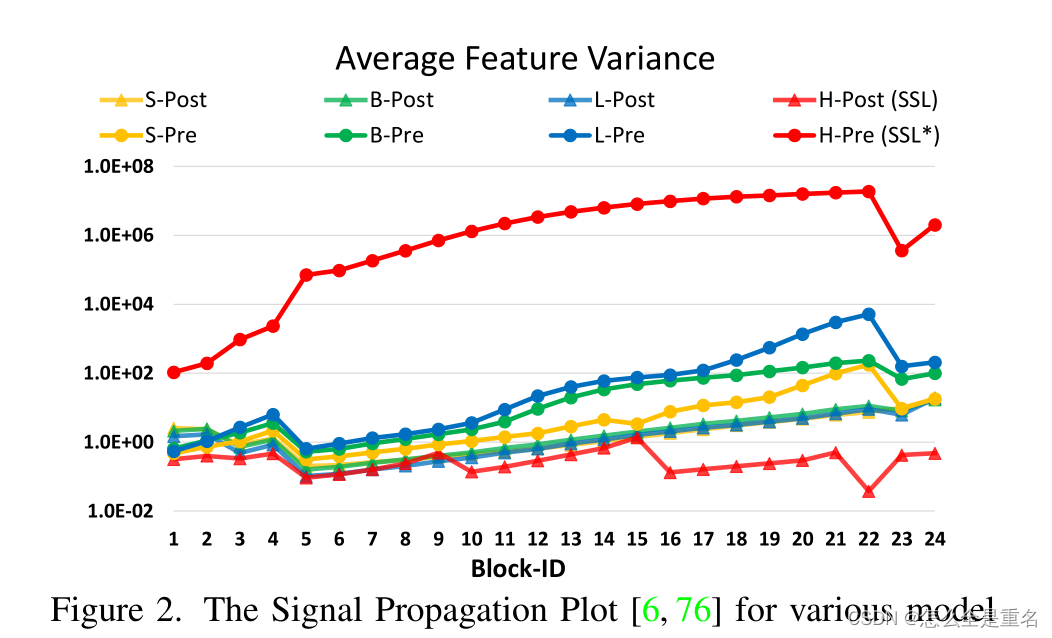
首先,我们对大视觉模型的实验揭示了训练中的不稳定性问题:我们发现,在大型模型中,不同层间的激活振幅差异显著增大,仔细观察原始架构就会发现,这是由直接添加回主分支的剩余单元的输出引起的,结果表明,激活值是逐层累积的,较深层的振幅明显大于早期的
为了解决这个问题,我们提出了一种新的规范化配置,称为res-post-norm,它将LN层从每个剩余单元的开始移动到后端,如图1所示
为了更好地扩展模型容量和窗口分辨率,对原始Swin Transformer架构(V1)进行了一些调整,我们发现,这种新配置在网络层上产生的激活值要温和得多,我们还提出了一种缩放余弦注意来取代之前的点积注意,缩放余弦注意使得计算与块输入的幅度无关,并且注意值不太可能陷入极端。在我们的实验中,这两种技术不仅使训练过程更加稳定,而且提高了训练精度,特别是对于更大的模型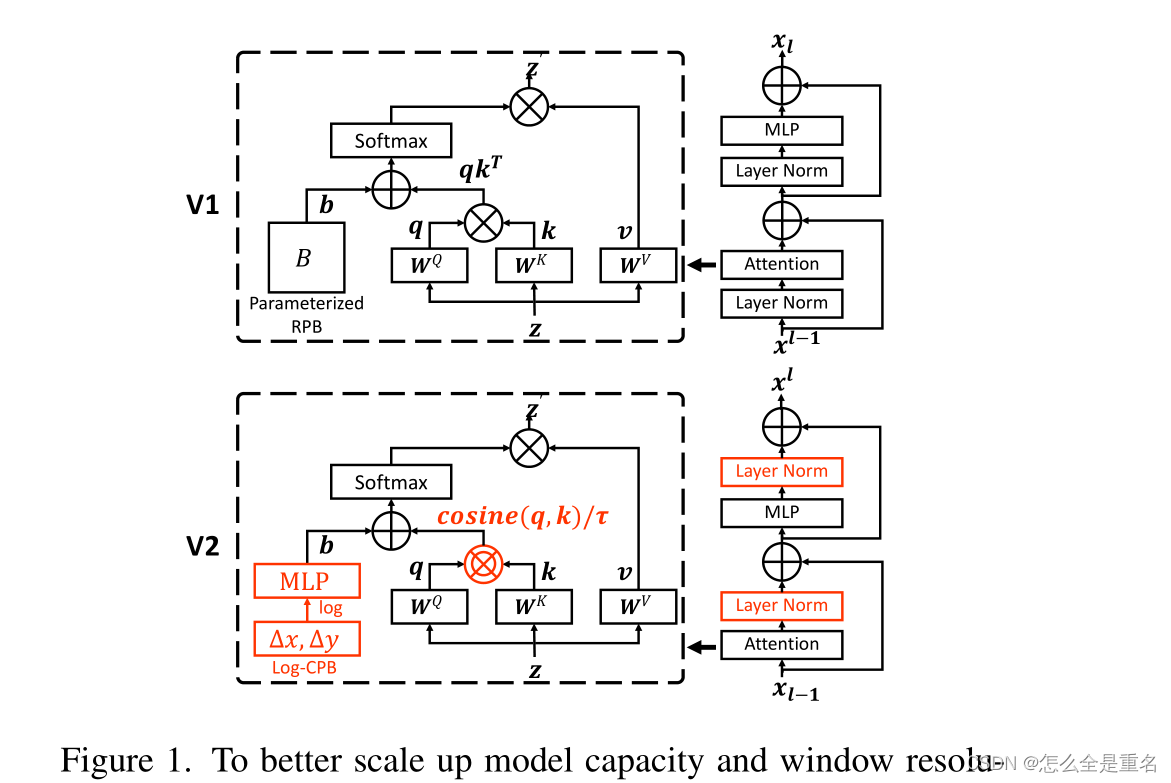
为了更好地扩展模型容量和窗口分辨率,对原始Swin Transformer架构(V1)进行了一些调整:
1)用 res-post-norm 取代前规范配置;2)用缩放余弦方法代替原有的点积方法;3)用对数间隔连续相对位置偏差方法代替之前的参数化方法
(1)和(2)使模型更容易扩展容量。自适应(3)使模型更有效地跨窗口分辨率传输
下游任务需要的高分辨率问题
许多下游视觉任务,如目标检测和语义分割,需要高分辨率的输入图像或大的注意窗口,低分辨率预训练和高分辨率微调之间的窗口大小变化可能相当大
目前常见的做法是对位置偏置图进行双三次插值。这个简单的修复方法有些特别,结果通常不是最优的
我们引入了对数间隔连续位置偏置(Log-CPB),它通过在对数间隔坐标输入上应用一个小元网络来生成任意坐标范围的偏置值,由于元网络采用任意坐标,预训练模型将能够通过共享元网络的权重自由地跨窗口大小转移
我们方法的一个关键设计是将坐标转换到对数空间中,这样即使目标窗口大小明显大于预训练的窗口大小,外推率也可以很低
解决内存问题
模型容量和分辨率的扩展导致现有视觉模型的GPU内存消耗过高
为了解决内存问题,我们结合了一些重要的技术,包括零优化器[54],激活检查指向[12]和一种新的自关注计算实现
-
使用这些技术,大模型和分辨率的GPU内存消耗显着降低,对训练速度只有边际影响。
Related Works
Language networks and scaling up
随着容量的增加,各种语言基准测试的准确性得到了显著提高。零样本或少样本性能也得到了显著提高,这是人类通用智能的基础
Vision networks and scaling up
可能是由于CNN架构中的归纳偏差限制了建模能力,绝对的性能并不是那么好
只有少数作品试图扩大ViT的规模[17,56,80]。然而,它们依赖于一个巨大的带有分类标签的图像数据集,即JFT-3B,并且仅用于图像分类问题
Transferring across window / kernel resolution
