







2022arxiv的论文,没有中,但一作是P大图班本MIT博,可信度应该还是可以的
0 摘要
- 深度回归模型通常以端到端的方式进行学习,不明确尝试学习具有回归意识的表示。
- 它们的表示往往是分散的,未能捕捉回归任务的连续性质。
- 在本文中,我们提出了“监督对比回归”(Supervised Contrastive Regression,SupCR)的框架
- 该框架通过将样本与目标距离进行对比来学习具有回归意识的表示。
- SupCR与现有的回归模型是正交的,并且可以与这些模型结合使用以提高性能。
- 在涵盖计算机视觉、人机交互和医疗保健领域的五个真实世界回归数据集上进行的大量实验表明,使用SupCR可以达到最先进的性能,并且始终在所有数据集、任务和输入模式上改进先前的回归基线。
- SupCR还提高了对数据损坏的鲁棒性
- 对减少的训练数据具有弹性
- 改善了迁移学习的性能
- 并且对未见过的目标有很好的泛化能力。
1 介绍
1.1 动机
- 之前的回归问题
- 都集中在以端到端的方式对最终预测进行约束
- 并未明确考虑模型学到的表示
- ——>学习的表示往往是分散的,未能捕捉回归任务中连续的关系

- 图1(a)展示了在从网络摄像头户外图像预测天气温度的任务中,由L1损失学习的表示
- L1模型学习的表示并没有呈现连续的真实温度值;相反,它按不同的摄像头以一种碎片化的方式进行分组。
- 这种无序和碎片化的表示对于回归任务是次优的,甚至可能会妨碍性能,因为其中包含了干扰信息
- L1模型学习的表示并没有呈现连续的真实温度值;相反,它按不同的摄像头以一种碎片化的方式进行分组。
- 之前的表示学习都集中在分类问题上
