










AI之GPU:GPUStack的简介、安装和使用方法、案例应用之详细攻略
目录
4、支持的加速器:Apple Metal/NVIDIA CUDA/Ascend CANN等
5、支持的模型:LLMs以及重排序模型/VLLMs/扩散模型/音频模型
案例二:使用stable-diffusion-v3-5-large-turbo模型生成图像
T2、使用OpenAI Python API库来使用这些API
GPUStack简介
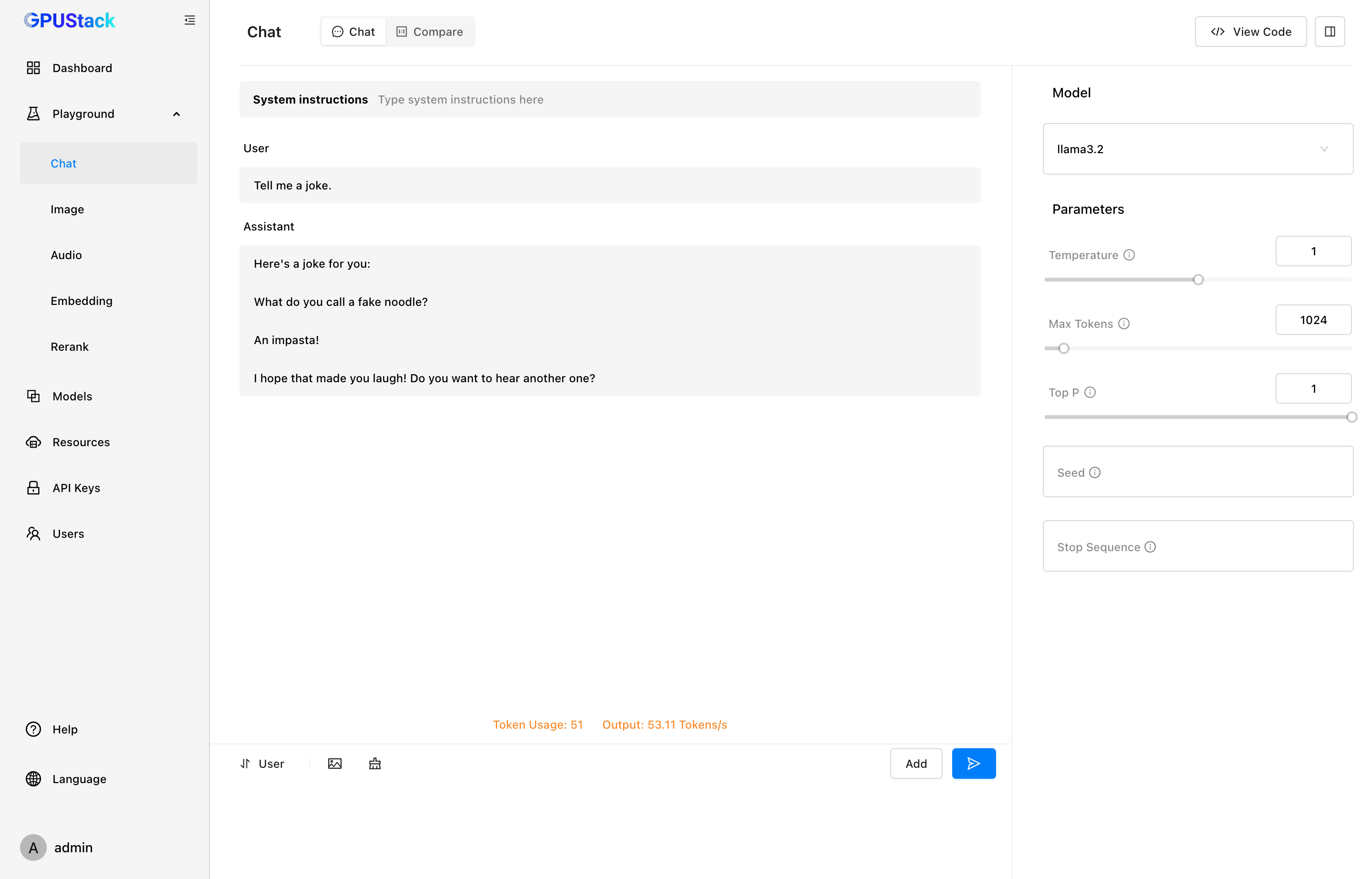
2024年8月,GPUStack是一个开源的GPU集群管理器,用于运行AI模型。它具有广泛的硬件兼容性,支持多种品牌的GPU,包括在Apple MacBook、Windows PC和Linux服务器上运行。 它支持各种AI模型,从大型语言模型(LLM)和扩散模型到音频、嵌入和重新排序模型。GPUStack可以轻松扩展,只需添加更多GPU或节点即可扩展您的操作。它支持单节点多GPU和多节点推理和服务,并支持llama-box(llama.cpp)和vLLM作为推理后端。GPUStack是一个轻量级的Python包,依赖项和操作开销最小,并提供与OpenAI标准兼容的API。此外,它还提供用户和API密钥管理、GPU指标监控以及令牌使用和速率指标跟踪功能。
GitHub地址:GitHub - gpustack/gpustack: Manage GPU clusters for running AI models
官网地址:GPUStack.ai
开发文档:Overview - GPUStack
1、特点
>> 广泛的硬件兼容性:支持不同品牌的GPU,可在Apple MacBooks、Windows PC和Linux服务器上运行。
>> 广泛的模型支持:支持各种AI模型,包括大型语言模型(LLMs)、扩散模型、音频模型、嵌入模型和重新排序模型。
>> 可扩展性:可以轻松添加更多GPU或节点来扩展操作规模。
>> 分布式推理:支持单节点多GPU和多节点推理及服务。
>> 多种推理后端:支持llama-box (包含llama.cpp和stable-diffusion.cpp服务器)、vox-box和vLLM作为推理后端。
>> 轻量级Python包:依赖项和操作开销最小。
>> 兼容OpenAI的API:提供与OpenAI标准兼容的API。
>> 用户和API密钥管理:简化了用户和API密钥的管理。
>> GPU指标监控:实时监控GPU性能和利用率。
>> 令牌使用和速率指标:追踪令牌使用情况并有效管理速率限制。
2、支持的平台:macOS/Windows/Linux
>> macOS
>> Windows (10, 11)
>> Linux (Ubuntu >= 20.04, Debian >= 11, RHEL >= 8, Rocky >= 8, Fedora >= 36, OpenSUSE >= 15.3 (leap), OpenEuler >= 22.03).
