







这里举几个RL的应用场景(当然有更多的)
1 RL & 调参(神经网络结构性参数)
1.1 策略网络
策略网络是一个循环神经网络 (RNN)输入向量 x t 是对上一个超参数做 Embedding 得到的。[ 向量 x 0 是例外; x 0 是用一种特殊的方法随机生成的。]
循环层的向量 h t 可以看做从序列 [ x1 , · · · , x t] 中提取的特征可以把看做第 t 个状态。
策略网 络的输出向量 f t 是一个概率分布。根据 f t 做随机抽样,得到动作 a t ,即第 t 个超参数。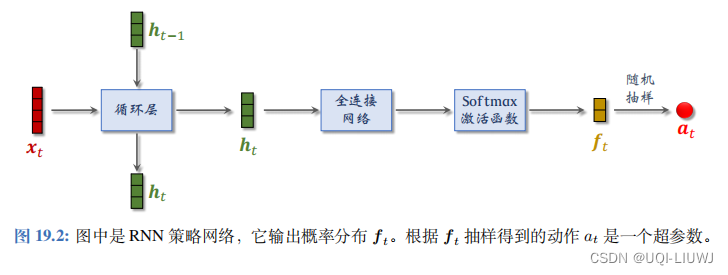
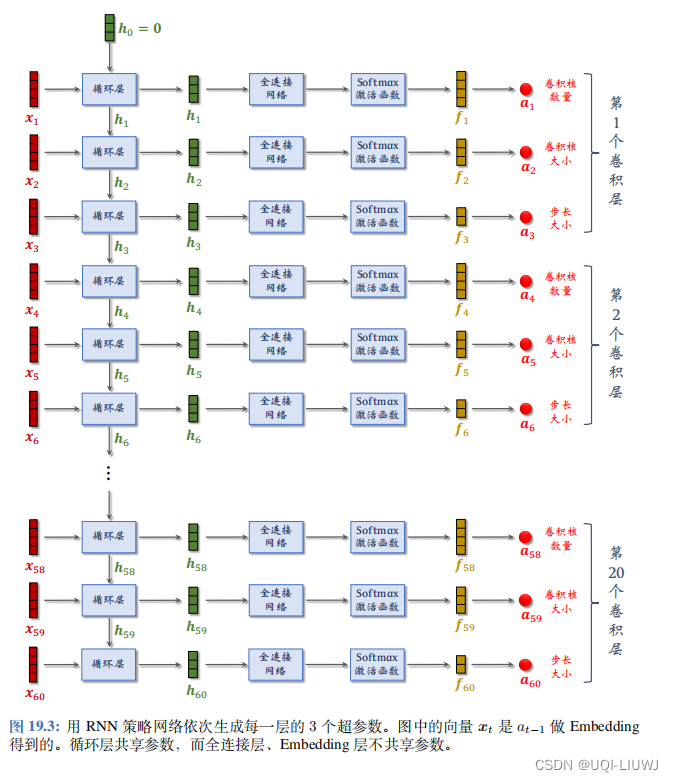
对我们这20个卷积层 ,依次生成每一层的卷积核数量、卷积核大小、步长大小。
在 RNN 运 行 60 步之后,得到 60 个超参数,也就确定了 20 个卷积层的结构。
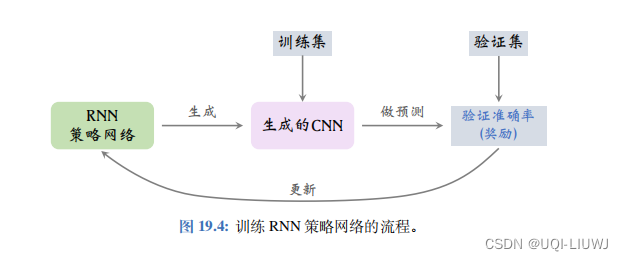
1.1.1 训练策略网络
在前 59 步,奖励全都是零:
然后可以用REINFORCE算法更新策略网络参数θ
强化学习笔记:policy learning_UQI-LIUWJ的博客-CSDN博客
1.2 一定要用强化学习吗?
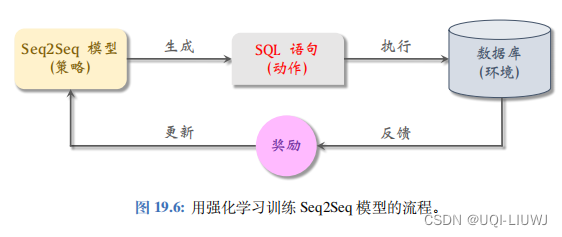
2 RL+SQL 生成
2.1 监督学习的局限性
- 即便两个 SQL 语句高度相似,它们在数据库中执行得到的结果可能完全不同。即便是一个字符的错误,也可能导致生成的 SQL 语法错误,无法执行。
- 哪怕两个 SQL 语句看似区别很大,它们的作用是完全相同的,它们在数据库中执行得到的结果是相同的。
- SQL 的写法会影响执行的效率,而从 SQL 语句的字面上难以看出它的效率。只有真正在数据库中执行,才知道 SQL 语句究竟花了多长时间。
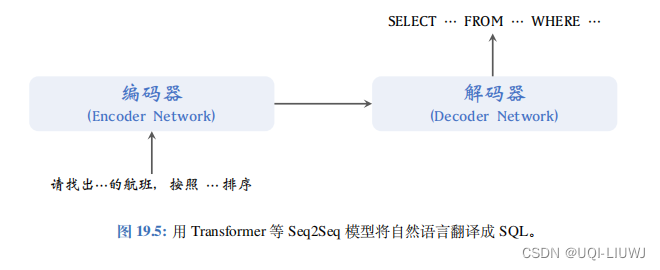
2.2 RL+SQL生成
https://faculty.cc.gatech.edu/~jarulraj/courses/8803-f18/papers/seq2sql.pdf

