







LLMs之Leaderboard之MTEB:MTEB(评估和比较不同文本嵌入模型性能的基准测试平台)的简介、使用方法、案例应用之详细攻略
导读:MTEB是一个大规模文本嵌入评估基准,旨在提供一个全面且可靠的文本嵌入模型性能评估平台。
MTEB基准的特点:
>> 多样性:包含8个文本嵌入任务,共计58个数据集,涵盖112种语言。
>> 简单性:采用简单的API接口,只需添加10行代码即可对任何模型进行评估。
>> 可扩展性:支持新的数据集和任务,也欢迎来自社区的贡献。
>> 可重复性:通过数据集和软件版本控制来保证结果的重复性。
方案:文章通过在MTEB基准上评估33个模型,旨在建立文本嵌入领域的另一个里程碑。主要发现为:
>> 没有模型在所有任务上表现优异,不同模型在不同任务上表现不尽相同。
>> 性能与模型规模呈正相关,大模型往往效果更好。
>> Retrieval任务性能与STSk任务差异很大,需区分对称与非对称任务。
>> 针对不同任务开发的模型(如GTR、ST5)性能优于泛化模型(如SimCSE)。
>> 经过监督学习的模型(如GTR、ST5)普遍优于自监督学习模型(如BERT)。
>> 在多语言任务上,MPNet和MiniLM表现更稳定,SGPT-BLOOM依赖先前学习语言。
通过系统和全面的基准测试,该研究对未来文本嵌入研究提供了宝贵参考,帮助选择模型和优化研究方向。
目录
《MTEB: Massive Text Embedding Benchmark》的翻译与解读
4、如何查找Embedding(召回)和Rerank(精选)的最佳搭配?
2、排行榜任务类型(总体表现/双语文本挖掘/分类/聚类/成对分类/重排序/检索/文本语义相似性/摘要/多标签分类/基于指令的检索)
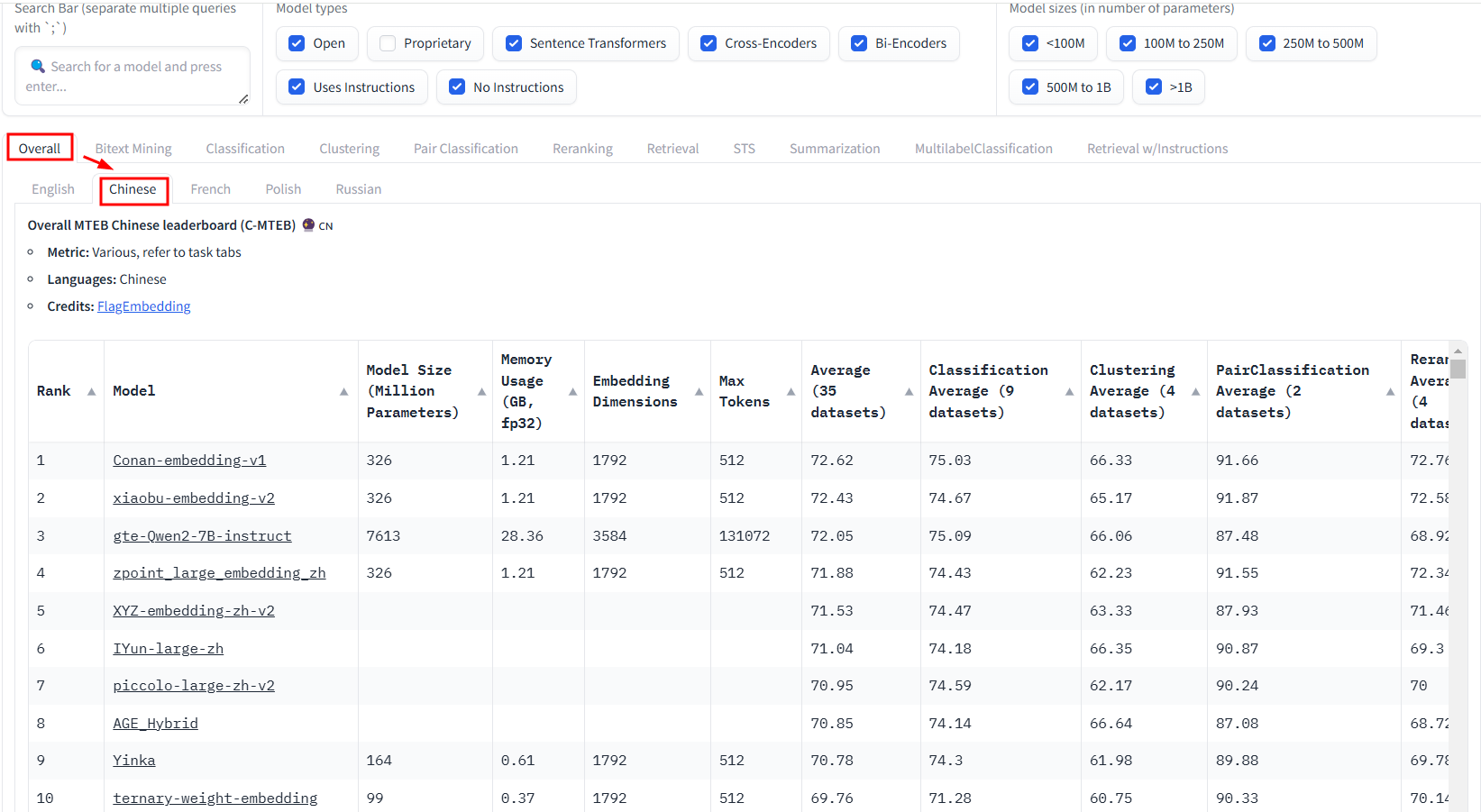
中文:gme-Qwen2、gte-Qwen2-7B-instruct
中文:gte-Qwen1.5-7B-instruct、AGE_Hybrid
中文:xiaobu-embedding-v2、Conan-embedding-v1、zpoint_large_embedding_zh
中文:ListConRanker、Conan-embedding-v1、xiaobu-embedding-v2、zpoint_large_embedding_zh
中文:Yuan-embedding-1.0、Chuxin-Embedding系列
中文:ZNV-Embedding、gte-Qwen2-7B-instruct、Dmeta-embedding-zh、xiaobu-embedding-v2
相关论文
《MTEB: Massive Text Embedding Benchmark》的翻译与解读
| 地址 | |
| 时间 | 2022年10月13日 最新:2023年3月19日 |
| 作者 | Hugging Face等团队 |
| 摘要 | 文本嵌入通常在单一任务的一小部分数据集上进行评估,这些评估并未涵盖其在其他任务中的可能应用。因此,目前尚不清楚在语义文本相似性(STS)上表现最先进的嵌入是否同样适用于聚类或重排序等其他任务。这使得跟踪该领域的进展变得困难,因为各种模型不断被提出,但没有得到适当的评估。为了解决这个问题,我们引入了大规模文本嵌入基准(MTEB)。MTEB覆盖了8个嵌入任务,涵盖了共58个数据集和112种语言。通过对MTEB上的33个模型进行基准测试,我们建立了迄今为止最全面的文本嵌入基准。我们发现,没有一种特定的文本嵌入方法在所有任务中占据主导地位。这表明该领域尚未收敛到一种通用的文本嵌入方法,并且尚未足够规模化以在所有嵌入任务上提供最先进的结果。MTEB附带开源代码和一个公开排行榜。 |
MTEB的简介
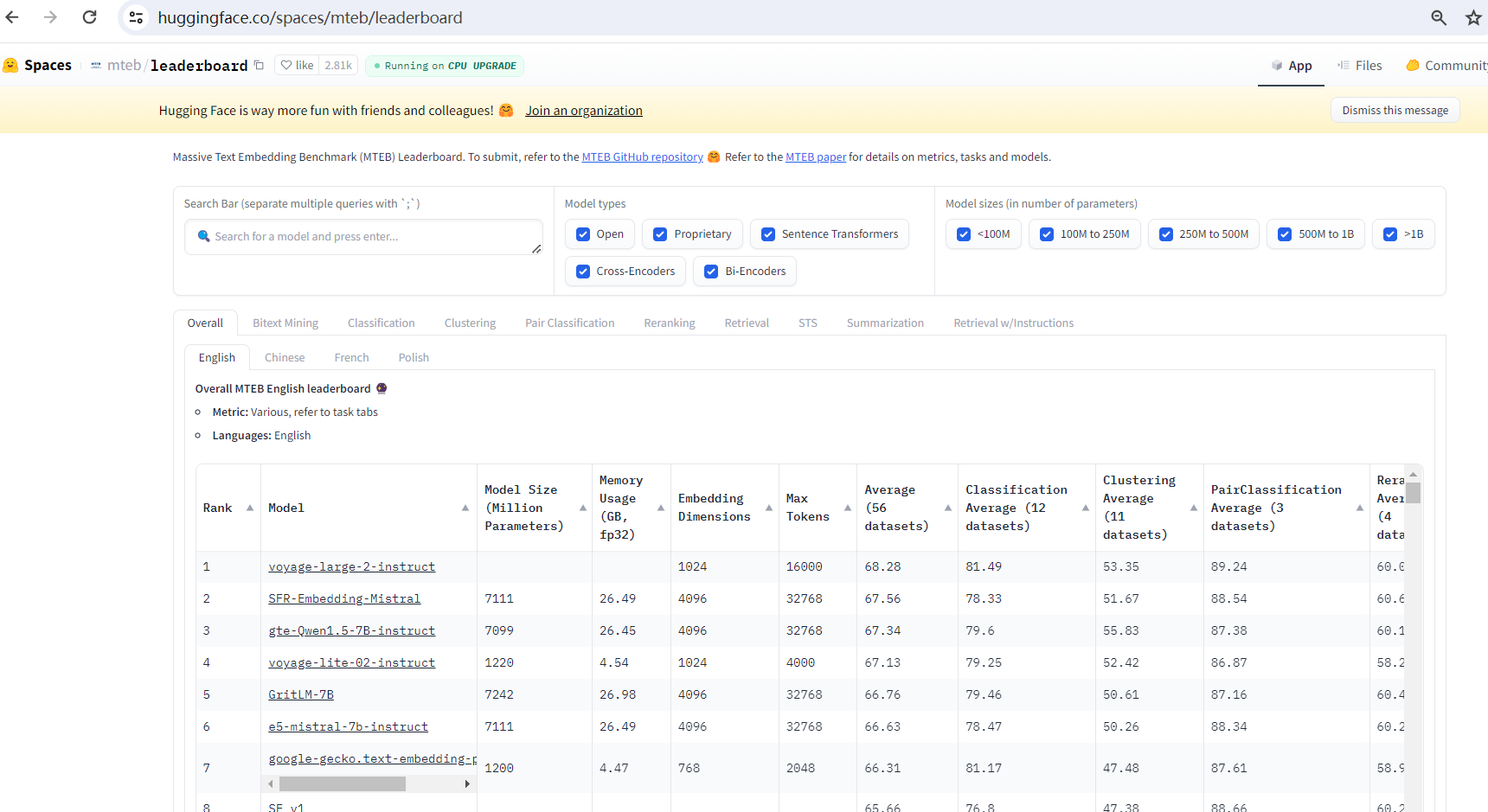
2022年10月13日,Hugging Face正式发布《MTEB: Massive Text Embedding Benchmark》,Massive Text Embedding Benchmark(MTEB)是一个用来评估和比较不同文本嵌入模型性能的基准测试平台。通过MTEB排行榜,可以对比不同向量模型在公开数据集上的表现。
