







世界上能够生存下来的物种,不是那些最强壮的,也不是那些最聪明的,而是那些应变迅速的”。
——达尔文

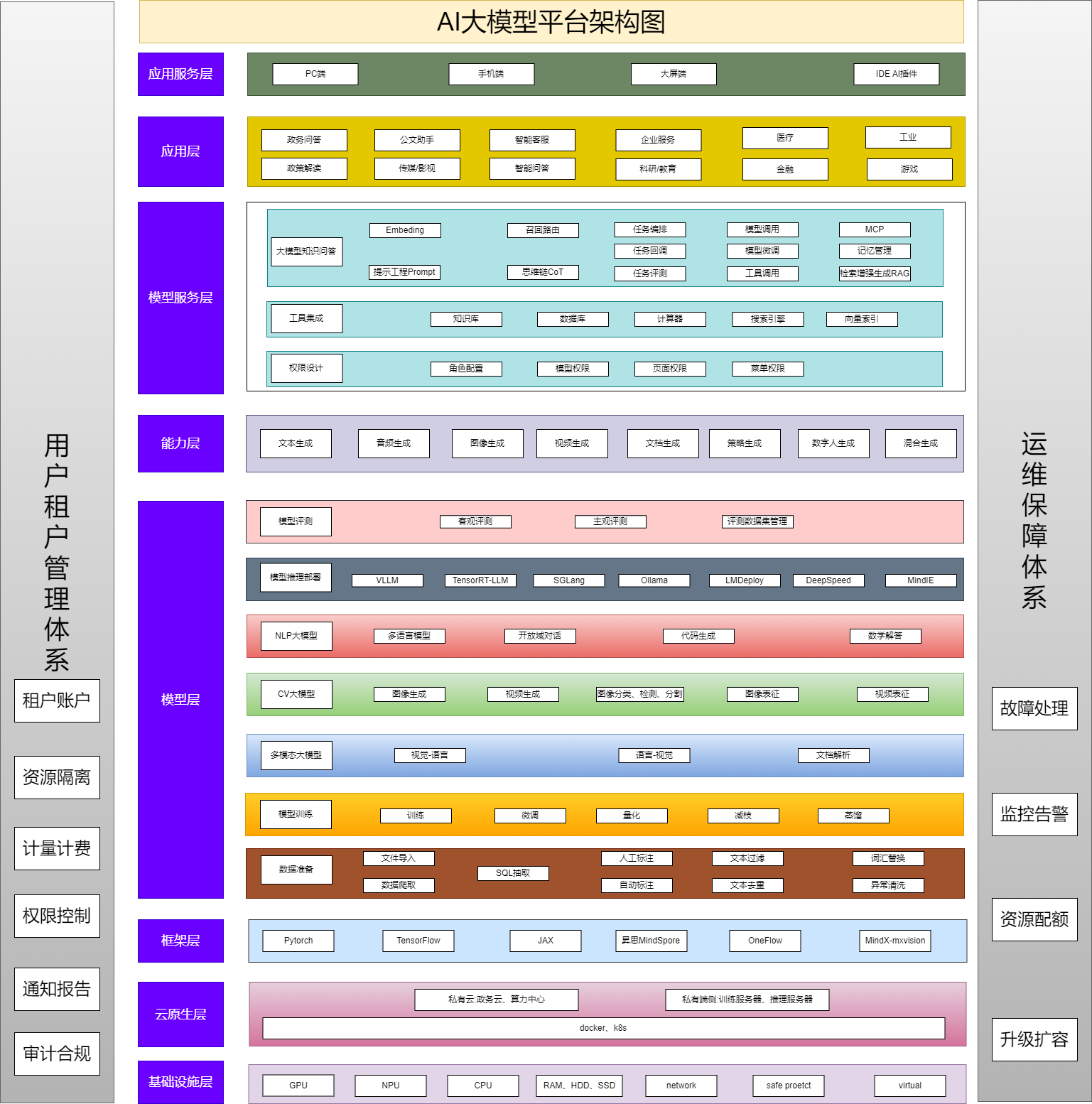
整个架构主要分为8个层次,分别是基础设施层、云原生层、框架层、模型层、能力层、模型服务层、应用层、应用服务层。这些层次共同构成了一个完整的技术生态系统,从底层硬件支持到顶层应用呈现,层层递进,相辅相成。
一、基础设施层
基础设施层是 AI 大模型平台运行的硬件根基。GPU(图形处理器)和 NPU(微处理器)凭借强大的并行计算能力,大幅加速深度学习模型的训练与推理过程,尤其适用于处理大规模数据和复杂算法。CPU 则负责协调和管理整个系统的运行。
RAM(随机存取存储器)为模型运行和数据处理提供快速的临时存储,保证数据能够被迅速读取和写入。HDD(机械硬盘)和 SSD(固态硬盘)作为数据的长期存储介质,HDD 适合大容量、对读写速度要求不太高的数据存储,而 SSD 以其高速读写性能,常用于存储需要频繁访问的数据。
network(网络)确保数据在平台各组件间的高效传输,无论是模型训练数据的分发,还是推理结果的返回,都依赖稳定高速的网络。security protect(安全防护)通过防火墙、加密技术、入侵检测等手段,防止数据泄露、恶意攻击和非法访问,保障平台和用户数据的安全。
二、云原生层
云原生层基于云计算技术构建,提供灵活且可扩展的资源管理与服务环境。私有云、政务云、算力中心等为平台提供了多样化的部署选择,满足不同用户对数据隐私和安全的需求。
K8S(Kubernetes)作为容器编排系统,可自动管理容器化应用的部署、扩展、更新和故障恢复。它能够根据实际需求动态分配计算资源,提高资源利用率,同时简化应用的运维管理。服务网格(如 Istio )管理服务间通信。此外,容器技术的应用使得应用的打包、分发和部署更加便捷,不同环境下的一致性得到有效保障。
三、框架层
框架层为 AI 模型的开发提供了基础工具和平台。PyTorch 以其动态计算图的特性,受到众多科研人员和开发者的青睐,便于快速实验和迭代模型。TensorFlow 则以其高度的灵活性和广泛的生态系统,适用于从研究到生产环境的各种场景。
JAX 结合了可组合的变换函数和自动微分功能,能够在多个加速器上高效运行。MindSpore 是华为推出的深度学习框架,具有端边云协同、自动并行等特点,提升了模型开发的效率和性能。OneFlow 和 MinMaxVision 也各自具备独特的优势,为开发者提供了多样化的选择,满足不同的开发需求和应用场景。
四、模型层
(一)数据准备
负责训练数据的采集、存储、清洗、标注等全流程管理,保障数据质量。
- 文本导入:将文本数据引入训练流程,可处理不同格式、来源的文本数据。
- 数据标注:对原始数据进行人工或半自动标注,为模型训练提供带有标签的样本。
- 数据增强:通过多种数据变换手段增加训练数据的多样性和数量,提升模型泛化能力。
- 人工标注:人工对数据进行标记、分类等操作,确保标注准确性和一致性。
- 文本清洗:去除文本数据中的噪声(如乱码、无效字符 )、重复内容,规范文本格式。
