






MLMs之TableGPT2:《TableGPT2: A Large Multimodal Model with Tabular Data Integration》翻译与解读
导读:这篇论文介绍了TableGPT2,一个大型多模态模型,旨在解决当前大型语言模型(LLM)在处理表格数据方面的不足,并将其应用于商业智能(BI)领域。
>> 背景痛点:论文首先指出,尽管像GPT、Claude、LLaMA和Qwen等模型极大地改变了AI应用,但在许多现实世界领域中起基础性作用的表格数据的整合仍然显著不足。这种差距至关重要,主要基于以下三个原因:
● 数据库或数据仓库的数据整合对于高级应用至关重要:当前的LLM大多无法有效地与外部数据库或数据仓库进行交互,限制了其在需要实时数据或大量数据的应用中的能力。例如,仅依赖LLM进行股票投资建议而无法访问实时市场数据是不可行的。
● 海量未开发的表格数据资源蕴藏着巨大的分析潜力:全球估计超过70%的数据以结构化的表格形式存在,但现有LLM未能充分利用这些数据。
● 商业智能(BI)领域特别需要灵活、精确的解决方案,而许多现有的LLM难以提供:传统的BI系统依赖于固定的查询、静态的数据结构和不灵活的交互方式,LLM虽然有潜力克服这些限制,但仍面临计算效率、无法完全理解表格数据以及与复杂的BI模式和用户需求不匹配等挑战。现有的方法如NL2SQL和常见的表格理解方法在处理大型、复杂且包含噪声的真实世界表格数据时也显得力不从心。
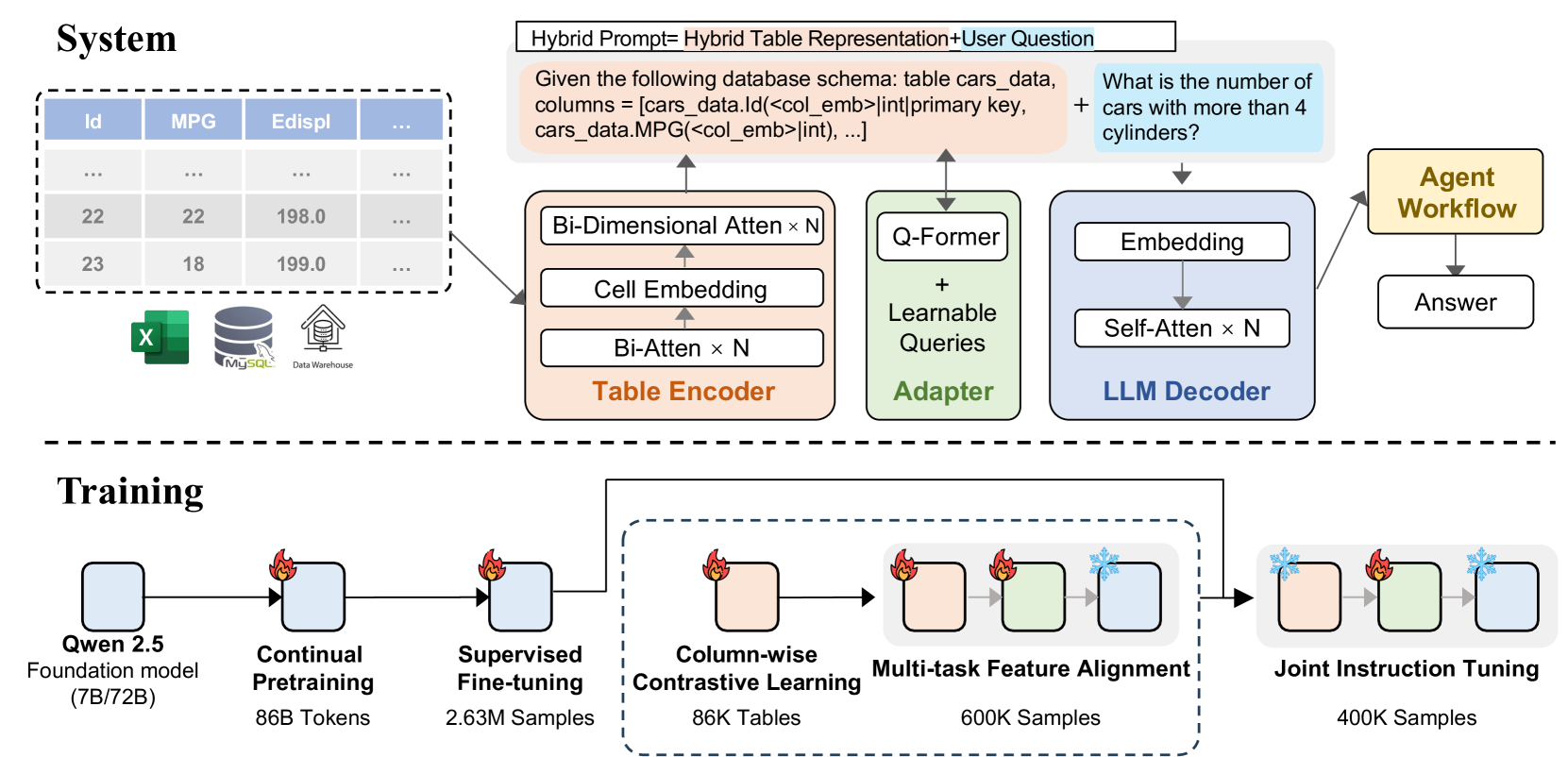
>> 具体的解决方案:为了解决上述痛点,论文提出了TableGPT2模型。TableGPT2的核心创新在于其新颖的表格编码器,该编码器专门设计用于捕获模式级别和单元格级别的信息。这增强了模型处理现实世界应用中常见的模糊查询、缺失列名和不规则表格的能力。类似于视觉语言模型(VLMs),这种开创性的方法与解码器集成,形成一个强大的大型多模态模型。
>> 核心思路步骤:TableGPT2的构建过程包含以下几个关键步骤:
● 基于Qwen的持续预训练(CPT):选择Qwen-2.5作为基础模型,并进行持续预训练,重点增强模型的编码和推理能力。CPT数据包括大量带注释的代码(占比80%)、推理数据和包含领域特定知识的教科书等,总共860亿个token。预训练过程中使用了文档级和token级的过滤策略,并引入了新的方法来处理代码长度和上下文窗口设置。
● 语义表格编码器:设计了一个语义表格编码器,该编码器将整个表格作为输入,为每一列生成一组紧凑的嵌入。该架构针对表格数据的独特属性(例如二维结构、冗余性和稀疏性)进行了调整,并使用了双向注意力机制和列对比学习方法。列嵌入通过Q-former风格的适配器与文本嵌入对齐。
