







LLMs之Time:《TimeDistill: Efficient Long-Term Time Series Forecasting with MLP via Cross-Architecture Distillation》翻译与解读
导读:这篇论文提出了一种名为 TimeDistill 的跨架构知识蒸馏框架,用于提高轻量级多层感知器 (MLP) 模型在长期时间序列预测任务中的性能。TimeDistill 提出了一种新颖的跨架构知识蒸馏方法,有效地解决了在长期时间序列预测任务中,高性能模型与高效率模型之间存在的矛盾。通过精心设计的多尺度和多周期蒸馏策略,TimeDistill 将教师模型中蕴含的时间序列模式(多尺度和多周期信息)迁移到轻量级的 MLP 学生模型中,从而在保证甚至超越教师模型性能的同时,大幅提升了模型的效率。 该方法的理论分析和大量的实验结果都验证了其有效性和实用性,为高效的时间序列预测提供了新的思路和方法。
>> 背景痛点:
● Transformer 和 CNN 模型效率低:基于 Transformer 和 CNN 的时间序列预测模型虽然性能强大,但计算和存储成本高,难以应用于大规模部署和实时预测场景。
● MLP 模型性能不足:轻量级的 MLP 模型效率高,但预测精度通常低于 Transformer 和 CNN 模型。
● 知识蒸馏方法的局限性:现有的知识蒸馏 (KD) 方法在时间序列预测任务中应用有限,缺乏针对时间序列特定模式(如多尺度和多周期模式)的设计。
>> 具体的解决方案:TimeDistill。TimeDistill 是一种跨架构知识蒸馏框架,它将 Transformer 或 CNN 模型(教师模型)中的知识迁移到 MLP 模型(学生模型),从而在保证预测精度的前提下提高模型效率。
>> 核心思路步骤:
● 多尺度蒸馏 (Multi-Scale Distillation):通过对教师模型的预测结果进行下采样,获得多尺度表示,然后将这些多尺度信息在预测层和特征层上与学生模型进行对齐。 这使得 MLP 模型能够学习到时间序列在不同时间尺度上的模式。
● 多周期蒸馏 (Multi-Period Distillation):使用快速傅里叶变换 (FFT) 将教师模型和学生模型的预测结果转换为频谱图,然后通过匹配频谱图中的周期分布来进行知识蒸馏。 这使得 MLP 模型能够学习到时间序列中的周期性模式。
● 联合优化:TimeDistill 联合优化监督损失、多尺度蒸馏损失和多周期蒸馏损失,以提高学生模型的预测精度。
● 理论分析:论文从数据增强的角度对 TimeDistill 进行理论分析,证明了该方法可以看作是一种特殊的 Mixup 数据增强策略,能够提高模型的泛化能力并稳定训练过程。
>> 优势:
● 显著提高 MLP 性能:TimeDistill 将 MLP 模型的性能提升了高达 18.6%,在多个数据集上超过了教师模型。
● 极高的效率:TimeDistill 达到了高达 7 倍的推理速度提升,并且参数量减少了 130 倍。
● 良好的泛化能力:TimeDistill 通过 Mixup 式的数据增强,提高了模型的泛化能力。
● 适应性强:TimeDistill 可以适应不同的教师模型和学生模型。
>> 结论和观点:
● TimeDistill 是一种有效且高效的长期时间序列预测框架,它成功地将复杂模型的知识迁移到轻量级的 MLP 模型中。
● 多尺度和多周期蒸馏是提高 MLP 模型性能的关键。
● TimeDistill 的理论分析为其有效性提供了坚实的理论基础。
● TimeDistill 为高效的时间序列预测提供了一种新的解决方案,尤其适用于资源受限的场景。
目录
《TimeDistill: Efficient Long-Term Time Series Forecasting with MLP via Cross-Architecture Distillation》翻译与解读
| 地址 | |
| 时间 | 2025年2月20日 |
| 作者 | Juntong Ni Zewen Liu Shiyu Wang Ming Jin Wei Jin |
Abstract
| Transformer-based and CNN-based methods demonstrate strong performance in long-term time series forecasting. However, their high computational and storage requirements can hinder large-scale deployment. To address this limitation, we propose integrating lightweight MLP with advanced architectures using knowledge distillation (KD). Our preliminary study reveals different models can capture complementary patterns, particularly multi-scale and multi-period patterns in the temporal and frequency domains. Based on this observation, we introduce TimeDistill, a cross-architecture KD framework that transfers these patterns from teacher models (e.g., Transformers, CNNs) to MLP. Additionally, we provide a theoretical analysis, demonstrating that our KD approach can be interpreted as a specialized form of mixup data augmentation. TimeDistill improves MLP performance by up to 18.6%, surpassing teacher models on eight datasets. It also achieves up to 7X faster inference and requires 130X fewer parameters. Furthermore, we conduct extensive evaluations to highlight the versatility and effectiveness of TimeDistill. | 基于 Transformer 和基于 CNN 的方法在长期时间序列预测中表现出色。然而,它们较高的计算和存储需求可能会阻碍大规模部署。为了解决这一局限性,我们提出将轻量级的多层感知机(MLP)与先进的架构结合,采用知识蒸馏(KD)技术。我们的初步研究表明,不同的模型能够捕捉到互补的模式,特别是在时间域和频率域中的多尺度和多周期模式。基于这一观察,我们引入了 TimeDistill,这是一种跨架构的知识蒸馏框架,能够将这些模式从教师模型(例如 Transformer、CNN)转移到 MLP 中。此外,我们还提供了理论分析,表明我们的 KD 方法可以解释为一种特殊形式的 mixup 数据增强。TimeDistill 能够将 MLP 的性能提升高达 18.6%,在八个数据集上超越了教师模型。它还实现了高达 7 倍的推理速度提升,并且所需的参数减少了 130 倍。此外,我们进行了广泛的评估,以突出 TimeDistill 的通用性和有效性。 |
图1:性能比较。
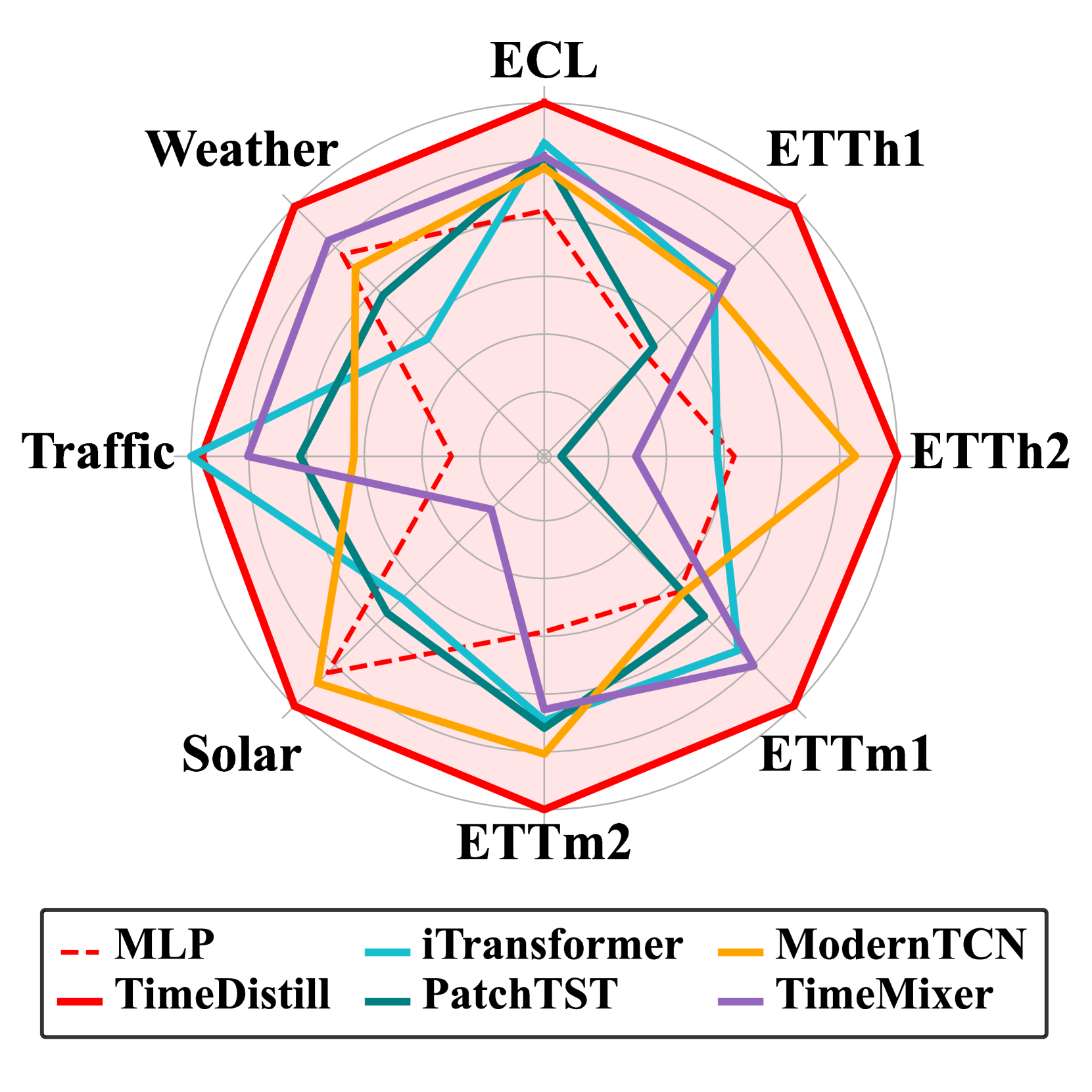
1、Introduction
| Forecasting is a notably critical problem in the time series analysis community, which aims to predict future time series based on historical time series records (Wang et al., 2024b). It has broad practical applications such as climate modeling (Wu et al., 2023), traffic flow management (Yin et al., 2021), healthcare monitoring (Kaushik et al., 2020) and finance analytics (Granger & Newbold, 2014). Recently, there has been an ongoing debate over which deep learning architecture best suits time series forecasting. The Figure 1:Performance comparison. rise of Transformers in various domains (Devlin et al., 2018; Khan et al., 2022) has led to their wide adoption in time series forecasting (Wen et al., 2022; Wu et al., 2021; Zhou et al., 2022, 2021; Nie et al., 2023; Liu et al., 2024), leveraging the strong capabilities of capturing pairwise dependencies and extracting multi-level representations within sequential data. Similarly, CNN architectures have also proven effective by developing convolution blocks for time series (Luo & Wang, 2024; Wang et al., 2023). However, despite the strong performance of Transformer-based and CNN-based models, they face significant challenges in large-scale industrial applications due to their relatively high computational demands, especially in latency-sensitive scenarios like financial prediction and healthcare monitoring (Granger & Newbold, 2014; Kaushik et al., 2020). In contrast, simpler linear or MLP models offer greater efficiency, although with lower performance (Zeng et al., 2023; Lin et al., 2024). These contrasting observations raises an intriguing question: Can we combine MLP with other advanced architectures (e.g., Transformers and CNNs) to create a powerful yet efficient model? | 预测是时间序列分析领域中一个极其关键的问题,其目标是基于历史时间序列记录来预测未来的时间序列(Wang 等人,2024b)。