MTEB Leaderboard 是一个 Hugging Face Spaces 应用,用于展示各种多任务文本编码器 (Multi-Task Text Encoder Benchmark, MTEB) 的性能排名。它提供了一个方便的平台,可以比较不同模型在各种自然语言处理任务上的表现。 目前页面显示正在运行中,并提示可以进行 CPU 升级。
MTEB Leaderboard 提供了一个查看多任务文本编码器基准测试结果的平台,但其具体使用方法需要进一步查阅相关文档或访问其运行实例。 目前提供的页面信息有限,仅展示了应用的运行状态和部分统计数据。
注意:这些公开数据集上的表现可能无法完全适用于垂直领域或企业自身的业务领域。因此,在选择向量模型时,仍需结合具体业务特点进行综合比较和权衡。
官方地址:https://huggingface.co/spaces/mteb/leaderboard
1、核心任务
| 任务类别 | 描述 | 评估指标 | 数据集语言 |
| 双语文本挖掘 (Bitext Mining) | 找出两种语言中对应的平行句子 | F1 | 117种语言对(英语及其他语言) |
| 分类 (Classification) | 为文本分配标签(如情感分析、意图分类等) | 准确率 (Accuracy) | 英语等 |
| 聚类 (Clustering) | 将相似的文档归为一类 | 有效性度量 (Validity Measure, v_measure) | 英语等 |
| 成对分类 (Pair Classification) | 判断两个文本是否相似或重复 | 基于余弦相似度的平均精度 (Average Precision based on Cosine Similarities) | 英语等 |
| 重排序 (Reranking) | 重新排序文档列表以提高相关性 | 平均精度 (Mean Average Precision, MAP) | 英语等 |
| 检索 (Retrieval) | 查找与查询相关的文档 | 归一化折扣累积增益 (Normalized Discounted Cumulative Gain @ k, ndcg_at_10) | 英语等 |
| 语义文本相似性 (STS) | 评估句子对之间的相似性 | 基于余弦相似度的斯皮尔曼相关系数 (Spearman correlation based on cosine similarity) | 英语等 |
| 摘要 (Summarization) | 生成文本摘要并评估其质量 | 基于余弦相似度的斯皮尔曼相关系数 (Spearman correlation based on cosine similarity) | 英语等 |
| 指令检索 (Retrieval w/Instructions) | 根据详细指令查找与查询相关的文档 | 成对平均互惠等级 (paired mean reciprocal rank) | 英语等 |
2、MTEB Leaderboard 特点
>> 模型性能排名:主要功能是展示不同模型在 MTEB 基准测试上的排名。
>> 多任务比较:允许用户比较不同模型在多个 NLP 任务上的性能。
>> 实时更新:页面提示正在刷新,暗示排行榜数据可能实时更新。
>> Hugging Face Spaces 应用:基于 Hugging Face Spaces 平台,易于访问和使用。
MTEB的使用方法
通过MTEB,可以测试和比较不同类型和大小的嵌入模型在多种任务上的性能,并根据具体业务需求选择最合适的模型。
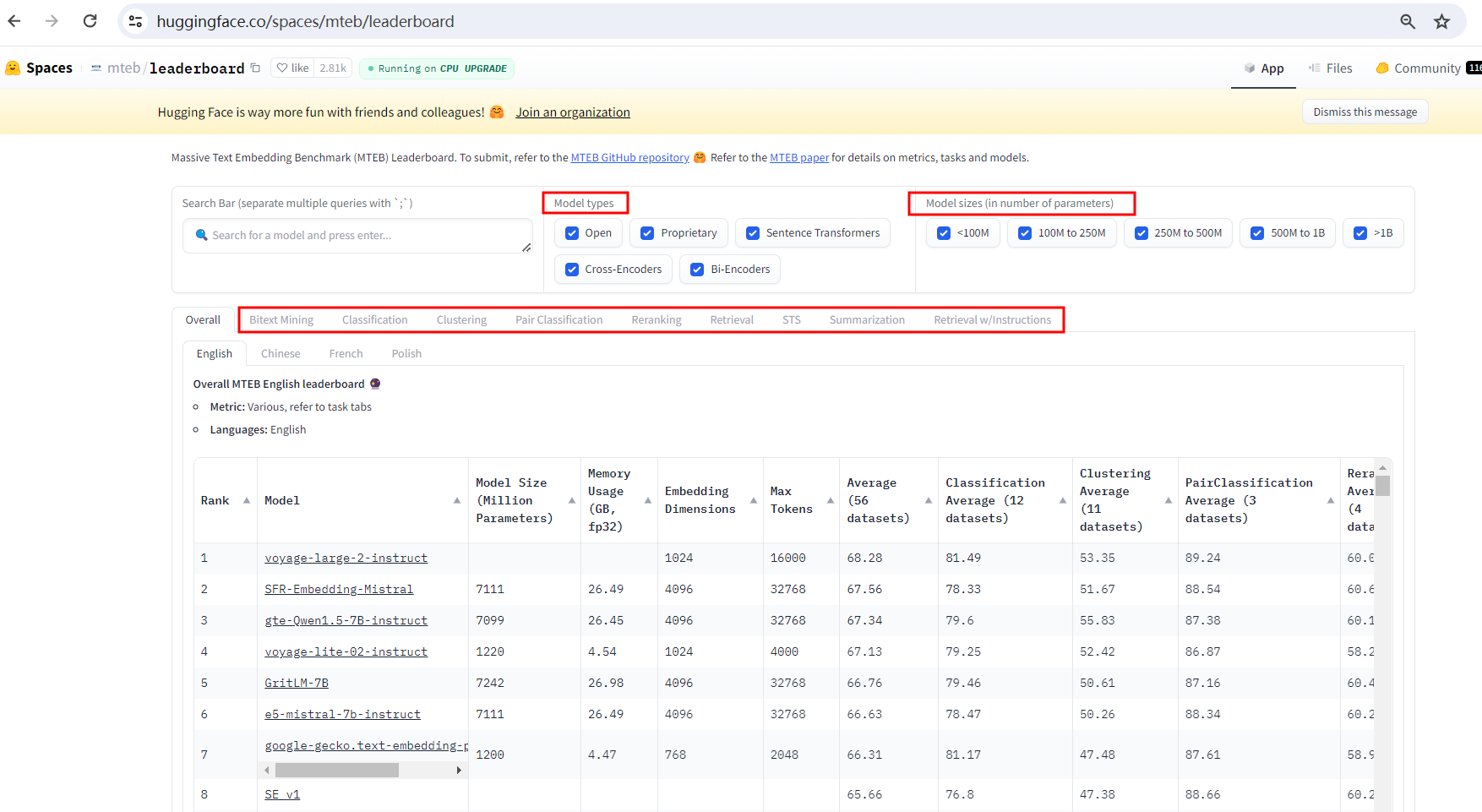
1、语料语言:MTEB的语料涵盖以下语言:
英语(English)
中文(Chinese)
法语(French)
波兰语(Polish)
2、向量模型类型:
开源(Open)
专有(Proprietary)
句子变换器(Sentence Transformers)
交叉编码器(Cross-Encoders)
双编码器(Bi-Encoders)
3、向量模型大小(参数数量):
小于100M(<100M)
100M到250M(100M to 250M)
250M到500M(250M to 500M)
500M到1B(500M to 1B)
大于1B(>1B)
4、如何查找Embedding(召回)和Rerank(精选)的最佳搭配?