● 基于表格数据的监督微调(SFT):使用超过593.8K个表格和2.36M个高质量的查询-表格-输出三元组进行监督微调,这个规模在之前的研究中是前所未有的。SFT数据包含各种表格相关的任务,例如代码生成(Python和SQL)、表格查询、数据可视化、统计检验和预测建模等,并进行了数据清洗和增强。
● Agent框架:提供了一个全面的Agent工作流程运行时框架,该框架包含运行时提示工程、安全的代码沙箱和Agent评估模块,以确保TableGPT2能够在现实世界中安全可靠地执行复杂的数据分析任务。该框架支持通过模块化步骤(输入规范化、Agent执行和工具调用)执行复杂的数据分析任务。
>> 优势:
● 大规模数据训练:TableGPT2使用了大规模的表格数据进行预训练和微调,这使得它在表格相关的任务上取得了显著的性能提升。
● 新颖的表格编码器:专门设计的表格编码器能够有效地捕获表格的结构和语义信息,从而提高模型处理复杂表格数据的准确性。
● 强大的多模态能力:TableGPT2是一个多模态模型,能够同时处理文本和表格数据,这使得它能够更好地理解和分析现实世界中的数据。
● 全面的Agent框架:提供的Agent框架使得TableGPT2能够轻松地与企业级数据分析工具集成,从而提高其在实际应用中的效率和可靠性。
● 在保持通用能力的同时提升表格处理能力:TableGPT2在表格相关任务上的性能显著提高,同时保持了强大的通用语言和编码能力,避免了在特定任务上的过拟合。
>> 结论和观点:
● TableGPT2在23个基准指标上取得了显著的性能提升,7B模型平均提升35.20%,72B模型平均提升49.32%。
● TableGPT2在处理复杂表格数据方面表现出色,尤其是在HiTab等包含层次结构表格的基准测试中。
● TableGPT2的Agent框架为其在真实世界BI环境中的应用提供了支持。
● 论文提出了一个新的基准数据集RealTabBench,该数据集更加贴近真实世界的应用场景。
● 论文讨论了未来研究方向,包括特定领域的编码、多Agent设计和处理更通用的表格数据等。
总而言之,TableGPT2是一个具有创新性的模型,它在处理表格数据方面取得了显著的进展,并为LLM在BI领域的应用提供了新的可能性。然而,论文也指出了未来需要解决的问题,例如特定领域编码、多Agent设计和处理更通用的表格数据等,这些都为未来的研究提供了方向。
目录
《TableGPT2: A Large Multimodal Model with Tabular Data Integration》翻译与解读
Figure 1:Overall framework of TableGPT2.