- 数据监控:实时监测训练数据的质量、数量变化,以及数据使用情况,及时发现问题。
- 文本采集:从各种渠道(如网页、文件、数据库 )收集文本数据,为训练提供素材。
- 数据脱敏:对包含敏感信息的数据进行脱敏处理,保护数据隐私安全。
(二)NLP 大模型
涵盖多语言模型、开放域对话模型等。多语言模型能够处理多种自然语言,实现跨语言的信息理解和生成。语言理解与生成技术可对文本进行语义分析、情感判断,并生成自然流畅的文本回复。语音语义理解则将语音转换为文本并进行语义解析,实现语音交互功能。多模态对话模型结合文本、图像、语音等多种信息,实现更加智能和自然的人机交互。
信息抽取与检索技术从大量文本中提取关键信息,并实现高效的信息检索。文本语义与图结构分析用于理解文本中的语义关系,并将其转化为图结构进行进一步分析。代码生成和理解模型能够根据自然语言描述生成代码,以及对代码进行语义理解和分析。
大语言模型如chatglm2-6b、Qwen-7B-Chat、Qwen-72B-Chat、baichuan-13b-chat等,支持复杂的自然语言处理任务。
(三)CV 大模型
图像表征技术用于提取图像的特征表示,为后续的分析和处理提供基础。视频表征则对视频序列进行特征提取和建模,实现对视频内容的理解。图像生成技术可根据输入条件生成逼真的图像,如风格迁移、图像修复等。视频生成能够合成动态视频内容。
图像与物体检测技术用于识别图像中的物体,并确定其位置和类别。语义分割则将图像中的每个像素进行分类,实现对图像的精细理解。图像分类技术对图像进行整体类别判断。因果推断旨在从图像数据中推断因果关系,为视觉任务提供更深入的理解。
视觉大模型如FLUX、sd3.5-large、HunyuanDiT-v1.2等。
(四)多模态大模型
融合视觉、语言、语音等多种模态信息,实现更强大的智能处理能力。例如,视觉 - 语言模型能够理解图像和文本之间的关联,用于图像描述生成、视觉问答等任务。语音 - 视觉模型结合语音和图像信息,实现更丰富的交互体验,如视频会议中的实时翻译和手势识别。
多模型大模型如CosyVoice2-0.5B、ChatTTS、FishSpeech-1.5、SenseVoiceSmall、F5-TTS、HunyuanVideo、CogVideoX-2b。
(五)模型推理部署
TensorRT-LLM
- 基本信息:NVIDIA 推出的开源库,用于定义、优化和执行大型语言模型在生产环境的推理,是 NVIDIA NeMo 框架的一部分。
- 部署方式:作为 NVIDIA NeMo 框架的一部分,通常与 NeMo 中的其他组件配合使用。首先需将模型转换为 TensorRT-LLM 支持的格式,利用其提供的工具和 API 进行模型加载和配置。然后可将配置好的模型部署到支持 NVIDIA GPU 的服务器上,通过相应的服务接口进行推理请求的接收和处理。
- 特点:支持多种大语言模型,如 Llama1 和 2、Bloom、ChatGLM 等。具备动态批处理和分页注意力功能,可提高推理效率。支持多 GPU 多节点推理,适用于大规模分布式推理场景。采用 FP8 精度的 NVIDIA Hopper Transformer 引擎,能在保证模型性能的同时,降低计算成本和显存占用,且支持多种 NVIDIA GPU 架构及原生 Windows 支持。
