




 UE5提供了多种内存分析工具,如memreport-full命令生成内存报告,详细显示物理内存和虚拟内存使用情况,以及UObject对象、纹理、静态网格、粒子系统等的内存占用。此外,UnrealInsights是一个独立的内存分析程序,支持实时监控和内存轨迹分析,帮助定位内存泄漏和过度使用问题。然而,它可能缺乏特定对象和地图路径的详细信息。
UE5提供了多种内存分析工具,如memreport-full命令生成内存报告,详细显示物理内存和虚拟内存使用情况,以及UObject对象、纹理、静态网格、粒子系统等的内存占用。此外,UnrealInsights是一个独立的内存分析程序,支持实时监控和内存轨迹分析,帮助定位内存泄漏和过度使用问题。然而,它可能缺乏特定对象和地图路径的详细信息。
UE5 提供了多种Profile内存(Memory)的手段。
memreport -full
在cmd命令行输入 memreport -full
内存报告文件会输出到Saved\Profiling\MemReports\XXX.memreport
用文本文件打开XXX.memreport
物理内存和虚拟内存相关信息
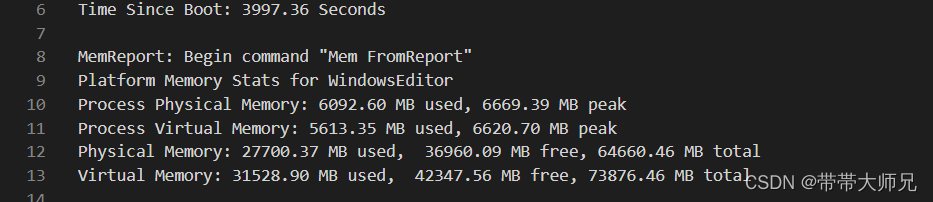
| Process Physical Memory | Process Virtual Memory | Physical Memory | Virtual Memory |
| 进程物理内存 | 进程虚拟内存 | 物理内存 | 虚拟内存 |
标记使用内存
