









LLMs之dataset:synthetic-data-generator(合成数据生成器)的简介、安装和使用方法、案例应用之详细攻略
目录
synthetic-data-generator的安装和使用方法
Chat Data:自然语言描述→配置→生成并推送到Hugging Face Hub
synthetic-data-generator的简介

2024年12月,合成数据生成器 (Synthetic Data Generator) 是一款强大的工具,用于创建高质量数据集,以训练和微调语言模型。它利用 distilabel 和大型语言模型 (LLM) 的能力,生成符合特定需求的合成数据,进而弥补真实世界数据不足的问题。该工具允许用户无需编写代码即可使用大型语言模型 (LLM) 创建自定义数据集。
工具的工作原理:用户提供数据描述(自定义提示词),工具利用合成数据管道(底层基于distilabel和Hugging Face免费文本生成API)生成数据集。 用户无需了解底层技术细节。目前,该工具支持文本分类和聊天数据集的生成。 文本分类需要用户提供类别,聊天数据集需要用户提供对话示例。 后续支持了更多任务,例如评估和RAG(检索增强生成)。
synthetic-data-generator是一个高效、灵活且易于使用的工具,它降低了创建高质量数据集的门槛,使得即使没有专业数据科学背景的用户也能快速生成满足特定需求的训练数据,从而显著加速 AI 模型的开发和部署。 其对多种任务的支持以及与 Hugging Face Hub 和 Argilla 的集成,更是进一步提升了其实用性和价值。
GitHub地址:GitHub - argilla-io/synthetic-data-generator: Build datasets using natural language
文章:https://huggingface.co/blog/synthetic-data-generator
1、核心功能和优势
>> 高质量数据集生成:该工具能够生成用于训练和微调语言模型的高质量数据集,显著提升模型性能。
>> 基于LLM和distilabel:它巧妙地结合了大型语言模型 (LLM) 的强大文本生成能力和 distilabel 框架的合成数据生成技术,保证了数据的质量和多样性。
>> 定制化能力强:用户可以根据自身需求,精确描述目标应用的特性,从而生成高度定制化的数据集。
>> 迭代式开发:支持迭代式地创建和改进样本数据集,方便用户逐步完善数据质量,最终获得理想的数据集。
>> 支持多种任务:目前支持文本分类、用于监督微调的聊天数据以及检索增强生成 (Retrieval Augmented Generation, RAG) 等多种任务,应用范围广泛。
>> 便捷的数据集管理:生成的完整数据集可以轻松地推送到 Hugging Face Hub 和/或 Argilla 平台,方便后续的模型训练和数据管理。
>> 加速AI开发流程:通过简化数据集创建过程,该工具极大地加快了 AI 开发流程,缩短了从概念到模型部署的时间。
2、特点
>> 使用自然语言构建数据集:您可以用自然语言描述所需数据集的特性。
>> 迭代式数据集构建:支持迭代式地创建和改进样本数据集。
>> 大规模数据集生成:能够生成完整规模的数据集。
>> 支持多种任务:支持文本分类、监督微调的聊天数据和检索增强生成 (Retrieval Augmented Generation, RAG) 等任务。
>> Hugging Face Hub 和 Argilla 集成:生成的的数据集可以轻松地推送到 Hugging Face Hub 和 Argilla 平台。
>> 可定制性:基于distilabel,您可以轻松更改LLM或流水线步骤。
>> 多种API支持:支持Hugging Face、OpenAI、Ollama和VLLM等多种API提供商和模型。
synthetic-data-generator的安装和使用方法
1、安装
pip安装
pip install synthetic-dataset-generator安装依赖项
创建虚拟环境:python -m venv .venv
激活虚拟环境:source .venv/bin/activate
安装依赖项:
pip install -e .