vLLM
- 基本信息:开源的大模型推理加速框架,通过 PagedAttention 技术高效管理 attention 中缓存的张量2。
- 部署方式:安装 vLLM 库后,可直接在 Python 代码中导入并使用。将预训练的模型加载到 vLLM 的推理引擎中,通过调用推理引擎的相关方法进行文本生成等推理任务。也可将 vLLM 部署为服务,通过 HTTP 或 gRPC 接口接收外部请求,实现远程推理服务。
- 特点7:通过 PagedAttention 和动态批处理机制,实现了比 HuggingFace Transformers 更高的吞吐量,能有效管理内存,降低内存浪费,支持多种解码算法,可无缝集成各类模型,兼容多种硬件平台的 GPU 和 CPU,灵活易用。
(六)模型评测
客观评测
- 性能指标
- 准确率:在分类任务中,正确分类的样本数占总样本数的比例。例如在垃圾邮件分类中,判断正确的邮件数与邮件总数的比值。
- 精确率:针对正例而言,预测为正例且实际为正例的样本数,占所有预测为正例样本数的比例。如在癌症检测中,检测出患癌且实际患癌的人数,占所有检测出患癌人数的比例。
- 召回率:真实正例中被正确预测为正例的比例。在疾病诊断场景,即实际患病被检测出患病的比例,关乎能否及时发现病例。
- F1 值:精确率和召回率的调和平均数,综合反映模型分类性能,平衡两者表现。
- 均方误差(MSE):用于回归任务,衡量预测值与真实值差值平方的平均值,MSE 越小,模型预测值越接近真实值。
- 平均绝对误差(MAE):计算预测值与真实值差值绝对值的平均值,直观体现预测误差平均幅度。
- 效率指标
- 推理时间:模型对输入数据进行推理预测所需时间,反映模型响应速度,对实时性要求高的应用(如自动驾驶 )很关键。
- 吞吐量:单位时间内模型能够处理的样本数量,体现模型大规模处理数据的能力。
主观评测
- 可用性:评估模型在实际使用过程中的便捷程度,包括操作界面是否友好、功能是否易于理解和使用等。例如,一个图像编辑 AI 工具,用户能否轻松找到并使用各种编辑功能。
- 满意度:通过用户调查、反馈收集等方式,了解用户对模型输出结果的满意程度。如文本生成模型,用户对生成文本在内容、风格等方面是否符合期望的评价。
- 适用性:判断模型在特定应用场景下,能否满足业务需求。比如法律文书生成模型,在法律行业实际应用中,生成文书是否符合法律规范和业务流程。
评测数据集管理
- 数据收集:从多种来源采集数据,如公开数据集、业务系统日志、用户反馈数据等。例如图像识别模型评测数据,可来自公开图像库、企业产品拍摄图像等。
- 数据标注:对收集的数据进行标注,为模型评测提供准确的标签信息。像文本情感分析,需人工标注文本的情感类别(正面、负面、中性 )。
- 数据划分:将数据集划分为训练集、验证集和测试集。训练集用于模型训练,验证集用于调整模型超参数,测试集评估模型最终性能。