中文领域最佳实践组合:Yuan-embedding-1.0与bge-reranker-v2-m3
MTEB Leaderboard 排行榜的内容概览
1、排行榜内容说明
| 模型类型 | 模型类型:开源(Open)、专有(Proprietary)、句子变换器(Sentence Transformers)、交叉编码器(Cross-Encoders)、双编码器(Bi-Encoders)、使用指令(Uses Instructions)、无指令(No Instructions) |
| 模型规模(按参数数量) | <100M、100M~250M、250M~500M、500M~1B、>1B |
| 排行榜任务类型 | 任务类型: >> 双语文本挖掘(Bitext Mining):双语文本挖掘是在两种语言中寻找平行句子的任务。 >> 分类(Classification):分类是为文本分配标签的任务。 >> 聚类(Clustering):聚类是将相似文档分组在一起的任务。 >> 成对分类(Pair Classification):成对分类是确定两个文本是否相似的任务。 >> 重排序(Reranking):重排序是重新排序文档列表以提高相关性的任务。 >> 检索(Retrieval):检索是为查询找到相关文档的任务。 >> 语义文本相似性(STS):语义文本相似度是确定两个文本相似程度的任务。 >> 摘要生成(Summarization):摘要是生成文本摘要的任务。 >> 多标签分类(Multilabel Classification):多标签分类是为文本分配多个标签的任务。 >> 带指令检索(Retrieval w/Instructions):带指令的检索的任务是根据具有详细指令的查询找到相关文档。 |
| 支持的语言 | 英语、中文、法语、波兰语、俄语 |
2、排行榜任务类型(总体表现/双语文本挖掘/分类/聚类/成对分类/重排序/检索/文本语义相似性/摘要/多标签分类/基于指令的检索)
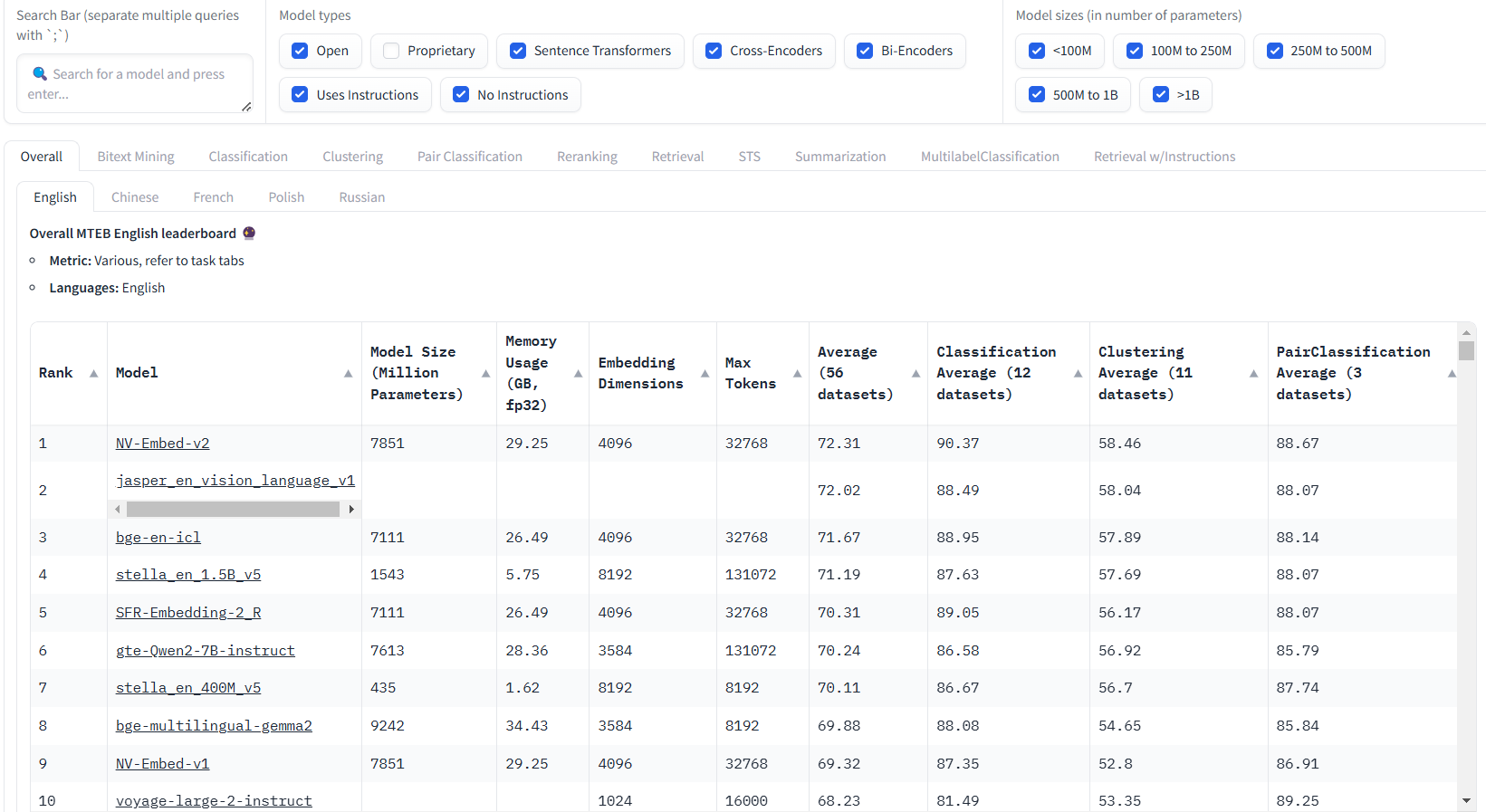
Overall
中文:
英文
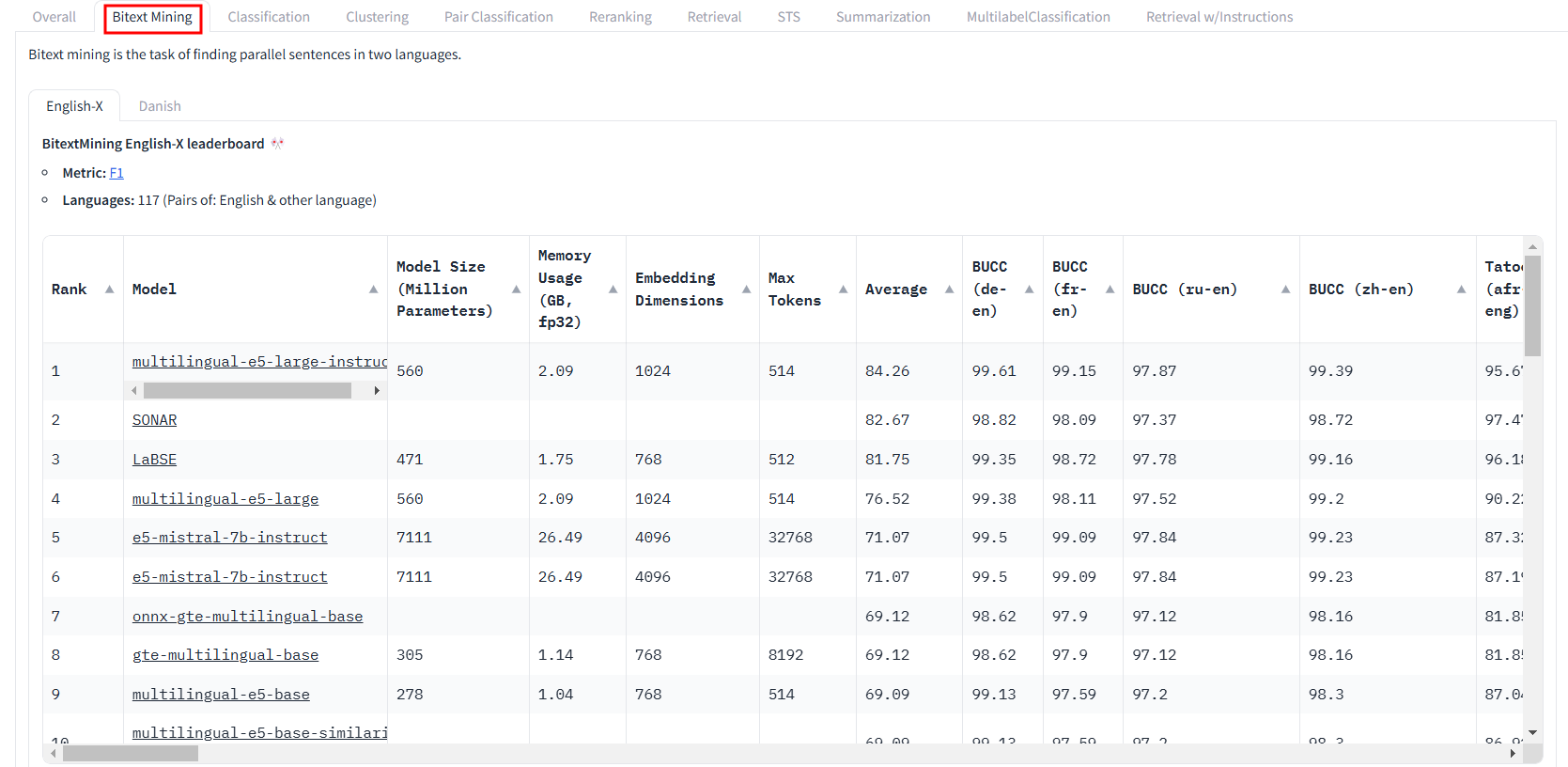
Bitext Mining
英文
