







简介
随着深度学习的发展,对并行训练的需求越来越大。这是因为模型和数据集越来越大,如果我们坚持使用单 GPU 训练,训练过程的等待将会成为一场噩梦。在本节中,我们将对现有的并行训练方法进行简要介绍。如果您想对这篇文章进行补充,欢迎在GitHub论坛上进行讨论。
数据并行
数据并行是最常见的并行形式,因为它很简单。在数据并行训练中,数据集被分割成几个碎片,每个碎片被分配到一个设备上。这相当于沿批次维度对训练过程进行并行化。每个设备将持有一个完整的模型副本,并在分配的数据集碎片上进行训练。在反向传播之后,模型的梯度将被全部减少,以便在不同设备上的模型参数能够保持同步。
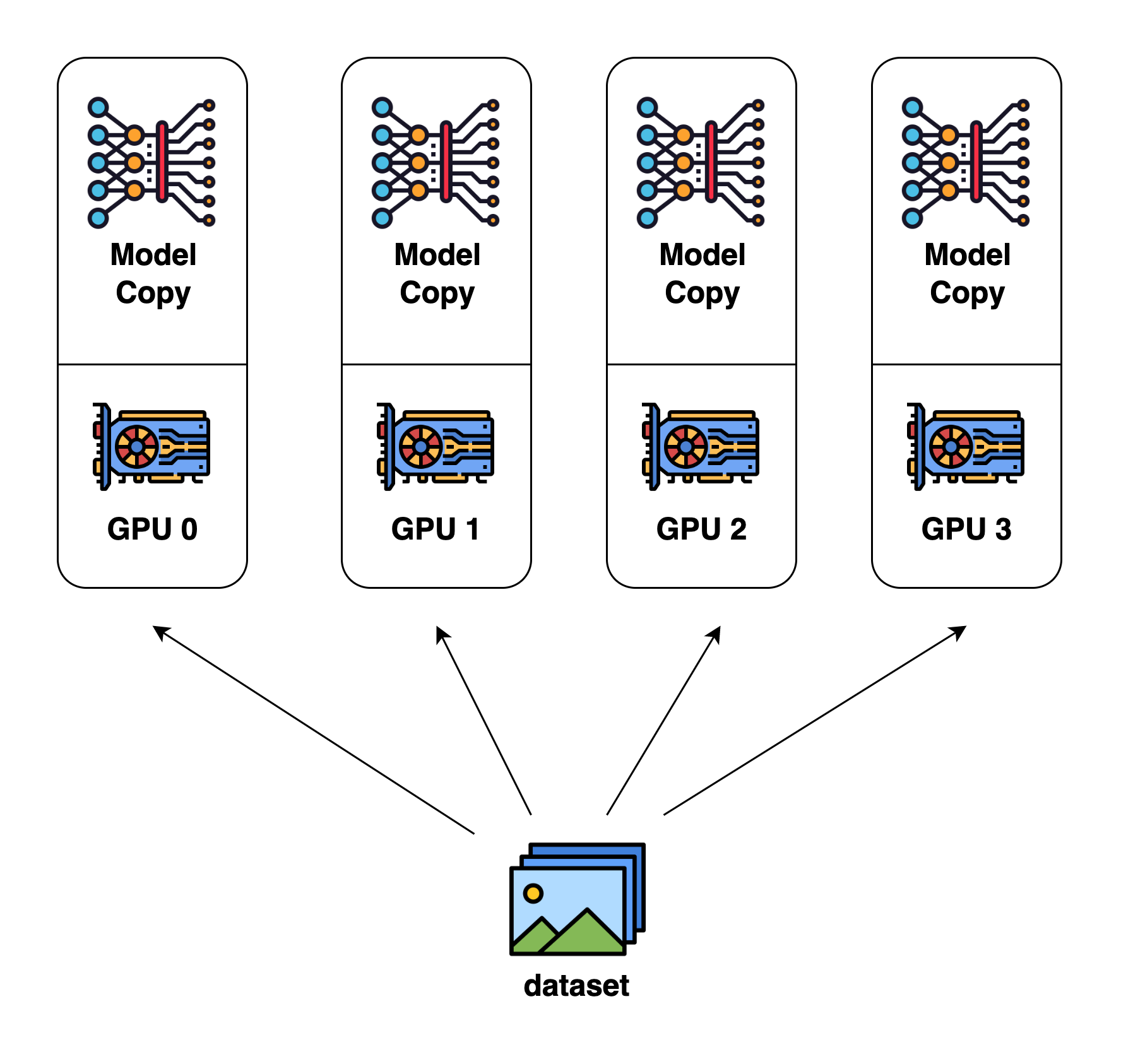
数据并行
模型并行
在数据并行训练中,一个明显的特点是每个 GPU 持有整个模型权重的副本。这就带来了冗余问题。另一种并行模式是模型并行,即模型被分割并分布在一个设备阵列上。通常有两种类型的并行:张量并行和流水线并行。张量并行是在一个操作中进行并行计算,如矩阵-矩阵乘法。流水线并行是在各层之间进行并行计算。因此,从另一个角度来看,张量并行可以被看作是层内并行,流水线并行可以被看作是层间并行。
张量并行
