







Semi-Dense 3D Semantic Mapping from Monocular SLAM
本文要点是将2D语义分割结果通过概率模型,推导到3D地图中,重建了具有语义信息的3D地图
摘要
计算机视觉中的几何和外观组合已被证明是机器人在各种应用中的一个有前途的解决方案。立体摄像机和rgbd传感器广泛应用于实现快速三维重建和密集的轨迹跟踪。然而,它们缺乏在不同缩放环境(即室内和室外场景)之间无缝切换的灵活性。此外,在三维映射中,语义信息仍然很难获取。我们通过结合最先进的深度学习方法和基于单目摄像机视频流的半密集同步定位与映射(slam)来应对这一挑战。 该方法通过具有空间一致性的连接关键帧之间的对应关系,将二维语义信息转化为三维映射。无需对序列中的每一帧进行语义分割,从而达到合理的计算时间。我们在室内/室外数据集上对我们的方法进行了评估,并在基线单帧预测的基础上改进了二维语义标记。
贡献
我们的方法是使用最新的深度cnn组件来预测语义信息,这些语义信息将从实时单目slam系统投影到全局一致的3d地图上。三维地图是由一系列选定的帧以计算出的深度信息作为跟踪参考逐步构建的。这允许二维CNN的语义标签附加到关键帧,关键帧可以以半密集的方式融合到三维地图中,如图1所示。无需对每一帧进行序列分割,节省了大量的计算量。由于三维地图应具有全局一致的深度信息,因此将根据其几何结构对其进行正则化。2d-3d转换后的正则化过程旨在去除显著的异常点,使3d地图中的成分更加一致,即具有语义标签的局部点应该在空间上接近。我们选择nyuv2和camvid/kitti数据集来评估我们的方法,并且我们见证了2d语义分割的改进。利用未标记的原始视频,实时(≈10hz)重建具有语义预测的3d地图。
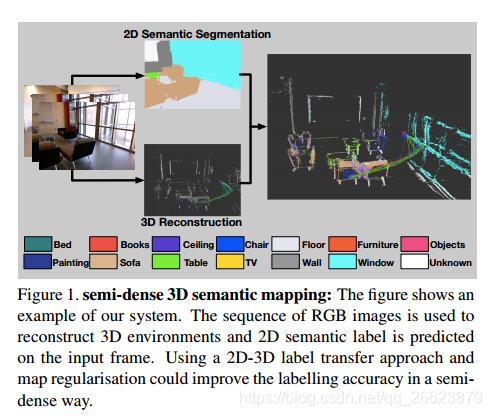
方法
三维重建过程从单目相机拍摄的图像帧序列中选择关键帧。所选关键帧将堆叠起来,以基于其姿势图重建三维贴图。整个过程在cpu内实时运行。同时,二维语义分割过程预测了关键帧的像素级分类。关键帧的深度信息由其连续帧迭代地细化。它为每个关键帧创建局部最优深度估计,并在三维点云中创建标记像素和体素之间的对应关系。为了获得全局最优的三维语义分割,我们利用相邻三维点的信息,包括距离、颜色相似度和语义标签。该过程实现了三维点状态的更新,生成了全局一致的三维地图。以下部分将更详细地描述每个过程。
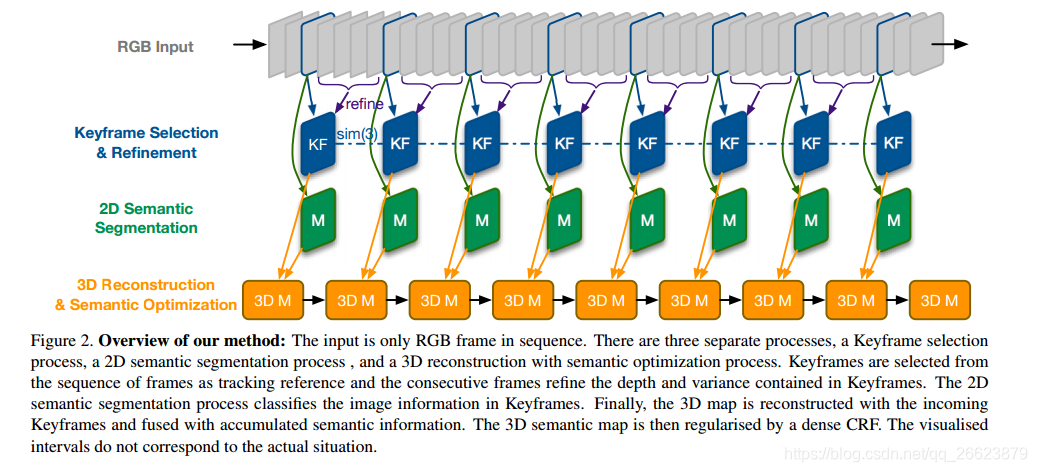
2D到3D的概率模型

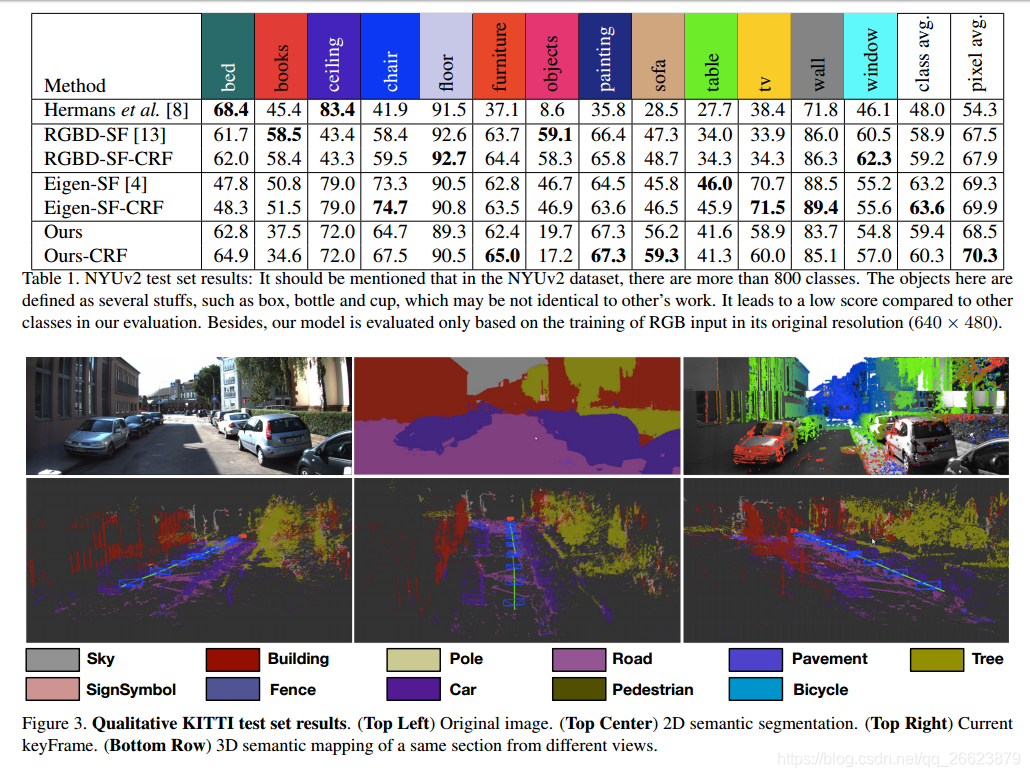
实验

















 1308
1308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