8.1、Coding in Specific Domains特定领域编码
8.3、Tables Are Versatile表格的多样性
《TableGPT2: A Large Multimodal Model with Tabular Data Integration》翻译与解读
| 地址 | |
| 时间 | 2024年11月4日 |
| 作者 | 浙江大学 |
Abstract
| The emergence of models like GPTs, Claude, LLaMA, and Qwen has reshaped AI applications, presenting vast new opportunities across industries. Yet, the integration of tabular data remains notably underdeveloped, despite its foundational role in numerous real-world domains. This gap is critical for three main reasons. First, database or data warehouse data integration is essential for advanced applications; second, the vast and largely untapped resource of tabular data offers immense potential for analysis; and third, the business intelligence domain specifically demands adaptable, precise solutions that many current LLMs may struggle to provide. In response, we introduce TableGPT2, a model rigorously pre-trained and fine-tuned with over 593.8K tables and 2.36M high-quality query-table-output tuples, a scale of table-related data unprecedented in prior research. This extensive training enables TableGPT2 to excel in table-centric tasks while maintaining strong general language and coding abilities. One of TableGPT2's key innovations is its novel table encoder, specifically designed to capture schema-level and cell-level information. This encoder strengthens the model's ability to handle ambiguous queries, missing column names, and irregular tables commonly encountered in real-world applications. Similar to visual language models, this pioneering approach integrates with the decoder to form a robust large multimodal model. We believe the results are compelling: over 23 benchmarking metrics, TableGPT2 achieves an average performance improvement of 35.20% in the 7B model and 49.32% in the 72B model over prior benchmark-neutral LLMs, with robust general-purpose capabilities intact. | GPT、Claude、LLaMA 和 Qwen 等模型的出现重塑了人工智能应用,在各行业带来了广泛的新机遇。然而,表格数据的集成仍相对落后,尽管其在众多现实领域中具有基础性作用。这一差距在三个方面尤为关键。首先,数据库或数据仓库数据的集成对于高级应用至关重要;其次,庞大且尚未充分开发的表格数据资源为分析带来了巨大潜力;第三,商业智能领域尤其需要适应性强且精确的解决方案,而许多当前的大型语言模型(LLM)可能难以满足这些需求。 为应对这一问题,我们引入了 TableGPT2,一个经过严格预训练和微调的模型,使用了超过 59.38 万张表格和 236 万条高质量的查询-表格-输出三元组数据进行训练,这是此前研究中前所未有的表格相关数据规模。这一广泛的训练使 TableGPT2 能够在以表格为中心的任务中表现出色,同时保持较强的通用语言和编程能力。 TableGPT2 的关键创新之一是其全新的表格编码器,专门设计用于捕捉模式级和单元级信息。该编码器增强了模型处理模糊查询、缺失列名以及实际应用中常见的非规则表格的能力。类似于视觉语言模型,这一开创性方法与解码器集成,形成了一个强大的大型多模态模型。 我们相信结果是令人信服的:在 23 个基准测试指标上,TableGPT2 在 7B 模型中平均性能提升了 35.20%,在 72B 模型中提升了 49.32%,优于以往的基准中立 LLMs,同时保持了强大的通用功能。 |
1、Introduction
| The emergence of large language models (LLMs) has driven remarkable progress in artificial intelligence (AI), reshaping its applications across various domains. Models like ChatGPT [5] have enhanced the machine’s ability to comprehend and produce human-like language, opening new possibilities in diverse fields. | 大型语言模型(LLM)的出现推动了人工智能的显著进步,重新定义了其在各个领域的应用。诸如 ChatGPT 等模型增强了机器理解和生成类人语言的能力,在不同领域中开辟了新的可能性。 图 1:TableGPT2 的总体框架。 |
Figure 1:Overall framework of TableGPT2.