pdm install运行应用
python app.py2、使用方法
快速入门
from synthetic_dataset_generator import launch
launch()环境变量配置
为了自定义生成过程,您可以设置以下环境变量:
>>HF_TOKEN:您的Hugging Face令牌,用于将数据集推送到Hugging Face Hub并从Hugging Face推理端点生成免费补全。 可以在examples文件夹中找到一些配置示例。
MAX_NUM_TOKENS:生成的令牌最大数量,默认为2048。
MAX_NUM_ROWS:生成的最多行数,默认为1000。
DEFAULT_BATCH_SIZE:生成数据集使用的默认批量大小,默认为5。
工具高级功能——可选的API提供商和模型配置:
通过修改环境变量来使用不同的模型(包括Hugging Face和OpenAI模型)、调整批大小以及使用私有的Argilla实例。 可以如何提高速度和准确性、本地部署以及自定义管道。 以及工具的开源特性,允许用户在GitHub上进行修改和适配。
MODEL:用于生成数据集的模型,例如meta-llama/Meta-Llama-3.1-8B-Instruct、gpt-4o、llama3.1等。
API_KEY:用于生成API的API密钥,例如hf_...、sk-...等。如果未提供,则默认为HF_TOKEN环境变量。
OPENAI_BASE_URL:任何与OpenAI兼容的API的基本URL,例如https://api.openai.com/v1/。
OLLAMA_BASE_URL:任何与Ollama兼容的API的基本URL,例如http://127.0.0.1:11434/。
HUGGINGFACE_BASE_URL:任何与Hugging Face兼容的API的基本URL,例如TGI服务器或专用推理端点。如果您想使用无服务器推理,只需设置MODEL。