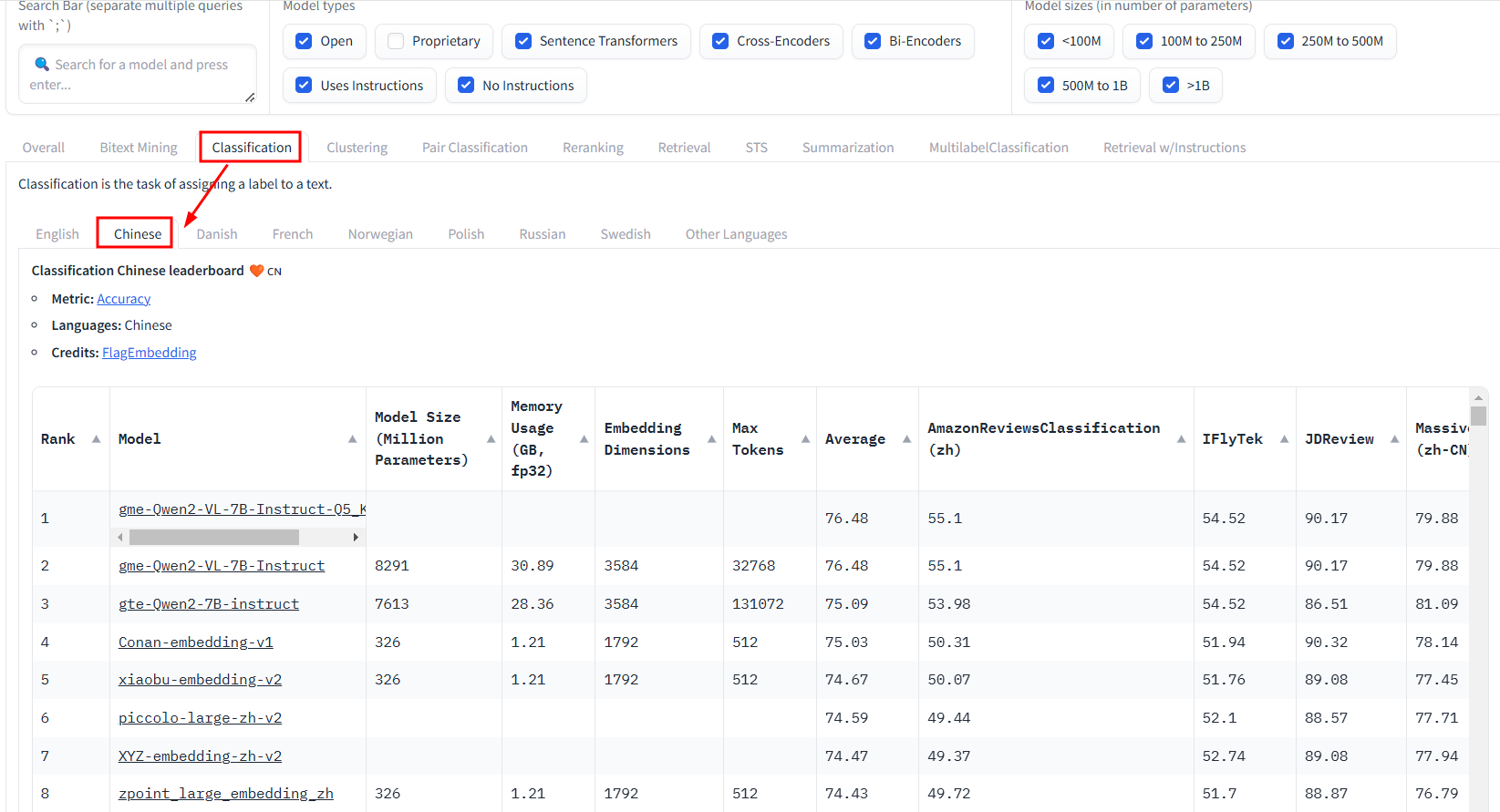
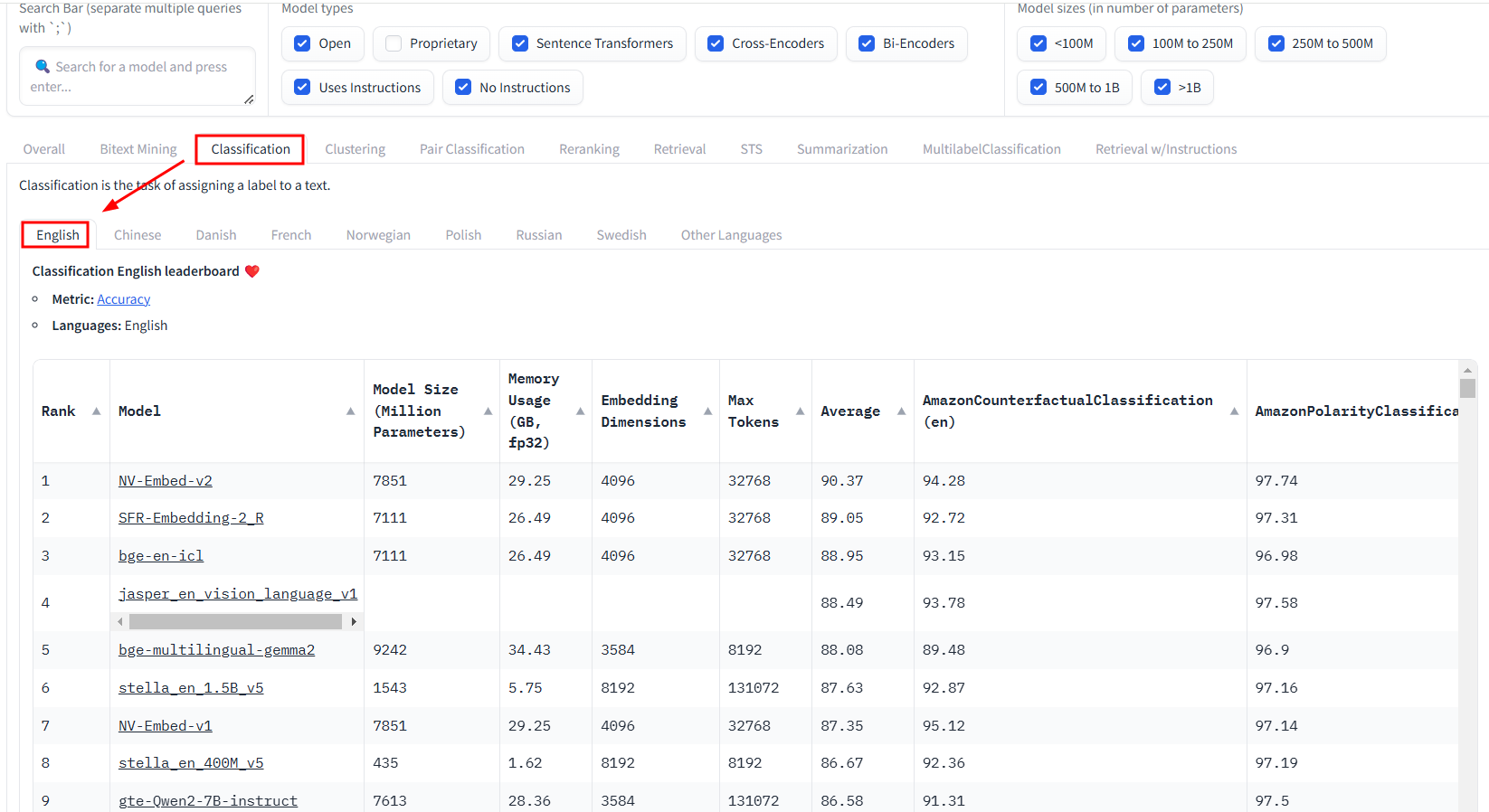
Classification
中文:gme-Qwen2、gte-Qwen2-7B-instruct
英文
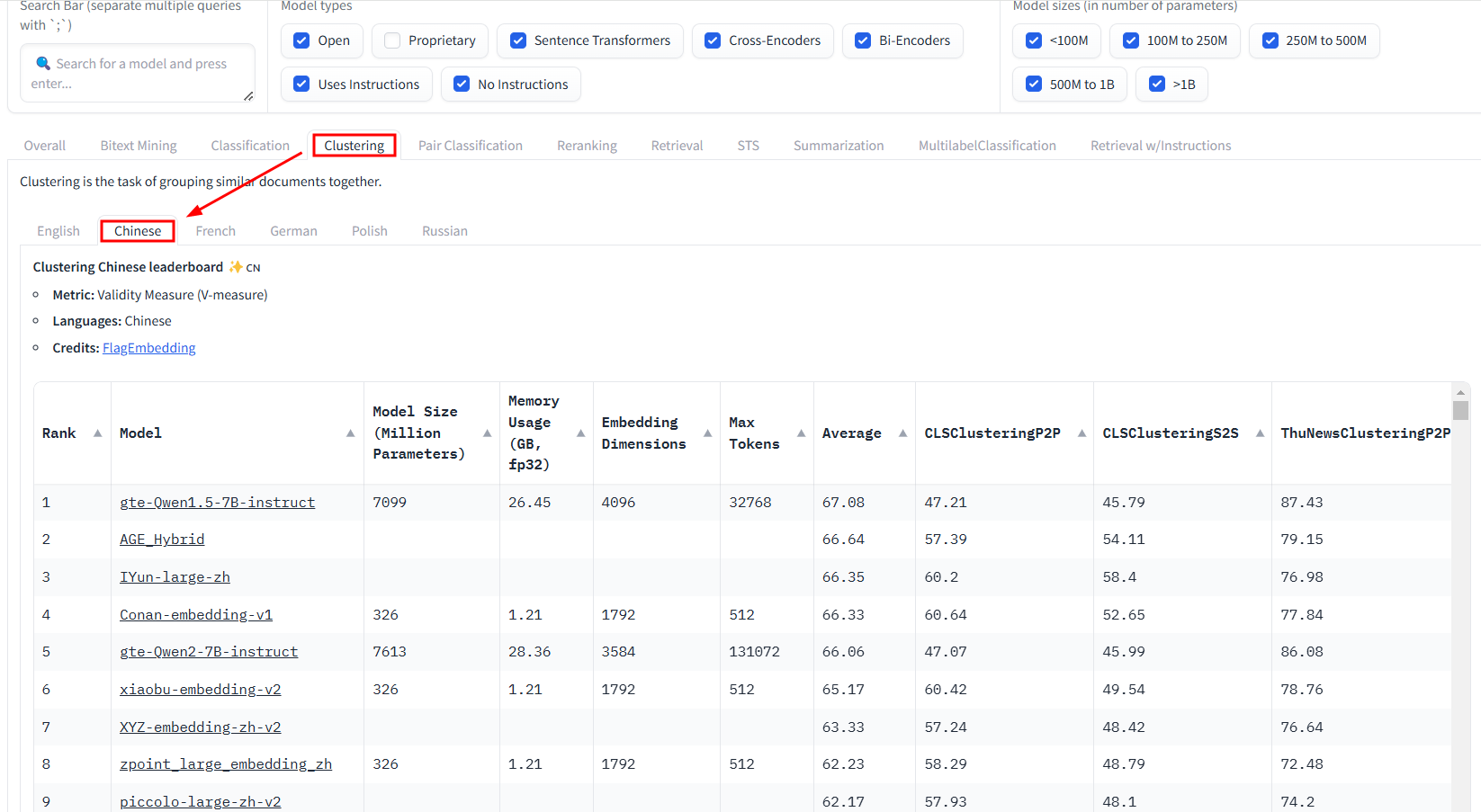
Clustering
中文:gte-Qwen1.5-7B-instruct、AGE_Hybrid
英文
Pair Classification
中文:xiaobu-embedding-v2、Conan-embedding-v1、zpoint_large_embedding_zh
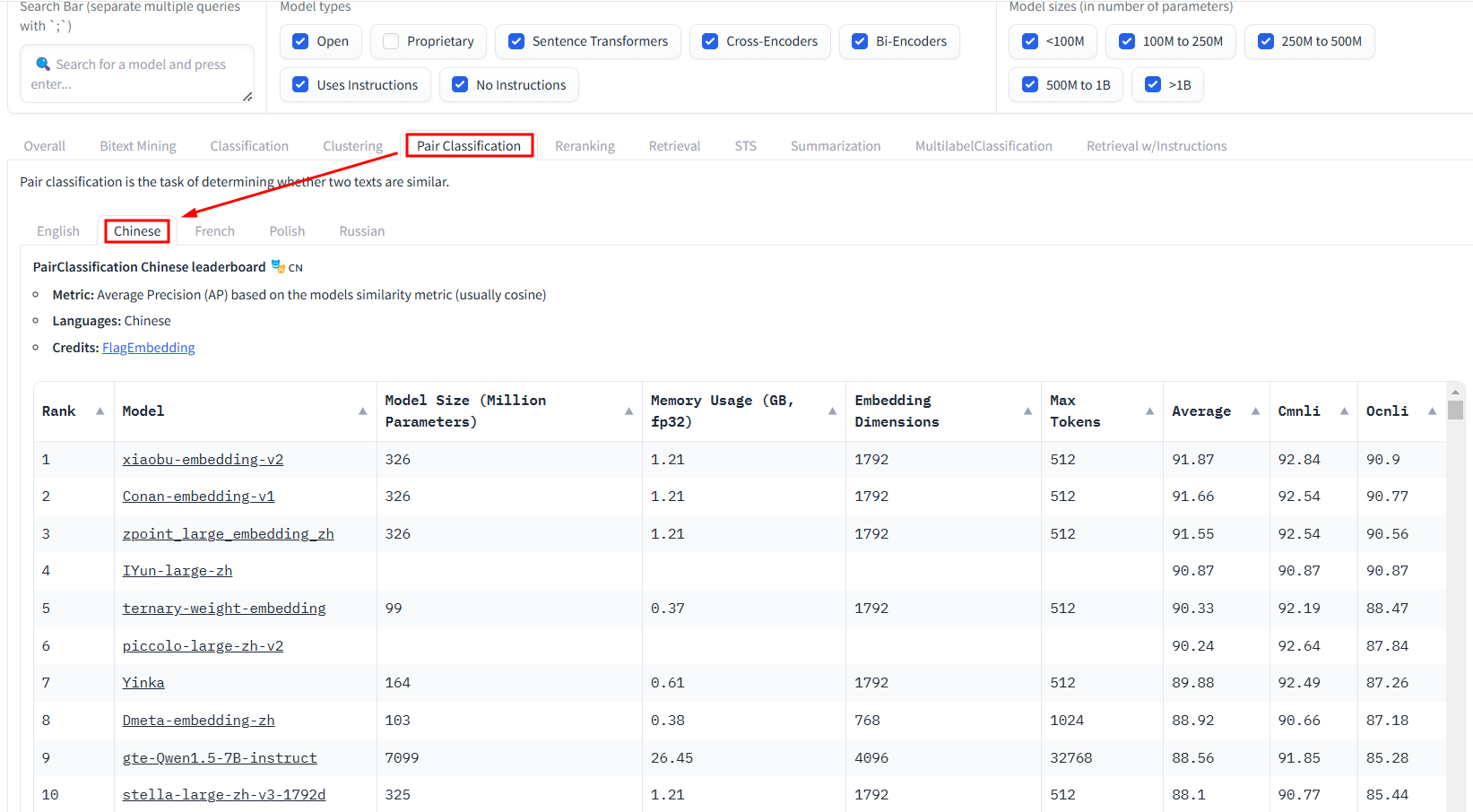
