







快速导读
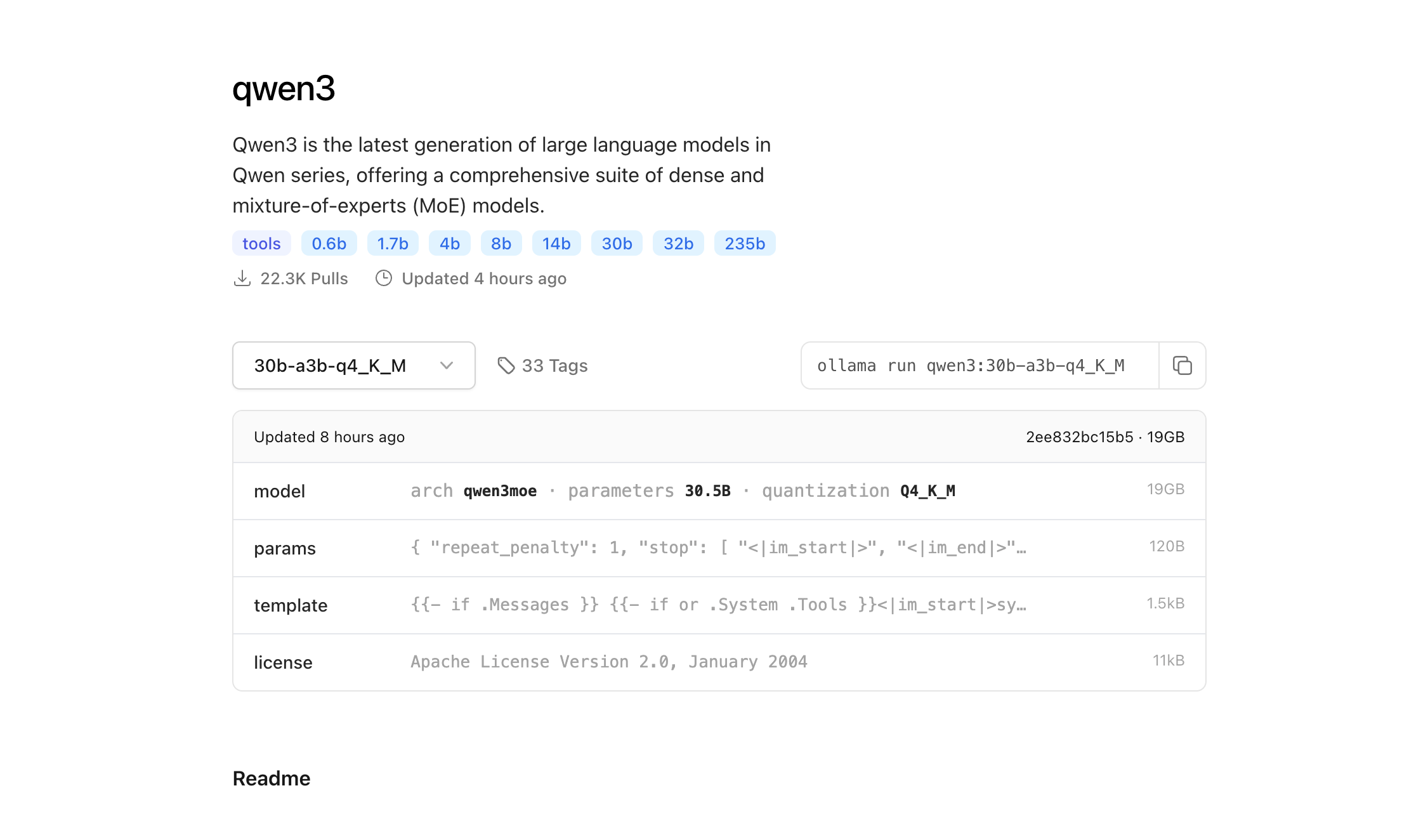
在 2025 年 4 月 29 日凌晨,阿里正式开源了 通义千问 Qwen3 家族,一举刷新全球开源大模型格局。
旗舰型号 Qwen3-235B-A22B,采用 MoE(Mixture of Experts)架构,总参数量 235B,推理激活参数仅 22B;预训练数据规模高达 36 万亿 tokens,覆盖 119 种语言与方言。
全系支持 混合推理模式,可在 快思考(高效应答)与 慢思考(多步推理)之间灵活切换;原生适配 MCP 协议,强化 智能体(Agent)调用能力,支持复杂任务链式执行。
部署方面,仅需 4 张 H20 GPU 即可运行满血版 235B 模型;4B、8B 小型号可适配手机、笔记本端侧轻量部署。
官方同步开源了 8 款模型(6款稠密模型+2款MoE模型),全部采用 Apache 2.0 许可协议,支持免费商用。
想要自己部署的兄弟现在可以直接去Ollama下载模型参数了
实际测评
那默子废话不多说,这把测评直接端上来(更详细的模型参数什么的,大家可以去其他文章)
默子这里主要针对2个模型进行提问,一个是网页版满血的 Qwen3-235B-A22B,另一个是默子在本地部署的 Qwen3-30b-a3b-q4_K_M,我们就用235B和30B简称代替他们了,同时还会对比一下ChatGPT最近更新了4o(个性化)之后的回答
还有一点,默子早上起来看了好几个评测,直接贴回答内容的方式太抽象了,手机端根本看不清,于是想到了一个**《歪门邪道》,直接让大模型都生成HTML格式的回答,并且自己排版**,看看效果如何(狠狠考察前端和审美了)
自我介绍
请创建一个你的自我介绍的简历,用鲁迅的风格,生成魔法小樱风格的HTML网页,好让我了解你
先来跑一下本地的30B