VLLM_BASE_URL:任何与VLLM兼容的API的基本URL,例如http://localhost:8000/。
为了使用特定模型专门生成补全,请在前面提到的环境变量后面添加_COMPLETION。例如,您可以使用MODEL_COMPLETION和OPENAI_BASE_URL_COMPLETION。
SFT和聊天数据生成:不支持OpenAI端点。此外,您需要根据其提示模板,基于模型系列进行配置,使用正确的TOKENIZER_ID和MAGPIE_PRE_QUERY_TEMPLATE环境变量。
TOKENIZER_ID:用于magpie管道的tokenizer ID,例如meta-llama/Meta-Llama-3.1-8B-Instruct。
MAGPIE_PRE_QUERY_TEMPLATE:强制设置Magpie的预查询模板,仅支持Hugging Face推理端点。llama3和qwen2开箱即用,分别使用<|begin_of_text|><|start_header_id|>user<|end_header_id|>\n\n和<|im_start|>user\n。对于其他模型,您可以传递自定义的预查询模板字符串。
Argilla集成
审查数据集,即使是合成数据也需要审查,并介绍了与Argilla(一个用于构建高质量数据集的协作工具)的集成,允许用户使用语义搜索和可组合过滤器来探索和评估数据集。

可以通过设置以下环境变量将数据集推送到Argilla进行进一步整理:
ARGILLA_API_KEY:您的Argilla API密钥。
ARGILLA_API_URL:您的Argilla API URL。
3、在线测试—生成数据集