UE Allocator对分配的内存打特殊标记, 比如TEXTUREGROUP_Lightmap,TEXTUREGROUP_UI等等。
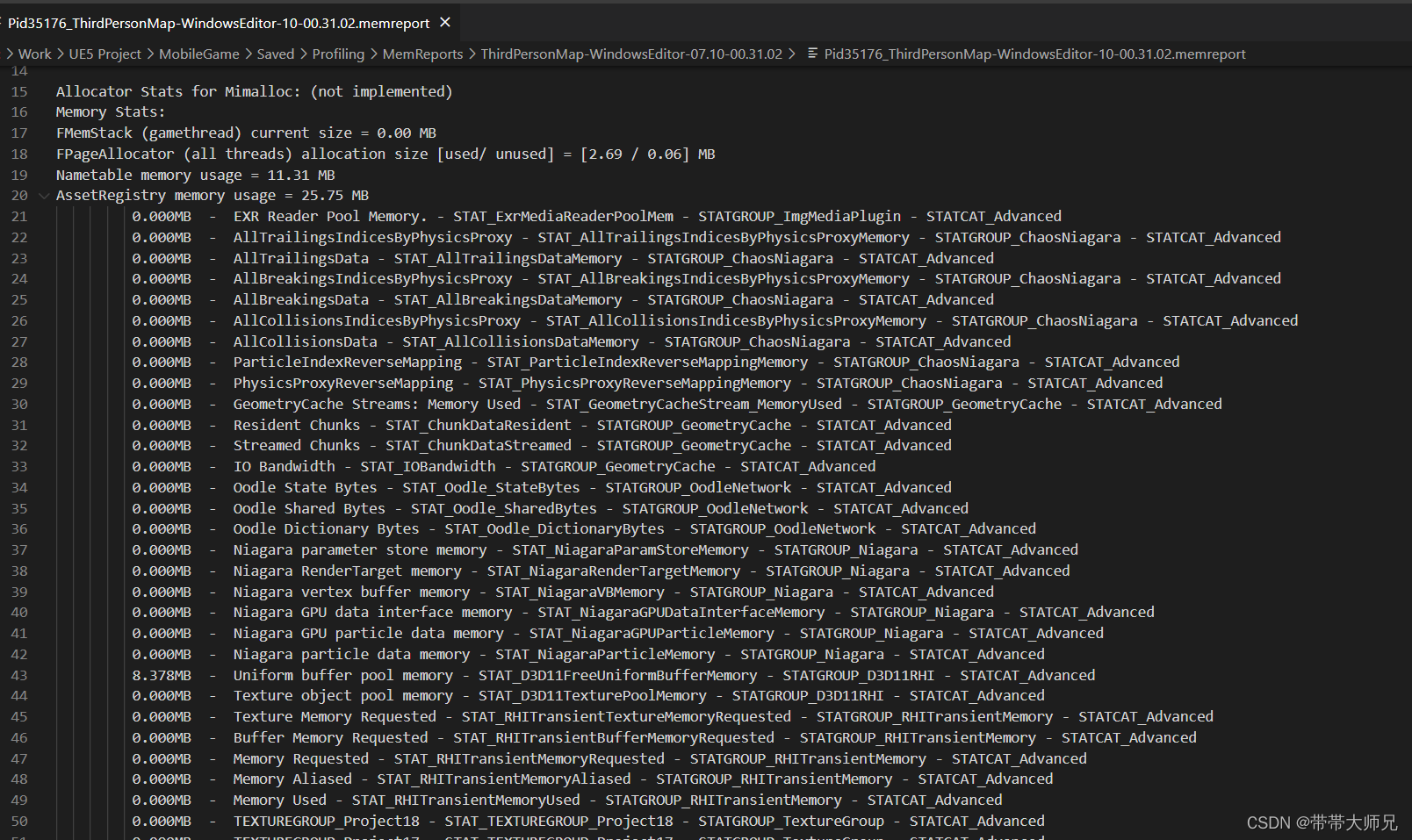
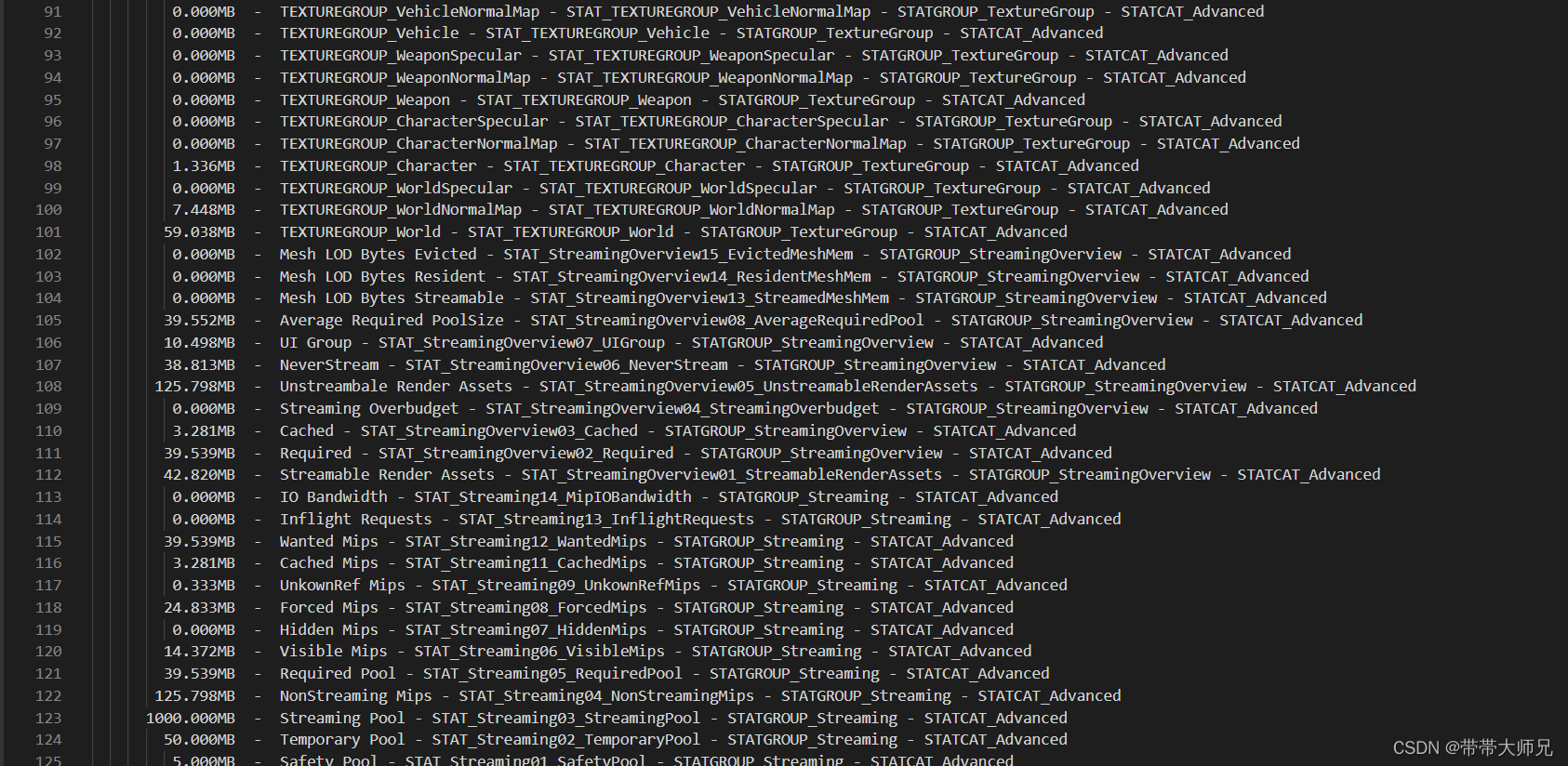
UObject对象数量和内存统计

最后一行算了Objects的总内存
| Class | Count | NumKB | MaxKB | ResExcKB | ResExcDedSysKB | ResExcShrSysKB | ResExcUnkKB |
| UObject的类别 | 数量 | 使用 内存 | 最大使用内存 | 其他ResExc的总和 | 专用系统内存中分配的字节数 | 共享系统内存中分配的字节数 | 在位置内存中分配的字节数 |
