









Competition:Kaggle竞赛平台的简介(比赛任务/常用数据集)、使用方法(Kaggle上比赛操作流程案例)、比赛经验(案例理解)之详细攻略
导读:一般而言,对于像Kaggle这样的在线数据分析竞赛平台,都遵照下载数据、搭建模型、提交结果三个步骤。并且多数情况下,并不要求参赛者在其指定的平台上运行源代码。因此就使得参赛的兴趣爱好者可以更加灵活地搭建预测模型,既可以自行编程,也可以使用大量开源的工具包。
目录
Dataset之AllstateClaimsSeverity:AllstateClaimsSeverity数据集(Kaggle2016竞赛)的简介、下载、案例应用之详细攻略
Dataset之RentListingInquries:RentListingInquries(Kaggle竞赛)数据集的简介、下载、案例应用之详细攻略
Dataset之HiggsBoson:Higgs Boson(Kaggle竞赛)数据集的简介、下载、案例应用之详细攻略
Kaggle竞赛平台的使用方法(了解如何在Kaggle上进行比赛)
ML之LoR:kaggle比赛之利用titanic(泰坦尼克号)数据集建立LoR模型对每个人进行获救是否预测
ML之LoR&Bagging&RF:依次利用LoR、Bagging、RF算法对titanic(泰坦尼克号)数据集 (Kaggle经典案例)获救人员进行二分类预测(最全)
ML之FE:Kaggle比赛之根据城市自行车共享系统数据进行FE+预测在某个时间段自行车被租出去的个数
ML之FE:利用FE特征工程(单个特征及其与标签关系的可视化)对RentListingInquries(Kaggle竞赛)数据集实现房屋感兴趣程度的多分类预测
Kaggle竞赛平台的简介
Kaggle是一个知名的在线数据科学竞赛平台,吸引了全球的数据科学家和机器学习爱好者。Kaggle竞赛的特点是竞赛难度大、竞赛奖金高、竞赛数据质量高,同时还提供了交流社区和学习资源。参赛者需要提交机器学习模型或算法来解决相应的问题。该平台提供了大量的数据和工具,以帮助参赛者完成任务。
Kaggle是当前世界上最为流行的,采用众包(Crowdsouring)策略,为科技公司、研究院所乃至高校课程提供数据分析与预测模型的竞赛平台。Kaggle是Google旗下的数据科学竞赛平台。Kaggle是由联合创始人、首席执行官安东尼·高德布卢姆(Anthony Goldbloom)2010年4月,在墨尔本创立的,主要为开发商和数据科学家提供举办机器学习竞赛、托管数据库、编写和分享代码的平台。该平台已经吸引了80万名数据科学家的关注,这些用户资源或许正是吸引谷歌的主要因素。