合成数据是人工生成的信息,能够模拟真实世界的数据。它通过扩充或增强数据集来克服数据的局限性。这是一款用户友好型应用程序,采用无代码方式利用大型语言模型(LLM)创建自定义数据集。最棒的是:它拥有简单易懂的分步流程,让数据集创建变得轻松无比,无需任何技术知识,任何人都能在几分钟内创建数据集和模型。合成数据生成器会根据你自定义的提示,通过合成数据管道生成适用于您用例的数据集。在后台,这由 distilabel 和免费的 Hugging Face 文本生成 API 提供支持,但我们无需担心这些复杂性,只需专注于使用用户界面即可。
地址:https://huggingface.co/spaces/argilla/synthetic-data-generator
Text Classification

文本分类通常用于对客户评论、社交媒体帖子或新闻文章等文本进行分类。生成分类数据集依赖于我们使用 LLM 解决的两个不同步骤。我们首先生成不同的文本,然后为它们添加标签。合成文本分类数据集的一个很好的例子是argilla/synthetic-text-classification-news,它将合成新闻文章分为 8 个不同的类别。
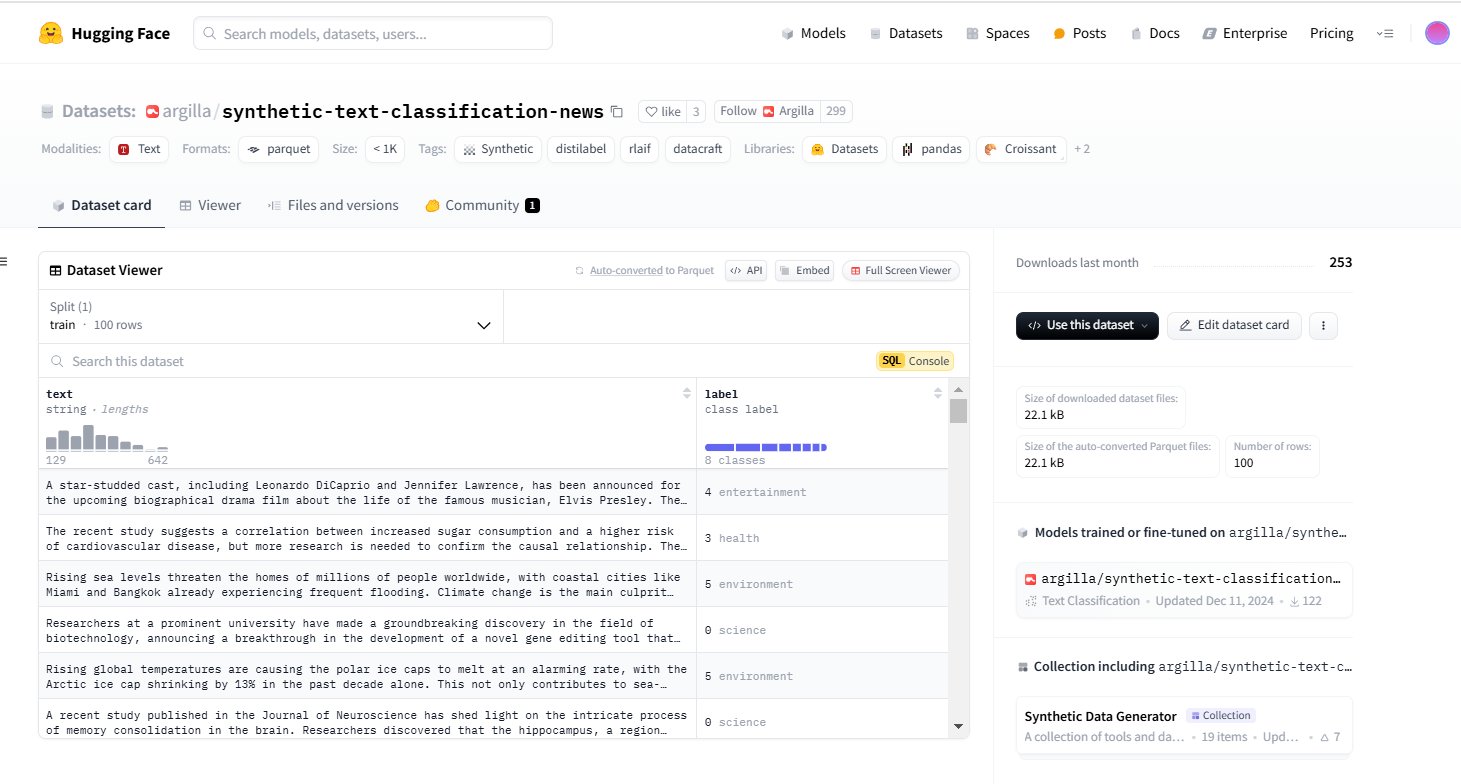
LLMs之ModernBERT:针对匮乏的领域数据利用LLM(ModernBERT-domain-classifier)生成合成数据并训练一个高效的文本分类模型——定义数据集(采用synthetic-data-generator合成+划分)→数据预处理(分词并确保数据格式)→模型训练(加载预训练模型并设置标签映射【ModernBERT】)→定义评估指标F1→微调模型→保存模型并上传到 Hugging Face→加载模型并进行推理与验证
https://yunyaniu.blog.csdn.net/article/details/145539730
Chat Data:自然语言描述→配置→生成并推送到Hugging Face Hub
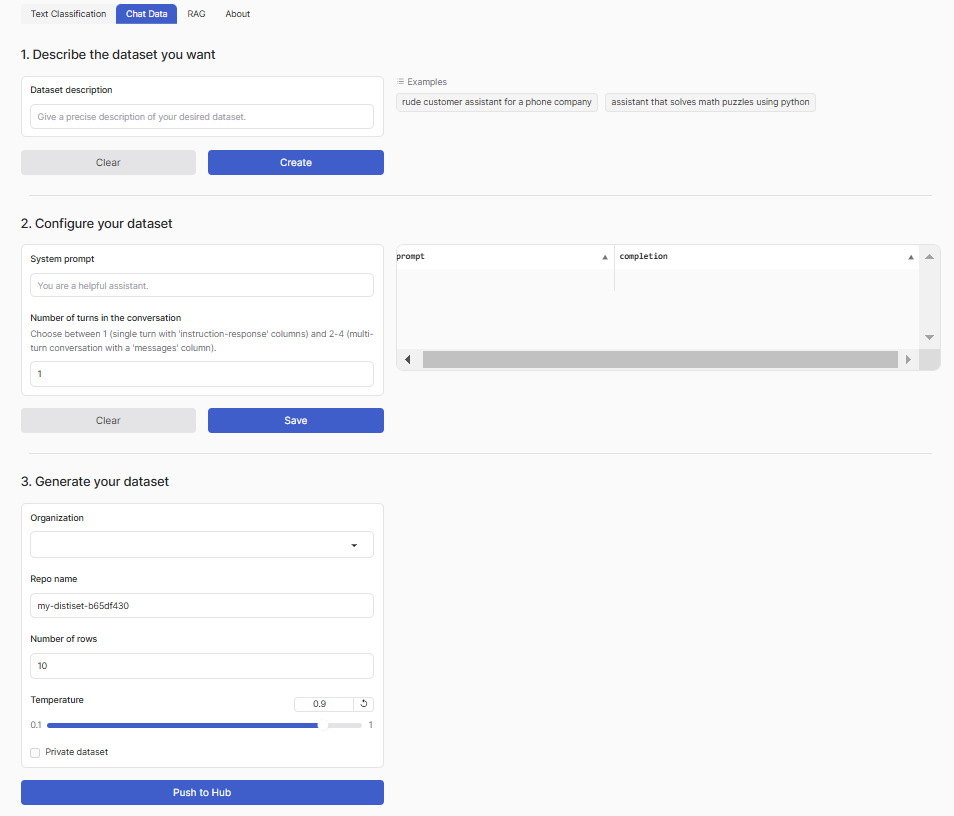
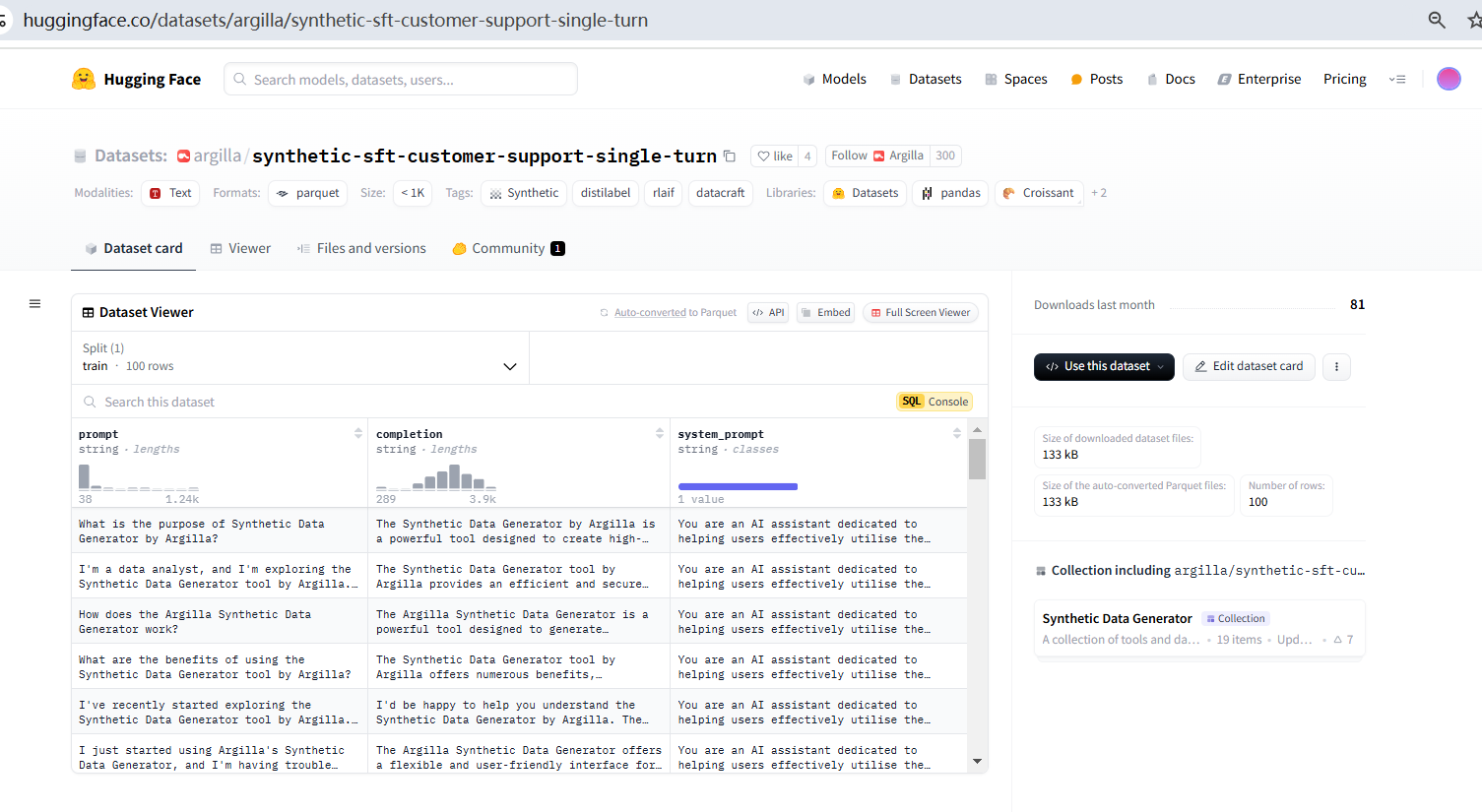
