







前言
本文介绍6D位姿估计的方法SAM-6D,来自CVPR 2024的论文。
它是一个用于零样本6D位姿估计的框架,在测试新物体时,无需进行微调,直接进行检测。
通过结合实例分割模型和姿态估计模型,实现对新物体的6D姿态估计。
论文地址:SAM-6D: Segment Anything Model Meets Zero-Shot 6D Object Pose Estimation
代码地址:https://github.com/JiehongLin/SAM-6D/

一、模型框架
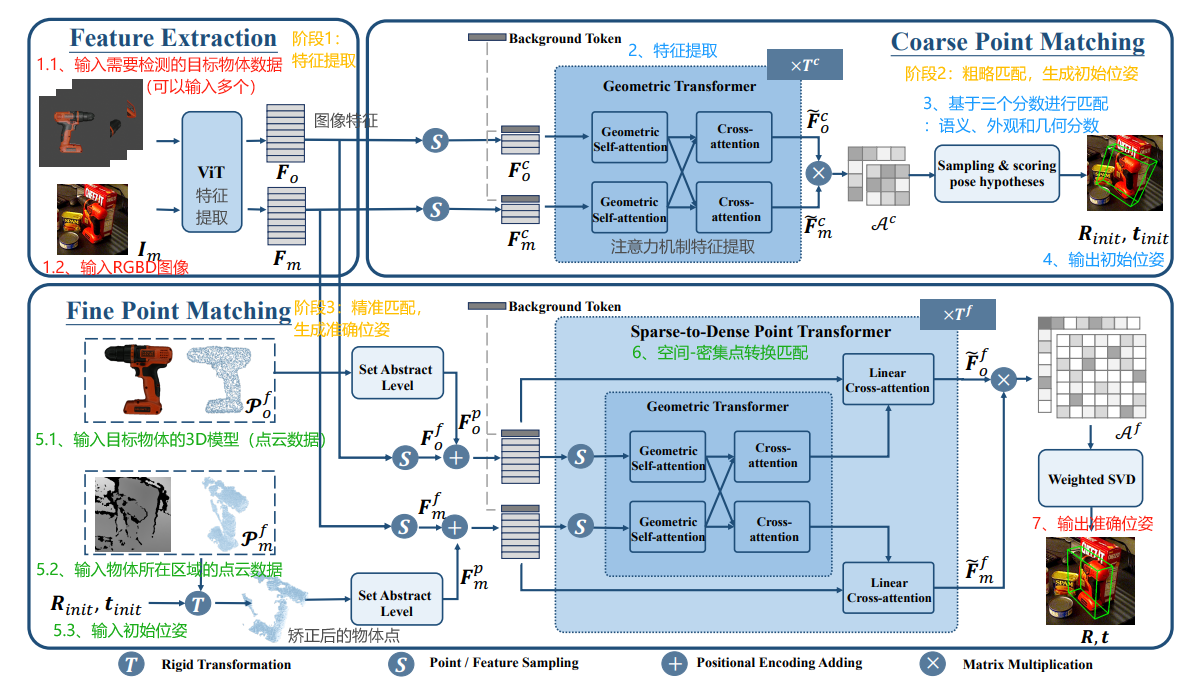
SAM-6D的模型框架,如下图所示:
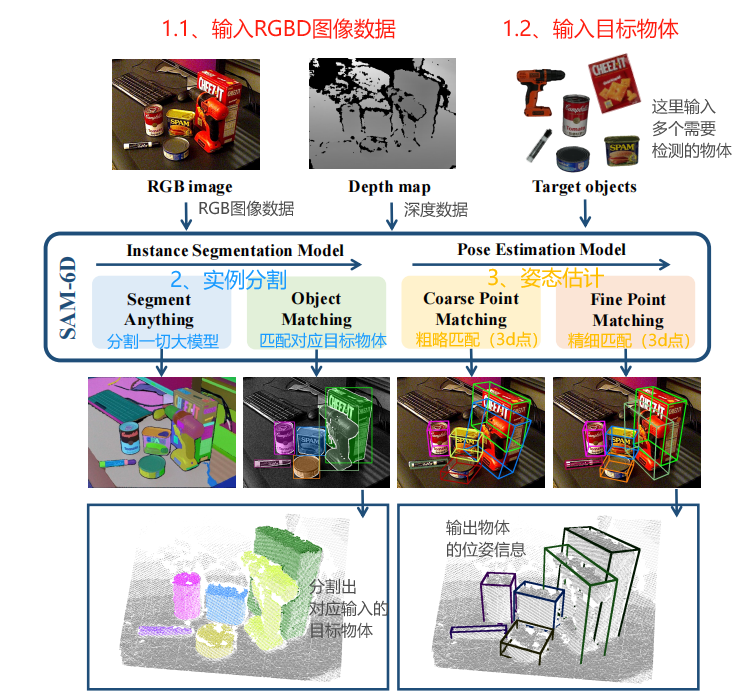
- 输入RGBD图像数据、待位姿估计的物体数据,可以输入多个要估计的物体。
- 实例分割,RGBD数据输入到Segment Anything模型(SAM)进行实例分割,生成所有可能的物体区域。
- 匹配对应目标物体,生成的物体区域会有多个,需要逐一和待估计的物体进行匹配。
- 姿态估计,输入包括RGB-D图像中提取的观测点云、目标物体的3D模型点云;首先进行粗略匹配,再进行精细匹配。
- 输出6D位姿信息,包括三维位置、三维方向。
二、创新点与特点
1)结合 Segment Anything Model (SAM) 的零样本实例分割
- 创新点:SAM-6D 利用了 SAM 模型的零样本实例分割能力,能够在没有见过的新物体上进行分割。这种方法不依赖于特定物体的预训练数据,使得模型具有很强的泛化能力。
- 特点:通过均匀采样2D网格点生成提示,SAM 能够生成所有可能的物体候选区域,为后续的姿态估计提供基础。
2)物体匹配的多重评价
- 创新点:通过语义匹配、外观匹配和几何匹配分数来筛选有效的物体候选区域。这种多重评价方法使得分割更加准确和鲁棒。
- 特点:结合语义、外观和几何特征进行匹配,提高了候选区域筛选的精度,有效过滤掉无关的候选区域。
3)Sparse-to-Dense Point Transformer (SDPT)
- 创新点:SDPT从稀疏特征生成密集特征,结合稀疏特征的高效处理和密集特征的高精度,显著提升了点云匹配的性能。
- 特点:SDPT 通过几何变换器处理稀疏点集的特征,并通过线性交叉注意力层将稀疏特征信息传递到密集点集,生成高质量的密集特征。
4)背景令牌设计
- 创新点:引入背景令牌解决部分匹配和遮挡问题。背景令牌帮助模型在处理复杂场景时提高鲁棒性,减少误匹配。
- 特点:背景令牌在点匹配过程中作为参考点,帮助建立更加准确的点对点对应关系,提高姿态估计的精度。
三、核心内容——实例分割
SAM-6D将SAM作为实例分割的基础,增强了对新奇物体的实例分割能力,并结合了精心设计的物体匹配评分系统。