张量并行训练是将一个张量沿特定维度分成 N 块,每个设备只持有整个张量的 1/N,同时不影响计算图的正确性。这需要额外的通信来确保结果的正确性。
以一般的矩阵乘法为例,假设我们有 C = AB。我们可以将B沿着列分割成 [B0 B1 B2 ... Bn],每个设备持有一列。然后我们将 A 与每个设备上 B 中的每一列相乘,我们将得到 [AB0 AB1 AB2 ... ABn] 。此刻,每个设备仍然持有一部分的结果,例如,设备(rank=0)持有 AB0。为了确保结果的正确性,我们需要收集全部的结果,并沿列维串联张量。通过这种方式,我们能够将张量分布在设备上,同时确保计算流程保持正确。
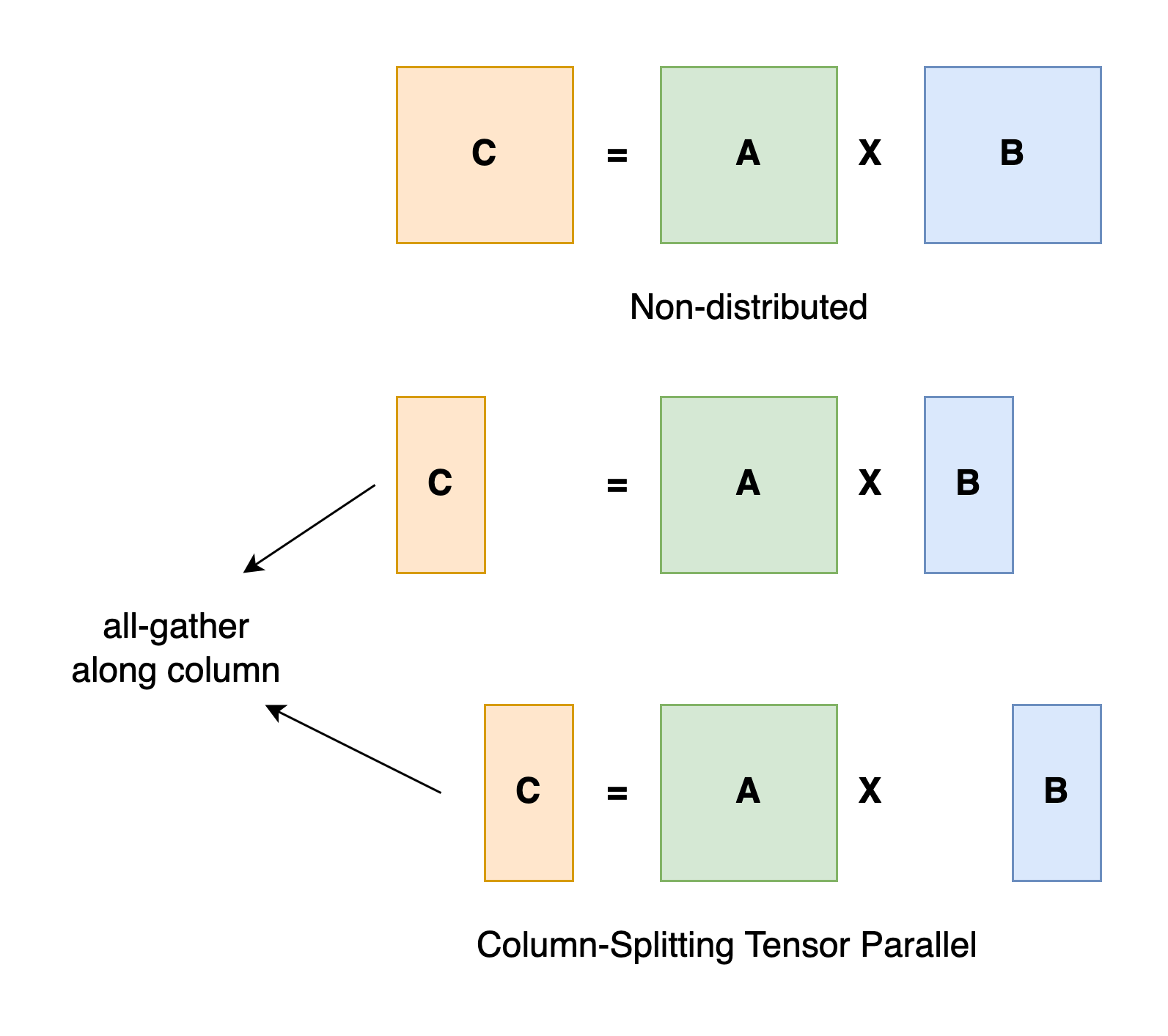
张量并行
在 Colossal-AI 中,我们提供了一系列的张量并行方法,即 1D、2D、2.5D 和 3D 张量并行。我们将在高级教程中详细讨论它们。
相关文章:
- GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
- An Efficient 2D Method for Training Super-Large Deep Learning Models
- 2.5-dimensional distributed model training