3 网约车调度
3.0 引子:两个具体的例子
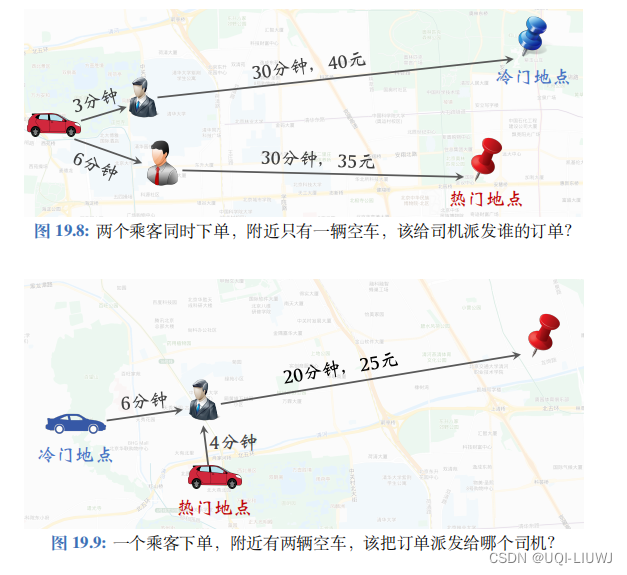
对于图 19.8 中的例子,假如不考虑目的地的热门程度(即附近接单的容易程度),则应该给司机派发上面蓝色目的地的订单,这样可以让司机在较短的时间内取得更高的收入。
但是这样其实不利于司机的总收入:在司机到达冷门地点之后,需要等待较长的时间才会有新的订单。
假如给司机派发下面热门目的地的订单,司机在完成这笔订单后,立刻就能接到下一笔订单;这样虽然单笔收入低,但是总收入高。
对于图 19.9 中的例子,很显然应该把订单派送给冷门地点的司机更合适。热门地点的司机得不到这笔订单几乎没有损失,因为在很短的时间之后就会有新的订单。而这笔订单对冷门地点的司机比较重要,如果没有这笔订单,司机还需要空等很久才有下一笔订单。
3.1 价值学习
3.2 订单派单机制
在学到状态价值函数
之后,可以用它来预估任意地点、时间的网约车的价值,并利用这一信息来给网约车派发订单。
主要想法是用负的 TD 误差来评价一个订单给一个网约车带来的额外收益。
在同一时刻,某区域内有 m 笔订单,有 n 个空车,那么计算所有(订单,空车)二元组的 TD 误差,得到一个 m × n 的矩阵。用二部图 (Bipartite Graph) 匹配算法,找订单—空车的最大匹配,完成订单派发。
简单起见,此处设折扣率 γ = 1,那么TD 目标等于:
可以这样理解 TD 目标:
- 假设给该空车派发该订单,那么该笔订单的价值 r = 40 加上未 来的状态价值,一共等于520.
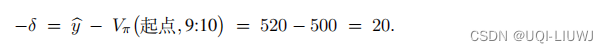
举个例子,在某个区域,当前有 3 笔订单, 有 4 辆空车。计算每个(订单,空车)二元组的 TD 误差,得到图 19.11 中大小为 3 × 4 矩阵。
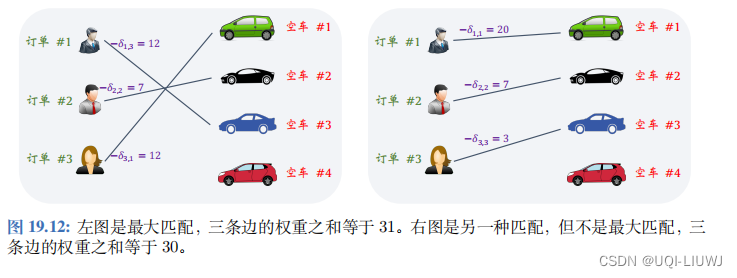
有了上面的矩阵,可以调用二部图匹配算法(比如匈牙利算法)来匹配订单和空车。 图 19.12(左) 是最大匹配,三条边的权重之和等于 31。图 19.12(右) 也是一种匹配方式,但是三条边的权重之和只有 30,说明它不是最大匹配,因此不会这样派发订单。


















 4323
4323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