Outlook展望
| In this article, we introduced TableGPT2, a model designed to address the integration of large language models (LLMs) into business intelligence (BI) workflows. However, despite achieving state-of-the-art (SOTA) performance in our experiments through careful design and implementation, TableGPT2 does not yet fully resolve the challenges of deploying LLMs in real-world BI environments. While significant progress has been made, there are still gaps that need to be addressed before it can be reliably used in production systems. In this section, we discuss some key techniques and approaches that could help bridge this gap. | 在本文中,我们介绍了 TableGPT2,一种旨在将大型语言模型(LLM)集成到商业智能(BI)工作流中的模型。然而,尽管通过精心设计和实现,我们的实验取得了最先进的性能(SOTA),但 TableGPT2 还未能完全解决在实际 BI 环境中部署 LLM 所面临的挑战。尽管已取得显著进展,仍存在需解决的差距,以确保其在生产系统中的可靠使用。在本节中,我们讨论了一些可以帮助弥合这一差距的关键技术和方法。 |
8.1、Coding in Specific Domains特定领域编码
| While we utilized Python and SQL data for fine-tuning TableGPT2, specific domains often require specialized coding practices for security and efficiency reasons. For example, some industries employ pseudo-SQL or domain-specific languages (DSLs) designed to limit access or adhere to strict compliance standards. In such cases, it becomes essential to build interpreters dedicated to these specific domains, ensuring that the generated code integrates seamlessly into existing data infrastructures. A key challenge here is enabling LLMs to quickly adapt to enterprise-specific DSLs or pseudo-code. Although LLMs like TableGPT2 can generate code, the question remains: how can we efficiently bridge the gap between LLM-generated code and the specific requirements of enterprise data infrastructures? One possible solution lies in the development of encapsulated programming languages, such as Logic-LM [70], which provide a structured framework that can be tailored to specific use cases. | 虽然我们使用了 Python 和 SQL 数据来微调 TableGPT2,但特定领域通常需要为安全和效率原因采用专门的编码实践。例如,一些行业使用伪 SQL 或领域特定语言(DSL)来限制访问或遵循严格的合规标准。在这种情况下,必须构建专门的解释器,以确保生成的代码能无缝集成到现有的数据基础设施中。 一个关键挑战是使 LLM 能够快速适应企业特定的 DSL 或伪代码。尽管像 TableGPT2 这样的 LLM 能生成代码,问题仍然是:如何有效地缩小 LLM 生成的代码与企业数据基础设施的具体要求之间的差距?一个可能的解决方案是开发封装的编程语言,如 Logic-LM 提供的结构化框架,可以根据特定用例进行定制。 |
| In previous version of TableGPT2 [18], we adopted a mixed output approach that combines both structured DSL output and standard programming code. The generation of this hybrid output was guided by prompt templates, and further reinforced during the supervised fine-tuning (SFT) process. This allowed the model to fluidly produce both structured and unstructured code, offering flexibility while maintaining the structure needed for domain-specific applications. These domain-specific languages offer several benefits, such as better interpretability, and allowing users to interact more directly with the LLM’s output through a user-friendly interface. Additionally, these languages can lead to safer and more robust solutions by minimizing potential security risks and errors. However, this encapsulation can limit the flexibility of the code, as it is constrained within predefined structures. In conclusion, coding in production environments goes beyond simple code generation. It requires careful consideration of domain-specific needs, infrastructure compatibility, and the ability to strike a balance between flexibility and safety, especially when using mixed approaches of DSL and general-purpose code. | 在 TableGPT2 的先前版本中,我们采用了一种混合输出的方法,结合了结构化 DSL 输出和标准编程代码。这种混合输出的生成由提示模板引导,并在监督微调(SFT)过程中得到了进一步加强,使模型能够流畅地产生结构化和非结构化代码,为特定领域的应用提供灵活性,同时保持所需的结构性。 这些领域特定语言具有多个优势,例如更好的可解释性,允许用户通过用户友好的界面更直接地与 LLM 的输出交互。此外,这些语言可以通过最小化潜在的安全风险和错误,带来更安全和稳健的解决方案。然而,这种封装会限制代码的灵活性,因为它被预定义结构所约束。 总之,生产环境中的编码不仅是简单的代码生成,还需要对特定领域需求、基础设施兼容性以及在 DSL 和通用代码之间找到灵活性与安全性的平衡的仔细考量。 |