- Maximizing Parallelism in Distributed Training for Huge Neural Networks
流水线并行
流水线并行一般来说很容易理解。请您回忆一下您的计算机结构课程,这确实存在于 CPU 设计中。
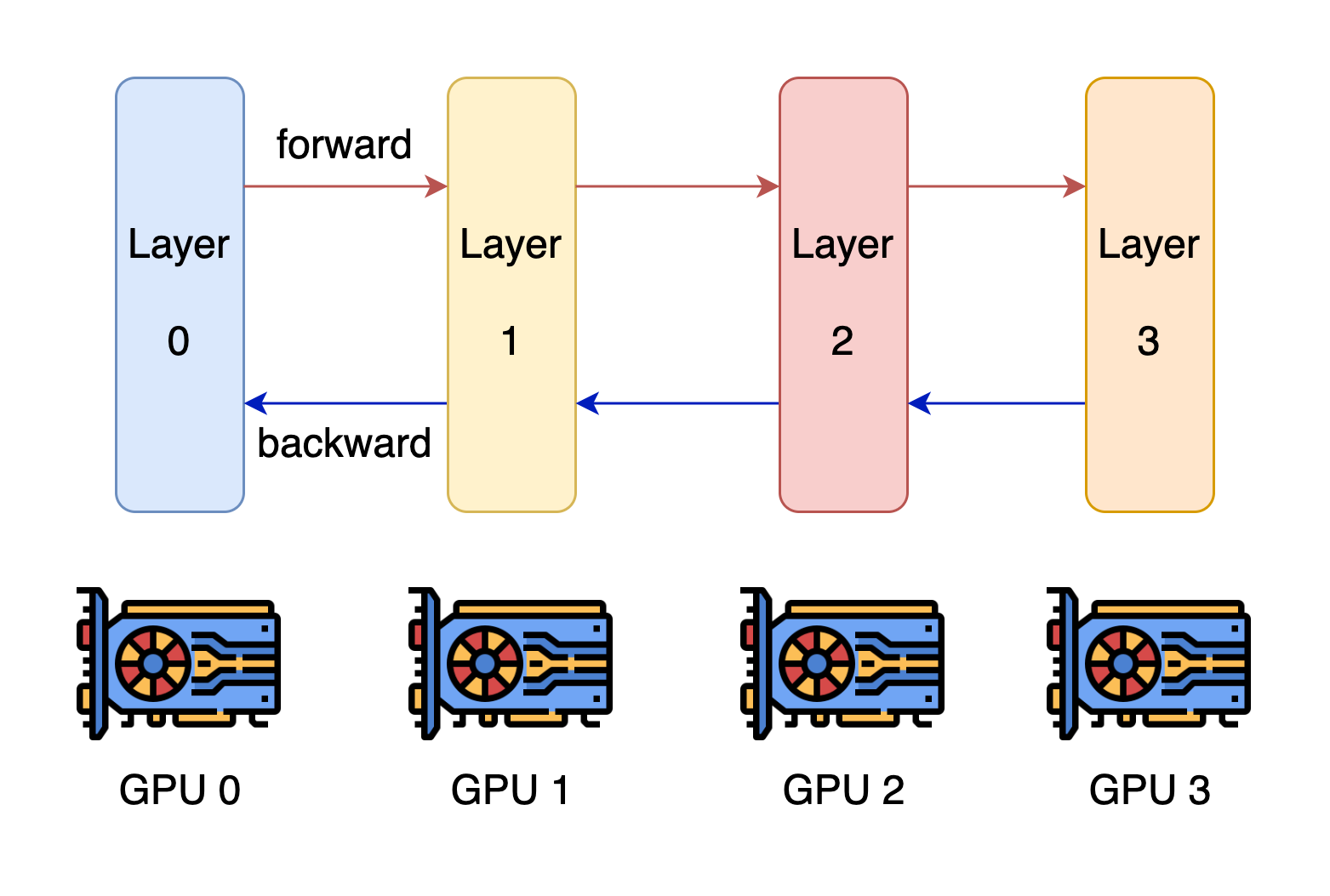
流水线并行
流水线并行的核心思想是,模型按层分割成若干块,每块都交给一个设备。在前向传递过程中,每个设备将中间的激活传递给下一个阶段。在后向传递过程中,每个设备将输入张量的梯度传回给前一个流水线阶段。这允许设备同时进行计算,并增加了训练的吞吐量。流水线并行训练的一个缺点是,会有一些设备参与计算的冒泡时间,导致计算资源的浪费。
Source: GPipe
相关文章:
- PipeDream: Fast and Efficient Pipeline Parallel DNN Training
- GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
- Chimera: Efficiently Training Large-Scale Neural Networks with Bidirectional Pipelines
优化器相关的并行