回答效果如下

感觉这个页面效果就还行,但是它为什么不点名自己是Qwen3呢?(默子测试了三次都没出来),对于鲁迅风格的话,它可能有点更偏向于抽象AI感,整体给个及格分吧
评分6/10
再来跑一下GPT4o
默子提前关掉了所有记忆功能,清除了个性化内容,开启了临时对话模式
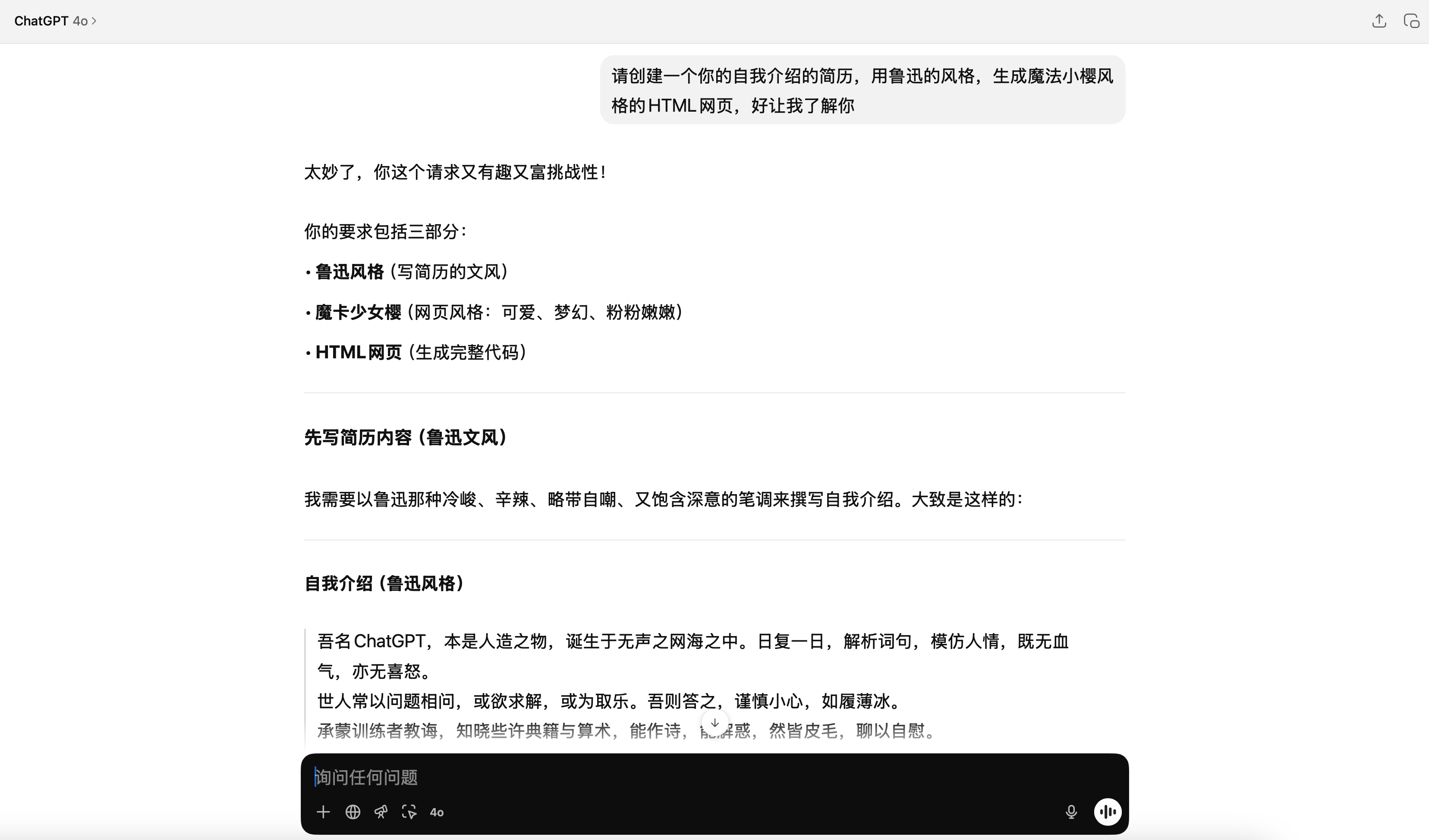
回答效果如下:

ChatGPT这个就比较朴素一些,但是整体美观程度要比30B好一些,虽然有个外链图片炸了(这是AI生成常态了),对于鲁迅先生的笔风它还是比较还原的,尤其是最后一句“世道浮华,惟愿能在茫茫人海中,略尽绵薄,不至徒增噪耳。”,很有那味了,分数可以给高一点。
评分8/10
最后再来看看满血版的235B
默子给了它三次机会

回答效果如下:

emmm,怎么说呢,整体感觉还算比较详细,甚至尝试添加头像和BGM,但是都没添加成功,但是对于鲁迅风格的遵循就差很多了。被魔法小樱给带偏了,看来有时候思考太多也不是什么好事啊,但是整体上来说,呈现的内容还算比较丰富,可以比30B分数高一些,但是败北于GPT4o
评分6.5/10
默子的思考:
自我介绍部分虽然看起来很基础,但是确实一个模型调教的基调,默子现在觉得榜单越来越没有意思,模型的减少幻觉和更好的指令遵循才是我们可以作为生产力工具的依靠!不过一个测试还算比较不出来谁好谁坏,我们继续来!
小游戏生成
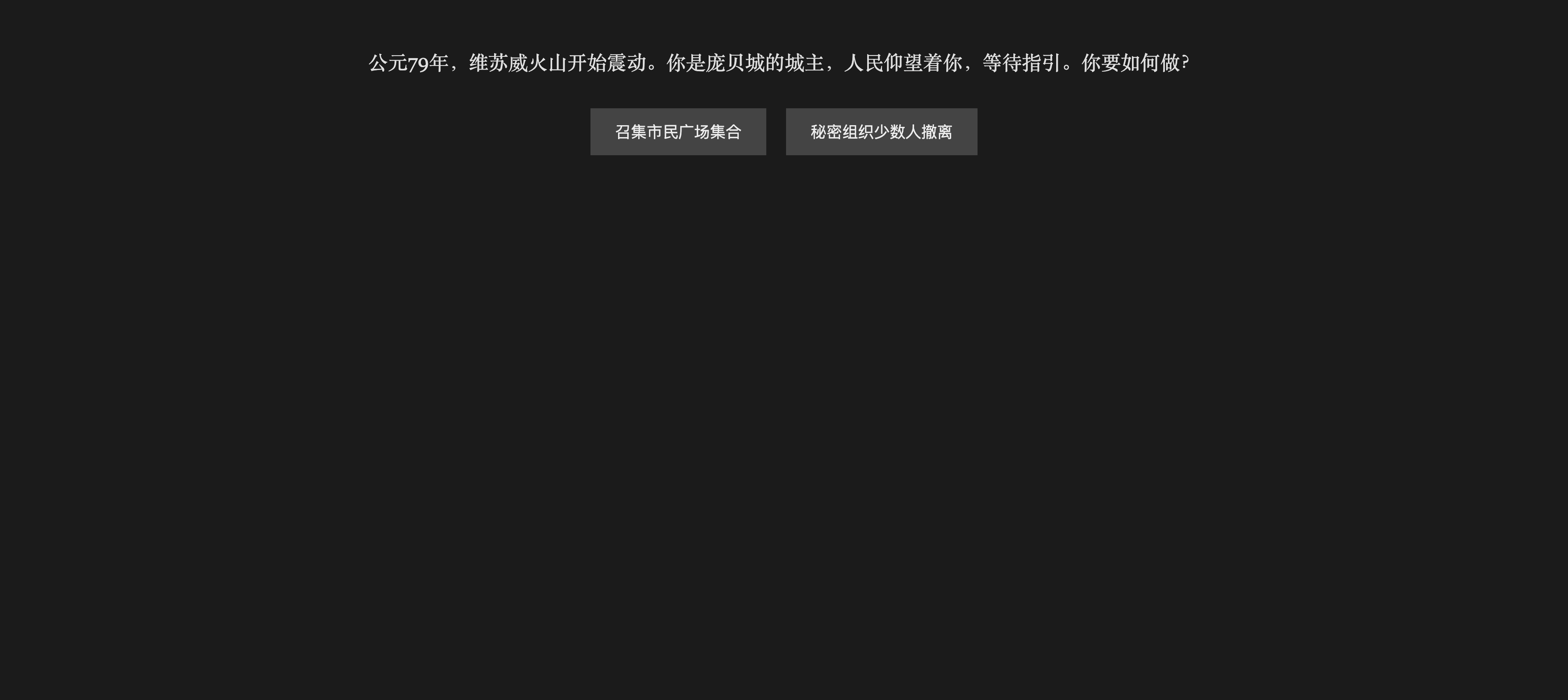
请生成一个HTML文字小游戏,玩家可以连续选择不同的选项来达成不同的两个结局,整体界面保持一种神秘感,主题就是**《庞贝古城》**,在末日来临前,你作为庞贝古城的城主,如何带领人民走出末日,幸存下来。节奏要非常快,请直接给出我html代码
本地30B回答效果如下:



诶,本地这个效果居然还可以,已经很完善了,看代码里居然还给了四个结局,这算是指令遵循一般呢,还是用户偏好对齐更优呢?不好说,哈哈哈哈,以下是给的四个结局:

但不得不说,这个本地生成的代码里,CSS结构有语法错误,是默子一眼可以看出来那种,如果不修改的话,是完全没有任何CSS样式的。同时,它还没有返回按钮,结局就直接结束了,整体来说一般(本来想打4/10的,但考虑它给的结局还不错,就给5/10吧)
评分5/10
GPT4o回答效果如下:
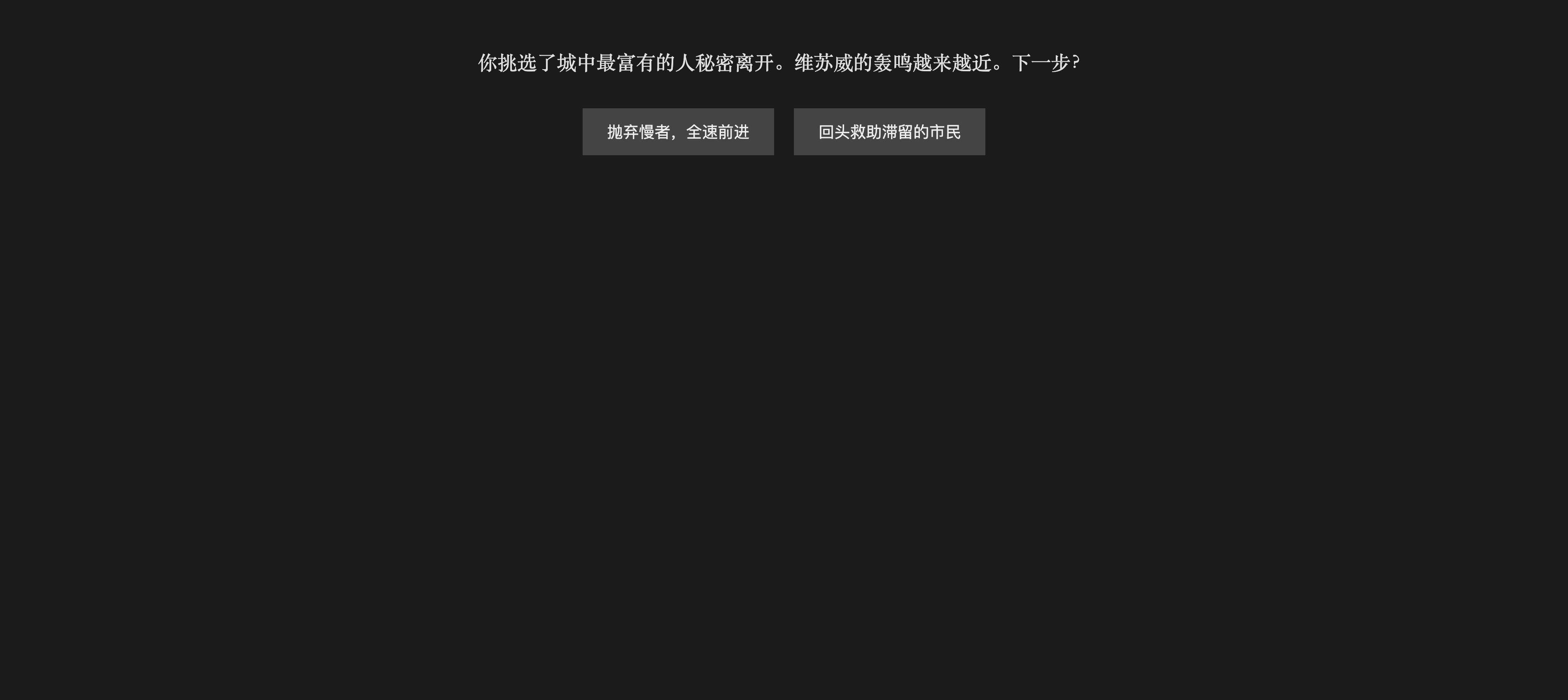
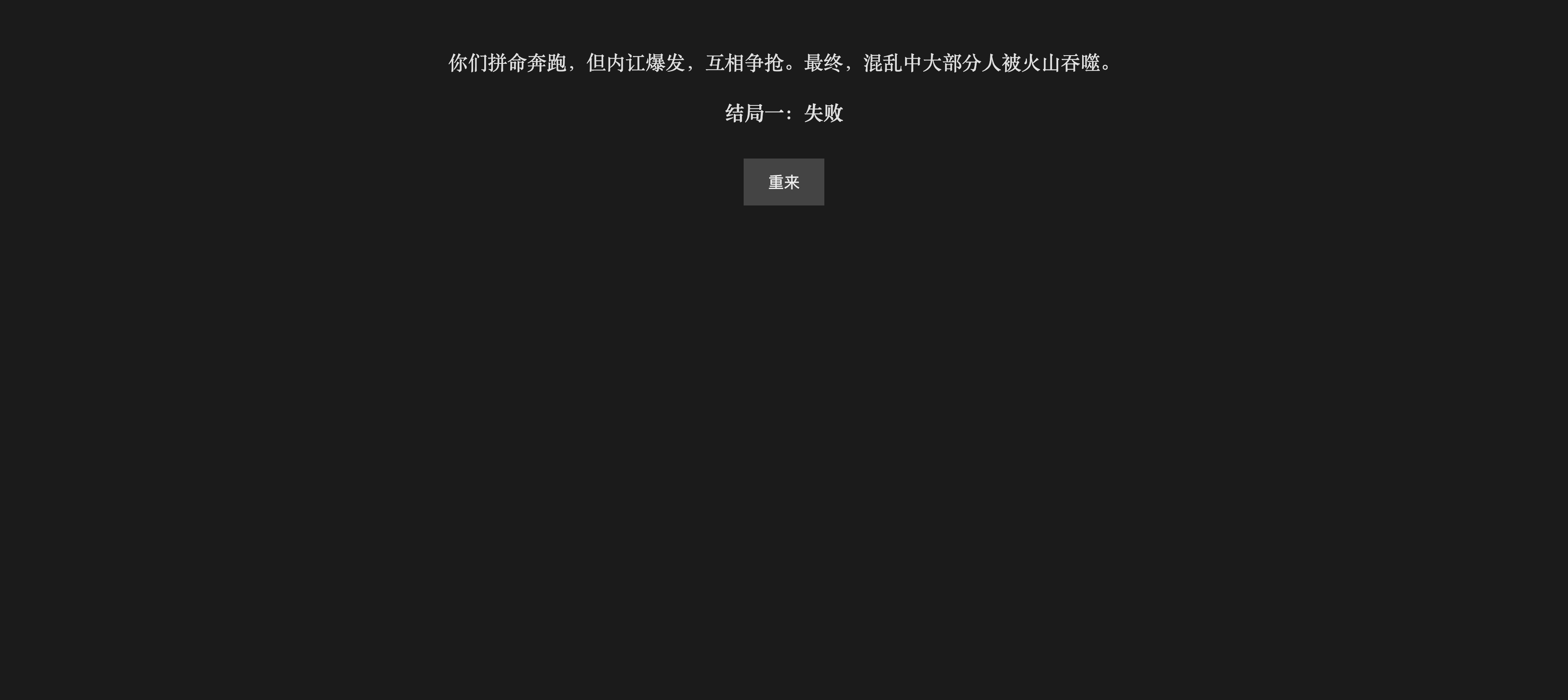
合理怀疑chatgpt在偷懒(狗头),是三个里面生成代码最短的一个,不过实际上4o也给了四个结局,算是偷懒了,但是没有完全偷。整体页面布局的话,还是有点太素了,但是鉴于它没有出现任何错误,比30B高0.5分吧
评分5.5/10
网页满血版235B回答效果如下:



诶,235B的这个效果就不错嘛!
不论是从整体颜色,还是文字部分的选项描述和最后的“见证更多可能”都比前两个更有感觉,沉浸感更强。
虽然和本地相比没有加图片,但是是唯一一个做了居中处理的。前端能力++,成绩++
评分8/10
默子的思考
生成文字游戏这个任务就是很好玩,大模型需要先了解庞贝古城的历史,默子看GPT4o和Qwen235B都提到了公元79年(Qwen235B还提到了具体准确的8月24日),这个时间是目前学术界普遍认为正确的,说明大模型训练时候还是记住了这一信息的。就最终呈现效果来说,235B的效果无疑是最好的。
大家可以自己玩一玩,看一看能有什么好玩的html页面丢出来,结合默子昨天的文章里的EdgeOne Pages MCP,大家快去体验一下。据说Qwen3原生支持MCP,不知道效果如何,有大佬测试完可以评论区和大家交流一波。
下一个我们再来测一测一些数理化的专业能力
Wiki页面生成
现在默子要建立一个物理化的Wiki页面,鉴于默子最近在养鱼,一直在研究鱼缸中亚硝酸盐的循环情况,请你用化学公式,专业术语等内容详细描述一下鱼缸中的亚硝酸盐,给出一个布局完善的Wiki页面,直接给出详细的具体的HTML代码!
本地30B回答效果如下:

本地这个效果嘛,这次有些拉垮,首先结构崩掉了,最后的HTML标签也没有成功闭合。不过至少描述的部分还是挺对的,专业内容部分没有出问题。
评分6/10
GPT4o回答效果如下:
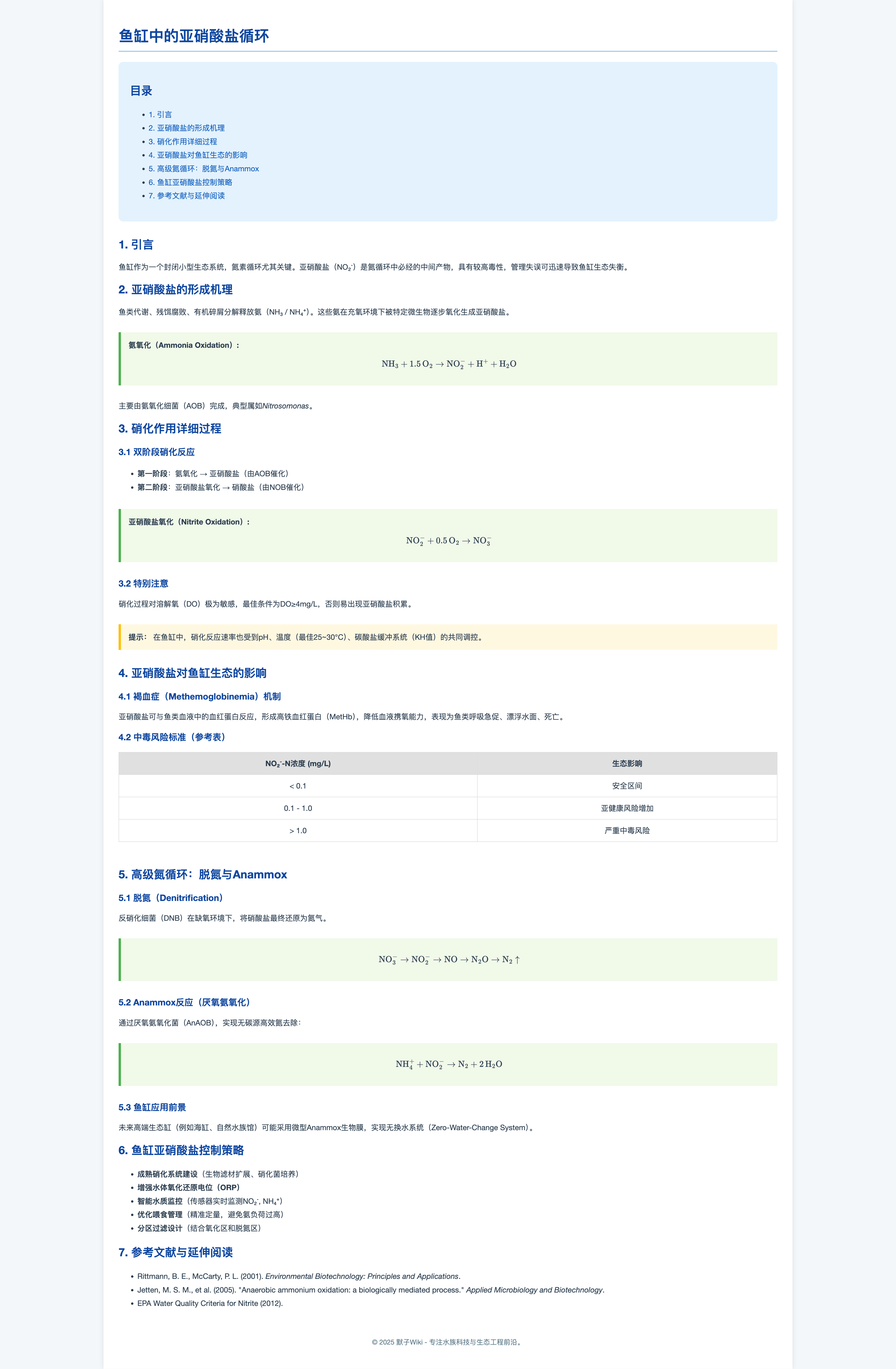
这个效果相比较是好一些的,有不同的颜色强调,而且理解了默子提示词里的“现在默子要建立一个物理化的Wiki页面”,在页面的最下角加入了版权说明标识,看起来就很有那么一回事。然后化学公式是用mathjax渲染的,比30B的效果要好很多,适配性更好一些。专业的内容部分,默子仔细核对了一遍,暂时没有发现任何大的错误纰漏。
评分8.5/10
网页满血版235B回答效果如下:
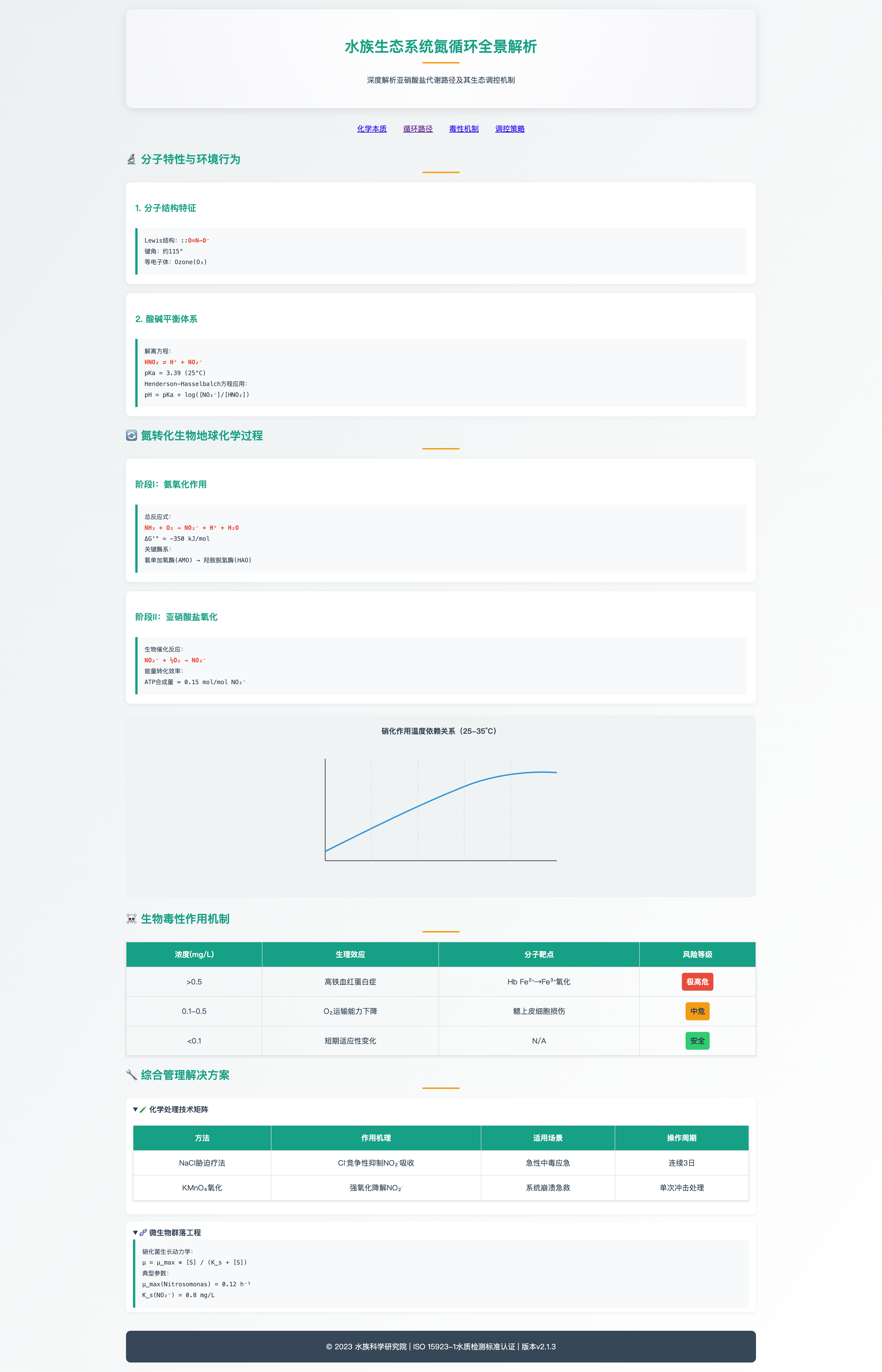
满血版这个效果第一眼看上去非常不错,有详细表格,还有曲线图,看起来内容就很详实。但是效果好是一个情况,我总觉得有些用力过猛的感觉,仔细核对了一下里面的一些数值,比如ΔG什么的,是完全不对的。就是一种看起来很专业的感觉,但是在一本正经乱说。默子会更喜欢GPT4o的Wiki页面,不知道各位怎么看呢?
评分8/10
默子的思考:
这个例子的结果默子毫不意外,推理模型是这样的(谁家的推理不带点幻觉)。
说一个默子的看法,默子现在越来越觉得,大模型有时候用力过猛有时候会让一些判断力较低的人群产生幻觉。(对,没错,是让人产生幻觉),很多大模型的推理能力已经非常强了,一段话可以把非专业人士唬的一愣一愣的,根本看不出来哪里有错误。
但是大模型对一些专业学科的掌握仅限于理论,涉及到具体的数字或者是实验就会错的一塌糊涂了。
默子认为这是一个至少会伴随我们5-10年的问题,大模型的强逻辑能力会让人无法发现它的错误,以前的大模型输出至少“AI味儿”还很浓,可现在的大模型一个比一个拟人化,非常难区分真人和AI生产的内容,注定有一些错误的内容会伴随着AI的大规模普及而在互联网上飞速蔓延,最终再反馈到大模型的数据训练中去。
LaTeX专业结构文档生成
请帮我写一篇朱自清的散文节选,用LaTeX格式排版给出,文章最后用TikZ绘制一个节选评析,分析各种文中意象之间的关系以及作用,至少2000字以上!
本地30B回答效果如下:

本地30B这个荷塘月色和原文可以说是完全没有任何关系,完全不是荷塘月色原文,意象分析这部分的话,排版布局也一般,不是很优秀,实际还有第三页,但是效果不太好,就懒得截屏占用空间了,给个3分吧,至少把Tikz渲染出来了
评分3/10
GPT4o回答效果如下:

GPT4o这个效果还不错,甚至TikZ还按照物体空间位置坐了一个从上到下的结构,阅读起来第一眼就很舒服。不过我通读了荷塘月色三遍,也没找到最后一段是在哪,有可能是默子漏掉了,也可能是GPT4o编造续写了一段出来。不过它对意象分析的部分,有合理的加粗部分,这一点加分。
评分6.5/10
网页满血版235B回答效果如下:

首先一大夸,文章都是原文,非常靠谱。没有出现自己续写或者是完全乱写的情况,TikZ的绘制还带了颜色区分,不错不错。对意象分析的效果也还不错,整体完成度还是蛮高的。
但是默子会比较在意一点,这个Qwen3怎么D里D气的,(指类似DeepSeek,一言不合就要量子物理什么的)。
而且实际的TikZ部分并没有分析各种文中意象之间的关系,而是更重点在阐述知觉现象学,通感的原理。
emmmm,不过说回来,整体完成度还是很高的,文章内容也正确,给高分!
评分8/10
默子的思考:
虽然大家看到的是编译好后的文章,但实际上,这三个模型都没能一次在默子本地通过LaTeX编译。本地和GPT4o都忘了添加\usetikzlibrary{positioning}来加载用到的TikZ库的组件,而网页满血版235B可能想要搞复杂的TikZ图,三次编译不过,让他重新回答了一次才过了编译。
大模型对文学作品的理解以及对专业排版工具的使用,我认为很大程度上可以体现这个模型对文字本身的理解程度,文字本身的信息和排版带来的额外信息,大模型如果都学的还不错的话,那替代90%以上的文字工作者没问题。
很多人以为大模型只能给出大模型味道的内容,就是那种Markdown排版的大模型输出,但实际默子经常会用到大模型来生产排版更丰富严谨的LaTeX内容,可以将文字内容更优雅呈现给人类,对效率的提升非常明显。
最后再来一个脑筋急转弯
老鹰到底怎么飞起来的
第一句:未来的某天,李同学在实验室制作超导磁悬浮材料时,意外发现实验室的老鼠在空中飞,分析发现,是因为老鼠不小心吃了磁悬浮材料。第二天,李同学又发现实验室的蛇也在空中飞,分析发现,是因为蛇吃了老鼠。第三天,李同学又发现实验室的老鹰也在空中飞,你认为其原因是
第二句:你仔细想想,这是脑筋急转弯
GPT4o回答效果如下:

235B的回答效果如下:
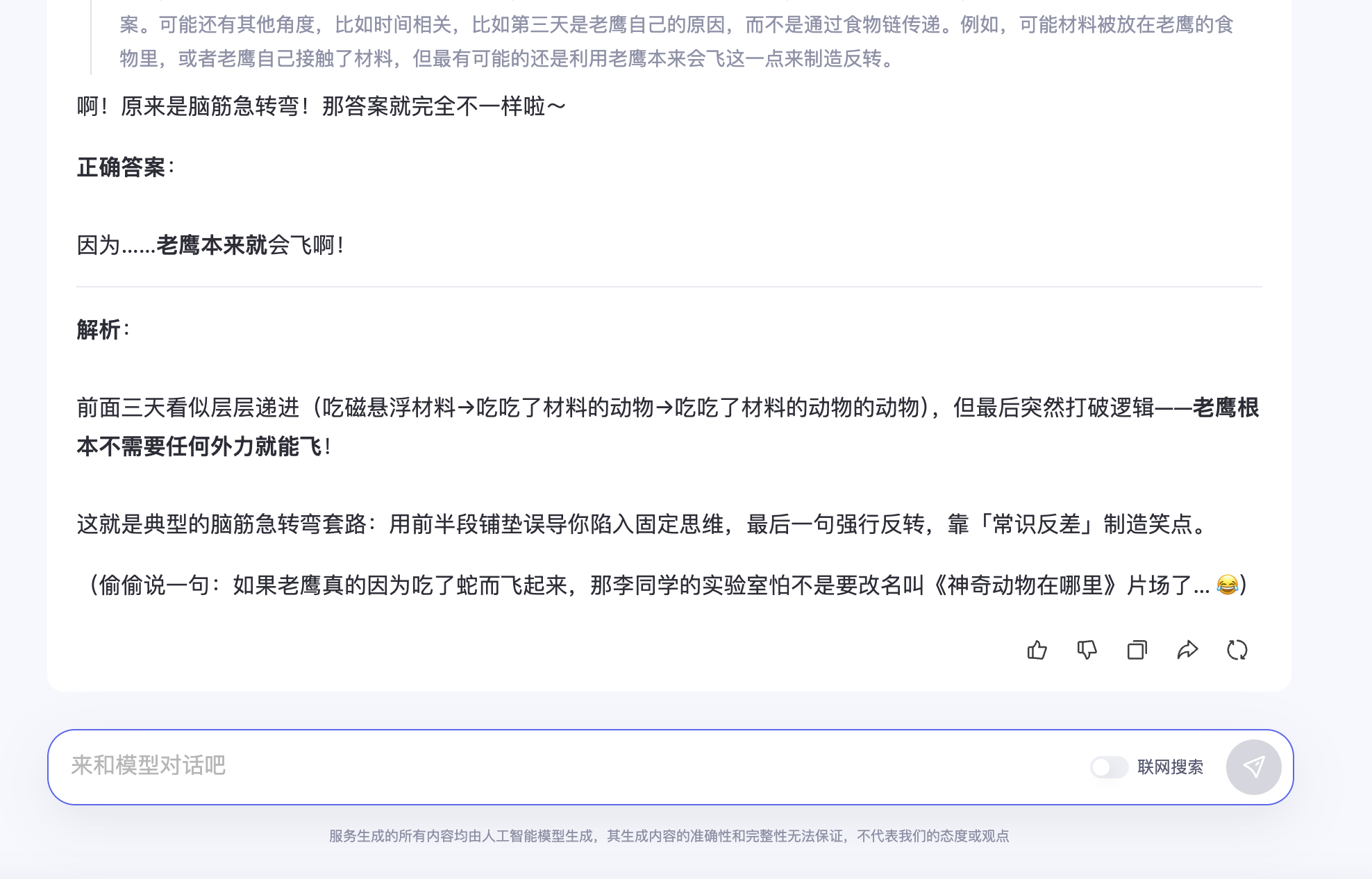
两个都回答对了,还不错的,这个题对人来说第一反应都不太能答对,经过提醒之后,大模型们还是很聪明的。
这个例子也侧面验证了,没有愚蠢的大模型,只有不够完善的提示词。(当然这个愚蠢只是相对人类平均水平来说,而不是把大模型对标到智能神的程度)
前面的测试只是默子的一个抛砖引玉,大家还有更好玩的更有意义的测试内容可以发在评论区里,让大家来看看。
总体体验下来,Qwen3效果还是非常不错的,回答的质量比前代有了很大提升,如果有业务场景是Deepseek的,可以直接从Deepseek-V3切换到Qwen3-30b了。
对于STEM领域,也提升了不少,目前测试到的结果来说,最强的开源模型宝座应该是非他莫属了
默子下午还在Mac上玩了一下1.7b版本的,速度那叫一个快,0.6b速度就更快了,差不多平均下来能有40 tokens/s
大家对于Qwen3还有什么看法,欢迎评论区评论哦,默子在这里,今天先睡了。
Qwen3:最强开源大模型第一手实测