8.2、Multi-agent Design多代理设计
| Although TableGPT2 achieves state-of-the-art performance in table-related tasks, we still cannot yet expect a single end-to-end LLM to fully solve complex, real-world problems independently. Recently, we have been closely following a new line of research focused on automated agency design [71], which builds on the principles to automate the orchestration of LLM workflows. In this approach, several LLMs are organized into a directed acyclic graph (DAG) structure, such that the input queries are automatically routed through a sequence of LLMs by the topological order of the graph. Each LLM performs a specialized functionality. The flow through the DAG is determined by the system itself, making decisions about which LLMs to involve based on the task at hand. These models may vary in their system prompt templates, retrieval-augmented generation (RAG) configurations, in-context learning (ICL) examples, and others. This automated flow engineering creates a flexible, modular pipeline that adjusts dynamically based on the problem’s requirements, much like how AutoML systems automatically configure machine learning models for optimal performance. | 尽管 TableGPT2 在表格相关任务中达到了最先进的性能,但我们仍不能期望单一的端到端 LLM 能够独立完全解决复杂的实际问题。近期,我们密切关注了一种基于自动化代理设计的新研究,这种设计基于自动化协调 LLM 工作流的原则。在这种方法中,多个 LLM 被组织成一个有向无环图(DAG)结构,以便输入查询自动按照图的拓扑顺序通过一系列 LLM。每个 LLM 执行一种特定功能,系统本身根据任务的需求决定涉及哪些 LLM。模型在系统提示模板、增强生成(RAG)配置、上下文学习(ICL)示例等方面各不相同。这种自动化流程工程创建了一个灵活的、模块化的管道,能够根据问题的要求动态调整,类似于 AutoML 系统为优化性能而自动配置机器学习模型。 |
| For example, in our small app designed for equity and fund recommendations via natural language, we needed to connect the LLM with real-time market data. In this multi-agent architecture, we generally assign distinct roles to different LLMs, each fine-tuned (SFT-ed) on data specifically tailored to its function. One LLM is dedicated to precise intent recognition, trained with datasets focused on understanding user queries and intents. Another LLM is specialized in code generation, data interaction, and tool invocation. A third LLM handles domain-specific and in-depth analysis, fine-tuned on industry-specific datasets to ensure expertise in the relevant field. Each LLM is further configured with distinct prompt templates and retrieval-augmented generation (RAG) setups for the input, while varied coding or conversation logic is applied to the output stage. This tailored fine-tuning at each stage ensures that the overall pipeline delivers precise, accurate, and context-aware responses, addressing the complex nature of real-world applications. | 例如,在我们为股权和基金推荐设计的小型应用中,我们需要将 LLM 连接到实时市场数据。在这种多代理架构中,我们通常为不同的 LLM 分配不同的角色,每个 LLM 都在特定功能的数据上进行微调(SFT)。一个 LLM 专门用于精确意图识别,使用聚焦于理解用户查询和意图的数据集进行训练。另一个 LLM 专门负责代码生成、数据交互和工具调用。第三个 LLM 负责领域特定和深入分析,基于行业特定数据集进行微调,以确保其在相关领域的专业性。每个 LLM 的输入配置了不同的提示模板和增强生成(RAG)设置,而在输出阶段应用了不同的编码或对话逻辑。这种在每个阶段的专门微调确保了整个管道提供准确、精确且具备上下文意识的响应,解决了实际应用的复杂需求。 |