英文
Reranking
中文:ListConRanker、Conan-embedding-v1、xiaobu-embedding-v2、zpoint_large_embedding_zh
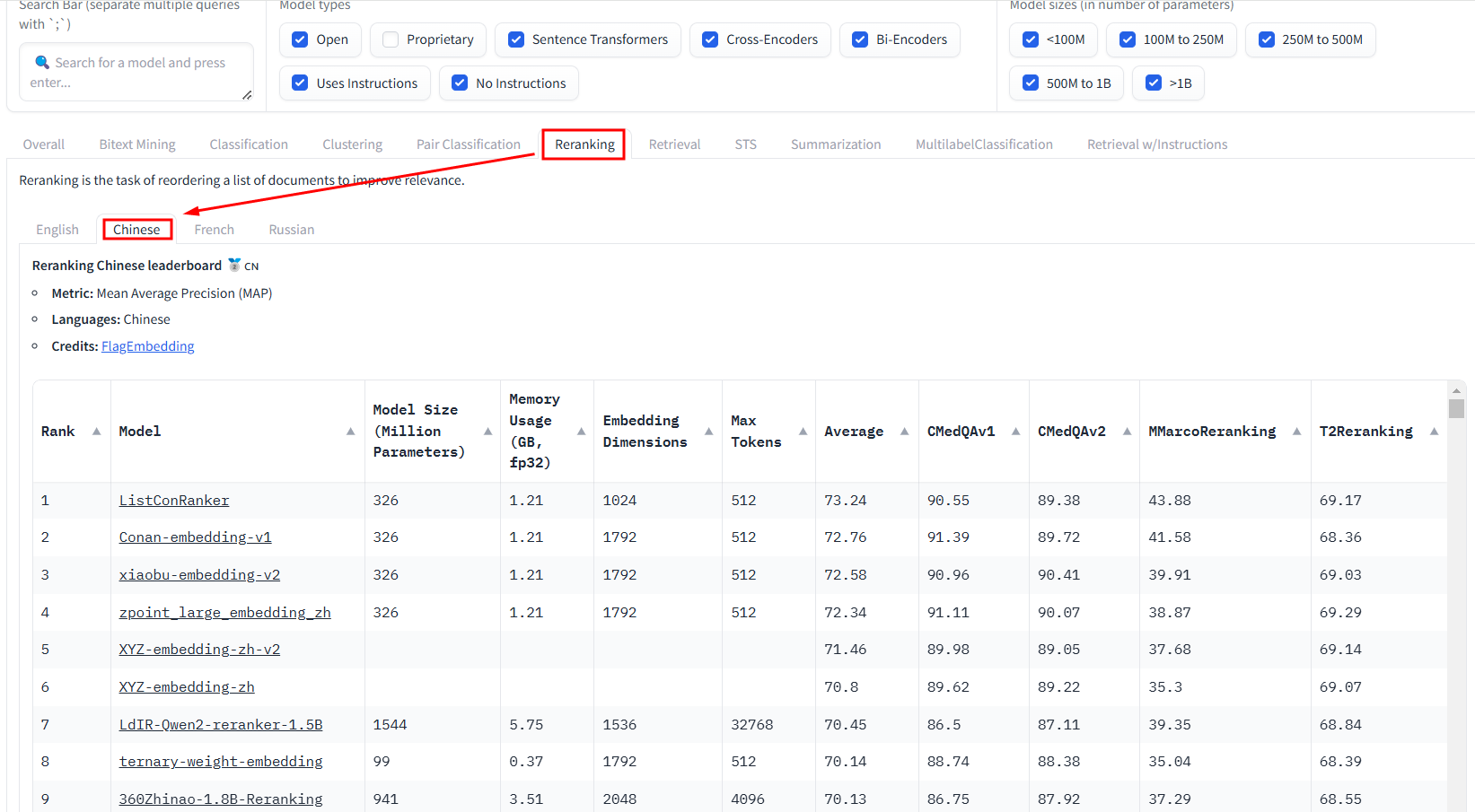
英文
Retrieval
中文:Yuan-embedding-1.0、Chuxin-Embedding系列
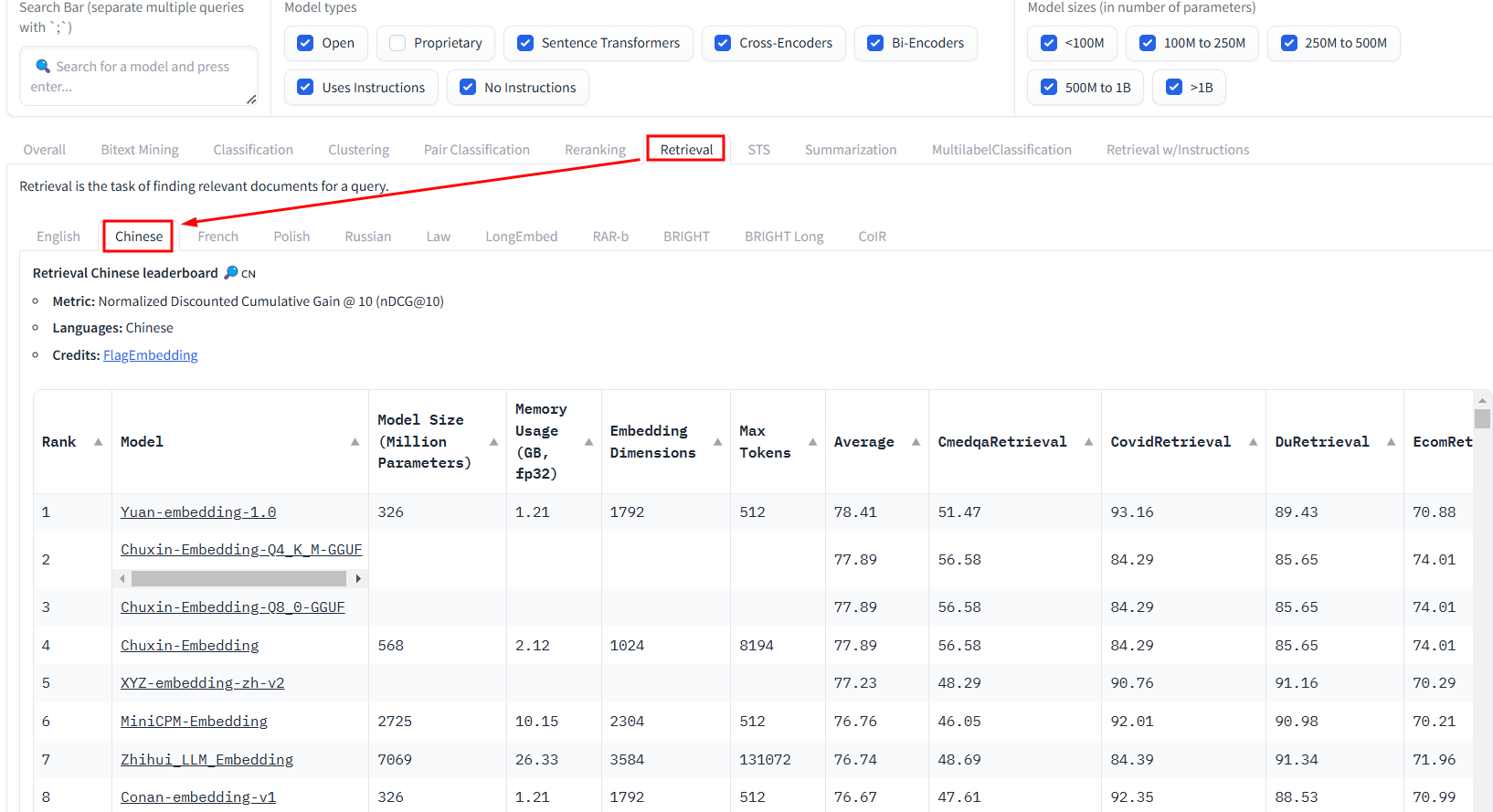
英文
STS
中文:ZNV-Embedding、gte-Qwen2-7B-instruct、Dmeta-embedding-zh、xiaobu-embedding-v2
