







 本文回顾了GAN的基本原理,并详细介绍了GAIL(生成判别模仿学习)如何利用生成器和判别器在智能体模仿学习中的角色。GAIL以专家轨迹数据为训练样本,通过策略网络和判别器优化,实现智能体行为的高效学习。
本文回顾了GAN的基本原理,并详细介绍了GAIL(生成判别模仿学习)如何利用生成器和判别器在智能体模仿学习中的角色。GAIL以专家轨迹数据为训练样本,通过策略网络和判别器优化,实现智能体行为的高效学习。
1 GAN (回顾)
GAN由生成器
(Generator)
和判别器
(Discriminator)组成,它们
各是一个神经网络。
——>生成器负责生成假的样本
——>判别器负责判定一个样本是真是假。
我们的目标是希望生成器生成的内容可以“以假乱真”
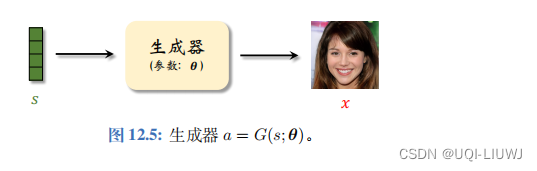
1.1 生成器
生成器
记作
a
=
G
(
s
;
θ
)
,其中 θ
是参数。它的输入是向量
s
,向量的每一个元素从均匀分布 或标准正态分布
N
(0
, 1) 中抽取。生成器的输出是数据(比如图片)x。
或标准正态分布
N
(0
, 1) 中抽取。生成器的输出是数据(比如图片)x。
1.2 判别器
判别器
记作 ,其中 ϕ
是参数。
,其中 ϕ
是参数。
它的输入是图片
x;输出
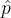 是介于 0
到
1
之间的概率值,0
表示“假的”,
1
表示“真的”。
是介于 0
到
1
之间的概率值,0
表示“假的”,
1
表示“真的”。
判别器的功能是二分类器。
1.3 训练生成器
将生成器与判别器相连,固定住判别器的参数,只更新生成器的参数 θ,使得生成的图片 x = G(s; θ) 在判别器的眼里更像真的。
对于任意一个随机生成的向量 s,应该改变 θ,使得判别器的输出尽量接近 1
可以用如下函数作为loss function:

我们希望此时D(x;Φ)越大越好,也就是E(s;θ)越小越好
所以我们用梯度下降来更新生成器的θ![]()
1.4 训练判别器
- 判别器的本质是个二分类器,它的输出值
判别器的训练如下图所示。
- 从真实数据集中抽取一个样本,记作
。
- 再随机生成一个向量 s,用生成器生成
- 训练判别器的目标是改进参数 ϕ,让
更接近 1(真),让
更接近 0 (假)。
- ——>也就是说让判别器的分类结果更准确,更好区分真实图片和生成的假图片。
此时的损失函数如下所示
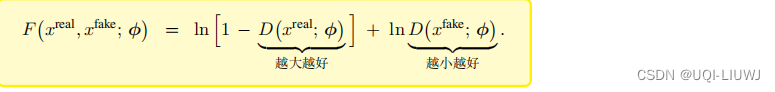
不难发现,判别器越准确,损失函数F越小
所以我们也用梯度下降更新判别器的θ![]()
1.5 整体训练流程
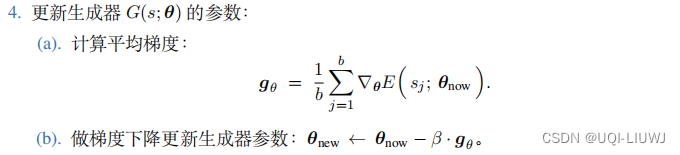
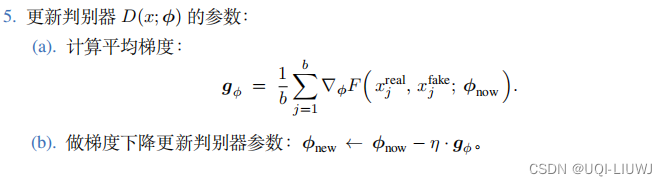
2 生成判别模仿学习 Generative Adversarial Imitation Learning, GAIL
2.1 训练数据
GAIL
的训练数据是被模仿的对象(人类专家)操作智能体得到的轨迹
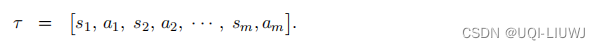
数据集中有
k
条轨迹,把数据集记作:
![]()
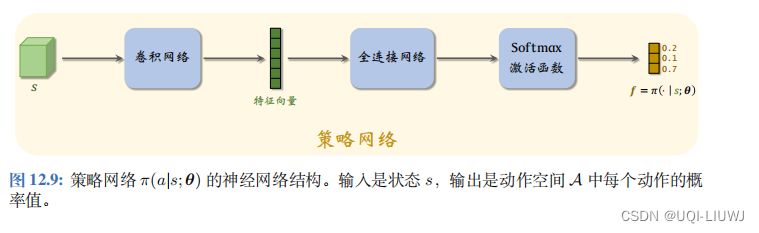
2.2 生成器
GAIL 的生成器是策略网络 π ( a | s ; θ )策略网络的输入是状态 s,输出是一个向量:
输出向量 f 的维度是动作空间的大小 A ,它的每个元素对应一个动作,表示执行该动作的概率。
给定初始状态 s 1 ,并让智能体与环境交互,可以得到一条轨迹:
其中动作是根据策略网络抽样得到的,
下一时刻的状态是环境根据状态转移函数计算出来的
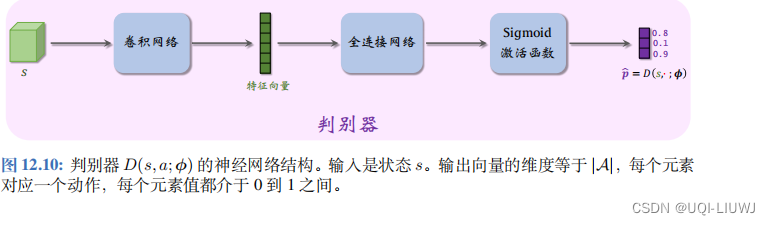
2.3 判别器
GAIL
的判别器记作
D
(
s, a
;
ϕ
)
判别器的输入是状态 s,输出是一个向量:

输出向量
的维度是动作空间的大小 A
,它的每个元素对应一个动作
a
,把一个元素记作:
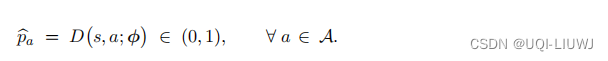
2.4 GAIL的训练
2.4.1 训练生成器
设 是当前策略网络的参数。用策略网络
是当前策略网络的参数。用策略网络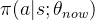 控制智能体与环境交互,得到一条轨迹:
控制智能体与环境交互,得到一条轨迹:
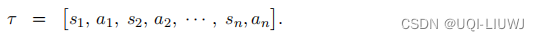
用判别器评价
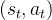 的真实情况,
的真实情况,
 越大,说明
在判别器的眼里越真实。
越大,说明
在判别器的眼里越真实。
我们记第t步的回报为:

于是我们的轨迹可以变成![]()
有不同的方法来更新策略网络的参数θ
在GAIL中,使用的是TRPO
强化学习笔记:置信域策略优化 TRPO_UQI-LIUWJ的博客-CSDN博客
即目标函数为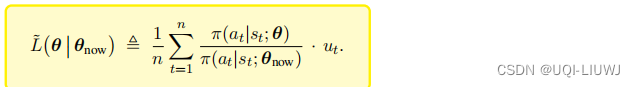
通过解带约束的最大化问题,得到新的参数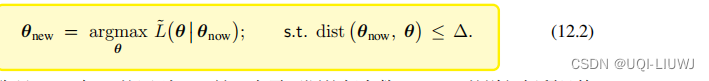
2.4.2 训练判别器
训练判别器的目的是让它能区分真的轨迹与生成的轨迹
我们从训练数据中抽样一条轨迹:
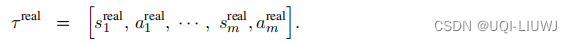
同时用策略网络控制智能体和环境交互,得到另一条轨迹,记作![]()
注意real和fake轨迹的长度可能不一样
同样地,我们希望尽量趋近于1,
尽量趋近于0
于是我们定义损失函数

我们希望损失函数尽量小,也就是说判别器能区分开真假轨迹。可以做梯度下降来更新判别器的参数Φ
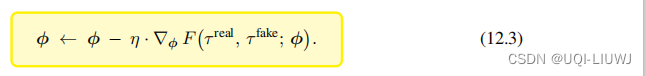
2.4.3 整体训练流程
每一轮训练更新一个生成器,更新一次判别器。训练重复以下步骤,直 到收敛。




















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