Kaggle平台设立的宗旨在于:汇聚全世界从事数据分析与预测的专家以及兴趣爱好者的集体智慧,利用公开数据竞赛的方式,为科技公司、研究院所和高校课程中的研发课题,提供有效的解决方案。这一初衷使得问题提出者与解决者获得了双赢。
Kaggle是全球知名的大数据竞赛平台,它一开始以Data Mining比赛起家,但随着机器学习热度的不断上升,CV、NLP等机器学习项目在Kaggle上所占的比重越来越大,它也因此被视为是ML爱好者的一个主要学习交流社区。
官方网址::Kaggle: Your Machine Learning and Data Science Community
Kaggle官网:Kaggle is the place to do data science projects
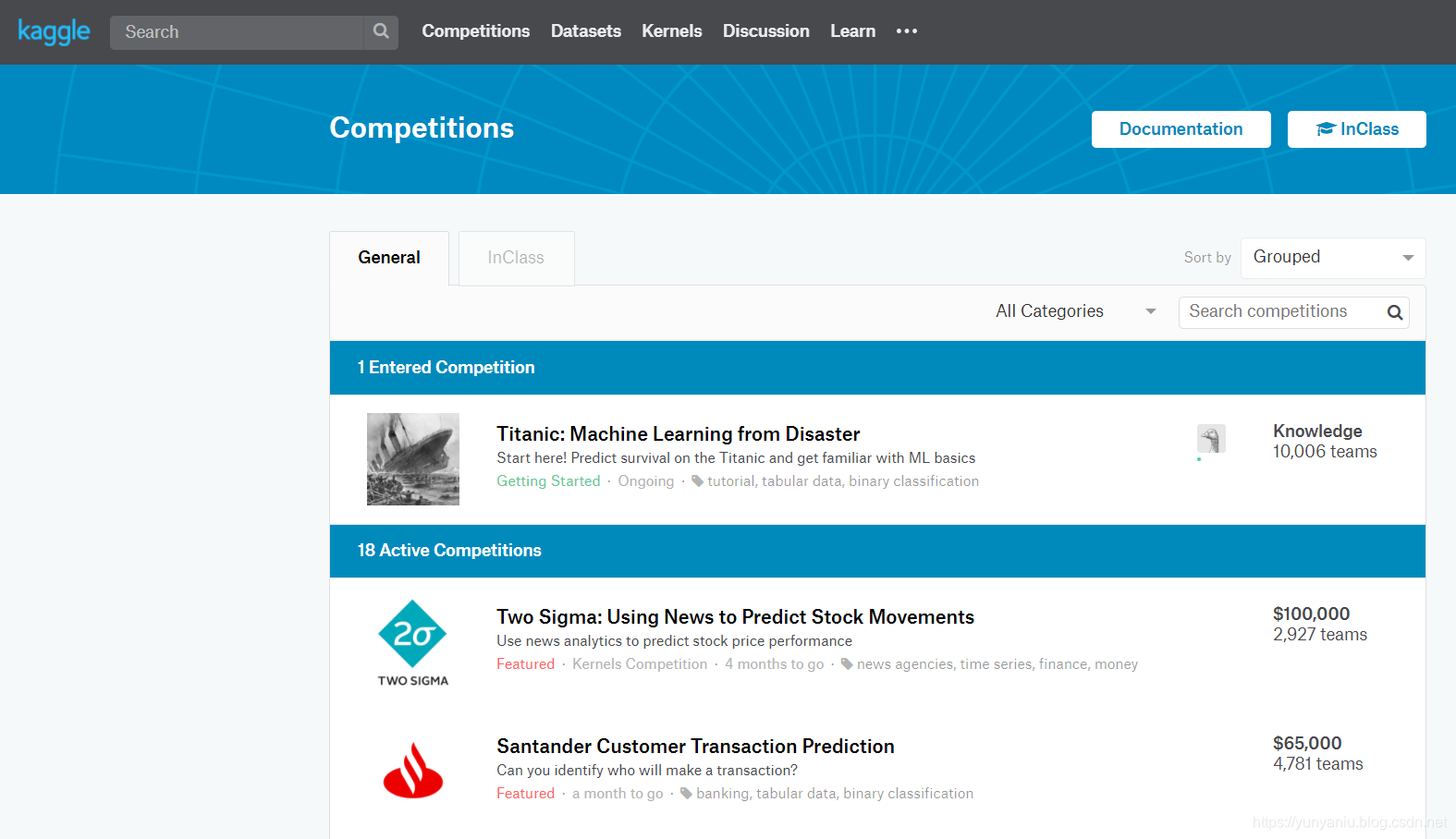
1、Kaggle平台上常见任务
2、在Kaggle平台上长期挂载的实践任务
| Titanic | |
| IMDB | |
| MNIST |
3、常用数据集
Dataset之AllstateClaimsSeverity:AllstateClaimsSeverity数据集(Kaggle2016竞赛)的简介、下载、案例应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/91164441