允许可变窗口大小在使用上更方便,以便被可能变化的整个特征映射所整除,并调整接受域以获得更好的交流精度
在本文中,我们提出了同间距连续位置偏差方法(Log-CPB),该方法可以更平滑地将低分辨率下的预训练模型权重转移到处理高分辨率窗口
Swin Transformer V2
Swin Transformer简介
Swin Transformer是一个通用的计算机视觉骨干,在区域级目标检测、像素级语义分割和图像级图像分类等各种粒度识别任务中取得了较强的性能。Swin Transformer的主要思想是在普通Transformer编码器中引入几个重要的视觉先验,包括层次、局部性和平移不变性,它结合了两者的优势:Transformer基本单元具有强大的建模能力,并且视觉先验使其对各种视觉任务友好
Scaling Up Model Capacity
当我们扩大模型容量时,在更深的层上观察到激活值的显著增加
事实上,在预归一化配置中,每个残差块的输出激活值直接合并回主支路,并且主支路的振幅在更深的层上变得越来越大。各层振幅差异大,导致训练失稳
Post normalization
为了缓解这个问题,我们建议使用残差后归一化方法,如图1所示
这种方法的激活幅度比原始的预归一化配置要温和得多,如图2
Scaled cosine attention
我们提出了一种缩放余弦注意方法,该方法通过缩放余弦函数计算像素对I和j的注意对数
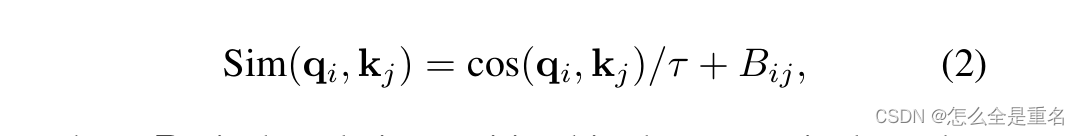
Scaling Up Window Resolution
我们引入了一种对数间隔的连续位置偏置方法,使得相对位置偏置可以在窗口分辨率之间平滑地传递
Self-Supervised Pre-training
在这项工作中,我们利用了一种自我监督的预训练方法,SimMIM[72],以减轻对标记数据的需求
Implementation to Save GPU Memory
为了解决内存问题,我们采用了以下实现
Zero-Redundancy Optimizer (ZeRO)
Activation check-pointing
Sequential self-attention computation
Experiment
我们在ImageNet-1K图像分类(V1和V2)[18,55]、COCO目标检测[44]和ADE20K语义分割[85]上进行了实验。对于3B模型实验,我们也报告了kinect -400视频动作识别的准确性
Conclusion
我们已经提出了将Swin Trans- former缩放到30亿个参数的技术,并使其能够使用高达1,536×1,536分辨率的图像进行训练,包括res-post-norm和缩放余弦注意,使模型更容易在容量上缩放,以及对数间隔连续相对位置偏差方法,使模型更有效地跨窗口分辨率传输。
对改编后的体系结构进行命名Swin Transformer V2,通过扩大容量和分辨率,它在4个代表性视觉基准上创下了新的记录















 4170
4170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