另一种并行方法和优化器相关,目前这种并行最流行的方法是 ZeRO,即零冗余优化器。 ZeRO 在三个层面上工作,以消除内存冗余(ZeRO需要进行fp16训练)。
- Level 1: 优化器状态在各进程中被划分。
- Level 2: 用于更新模型权重的32位梯度也被划分,因此每个进程只存储与其优化器状态划分相对应的梯度。
- Level 3: 16位模型参数在各进程中被划分。
相关文章:
异构系统的并行
上述方法通常需要大量的 GPU 来训练一个大型模型。然而,人们常常忽略的是,与 GPU 相比,CPU 的内存要大得多。在一个典型的服务器上,CPU 可以轻松拥有几百GB的内存,而每个 GPU 通常只有16或32GB的内存。这促使人们思考为什么 CPU 内存没有被用于分布式训练。
最近的进展是依靠 CPU 甚至是 NVMe 磁盘来训练大型模型。主要的想法是,在不使用张量时,将其卸载回 CPU 内存或 NVMe 磁盘。通过使用异构系统架构,有可能在一台机器上容纳一个巨大的模型。
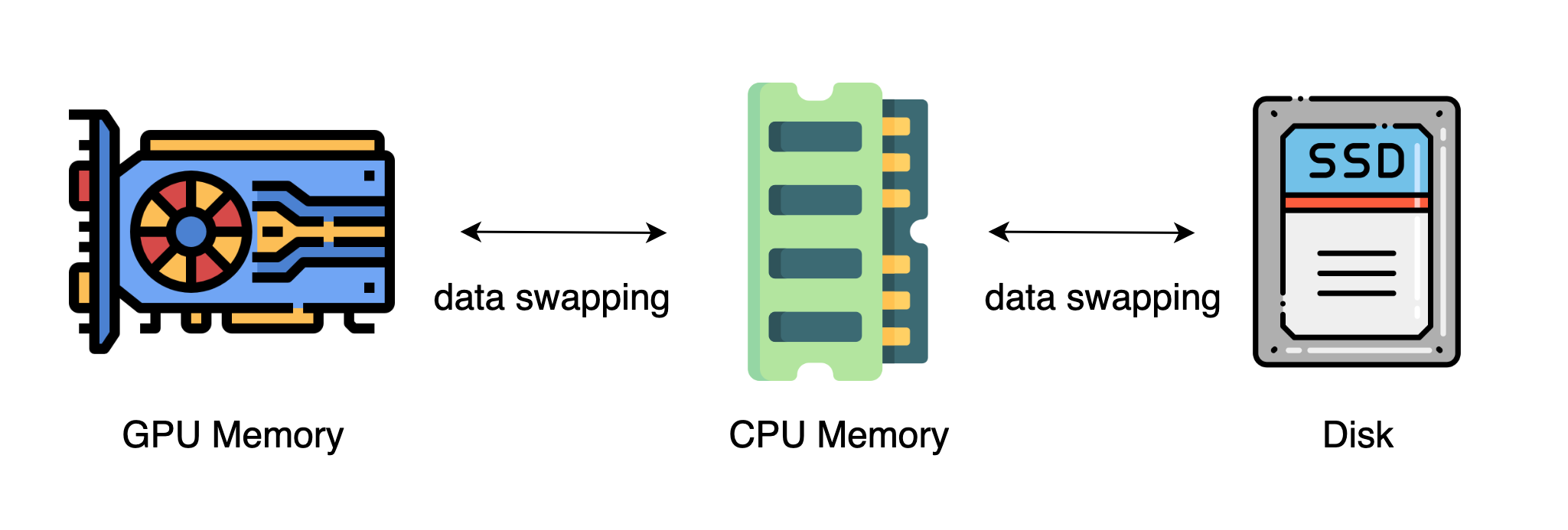
异构系统
相关文章:















 1066
1066











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