| Indeed, while there is ongoing speculation that a single foundation model with sufficiently advanced capabilities might eventually replace the need for chaining multiple models, this remains largely theoretical. Such a model would possess enough general-purpose intelligence to handle various tasks within a unified framework. However, based on our experience with specialized projects, we typically require more than two LLMs to address the full complexity of real-world applications. Just as MetaGPT [72] suggests, unified models are promising in their design, but it is evident that for now, one LLM is not sufficient to manage the intricacies of complex workflows. Much like the Qwen and LLaMA model families, where specialized models are developed for tasks such as mathematics or coding, it remains uncertain when a single model can seamlessly solve problems across multiple domains at a high level of proficiency, especially towards production. | 实际上,尽管有单一基础模型具有足够高级的通用能力以处理各种任务的猜测,但这一点仍然主要停留在理论层面。这类模型需具备足够的通用智能以在统一框架中处理各种任务。然而,根据我们在专门项目中的经验,我们通常需要超过两个 LLM 来处理现实应用的全部复杂性。正如 MetaGPT 所建议的,统一模型在设计上具有前景,但显然目前一个 LLM 还不足以管理复杂工作流的细微差别。类似于 Qwen 和 LLaMA 模型系列中为数学或编码任务开发的专用模型,我们尚不确定何时能出现一个单一模型在多个领域内达到高水平的熟练度,特别是面向生产环境。 |
8.3、Tables Are Versatile表格的多样性
| While TableGPT2 primarily focuses on business intelligence (BI) applications, where databases or data warehouses serve as the upstream sources of structured data, another common and unneglectable form of tabular data originates from apps like Apple Pages or Microsoft Excel. These types of tables differ significantly from those in data infrastructures because they often exhibit irregularities. For example, tables in Excel or Pages frequently have merged cells, inconsistent row or column structures, and non-standard data formatting, making them more complex to process. These tables can vary widely in organization, where cells might contain free-form text, be partially filled, or use multi-level headers, making them far less uniform than typical database tables. | 尽管 TableGPT2 主要关注商业智能(BI)应用,在这里数据库或数据仓库是结构化数据的上游来源,另一种常见且不可忽视的表格数据来自 Apple Pages 或 Microsoft Excel 等应用。这类表格与数据基础设施中的表格显著不同,通常具有不规则性。例如,Excel 或 Pages 中的表格经常包含合并单元格、不一致的行或列结构,以及非标准的数据格式,增加了处理难度。这些表格在组织上差异很大,其中单元格可能包含自由格式的文本、部分填充或使用多级标题,使其远不如典型的数据库表格一致。 |
| In the agent workflow where TableGPT2 model resides, we fine-tuned a separate LLM specifically for normalizing irregular tables and integrated it into a holistic system. However, handling these irregular tables still leaves considerable room for improvement, especially given the substantial commercial potential for production use. Thus, we may hypothesize that addressing such irregularities should begin during the pretraining stage to ensure the model becomes adept at handling the wide array of formats that tables can take. Many current LLMs, along with retrieval-augmented generation (RAG) processes, do not adequately process or handle these non-standard table structures. Moreover, many existing pretraining corpora tend to overlook this type of data [73]. This gap presents a valuable opportunity for future research to enhance models capable of effectively processing versatile structured data formats, particularly those widely used, such as Excel and Pages. | 在 TableGPT2 模型所在的代理工作流中,我们专门微调了一个 LLM 用于规范化不规则表格并将其集成到整体系统中。然而,处理这些不规则表格仍有很大改进空间,特别是在商业化生产中的潜力巨大。 因此,我们可以假设,为了确保模型在预训练阶段便能适应表格可能的多种格式,从而处理这种不规则性,应该从预训练阶段开始。目前许多 LLM 以及增强生成(RAG)流程对这些非标准表格结构处理不足。此外,许多现有的预训练语料库往往忽视了此类数据。这一差距为未来研究提供了宝贵的机会,可以开发更擅长处理多样化结构化数据格式的模型,特别是那些被广泛使用的格式,如 Excel 和 Pages。 |



















 387
387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