- 尤其是监督学习和对比学习
- 如图1(b)所示,这些方法在上述视觉温度预测任务中学习的表示对于回归问题来说是次优的
- 因为它忽略了回归任务中样本之间的连续顺序。
1.2 本文思路
- 引入了“监督对比回归”(Supervised Contrastive Regression,SupCR)这一新的深度回归学习框架
- 首先学习一个表示,确保嵌入空间中的距离与目标值的顺序相对应
- 为了学习这样一个具有回归意识的表示,我们根据样本的标签/目标值距离将样本进行对比
- 然后使用这个表示来预测目标值
- 首先学习一个表示,确保嵌入空间中的距离与目标值的顺序相对应
- 方法明确地利用样本之间的有序关系来优化下游回归任务的表示(如1(c)所示)
- 此外,SupCR与现有的回归方法正交
- 可以使用任何类型的回归方法将学习到的表示映射到预测值上。
2 方法
2.0 方法定义
- 学习一个神经网络,由两部分组成
- 特征encoder
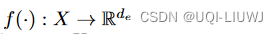
- 预测器
从
中预测
- 特征encoder
- 对于给定的输入 batch,类似于对比学习,首先对数据进行两次数据增强,得到batch的两个view
- 这两个view被输入到编码器f(·)中,为每个增强的输入数据获取一个de维特征嵌入
- 监督对比回归损失
是在这些特征嵌入上计算的
- 为了将学习到的表示用于回归,冻结编码器f(·),然后在其之上训练预测器,使用回归损失(例如,L1损失)
2.1 监督对比回归损失
- 大前提:希望损失函数能够确保嵌入空间中的距离与标签空间中的距离相对应
- 给定N个数据组成的batch ,其中有input和label