| ResExcDedVid | ResExcShrVidKB |
| 专用视频内存(VRAM)中分配的字节数 | 共享视频内存(VRAM)中分配的字节数 |
RHI内存
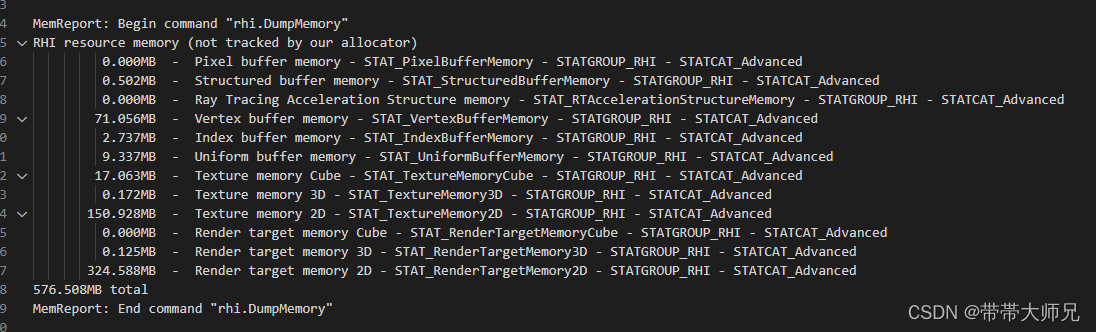
RHI资源内存(比RHI内存更具体)
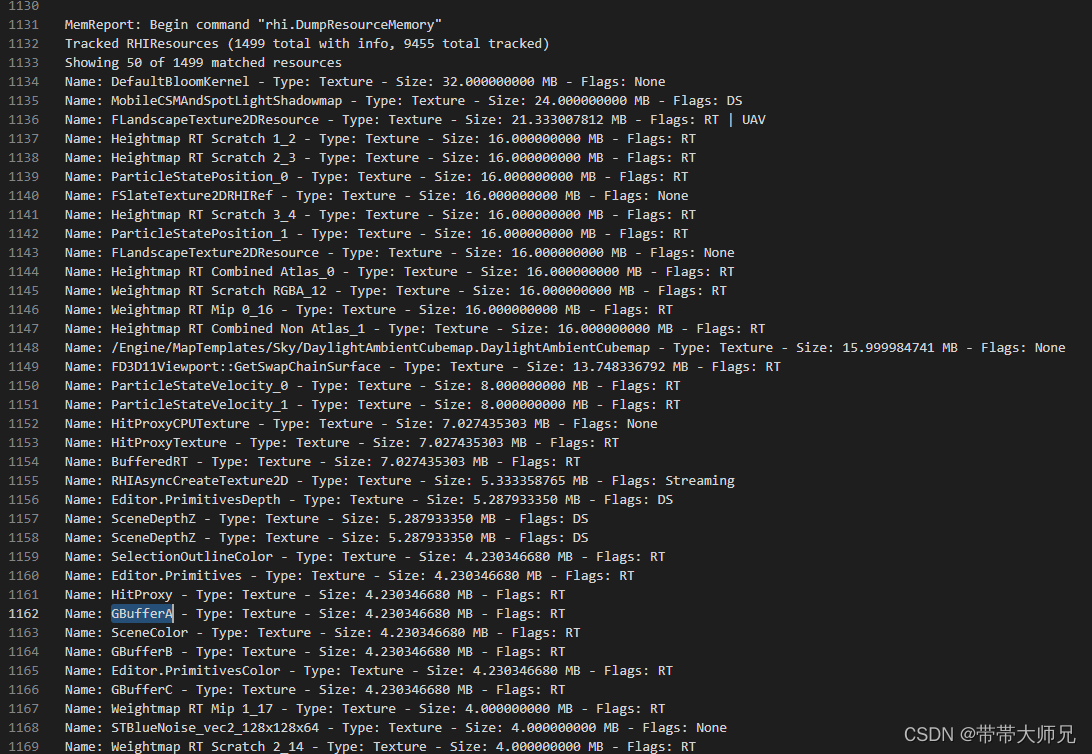
SkeletalMesh的资源 Object对象数量和内存统计

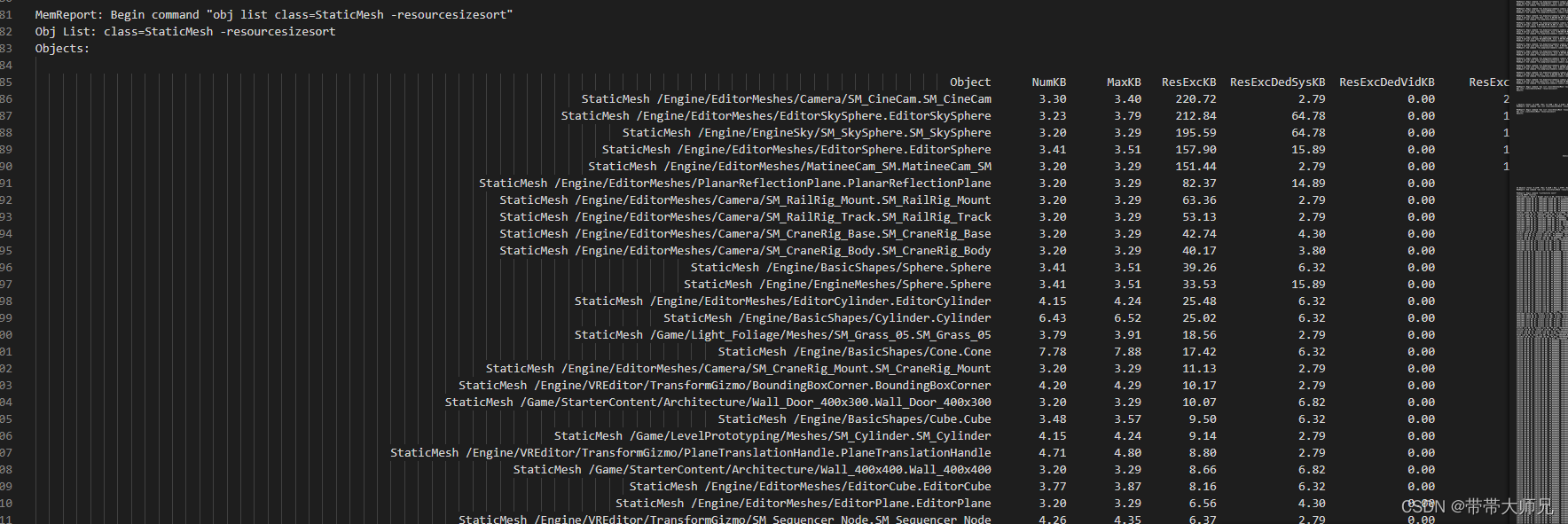
StaticMesh的资源 Object对象数量和内存统计
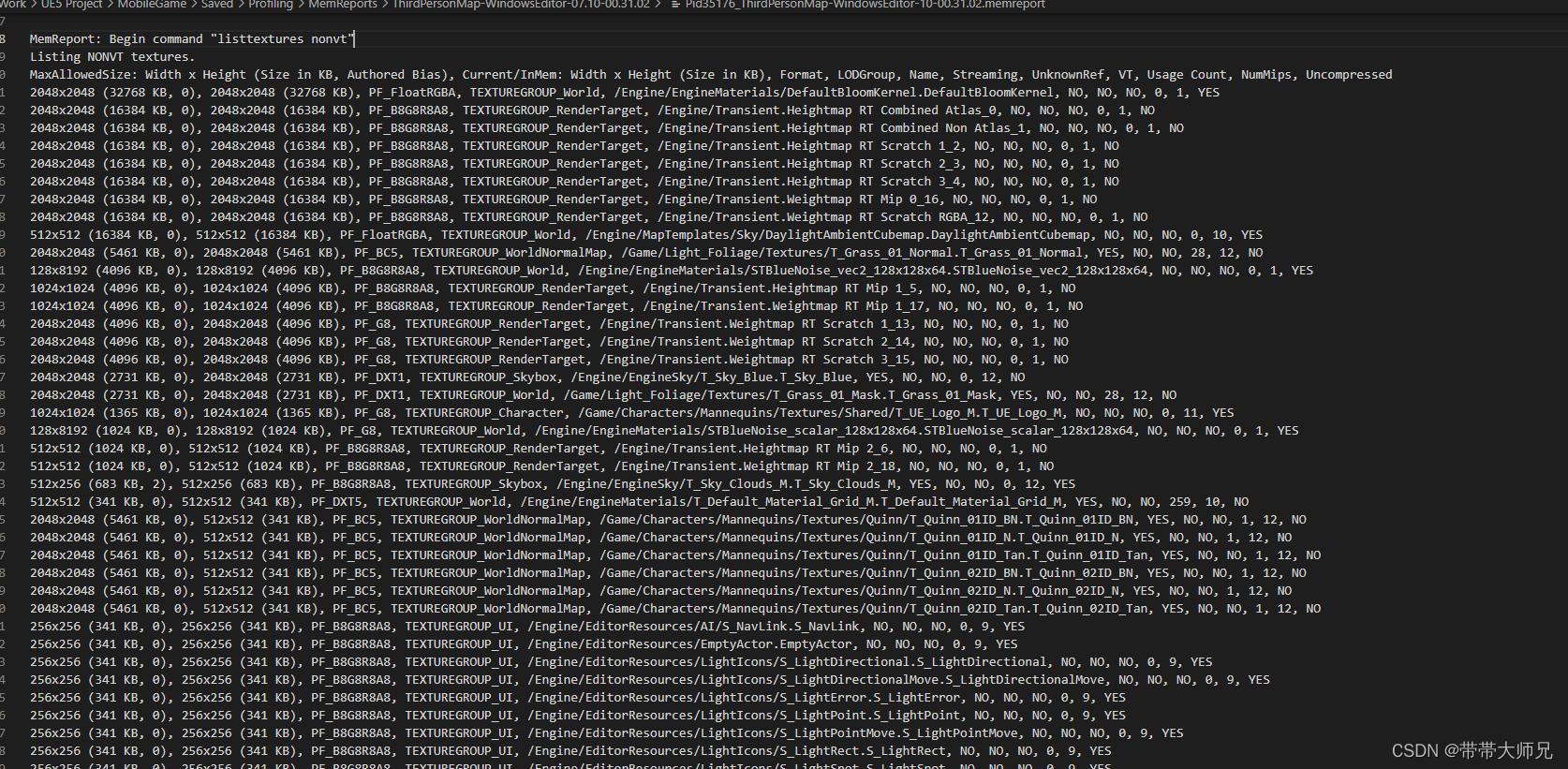
具体纹理对象内存占用(非VirtualTexture)