Dataset之RentListingInquries:RentListingInquries(Kaggle竞赛)数据集的简介、下载、案例应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/90899632
Dataset之HiggsBoson:Higgs Boson(Kaggle竞赛)数据集的简介、下载、案例应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/90792536
Kaggle竞赛平台的使用方法(了解如何在Kaggle上进行比赛)
1、操作流程
第一步,下载数据
第二步,搭建模型
EL之XGBoost:Kaggle神器XGBoost算法模型的简介、安装、使用方法、案例应用之详细攻略
第三步,提交结果
2、案例经验——以Titanic为例
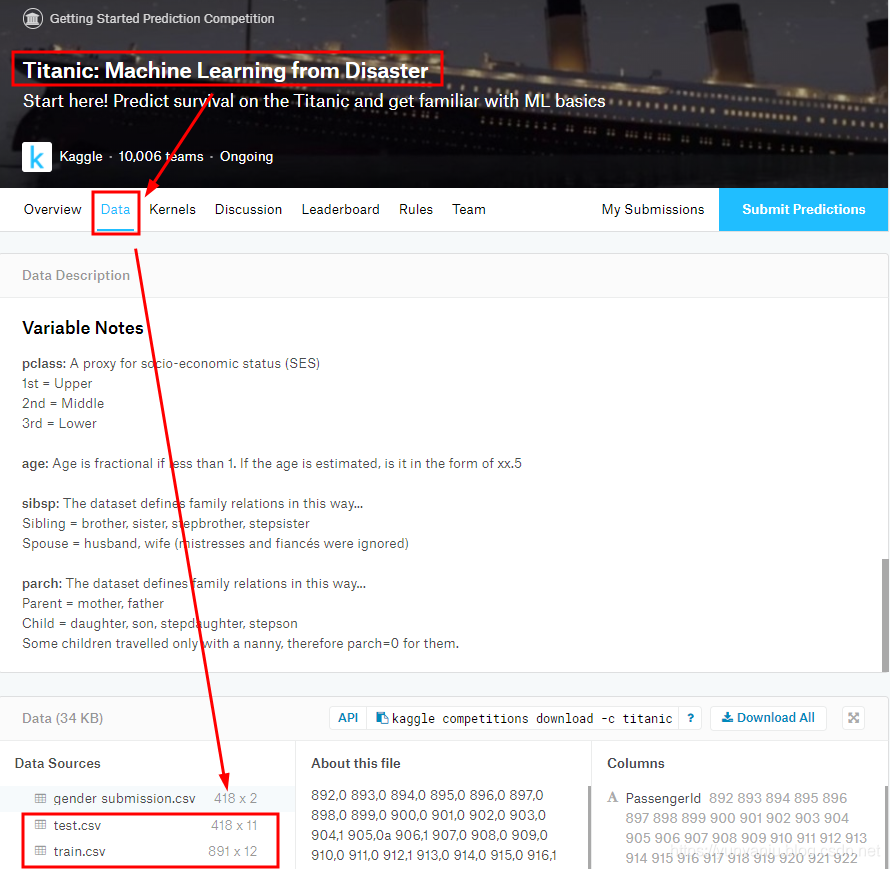
(1)、下载数据集
Titanic - Machine Learning from Disaster | Kaggle