- 数据更新:随着时间推移和业务变化,及时更新评测数据集,纳入新数据类型、新场景数据,保证评测有效性。如电商推荐模型,要根据新上架商品、新用户行为数据更新评测集。
五、能力层
能力层基于模型层的基础,为平台提供了具体的应用能力。文字生成能力可用于自动写作、智能客服回复等场景,根据输入的提示或要求生成高质量的文本内容。音频生成能够合成语音、音乐等音频内容,应用于有声读物、虚拟主播等领域。
图像生成可用于艺术创作、产品设计等,快速生成各种风格的图像。视频生成技术则可用于影视制作、广告宣传等,自动生成动态视频画面。虚拟人 / 场景生成能够创建逼真的虚拟人物和场景,广泛应用于游戏、虚拟现实等领域。
代码生成能力可根据自然语言描述或需求自动生成代码,提高软件开发效率。策略生成能够根据给定的目标和条件,生成最优的决策策略,应用于智能规划、资源分配等场景。多模态生成则融合多种模态信息,生成更加丰富和多样化的内容。
六、模型服务层
模型服务层主要负责对大模型进行管理和提供服务。大模型内容管理涵盖模型的版本控制、存储和更新,确保模型的可用性和一致性。AI 搜索与问答通过对模型的调用和优化,实现智能搜索和准确的问答服务,快速响应用户的查询。
模型的服务应用一共可以分为3种模式,单纯的大模型问答、大模型+知识库问答、大模型+数据库问答。
Embedding(嵌入)技术将文本、图像等数据转换为低维向量表示,便于模型处理和计算。召回路由根据用户请求,从大量模型和数据中快速筛选出相关内容。任务编排负责对模型调用的流程进行规划和管理,确保各环节的高效运行。
RAG(检索增强生成)技术融合了检索与生成两种方法,旨在提升信息生成的精准度。它利用检索到的相关信息来增强生成模型的效能,确保所生成内容的准确性与相关性
大模型微调(Fine-tuning)技术通过对模型进行细致调整,使其更好地适应特定任务需求,在特定任务的数据集上进行微调后,模型在相关任务上的性能可以得到显著提升,实现更精准和高效的处理。
提示词工程(Prompt Engineering)专注于设计高效的提示语,以优化模型的输出结果。通过精心设计的提示词,可以引导模型生成更加符合预期的内容,从而提升生成文本的质量。
思维链(Chain-of-Thought)技术模拟人类的思考过程,以增强模型的决策和推理能力。通过逐步推理和决策,该技术使得模型能够更有效地处理复杂问题,并做出更加合理的判断
工具调用功能允许平台集成和调用外部工具,拓展模型的应用能力。性能调优则通过对模型参数和运行环境的优化,提升模型的推理速度和准确性。安全监控实时监测模型服务的运行状态,防范安全风险。
MCP 是 Model Context Protocol(模型上下文协议),是一种开放标准协议,旨在为大型语言模型与外部数据源、工具和服务,提供标准化的双向通信接口,核心特性包括支持单一协议连接多种工具和服务、AI 智能体可动态发现可用工具、基于双向通信机制实现实时交互、本地与远程兼容,以及内置标准化访问控制确保安全等。通过 MCP,能简化 AI 智能体与外部系统的集成,打破数据孤岛,提升开发效率,推动 AI 从 “对话” 向 “执行” 进化,助力 AI 在自动化工作流、跨系统数据整合等多场景的创新实践 。