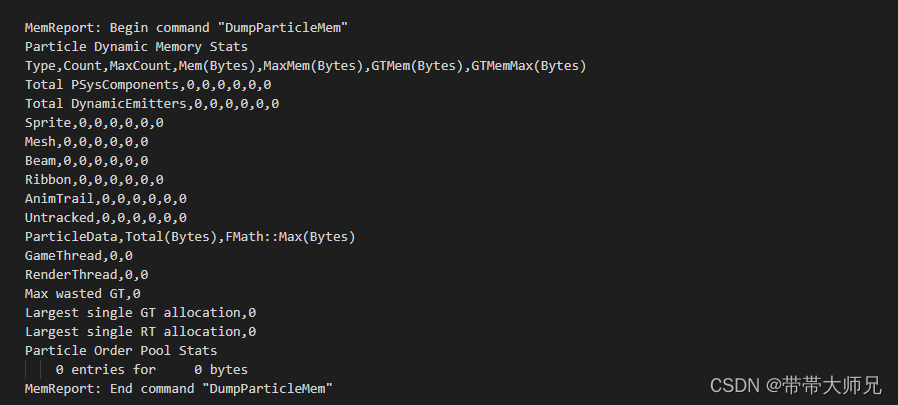
粒子系统占用内存
.ini配置文件占用内存
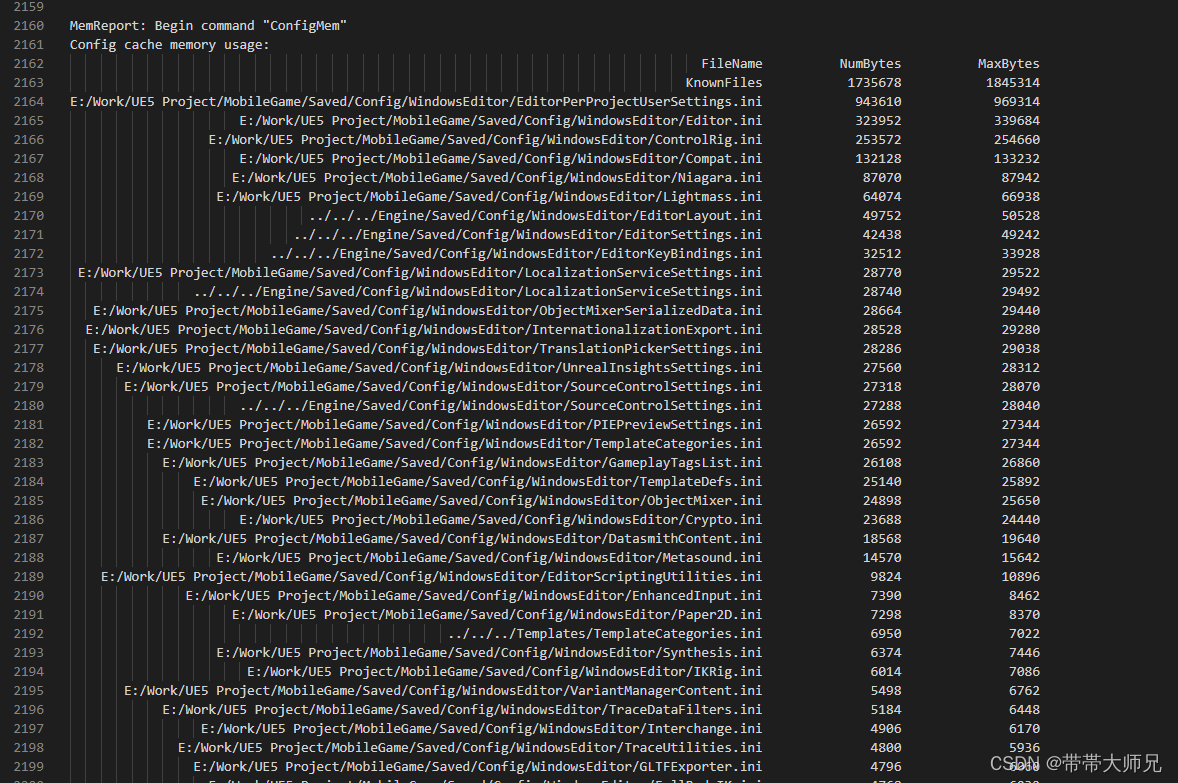
RT池占用内存
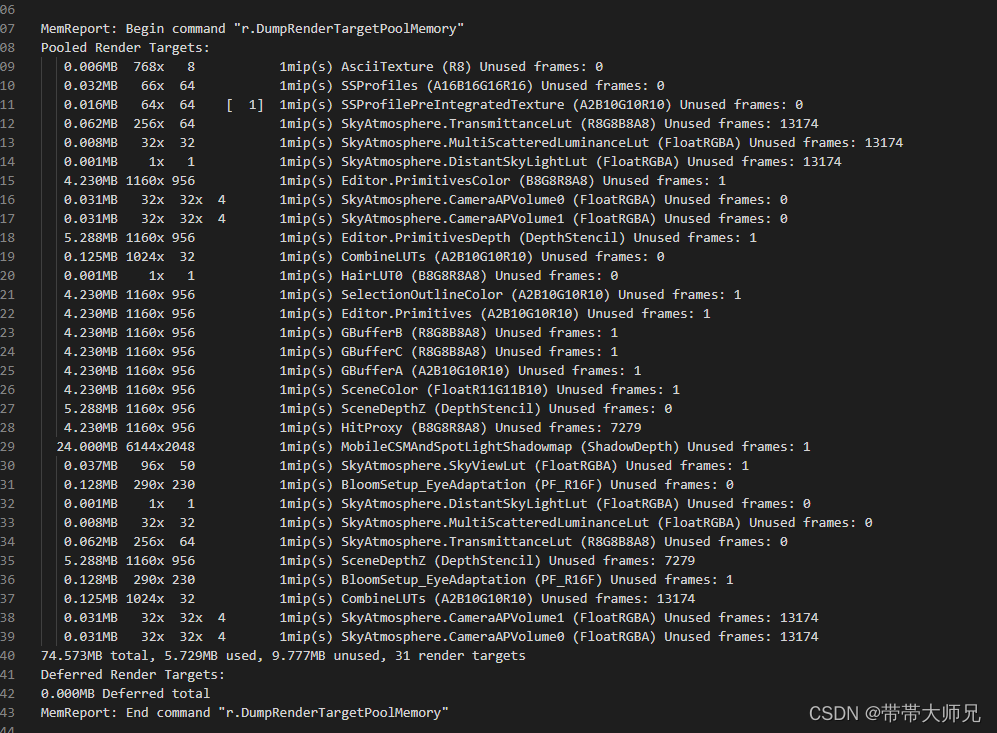
具体纹理对象内存占用
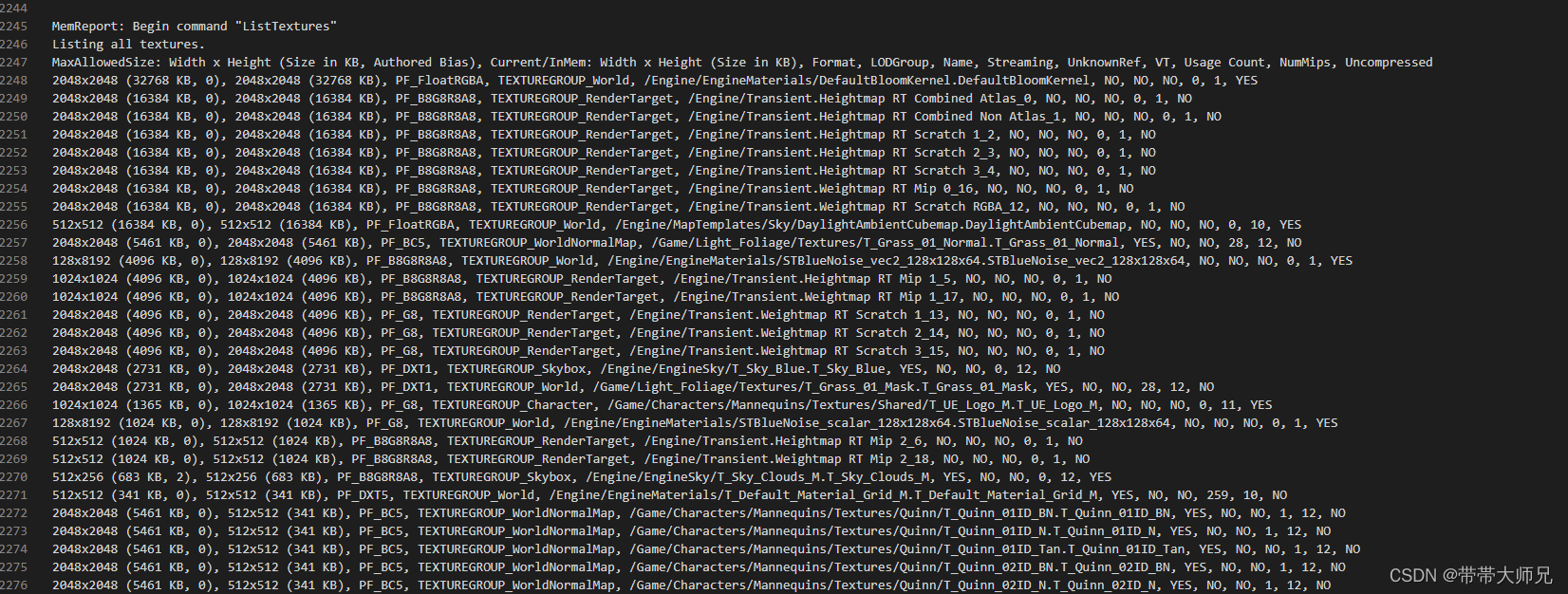
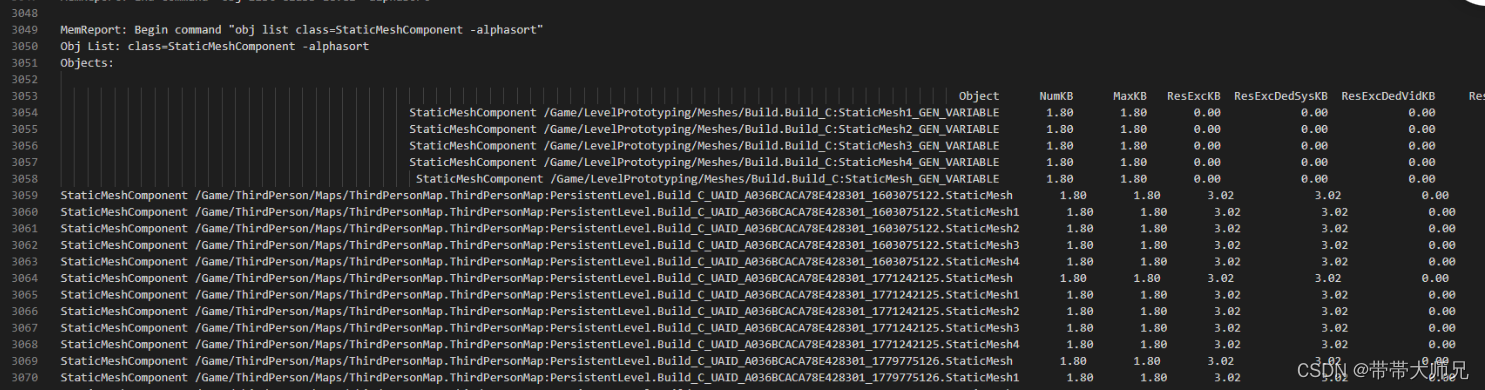
StaticMeshCompoent占据内存Object对象统计
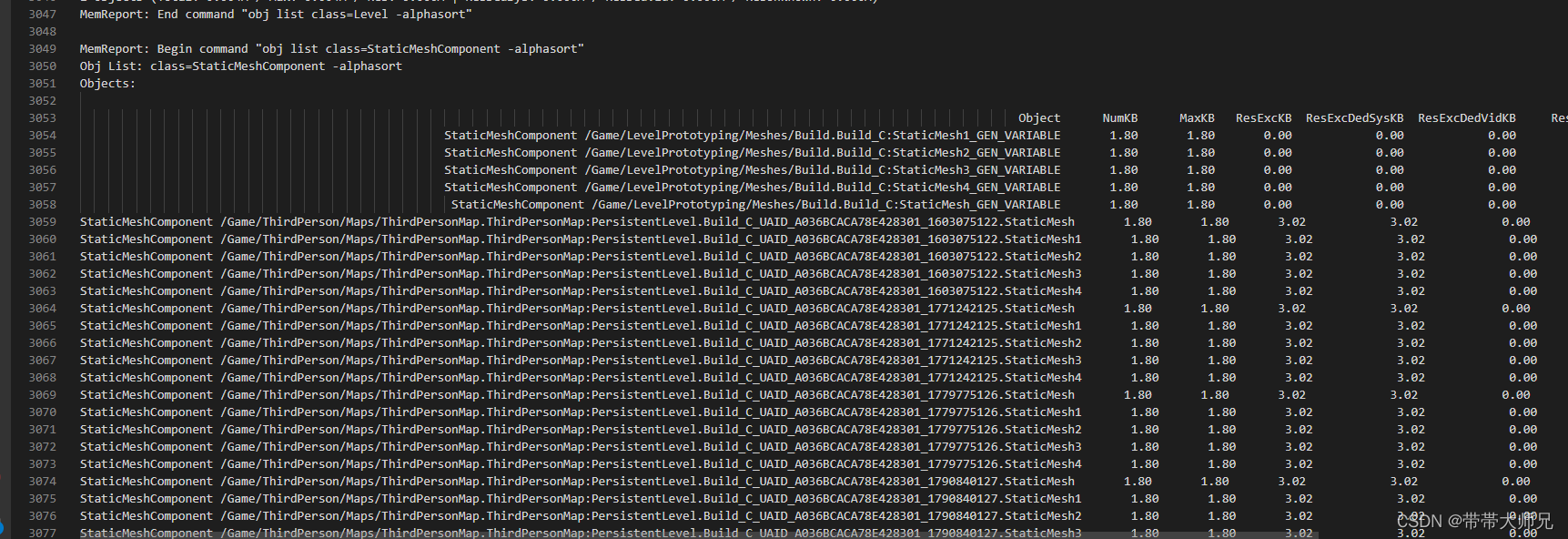
Unreal Insights--Memory Insights