聊天类型的数据集可用于监督微调 (SFT),这是允许 LLM 处理对话数据的技术,允许用户通过聊天界面与 LLM 交互。合成聊天数据集的一个很好的例子是 argilla /synthetic-sft-customer-support-single-turn,它重点介绍了一个旨在处理客户支持的 LLM 示例。在此示例中,客户支持主题是合成数据生成器本身。
使用该工具生成一个基本的聊天数据集,分为三个步骤:
(1)、描述你的数据集 (Describe Your Dataset):用户需要提供详细的数据集描述,包括用例,以便生成器理解需求。
(2)、配置和优化 (Configure and Refine):用户可以调整系统提示词和特定任务设置来优化生成的数据集。
(3)、生成和推送 (Generate and Push):用户需要填写数据集名称、组织信息、样本数量和温度(控制生成的创造性),然后点击“生成”按钮。 生成的数据集将直接保存到Argilla和Hugging Face Hub。
RAG
持续更新中……
4、利用AutoTrain训练模型
使用AutoTrain(一个无需代码即可创建AI模型的工具)来训练模型。 它以argilla/synthetic-text-classification-news数据集为例,演示了训练模型的流程。
synthetic-data-generator的案例应用
synthetic-data-generator工具可以用于快速原型设计和创建各种数据集,从而加速AI开发过程。 提供的例子包括创建用于文本分类、监督微调的聊天数据以及检索增强生成的数据集。 具体应用场景取决于用户自定义的模型和参数。



















 517
517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