注意:Linux系统上安装GPUStack worker需要GLIBC版本2.29或更高。
3、支持的架构:AMD64/ARM64
>> AMD64
>> ARM64 (注意:Linux和macOS系统在使用低于3.12版本的Python时,需要安装与架构匹配的Python发行版;Windows系统请使用AMD64版本的Python,因为某些依赖项的wheel包在ARM64上不可用。如果使用conda,则会自动处理,因为conda默认安装AMD64发行版。)
4、支持的加速器:Apple Metal/NVIDIA CUDA/Ascend CANN等
>> Apple Metal (M系列芯片)
>> NVIDIA CUDA (计算能力6.0及以上)
>> Ascend CANN(华为系列)
>> Moore Threads MUSA
>> 未来计划支持:AMD ROCm, Intel oneAPI, Qualcomm AI Engine
5、支持的模型:LLMs以及重排序模型/VLLMs/扩散模型/音频模型
GPUStack使用llama-box(捆绑llama.cpp和stable-diffusion.cpp服务器)、vLLM和vox-box作为后端,支持来自以下来源的各种模型:
Hugging Face
ModelScope
Ollama Library
本地文件路径
文档中列举了以下几类模型的示例:
>> 大型语言模型 (LLMs): Qwen, LLaMA, Mistral, Deepseek, Phi, Yi
>> 视觉语言模型 (VLMs): Llama3.2-Vision, Pixtral, Qwen2-VL, LLaVA, InternVL2
>> 扩散模型 (Diffusion Models): Stable Diffusion, FLUX
>> 重新排序器 (Rerankers): GTE, BCE, BGE, Jina
>> 音频模型 (Audio Models): Whisper (语音转文本), CosyVoice (文本转语音)
GPUStack 安装和使用方法
1、安装
Linux或macOS
GPUStack提供一个脚本,可在基于systemd或launchd的系统上将其安装为服务。安装方法如下:
curl -sfL https://get.gpustack.ai | sh -s -Windows
以管理员身份运行PowerShell(避免使用PowerShell ISE),然后运行以下命令安装GPUStack:
Invoke-Expression (Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content其他安装方法
对于手动安装、Docker安装或详细的配置选项,请参考安装文档。
2、使用方法
案例一:运行并与llama3.2模型聊天
gpustack chat llama3.2 "tell me a joke."
案例二:使用stable-diffusion-v3-5-large-turbo模型生成图像
此命令会从Hugging Face下载模型(约12GB)。下载时间取决于网络速度。请确保您有足够的磁盘空间和VRAM(12GB)来运行模型。如果遇到问题,您可以跳过此步骤并转到下一步。
gpustack draw hf.co/gpustack/stable-diffusion-v3-5-large-turbo-GGUF:stable-diffusion-v3-5-large-turbo-Q4_0.gguf \
"A minion holding a sign that says 'GPUStack'. The background is filled with futuristic elements like neon lights, circuit boards, and holographic displays. The minion is wearing a tech-themed outfit, possibly with LED lights or digital patterns. The sign itself has a sleek, modern design with glowing edges. The overall atmosphere is high-tech and vibrant, with a mix of dark and neon colors." \
--sample-steps 5 --show命令完成后,生成的图像将出现在默认查看器中。您可以尝试不同的提示和CLI选项来自定义输出。
访问GPUStack UI
在浏览器中打开http://myserver访问GPUStack UI。使用用户名admin和默认密码登录。可以使用以下命令获取默认设置的密码:
Linux或macOS
cat /var/lib/gpustack/initial_admin_passwordWindows
Get-Content -Path "$env:APPDATA\gpustack\initial_admin_password" -Raw在导航菜单中点击“Playground”,即可在UI playground中与LLM聊天。
创建和使用API密钥
在导航菜单中点击“API Keys”,然后点击“New API Key”按钮。填写名称并点击“Save”按钮。复制生成的API密钥并将其保存在安全的地方,因为您只能在创建时看到它一次。使用API密钥访问与OpenAI兼容的API。
T1、使用curl
export GPUSTACK_API_KEY=myapikey
curl http://myserver/v1-openai/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $GPUSTACK_API_KEY" \
-d '{
"model": "llama3.2",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
],
"stream": true
}'T2、使用OpenAI Python API库来使用这些API
from openai import OpenAI
client = OpenAI(base_url="http://myserver/v1-openai", api_key="myapikey")
completion = client.chat.completions.create(
model="llama3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)GPUStack的案例应用
持续更新中……



















 716
716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