文档在: 虚幻引擎中的Memory Insights | 虚幻引擎5.2文档 (unrealengine.com)
打开Unreal Insights
UnrealInsights.exe是一个独立Profile程序, 在 Engine\Binaries\Win64
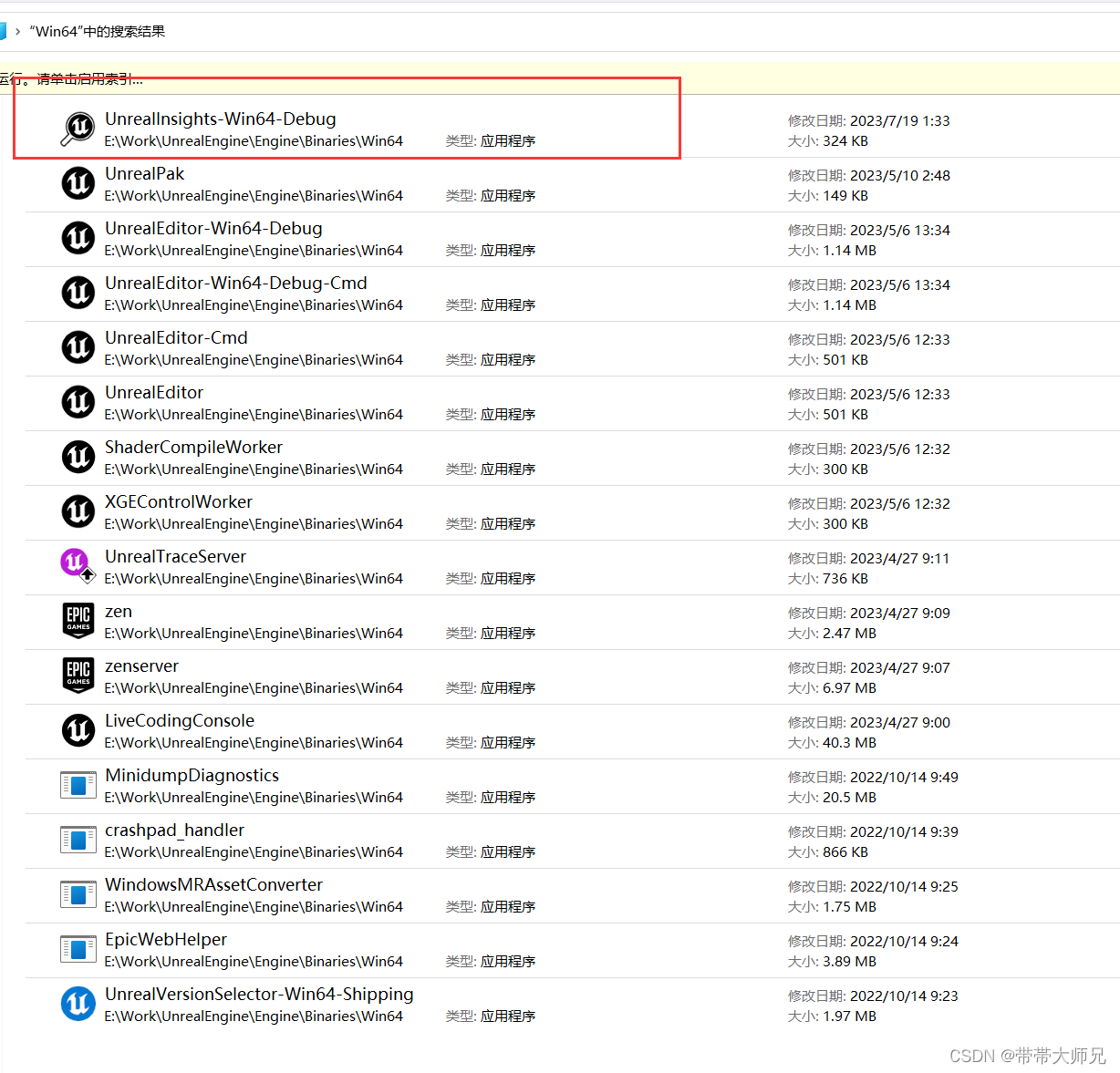
如果该目录不存在UnrealInsights.exe执行程序, 得在工程中构建
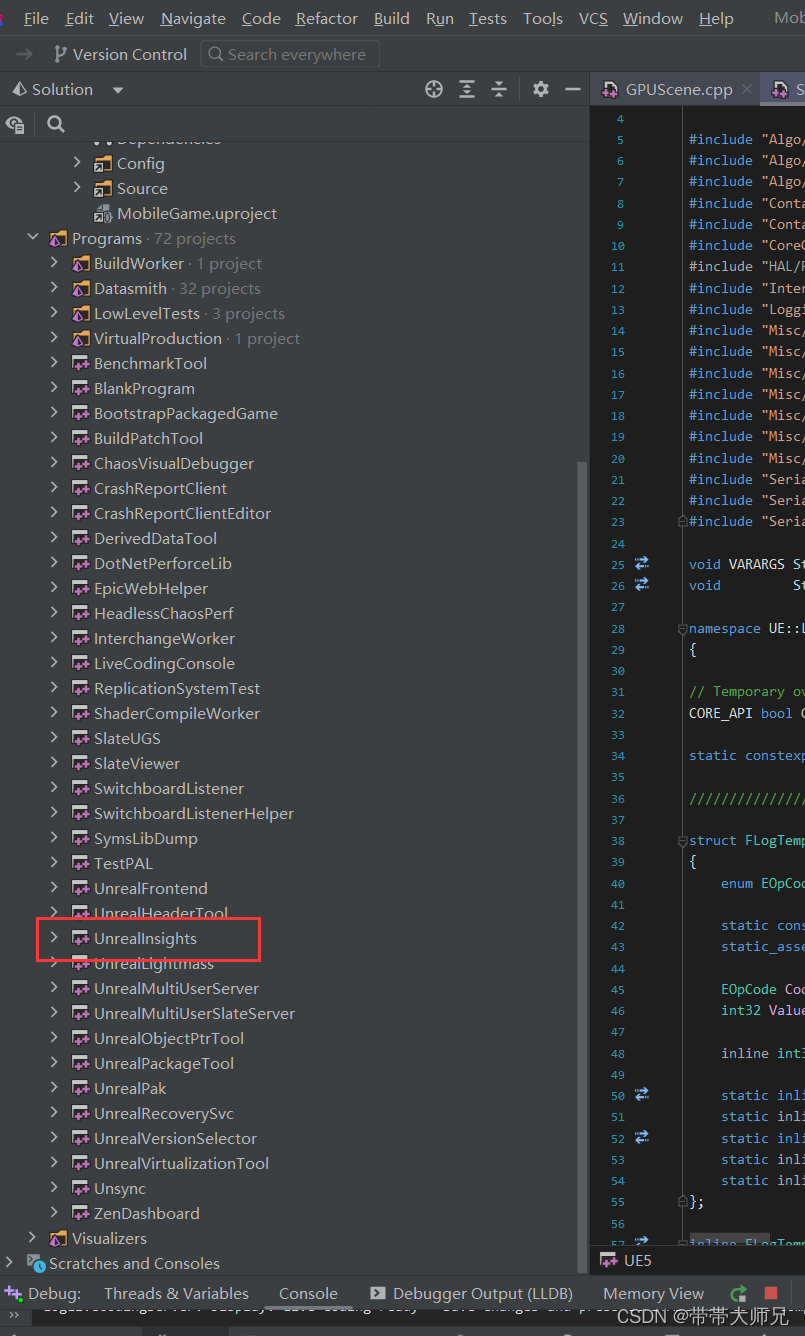
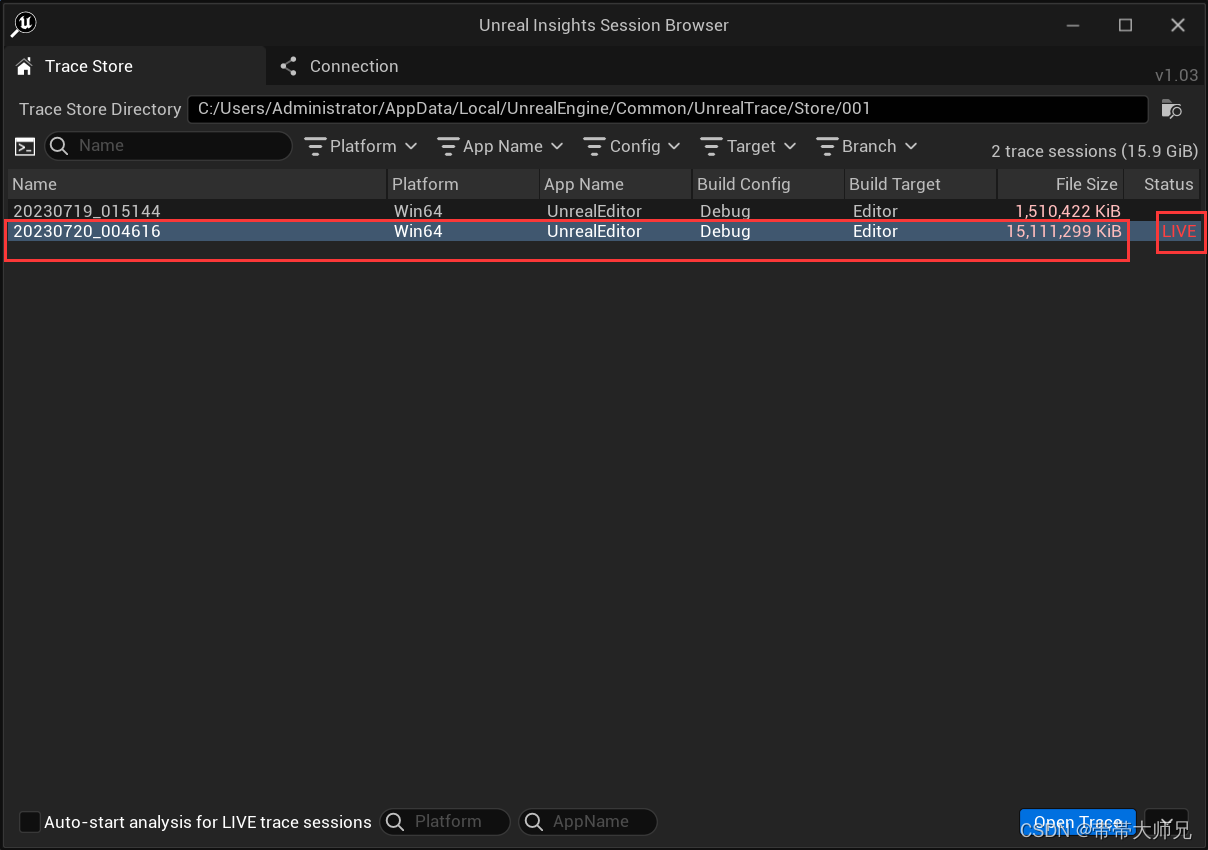
打开显示: Live代表正在运行的进程
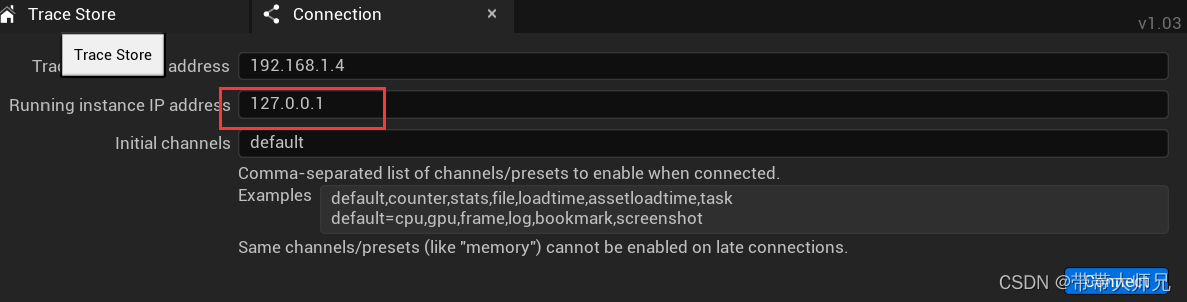