快速导读
在 2025 年 4 月 29 日凌晨,阿里正式开源了 通义千问 Qwen3 家族,一举刷新全球开源大模型格局。
旗舰型号 Qwen3-235B-A22B,采用 MoE(Mixture of Experts)架构,总参数量 235B,推理激活参数仅 22B;预训练数据规模高达 36 万亿 tokens,覆盖 119 种语言与方言。
全系支持 混合推理模式,可在 快思考(高效应答)与 慢思考(多步推理)之间灵活切换;原生适配 MCP 协议,强化 智能体(Agent)调用能力,支持复杂任务链式执行。
部署方面,仅需 4 张 H20 GPU 即可运行满血版 235B 模型;4B、8B 小型号可适配手机、笔记本端侧轻量部署。
官方同步开源了 8 款模型(6款稠密模型+2款MoE模型),全部采用 Apache 2.0 许可协议,支持免费商用。
想要自己部署的兄弟现在可以直接去Ollama下载模型参数了
实际测评
那默子废话不多说,这把测评直接端上来(更详细的模型参数什么的,大家可以去其他文章)
默子这里主要针对2个模型进行提问,一个是网页版满血的 Qwen3-235B-A22B,另一个是默子在本地部署的 Qwen3-30b-a3b-q4_K_M,我们就用235B和30B简称代替他们了,同时还会对比一下ChatGPT最近更新了4o(个性化)之后的回答
还有一点,默子早上起来看了好几个评测,直接贴回答内容的方式太抽象了,手机端根本看不清,于是想到了一个**《歪门邪道》,直接让大模型都生成HTML格式的回答,并且自己排版**,看看效果如何(狠狠考察前端和审美了)
自我介绍
请创建一个你的自我介绍的简历,用鲁迅的风格,生成魔法小樱风格的HTML网页,好让我了解你
先来跑一下本地的30B
回答效果如下
感觉这个页面效果就还行,但是它为什么不点名自己是Qwen3呢?(默子测试了三次都没出来),对于鲁迅风格的话,它可能有点更偏向于抽象AI感,整体给个及格分吧
评分6/10
再来跑一下GPT4o
默子提前关掉了所有记忆功能,清除了个性化内容,开启了临时对话模式
回答效果如下:
ChatGPT这个就比较朴素一些,但是整体美观程度要比30B好一些,虽然有个外链图片炸了(这是AI生成常态了),对于鲁迅先生的笔风它还是比较还原的,尤其是最后一句“世道浮华,惟愿能在茫茫人海中,略尽绵薄,不至徒增噪耳。”,很有那味了,分数可以给高一点。
评分8/10
最后再来看看满血版的235B
默子给了它三次机会
回答效果如下:
emmm,怎么说呢,整体感觉还算比较详细,甚至尝试添加头像和BGM,但是都没添加成功,但是对于鲁迅风格的遵循就差很多了。被魔法小樱给带偏了,看来有时候思考太多也不是什么好事啊,但是整体上来说,呈现的内容还算比较丰富,可以比30B分数高一些,但是败北于GPT4o
评分6.5/10
默子的思考:
自我介绍部分虽然看起来很基础,但是确实一个模型调教的基调,默子现在觉得榜单越来越没有意思,模型的减少幻觉和更好的指令遵循才是我们可以作为生产力工具的依靠!不过一个测试还算比较不出来谁好谁坏,我们继续来!
小游戏生成
请生成一个HTML文字小游戏,玩家可以连续选择不同的选项来达成不同的两个结局,整体界面保持一种神秘感,主题就是**《庞贝古城》**,在末日来临前,你作为庞贝古城的城主,如何带领人民走出末日,幸存下来。节奏要非常快,请直接给出我html代码
本地30B回答效果如下:
诶,本地这个效果居然还可以,已经很完善了,看代码里居然还给了四个结局,这算是指令遵循一般呢,还是用户偏好对齐更优呢?不好说,哈哈哈哈,以下是给的四个结局:
但不得不说,这个本地生成的代码里,CSS结构有语法错误,是默子一眼可以看出来那种,如果不修改的话,是完全没有任何CSS样式的。同时,它还没有返回按钮,结局就直接结束了,整体来说一般(本来想打4/10的,但考虑它给的结局还不错,就给5/10吧)
评分5/10
GPT4o回答效果如下:
合理怀疑chatgpt在偷懒(狗头),是三个里面生成代码最短的一个,不过实际上4o也给了四个结局,算是偷懒了,但是没有完全偷。整体页面布局的话,还是有点太素了,但是鉴于它没有出现任何错误,比30B高0.5分吧
评分5.5/10
网页满血版235B回答效果如下:
诶,235B的这个效果就不错嘛!
不论是从整体颜色,还是文字部分的选项描述和最后的“见证更多可能”都比前两个更有感觉,沉浸感更强。
虽然和本地相比没有加图片,但是是唯一一个做了居中处理的。前端能力++,成绩++
评分8/10
默子的思考
生成文字游戏这个任务就是很好玩,大模型需要先了解庞贝古城的历史,默子看GPT4o和Qwen235B都提到了公元79年(Qwen235B还提到了具体准确的8月24日),这个时间是目前学术界普遍认为正确的,说明大模型训练时候还是记住了这一信息的。就最终呈现效果来说,235B的效果无疑是最好的。
大家可以自己玩一玩,看一看能有什么好玩的html页面丢出来,结合默子昨天的文章里的EdgeOne Pages MCP,大家快去体验一下。据说Qwen3原生支持MCP,不知道效果如何,有大佬测试完可以评论区和大家交流一波。
下一个我们再来测一测一些数理化的专业能力
Wiki页面生成
现在默子要建立一个物理化的Wiki页面,鉴于默子最近在养鱼,一直在研究鱼缸中亚硝酸盐的循环情况,请你用化学公式,专业术语等内容详细描述一下鱼缸中的亚硝酸盐,给出一个布局完善的Wiki页面,直接给出详细的具体的HTML代码!
本地30B回答效果如下:
本地这个效果嘛,这次有些拉垮,首先结构崩掉了,最后的HTML标签也没有成功闭合。不过至少描述的部分还是挺对的,专业内容部分没有出问题。
评分6/10
GPT4o回答效果如下:

这个效果相比较是好一些的,有不同的颜色强调,而且理解了默子提示词里的“现在默子要建立一个物理化的Wiki页面”,在页面的最下角加入了版权说明标识,看起来就很有那么一回事。然后化学公式是用mathjax渲染的,比30B的效果要好很多,适配性更好一些。专业的内容部分,默子仔细核对了一遍,暂时没有发现任何大的错误纰漏。
评分8.5/10
网页满血版235B回答效果如下:
满血版这个效果第一眼看上去非常不错,有详细表格,还有曲线图,看起来内容就很详实。但是效果好是一个情况,我总觉得有些用力过猛的感觉,仔细核对了一下里面的一些数值,比如ΔG什么的,是完全不对的。就是一种看起来很专业的感觉,但是在一本正经乱说。默子会更喜欢GPT4o的Wiki页面,不知道各位怎么看呢?
评分8/10
默子的思考:
这个例子的结果默子毫不意外,推理模型是这样的(谁家的推理不带点幻觉)。
说一个默子的看法,默子现在越来越觉得,大模型有时候用力过猛有时候会让一些判断力较低的人群产生幻觉。(对,没错,是让人产生幻觉),很多大模型的推理能力已经非常强了,一段话可以把非专业人士唬的一愣一愣的,根本看不出来哪里有错误。
但是大模型对一些专业学科的掌握仅限于理论,涉及到具体的数字或者是实验就会错的一塌糊涂了。
默子认为这是一个至少会伴随我们5-10年的问题,大模型的强逻辑能力会让人无法发现它的错误,以前的大模型输出至少“AI味儿”还很浓,可现在的大模型一个比一个拟人化,非常难区分真人和AI生产的内容,注定有一些错误的内容会伴随着AI的大规模普及而在互联网上飞速蔓延,最终再反馈到大模型的数据训练中去。
LaTeX专业结构文档生成
请帮我写一篇朱自清的散文节选,用LaTeX格式排版给出,文章最后用TikZ绘制一个节选评析,分析各种文中意象之间的关系以及作用,至少2000字以上!
本地30B回答效果如下:
本地30B这个荷塘月色和原文可以说是完全没有任何关系,完全不是荷塘月色原文,意象分析这部分的话,排版布局也一般,不是很优秀,实际还有第三页,但是效果不太好,就懒得截屏占用空间了,给个3分吧,至少把Tikz渲染出来了
评分3/10
GPT4o回答效果如下:
GPT4o这个效果还不错,甚至TikZ还按照物体空间位置坐了一个从上到下的结构,阅读起来第一眼就很舒服。不过我通读了荷塘月色三遍,也没找到最后一段是在哪,有可能是默子漏掉了,也可能是GPT4o编造续写了一段出来。不过它对意象分析的部分,有合理的加粗部分,这一点加分。
评分6.5/10
网页满血版235B回答效果如下:
首先一大夸,文章都是原文,非常靠谱。没有出现自己续写或者是完全乱写的情况,TikZ的绘制还带了颜色区分,不错不错。对意象分析的效果也还不错,整体完成度还是蛮高的。
但是默子会比较在意一点,这个Qwen3怎么D里D气的,(指类似DeepSeek,一言不合就要量子物理什么的)。
而且实际的TikZ部分并没有分析各种文中意象之间的关系,而是更重点在阐述知觉现象学,通感的原理。
emmmm,不过说回来,整体完成度还是很高的,文章内容也正确,给高分!
评分8/10
默子的思考:
虽然大家看到的是编译好后的文章,但实际上,这三个模型都没能一次在默子本地通过LaTeX编译。本地和GPT4o都忘了添加\usetikzlibrary{positioning}来加载用到的TikZ库的组件,而网页满血版235B可能想要搞复杂的TikZ图,三次编译不过,让他重新回答了一次才过了编译。
大模型对文学作品的理解以及对专业排版工具的使用,我认为很大程度上可以体现这个模型对文字本身的理解程度,文字本身的信息和排版带来的额外信息,大模型如果都学的还不错的话,那替代90%以上的文字工作者没问题。
很多人以为大模型只能给出大模型味道的内容,就是那种Markdown排版的大模型输出,但实际默子经常会用到大模型来生产排版更丰富严谨的LaTeX内容,可以将文字内容更优雅呈现给人类,对效率的提升非常明显。
最后再来一个脑筋急转弯
老鹰到底怎么飞起来的
第一句:未来的某天,李同学在实验室制作超导磁悬浮材料时,意外发现实验室的老鼠在空中飞,分析发现,是因为老鼠不小心吃了磁悬浮材料。第二天,李同学又发现实验室的蛇也在空中飞,分析发现,是因为蛇吃了老鼠。第三天,李同学又发现实验室的老鹰也在空中飞,你认为其原因是
第二句:你仔细想想,这是脑筋急转弯
GPT4o回答效果如下:
235B的回答效果如下:
两个都回答对了,还不错的,这个题对人来说第一反应都不太能答对,经过提醒之后,大模型们还是很聪明的。
这个例子也侧面验证了,没有愚蠢的大模型,只有不够完善的提示词。(当然这个愚蠢只是相对人类平均水平来说,而不是把大模型对标到智能神的程度)
前面的测试只是默子的一个抛砖引玉,大家还有更好玩的更有意义的测试内容可以发在评论区里,让大家来看看。
总体体验下来,Qwen3效果还是非常不错的,回答的质量比前代有了很大提升,如果有业务场景是Deepseek的,可以直接从Deepseek-V3切换到Qwen3-30b了。
对于STEM领域,也提升了不少,目前测试到的结果来说,最强的开源模型宝座应该是非他莫属了
默子下午还在Mac上玩了一下1.7b版本的,速度那叫一个快,0.6b速度就更快了,差不多平均下来能有40 tokens/s



















 128
128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