它在气候建模(Wu 等人,2023)、交通流量管理(Yin 等人,2021)、医疗保健监测(Kaushik 等人,2020)和金融分析(Granger 和 Newbold,2014)等众多实际应用中发挥着重要作用。 近来,关于哪种深度学习架构最适合时间序列预测一直存在争论。Transformer 在各个领域的兴起(Devlin 等人,2018;Khan 等人,2022)促使其在时间序列预测中得到广泛应用(Wen 等人,2022;Wu 等人,2021;Zhou 等人,2022,2021;Nie 等人,2023;Liu 等人,2024),得益于其在捕捉成对依赖关系和提取序列数据中的多层次表示方面的强大能力。同样,卷积神经网络架构也通过为时间序列开发卷积块而证明了其有效性(Luo 和 Wang,2024;Wang 等人,2023)。然而,尽管基于 Transformer 和 CNN 的模型表现强劲,但由于其计算需求相对较高,在大规模工业应用中面临重大挑战,尤其是在金融预测和医疗监测等对延迟敏感的场景中(格兰杰和纽博尔德,2014 年;考希克等人,2020 年)。相比之下,更简单的线性或多层感知机(MLP)模型效率更高,尽管性能稍逊(曾等人,2023 年;林等人,2024 年)。这些对比观察引发了一个有趣的问题: 我们能否将 MLP 与其他先进架构(例如 Transformer 和 CNN)相结合,以创建一个既强大又高效的模型? |
| A promising approach to addressing this question is knowledge distillation (KD) (Hinton, 2015), a technique that transfers knowledge from a larger and more complex model (teacher) to a smaller and simpler one (student) while maintaining comparable performance. In this work, we pioneer cross-architecture KD in time series forecasting, with MLP as the student and other advanced architectures (e.g., Transformers and CNNs) as the teacher. However, designing such a framework is non-trivial, as it remains unclear what “knowledge” should be distilled into MLP. To investigate this potential, we conduct a comparative analysis of prediction patterns between MLP and other time series models. Our findings reveal that MLP still excels on some data subsets despite its overall lower performance (Sec. 3.1), which highlights the value of harnessing the complementary capabilities across different architectures. To further explore the specific properties to distill, we focus on two key time series patterns: multi-scale pattern in temporal domain and multi-period pattern in frequency domain, given that they are vital in capturing the complex structures typical of many time series. (1) Multi-Scale Pattern: Real-world time series often show variations at multiple temporal scales. For example, hourly recorded traffic flow data capture changes within each day, while daily sampled data lose fine-grained details but reveal patterns related to holidays (Wang et al., 2024a). We observe that models