- 对该批数据应用数据增强,得到两个视图的batch
- t和t'是两种数据增强方式
- ——>得到两个视图下的batch
- 数据增强后的batch会被喂到encoder中,以获得相应的embedding
- 对该批数据应用数据增强,得到两个视图的batch
- 监督对比回归损失为
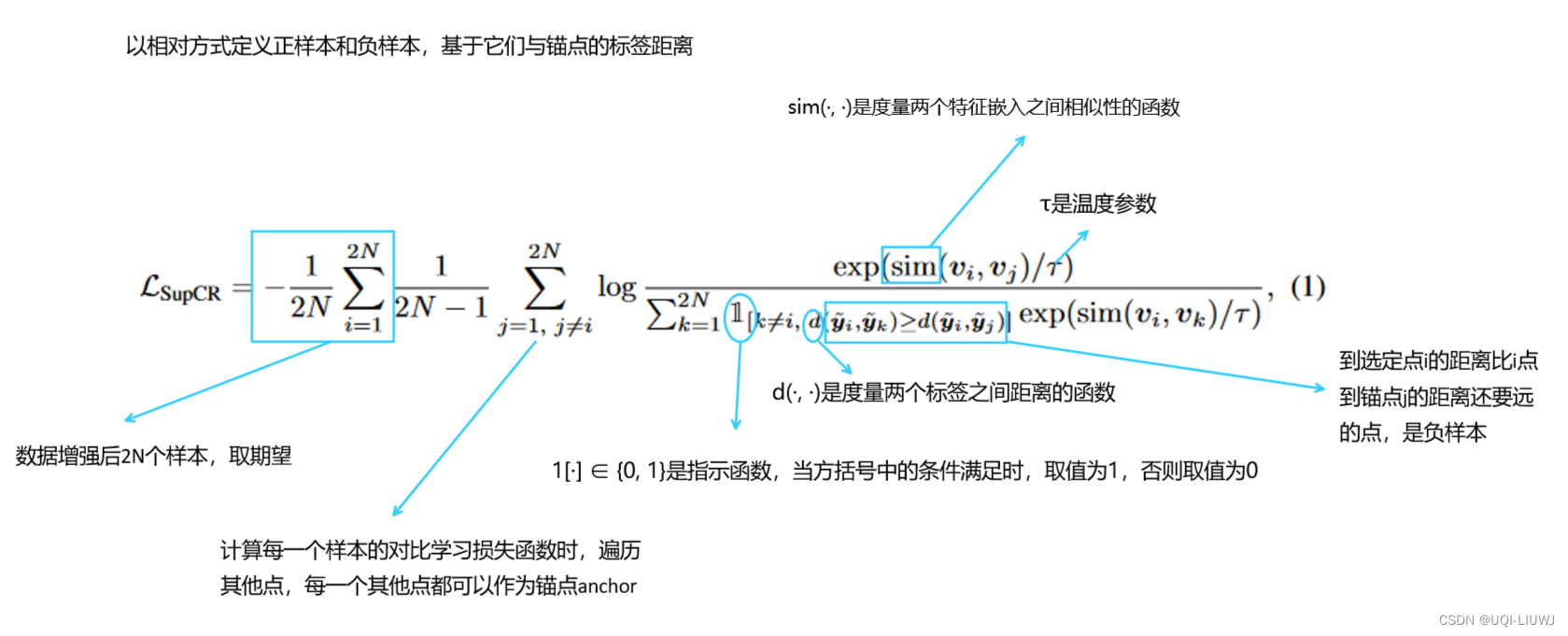
比如我们计算20这个样本的对比学习损失函数时,将30作为anchor的时候,会有两个负样本;将0作为anchor的时候,会有一个负样本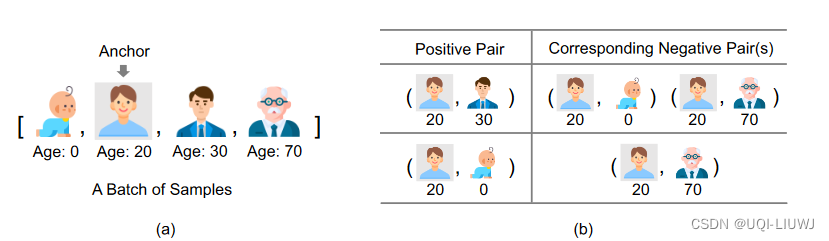
2.2 理论证明
略
3 实验
3.1 五个实验
| AgeDB |
|
| TUAB |
|
| MPIIFaceGaze |
|
| SkyFinder |
|
| IMDB-WIKI |
|
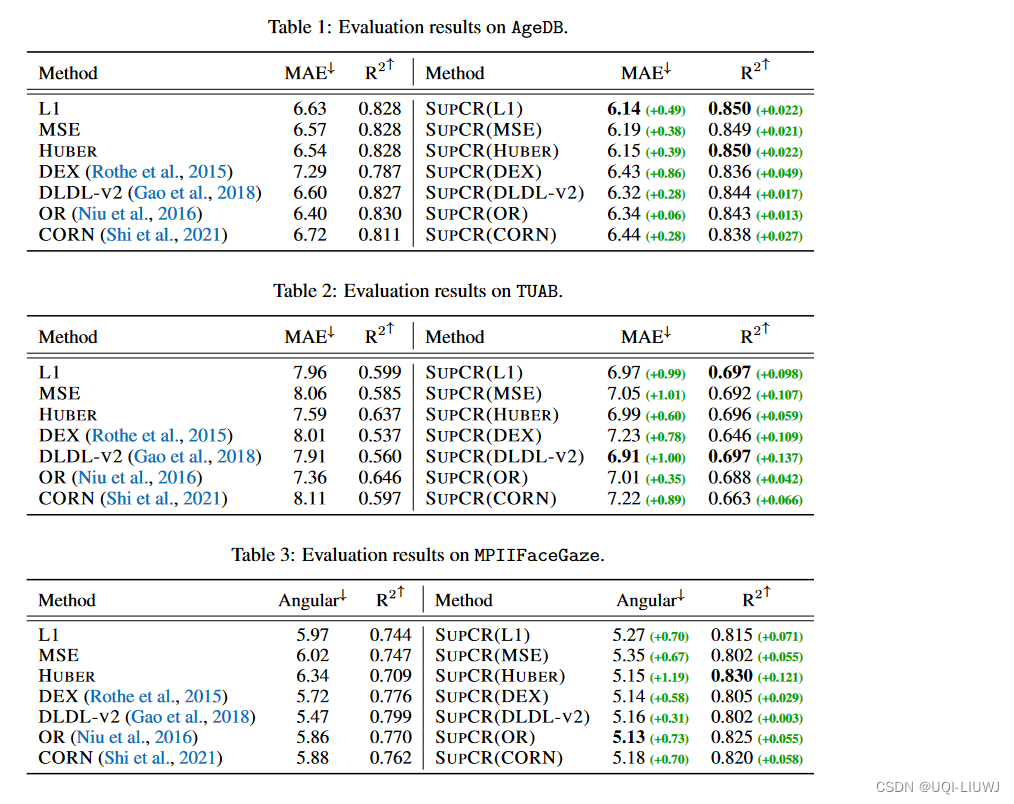
3.2 实验效果
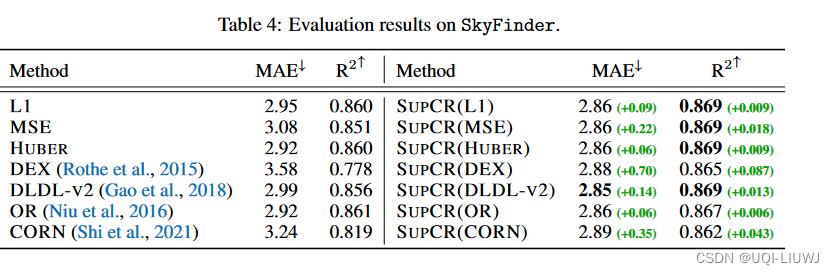
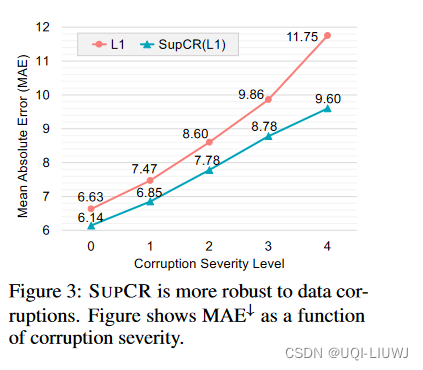
3.3 数据损坏的鲁棒性
使用ImageNet-C基准测试中的损坏生成过程来对AgeDB测试集进行19种不同强度级别的多样化损坏。
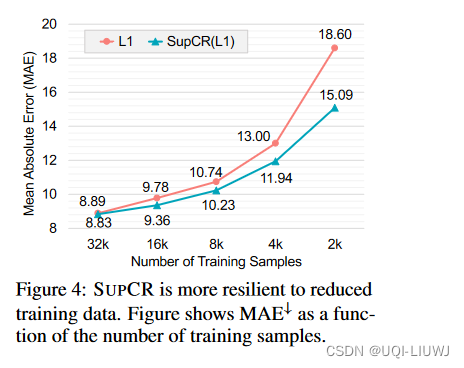
3.4 训练数据的影响


















 1119
1119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