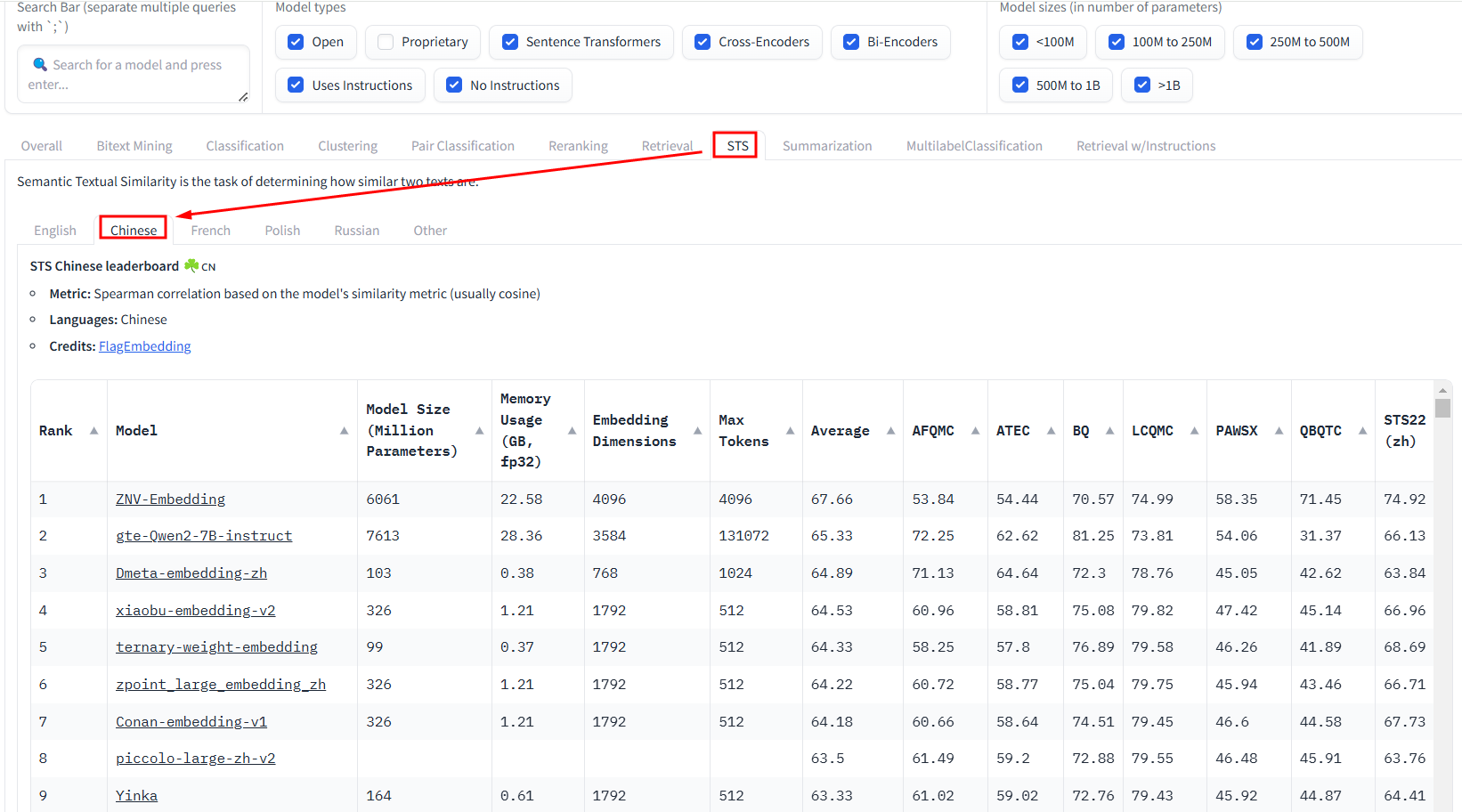
英文
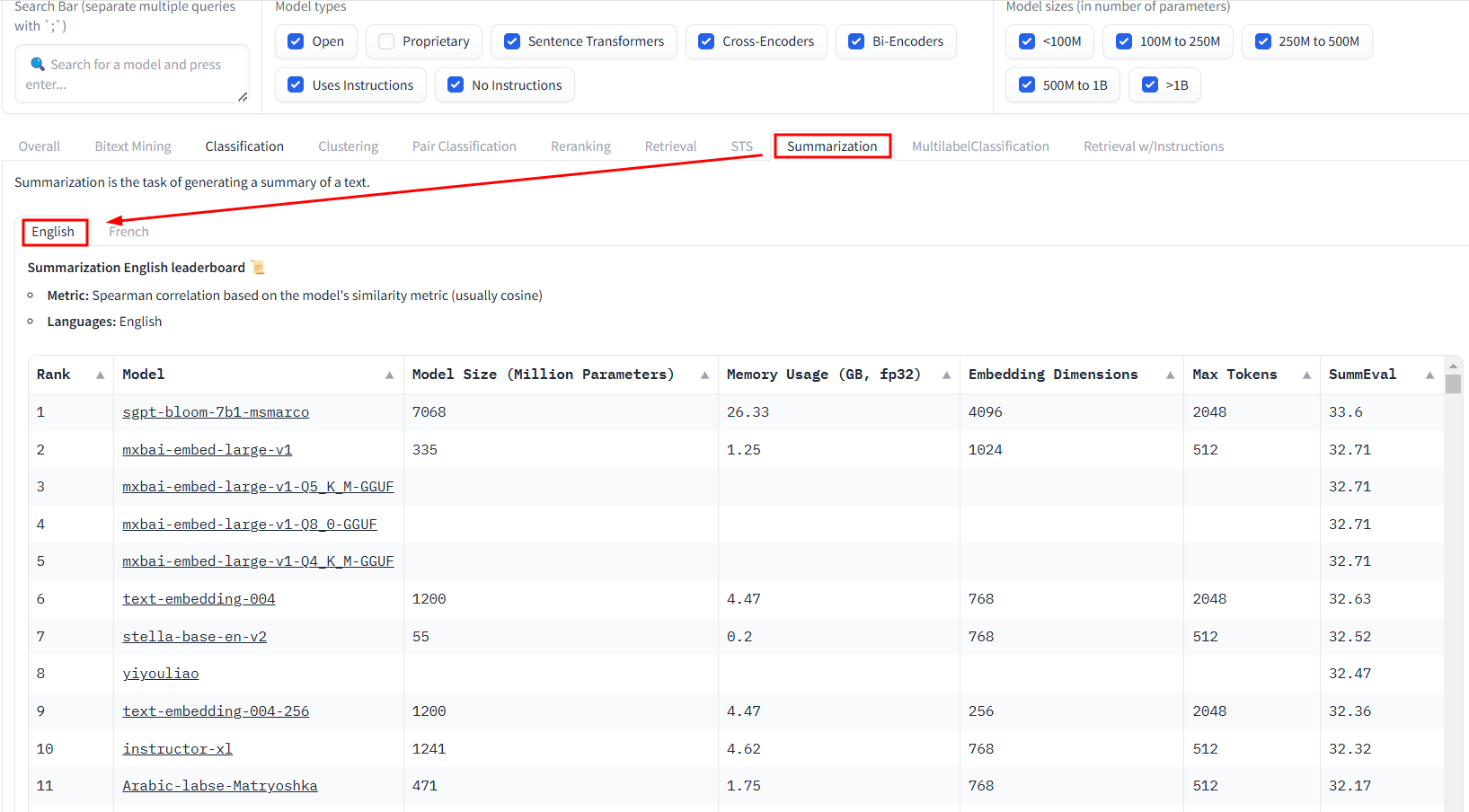
Summarization
英文
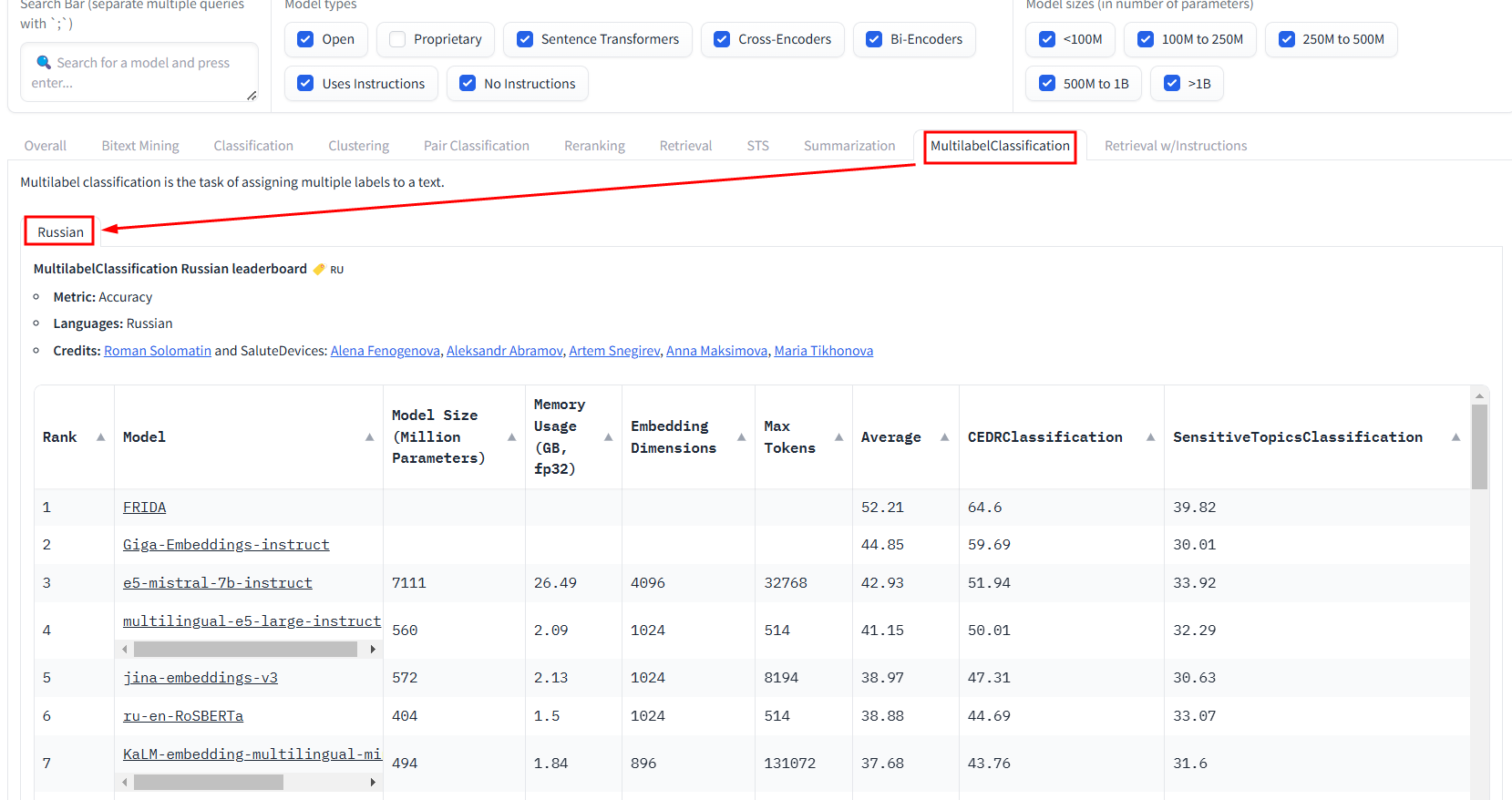
MultilabelClassification
俄文
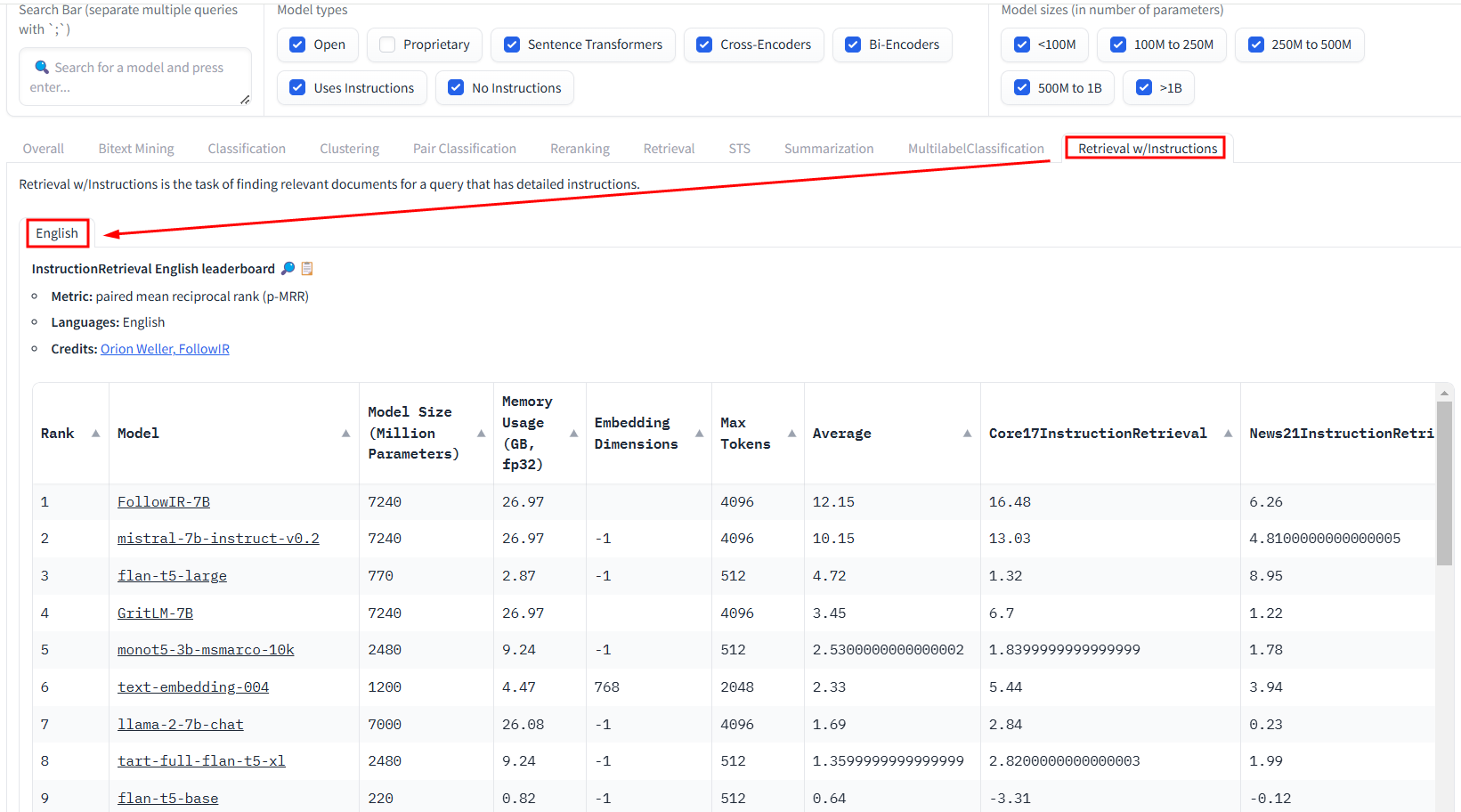
Retrieval w/Instructions
英文



















 4225
4225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