七、应用层
应用层将大模型的能力应用于各个具体行业和领域。在政务领域,可实现政务问答、政策解读等功能,提高政务服务的效率和透明度。公文助手利用文字生成能力辅助公文撰写和审核。
金融行业借助智能客服、风险评估等应用,提升客户服务质量和风险防控能力。在零售电商领域,可实现智能推荐、商品描述生成等功能,促进销售增长。传媒影视行业利用图像生成、视频生成等技术,辅助内容创作和特效制作。
教育科研领域,通过智能辅导、科研助手等应用,提升教育质量和科研效率。在医疗行业,可用于疾病诊断辅助、医学影像分析等,为医疗决策提供支持。工业领域可实现智能质检、设备故障预测等,提高生产效率和质量。能源领域则可用于能源消耗预测、智能电网管理等。
八、应用服务层
服务层为不同终端用户提供访问大模型平台的接口。PC 端、手机端、大屏端和泛 AIoT 端(人工智能物联网终端)等多种终端支持,确保用户可以在不同设备上便捷地使用平台服务。针对不同终端的特点和需求,进行界面优化和功能适配,提供一致且优质的用户体验。
九、运维保障体系
运维保障体系贯穿整个大模型平台架构,负责平台的日常运行维护、性能监控、故障排除和优化升级。通过实时监控系统资源使用情况、模型运行状态等指标,及时发现潜在问题并采取相应措施。
定期对平台进行性能优化,包括硬件升级、软件更新、模型调优等,以确保平台始终保持高效稳定的运行状态。同时,制定完善的备份和恢复策略,防止数据丢失,并在系统出现故障时能够快速恢复服务。
- 故障处理:及时发现系统运行过程中的故障(如硬件故障、软件错误 ),并进行诊断和修复,恢复系统正常运行。
- 监控告警:实时监控平台的各项指标(如 CPU 使用率、内存占用、网络流量 ),当指标超出阈值时及时发出告警通知。
- 资源配额:为不同租户或应用分配合理的资源使用额度(如计算资源、存储资源 ),并进行动态调整。
- 升级扩容:对平台软件进行版本升级,以及根据业务需求扩展硬件资源(如增加服务器、存储设备 ),提升平台性能和容量。
十、用户租户管理体系
涵盖租户账户管理,实现资源隔离,确保不同租户资源独立;计量计费用于统计资源使用并计费;权限控制保障数据和功能访问安全;通知报告用于信息传递;审计合规确保平台运营符合规定。
- 租户账户:用于管理不同租户的账号信息,包括创建、修改、删除账号,以及账号权限配置等。
- 资源隔离:确保不同租户的资源(如计算资源、存储资源 )相互独立,互不干扰,保障数据安全和服务质量。
- 计量计费:统计租户对平台资源(如计算时长、存储容量 )的使用情况,并根据计费规则进行费用计算与结算。
- 权限控制:根据租户角色和业务需求,精细控制租户对平台功能、数据的访问权限。
- 通知报告:向租户发送系统通知(如维护通知、账单通知 ),并提供资源使用报告、服务状态报告等。
- 审计合规:对租户操作行为进行审计,确保平台运营符合法律法规、行业规范以及内部管理要求。


















 1590
1590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