- SAM的全称是Segment Anything Model ,表示分割一切物体;
- 它能够在没有先前见过具体物体的情况下,实现对物体的识别和分割。
SAM相关算法的改进:
- Semantic Segment Anything (SSA):在SAM的基础上提出,旨在将语义类别分配给SAM生成的掩码。
- PerSAM 和 Matcher:利用 SAM 分割查询图像中特定类别的物体,通过包含同类物体的参考图像来辅助点提示。
- CNOS:分割给定物体模型的所有实例,首先通过 SAM 生成掩码提案,然后过滤出与物体模板低特征相似度的提案。
- FastSAM:利用常规卷积网络替代SAM中使用的视觉变换器,提升效率。
- MobileSAM:通过解耦蒸馏,用轻量级编码器替代 SAM 的重型编码器。
实例分割主要分为两个步骤:
- 生成候选区域:使用SAM生成所有可能的物体候选区域。
- 筛选有效候选区域:通过计算物体匹配分数(基于语义、外观和几何特征)来筛选出有效的物体实例。
3.1)生成候选区域
使用SAM生成所有可能的物体候选区域。
思路过程:
- 输入图像:从RGB-D图像中提取的观测图像。
- 提示生成:使用均匀采样生成一系列2D网格点作为提示输入SAM。
- 候选区域生成:SAM根据这些提示生成所有可能的物体候选区域。
3.2)筛选有效候选区域
输入多个要估计的物体,生成的物体区域会有多个,需要逐一和待估计的物体进行匹配。
通过计算物体匹配分数来筛选出有效的物体实例。
物体匹配分数基于以下三个方面进行计算:语义匹配分数、外观匹配分数、何匹配分数
语义匹配分数:
- 定义:评估候选区域与目标物体在语义上的匹配程度。
- 计算:将候选区域的语义特征与目标物体的语义特征进行比较,通过类内相似度计算得到分数。
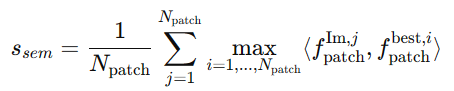
外观匹配分数:
- 定义:评估候选区域与目标物体在外观上的匹配程度。
- 计算:将候选区域的外观特征与目标物体的外观特征进行比较,通过类内相似度计算得到分数。
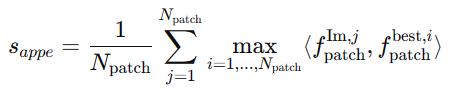
何匹配分数:
- 定义:评估候选区域与目标物体在几何形状上的匹配程度。
- 计算:通过候选区域的几何特征与目标物体的几何特征进行比较,计算IoU值(Intersection-over-Union)。
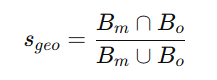
最终物体匹配分数:
- 定义:将以上三个分数综合,得到最终的物体匹配分数 𝑠𝑚
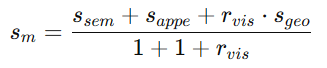