加执行命令参数启动Editor或者项目
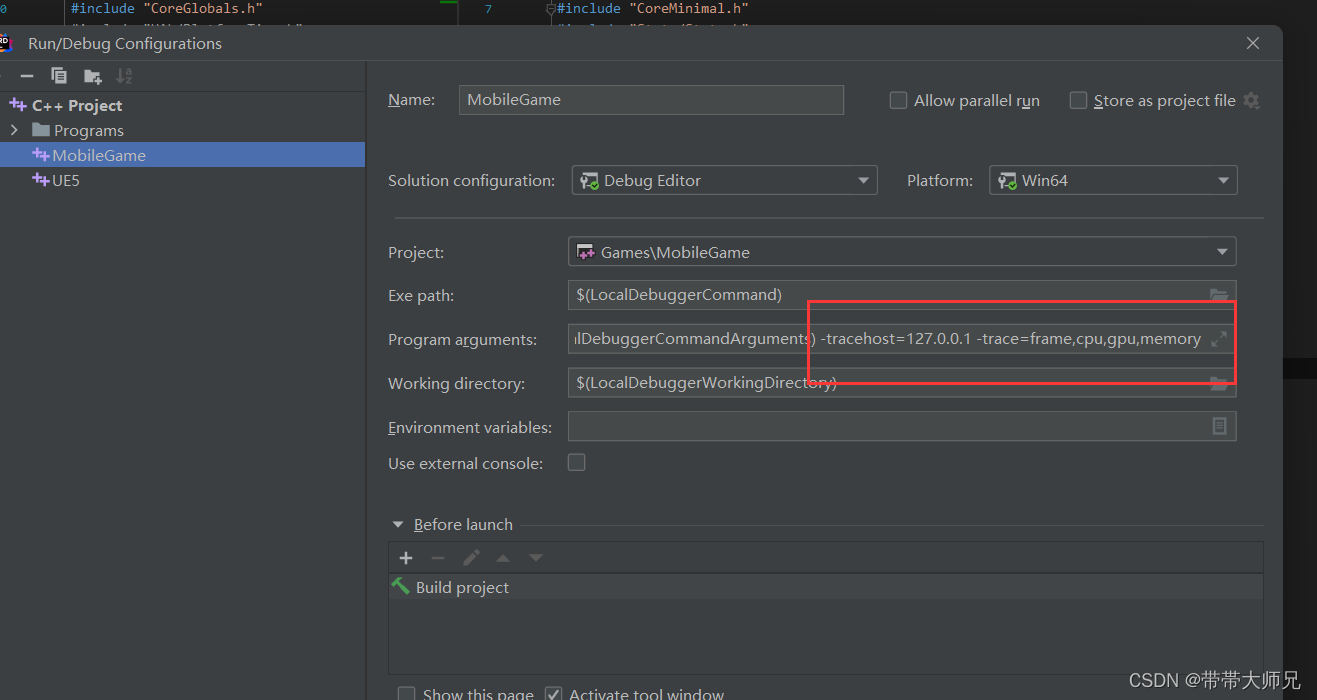
Trace分析
点击上面UnrealInsight的OpenTrace,打开捕捉信息
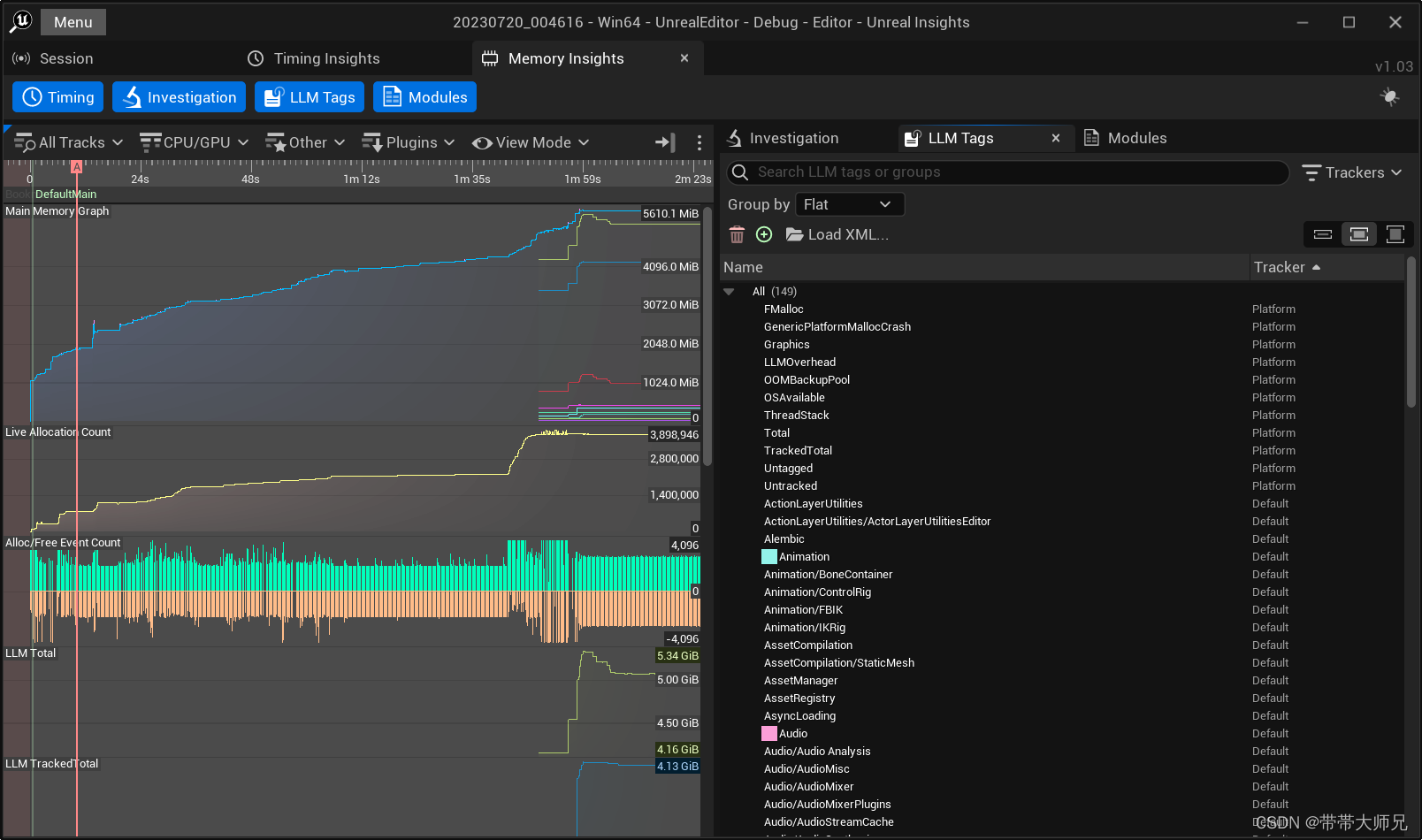
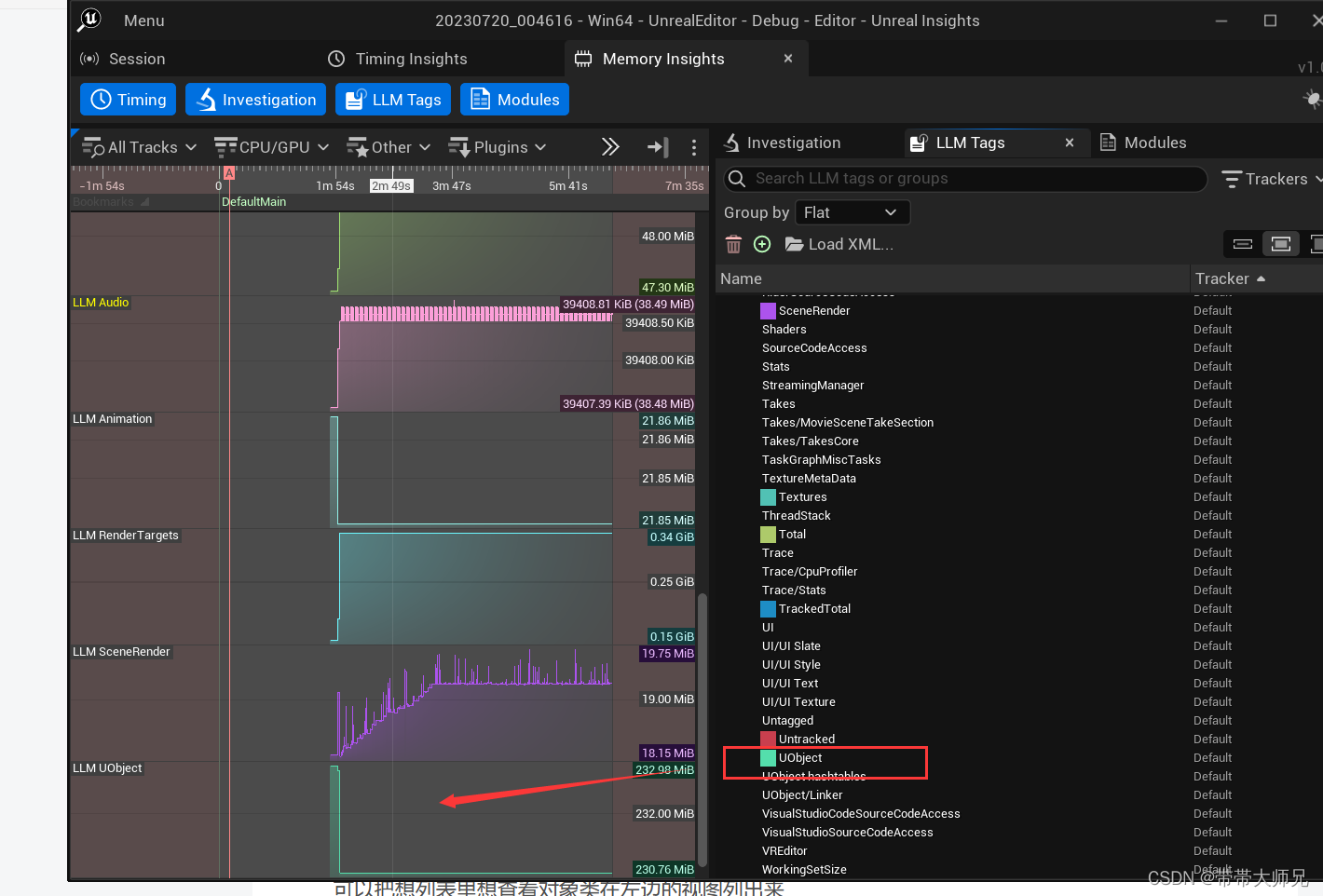
LLM Tags
可以把想列表里想查看内存的对象类在左边的视图列出来
Investigation
内存调查系统, 可以使用规则(大于某个时间点,小于某个时间点,在某两个时间点之间)来显示一段时间内分配而一直未释放的内存, 下面是查看从10秒 ~ 20s的内存变化(10s开始分配并且到20s的时候还未释放的内存统计