that perform well on the finest scale also perform accurately on coarser scales, while MLP fails on most scales (Sec. 3.2). (2) Multi-Period Pattern: Time series often exhibit multiple periodicities. For instance, weather measurements may have both daily and yearly cycles, while electricity consumption data may show weekly and quarterly cycles (Wu et al., 2022). We find that models that perform well can capture periodicities similar to those in the ground truth, but MLP fails to capture these periodicities (Sec. 3.2). Therefore, enhancing MLP requires distilling and integrating these multi-scale and multi-period patterns from teacher models. | 解决这一问题的一个有前景的方法是知识蒸馏(KD)(辛顿,2015 年),这是一种将知识从较大且更复杂的模型(教师)转移到较小且更简单的模型(学生)的技术,同时保持相当的性能。在本研究中,我们率先在时间序列预测中探索跨架构知识蒸馏,以 MLP 作为学生,而其他先进架构(例如 Transformer 和 CNN)作为教师。然而,设计这样一个框架并非易事,因为目前尚不清楚应将何种“知识”提炼到多层感知机(MLP)中。为了探究这一潜力,我们对 MLP 与其他时间序列模型的预测模式进行了比较分析。我们的研究结果表明,尽管 MLP 的整体性能较低,但在某些数据子集上仍表现出色(第 3.1 节),这凸显了利用不同架构互补能力的价值。为了进一步探究应提炼的具体属性,我们重点关注两种关键的时间序列模式:时间域中的多尺度模式和频率域中的多周期模式,因为它们对于捕捉许多时间序列中常见的复杂结构至关重要。(1)多尺度模式:现实世界中的时间序列通常在多个时间尺度上表现出变化。例如,每小时记录的交通流量数据捕捉了每天内部的变化,而每天采样的数据则丢失了细粒度的细节,但揭示了与节假日相关的模式(Wang 等人,2024a)。我们观察到,在最精细尺度上表现良好的模型在较粗尺度上也表现准确,而 MLP 在大多数尺度上都表现不佳(第 3.2 节)。(2)多周期模式:时间序列通常会呈现出多种周期性。例如,天气测量数据可能同时具有日周期和年周期,而电力消耗数据则可能表现出周周期和季周期(Wu 等人,2022 年)。我们发现,表现良好的模型能够捕捉到与真实情况相似的周期性,但多层感知机(MLP)却无法捕捉到这些周期性(第 3.2 节)。因此,要增强 MLP,就需要提炼并整合这些多尺度的周期性特征。 |
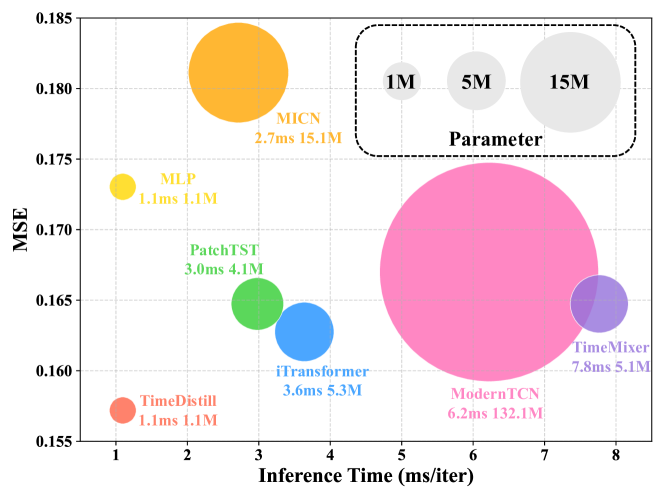
| Based on our observations, we propose a cross-architecture KD framework named TimeDistill to bridge the performance and efficiency gap between complex teacher models and a simple MLP. Instead of solely matching predictions in conventional KD, TimeDistill focuses on aligning multi-scales and multi-period patterns between MLP and the teacher: we downsample the time series for temporal multi-scale alignment and apply Fast Fourier Transform (FFT) to align period distributions in the frequency domain. The KD process can be conducted offline, shifting heavy computations from the latency-critical inference phase, where millisecond matter, to the less time-sensitive training phase, where longer processing time is acceptable. We validate the effectiveness of TimeDistill both theoretically and empirically and summarize our contributions as follows: .(a) We present the first cross-architecture KD framework TimeDistill tailored for efficient and effective time series forecasting via MLP, which is supported by our preliminary studies examining multi-scale and multi-period patterns in time series. .