- 筛选过程:根据物体匹配分数的大小,筛选出有效的物体候选区域。这些区域将作为有效的物体实例用于后续的姿态估计。
- 输出:最终输出的是筛选后的有效物体实例分割掩码,这些掩码将用于姿态估计模型(PEM)。
四、核心内容——姿态估计
姿态估计输入RGB-D图像中提取的观测点云、目标物体的3D模型点云;首先进行粗略匹配,再进行精细匹配。
粗略点匹配(Coarse Point Matching):
- 输入:从RGB-D图像中提取的观测点云𝑃𝑚和目标物体的CAD模型点云𝑃𝑜。
- 处理:通过几何变换器处理稀疏点集的特征,生成初步的增强特征,并计算软分配矩阵 。
- 输出:初步的物体姿态估计,用于精细点匹配的初始条件。
精细点匹配(Fine Point Matching):
- 输入:通过粗略匹配得到的初始姿态对齐的观测点云和目标点云。
- 处理:利用Sparse-to-Dense Point Transformer (SDPT)生成密集特征,通过线性交叉注意力层传递稀疏特征信息,计算新的软分配矩阵。
- 输出:最终的高精度物体姿态估计,包括旋转矩阵R和平移向量t。
训练过程:
- 对于粗略和精细点匹配模块,通过计算注意力矩阵的损失,逐层优化每个变换器块的参数。
- 使用真实标签计算距离阈值,确保模型在处理复杂点云数据时的鲁棒性和准确性。
损失函数:
- 使用InfoNCE损失函数来监督注意力矩阵的学习,确保模型能够准确地匹配观测点云和目标点云之间的对应关系。
- 交叉熵损失函数用于优化注意力矩阵,确保特征匹配的准确性。
模型框架,如下图所示:
4.1)粗略点匹配
输入信息:
1. 观测到的物体点集 𝑃𝑚
- 来源:从RGB-D图像中提取的观测物体点集。
- 特征:这些点集通常包含观测场景中的目标物体和背景信息。通过实例分割模型(ISM)进行初步的分割和裁剪,提取出感兴趣的区域。
2. 目标物体的3D模型(CAD)点集𝑃𝑜
- 来源:目标物体的预定义3D模型。
- 特征:这些点集包含了物体在不同视角和姿态下的几何信息,是进行姿态匹配的基准。
匹配流程:
特征提取与增强
- 特征提取:从点集 𝑃𝑚和𝑃𝑜中提取特征,利用几何变换器对这些特征进行增强。
- 背景令牌:添加背景令牌的特征,处理那些没有直接对应点的情况。
软分配矩阵的计算
- 矩阵维度:软分配矩阵的维度为
,包括背景令牌的额外维度。
- 计算方式:通过几何变换器处理特征,计算每个点对的匹配概率,并形成软分配矩阵。
姿态假设生成与选择
- 假设生成:从软分配矩阵中选出6,000个三点对,生成姿态假设。
- 假设优化:计算这些假设的匹配误差,选出误差最小的300个假设。
- 最终选择:从300个假设中选出匹配分数最高的姿态,作为精细点匹配的初始姿态。
4.2)精细点匹配
用粗略点匹配提供的初始姿态,对物体的点云进行更为精确的对齐,最终得出高精度的6D姿态估计。