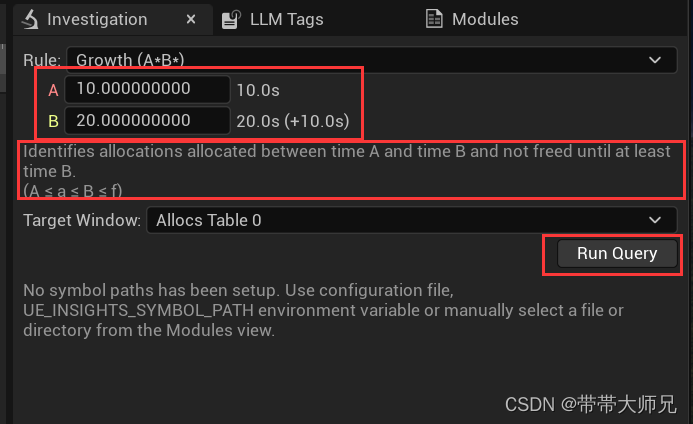
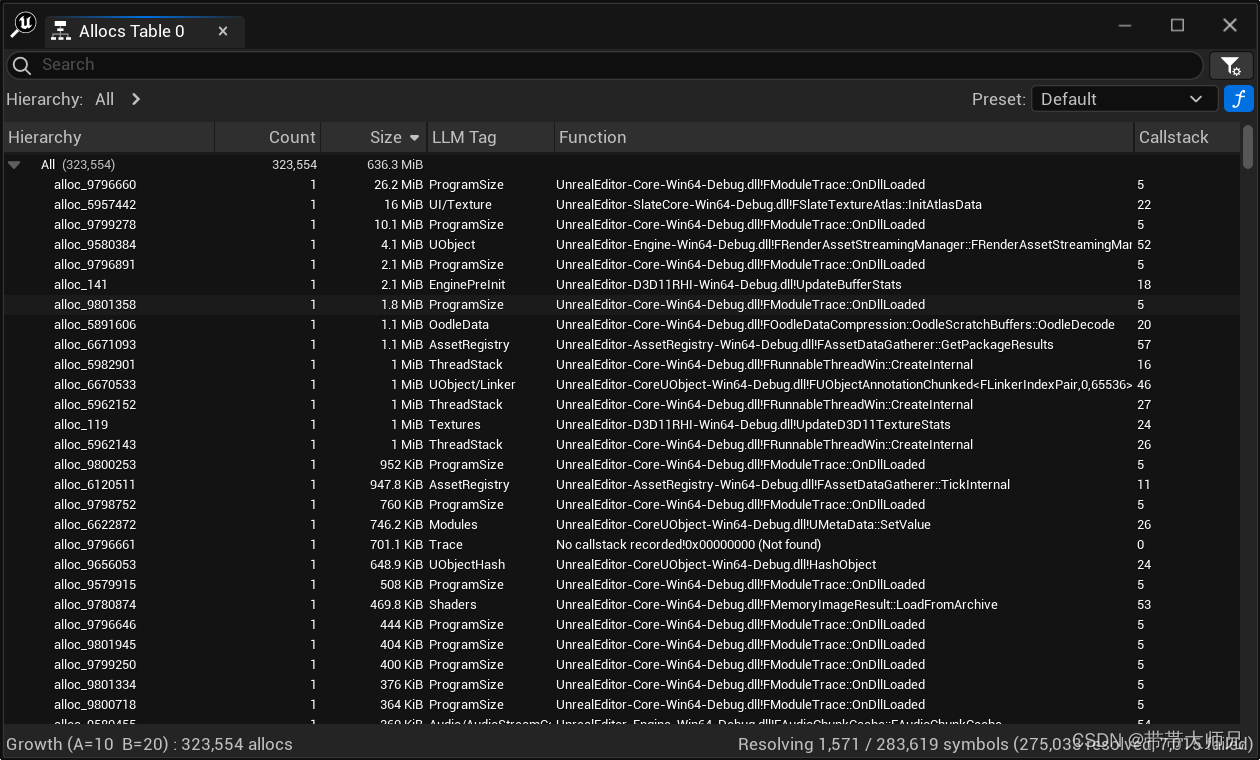
这里点击Hierarchy每个alloc名字左边可以查看分配程序栈,内存大小,源文件等等:
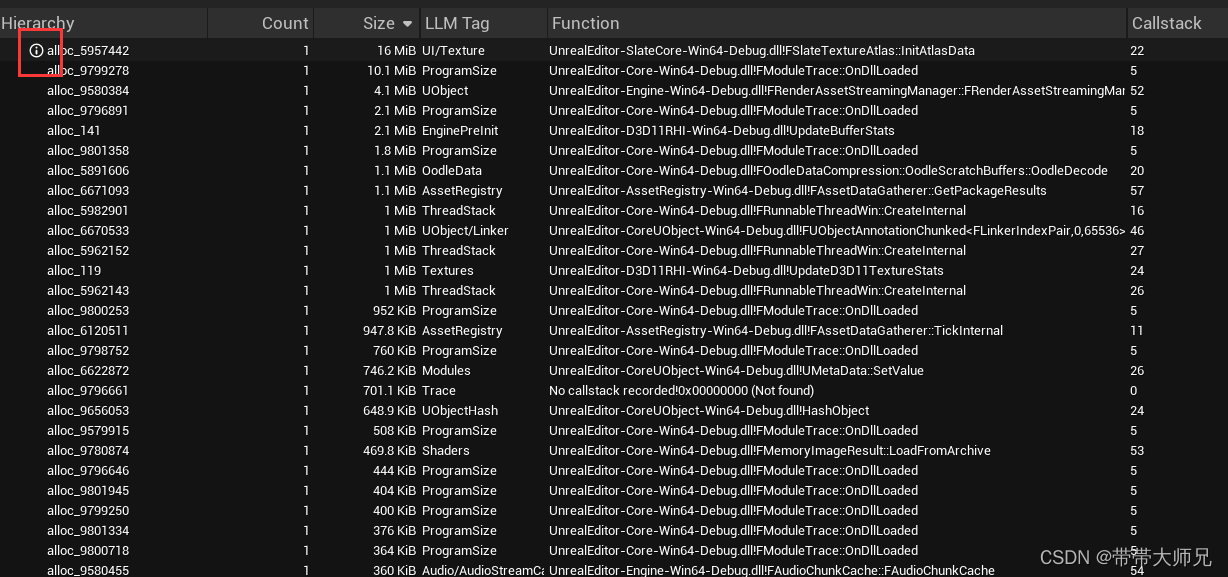
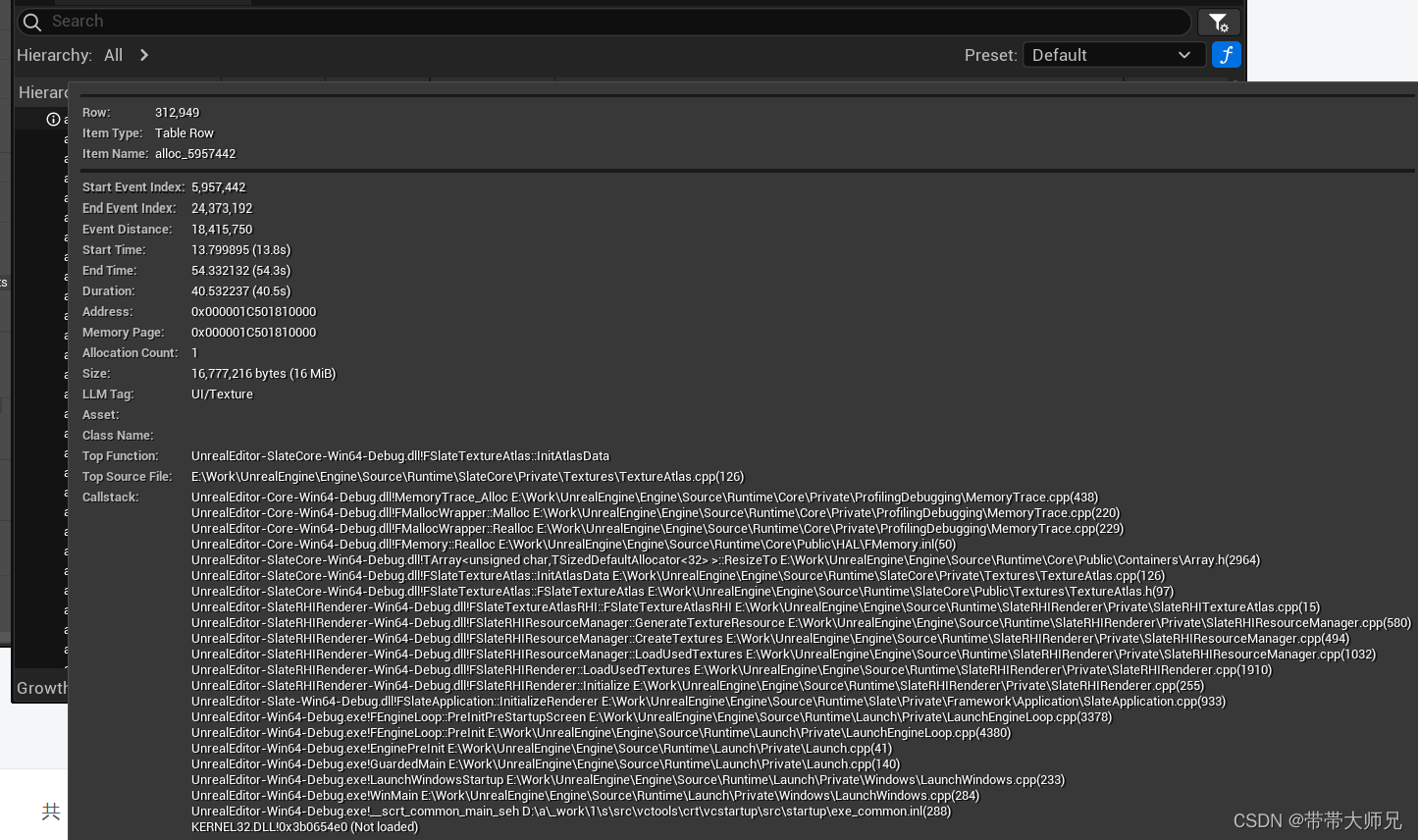
看了下感觉没中不足的是,缺乏信息,像Memort -full指令能指出一个object对象的具体名字和地图路径。

















 716
716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