(b) We provide theoretical insights into the benefits of TimeDistill, illustrating that the proposed distillation process can be viewed as a form of data augmentation through a special mixup strategy. .(c) We show that TimeDistill is both effective and efficient, consistently outperforming standalone MLP by up to 18.6% and surpassing teacher models in nearly all cases (see Figure 1). Additionally, it achieves up to 7x faster inference and requires up to 130× fewer parameters compared to teacher models (see Figure 2). .(d) We conduct deeper analyses of TimeDistill, exploring its adaptability across various teacher/student models and highlighting the distillation impacts it brings to the temporal and frequency domains. | 基于我们的观察,我们提出了一种名为 TimeDistill 的跨架构知识蒸馏框架,旨在弥合复杂教师模型与简单多层感知机(MLP)之间的性能和效率差距。与传统知识蒸馏仅匹配预测不同,TimeDistill 专注于在 MLP 和教师模型之间对齐多尺度和多周期模式:我们对时间序列进行下采样以实现时间多尺度对齐,并应用快速傅里叶变换(FFT)在频域中对齐周期分布。知识蒸馏过程可以离线进行,将繁重的计算从对延迟敏感的推理阶段(毫秒级至关重要)转移到对时间不太敏感的训练阶段(可以接受更长的处理时间)。我们从理论和实证两方面验证了 TimeDistill 的有效性,并总结我们的贡献如下: (a)我们提出了首个针对通过 MLP 进行高效且有效的时间序列预测而定制的跨架构知识蒸馏框架 TimeDistill,这得到了我们初步研究中对时间序列多尺度和多周期模式的考察的支持。(b)我们对 TimeDistill 的优势提供了理论见解,表明所提出的蒸馏过程可以通过一种特殊的混合策略被视为一种数据增强形式。 (c)我们证明了 TimeDistill 既有效又高效,始终比独立的多层感知机(MLP)高出多达 18.6%,并且在几乎所有情况下都超过了教师模型(见图 1)。此外,它实现了高达 7 倍的更快推理速度,并且与教师模型相比参数需求减少了多达 130 倍(见图 2)。 (d)我们对 TimeDistill 进行了更深入的分析,探讨了其在各种教师/学生模型中的适应性,并强调了它在时间域和频率域带来的蒸馏影响。 |
Figure 2:Model efficiency comparison averaged across all prediction lengths (96, 192, 336, 720) for the ECL dataset. Full results on more datasets are listed in Appendix I.图 2:ECL 数据集上所有预测长度(96、192、336、720)的模型效率平均比较。更多数据集的完整结果列于附录 I 中。
Conclusion and Future work
| We propose TimeDistill, a cross-architecture KD framework enabling lightweight MLP to surpass complex teachers. By distilling multi-scale and multi-period patterns, TimeDistill efficiently transfers temporal and frequency-domain knowledge. Theoretical interpretations and experiments confirm its effectiveness. Future work includes distilling from advanced time series models, e.g. time series foundation models, and incorporating multivariate patterns. | 我们提出了 TimeDistill,这是一种跨架构的知识蒸馏框架,能让轻量级的多层感知机超越复杂的教师模型。通过蒸馏多尺度和多周期模式,TimeDistill 能够高效地转移时域和频域知识。理论解释和实验均证实了其有效性。未来的工作包括从先进的时间序列模型(例如时间序列基础模型)中进行蒸馏,并纳入多变量模式。 |



















 1386
1386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