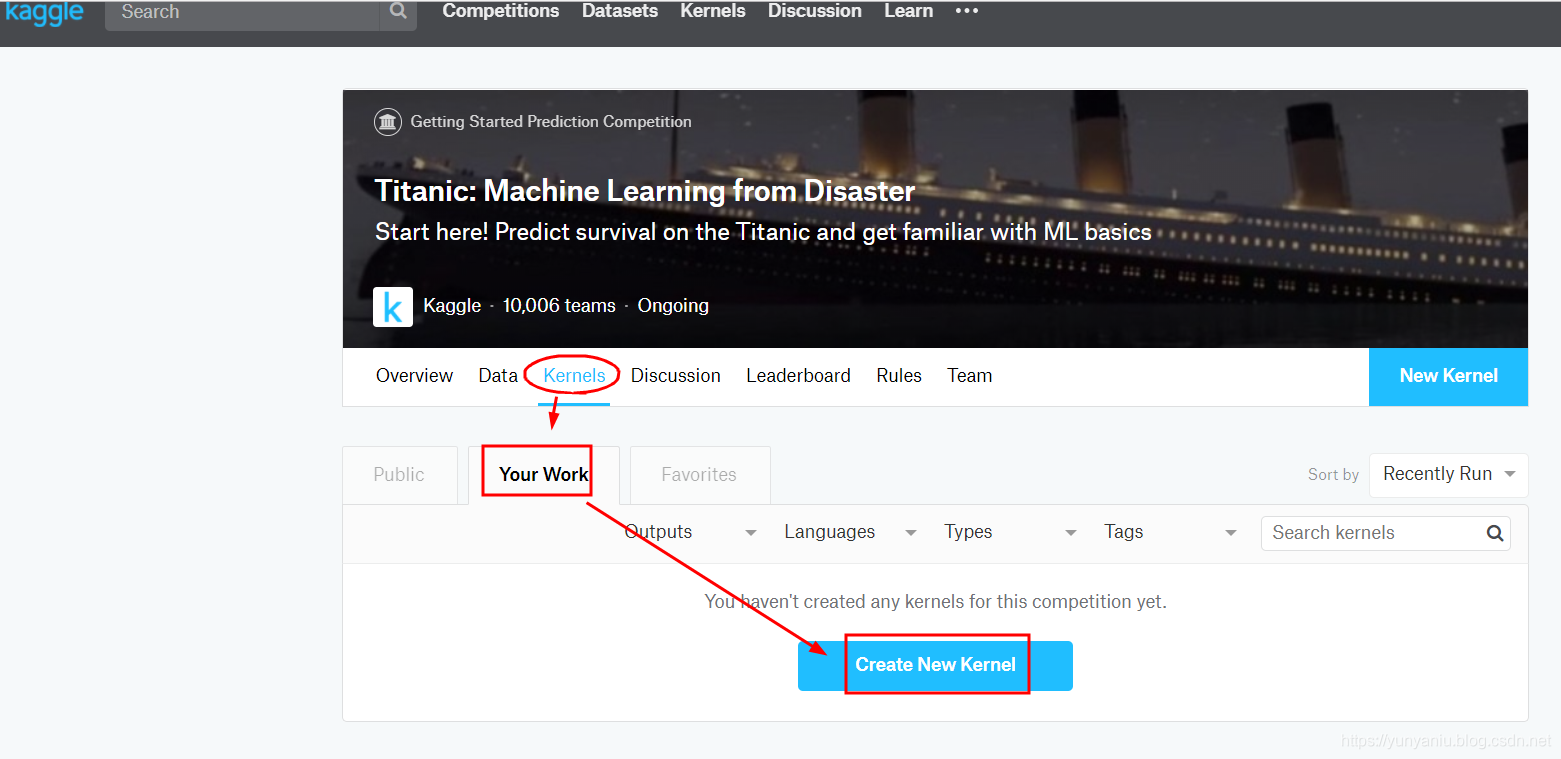
(2)、搭建模型:本地IDE编写、Kaggle平台编写
本地IDE编写:在自己本地计算机编写代码,IPython Notebook或者其他基于python的IDE。
Kaggle平台编写:直接在Kaggle平台上编写代码并在线运行。只需在左边栏点击
Create New Kernel→选择Script或者Notebook,
进入Kaggle在线编程页面,按照所给的代码范例,并注意文件读写的正确路径即可。
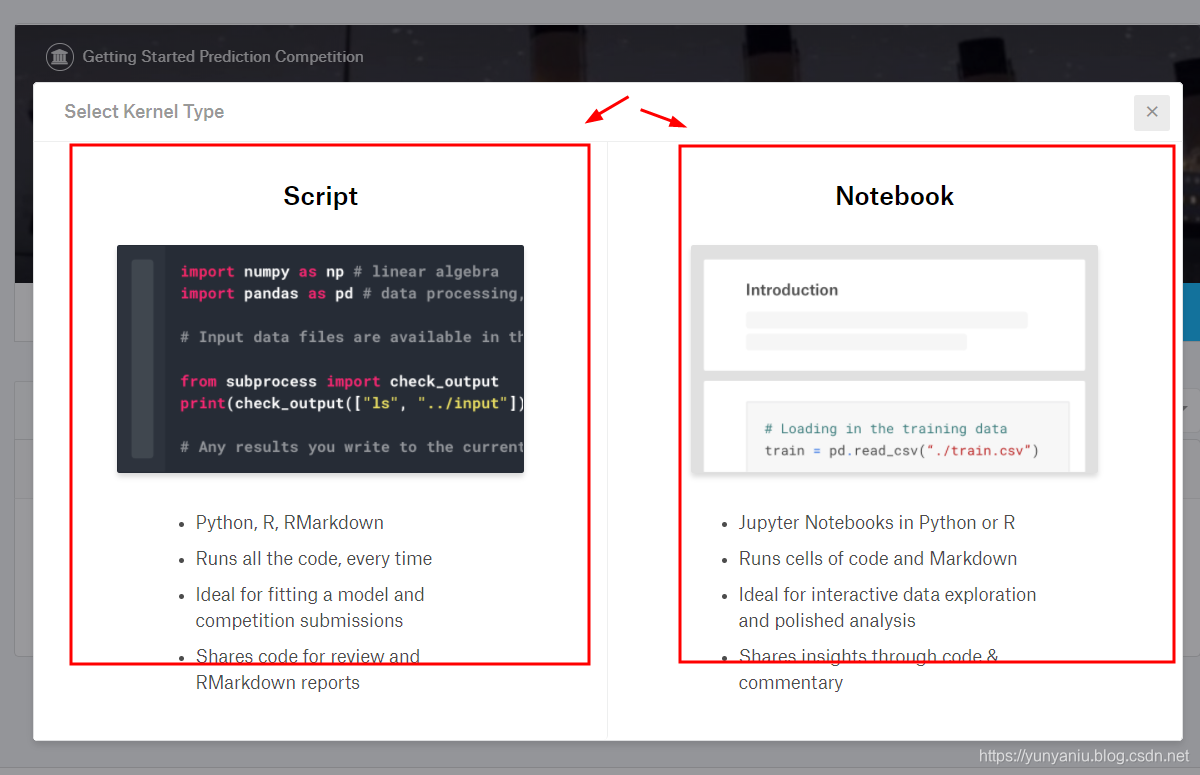
(3)、提交结果
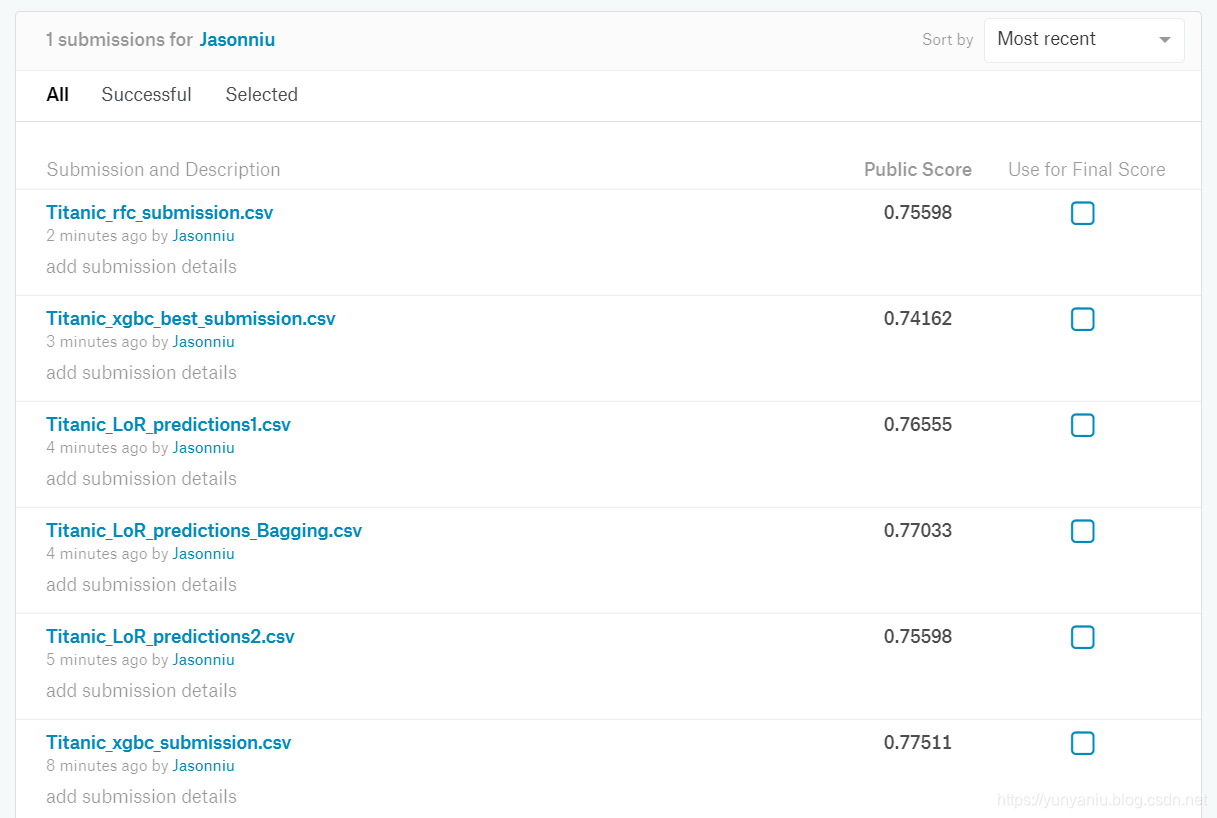
必须注意的是,在代码完成后,提交结果时,一定要严格遵守竞赛数据中所提供的样例提交文件的格式。因为所有参赛选手所提交的文件,都会在网站后台由程序自动按照Evaluation中的评估函数进行评价,而且稍有不符合格式的提交文件都不会被评估程序所考量,更不必说取得竞赛的名次。
>> Kaggle竞赛平台的自动测评系统给出了上述3个提交文件的最终性能表现。有时候Kaggle测评结果也许有些出乎意料,因为原本以为经过超参数搜索和优化之后的模型可以取得更好的预测性能,但是,事实恰恰相反。
>> 在今后的实践中也有可能出现这样的情况,究其原因是因为无法保证现实数据都来源于同一种分布,因此尽管模型经过交叉验证和超参数搜索等步骤处理,也不能保证在所有情况下都能取得更高的性能。
Kaggle竞赛平台的实战案例
1、基础案例
ML之LoR:kaggle比赛之利用titanic(泰坦尼克号)数据集建立LoR模型对每个人进行获救是否预测
https://yunyaniu.blog.csdn.net/article/details/81700746
ML之LoR&Bagging&RF:依次利用LoR、Bagging、RF算法对titanic(泰坦尼克号)数据集 (Kaggle经典案例)获救人员进行二分类预测(最全)
https://yunyaniu.blog.csdn.net/article/details/86725535
2、进阶案例
ML之FE:Kaggle比赛之根据城市自行车共享系统数据进行FE+预测在某个时间段自行车被租出去的个数
https://yunyaniu.blog.csdn.net/article/details/81711462



















 1968
1968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