输入:
- 观测点云 Pm:从粗略点匹配阶段得到的初始姿态对齐的观测点云。
- 目标点云 Po:目标物体的CAD模型点云。
- 增强的点云特征:分别来自观测点云和目标点云的高维特征,包含了位置编码和背景令牌信息。
工作流程:
- 特征提取与增强
- 位置编码注入:在粗略点匹配的基础上,注入位置编码以增强点特征。这有助于模型在建立点对点对应关系时考虑空间位置。
- 特征提取与拼接:利用视觉变换器(ViT)从图像中提取每个点的高维特征,将这些特征拼接后通过全连接层进行处理。

五、模型设计细节
模型细节:
- 对于实例分割模型,使用了ViT-H SAM或FastSAM进行提议生成,并使用ViT-L模型的DINOV2提取类别和补丁嵌入。
- 对于姿态估计,设置了矩阵和损失函数的相关参数,并使用ADAM优化器进行训练,总计60万次迭代,初始学习率为0.0001,并使用余弦退火调度,批次大小为28。
姿态估计部分:
- 点数设置:PEM中的点数Nc=No=196 和 𝑁𝑓𝑚=𝑁𝑓𝑜=2048,这种设置确保了在稀疏和密集匹配阶段都能处理足够的点以维持高精度。
- 训练细节:PEM经过600,000次迭代的训练,使用了InfoNCE损失函数优化注意力矩阵的学习。初始化学习率为0.0001,采用余弦退火调度来调整学习率,并设置了28的批次大小。
- 模板使用:在训练和评估时分别使用了36和42个模板,这有助于提高模型在处理不同姿态物体时的准确性和鲁棒性。
数据集:
- 评估使用了BOP基准测试集中的七个核心数据集,包括LM-O、T-LESS、TUD-L、IC-BIN、ITODD、HB和YCB-V。
- 姿态估计模型在大型合成ShapeNet-Objects数据集和Google-Scanned-Objects数据集上进行训练,总计200万个图像,约包含5万个物体。
评价指标:
- 对于实例分割,采用不同交并比(IoU)阈值下的平均准确率(mAP)。
- 对于姿态估计,采用相对于三种误差函数(VSD、MSSD、MSPD)的平均召回率(AR)。
六、模型效果
在BOP基准测试集上,进行实例分割对比,采用平均精度(mAP)评价。
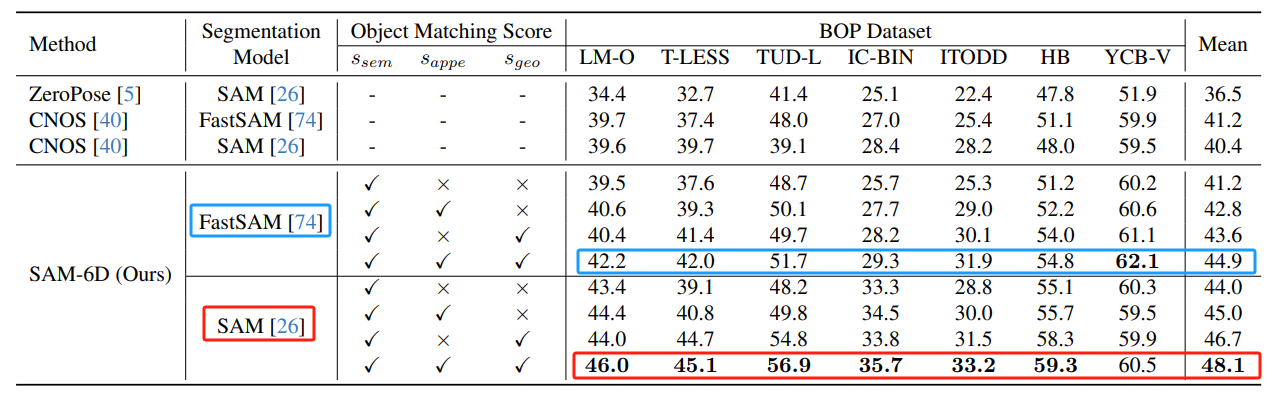
- 对象匹配得分(Object Matching Score):包括语义得分(s_sem)、外观得分(s_appe)和几何得分(s_geo)。
- BOP数据集(BOP Dataset):七个核心数据集(LM-O、T-LESS、TUD-L、IC-BIN、ITODD、HB、YCB-V)的结果。
- FastSAM:所有三种匹配得分都启用时,达到44.9。
- SAM:所有三种匹配得分都启用时,平均mAP得分最高,达到48.1。
不同方法在BOP基准测试集上,进行姿态估计对比。
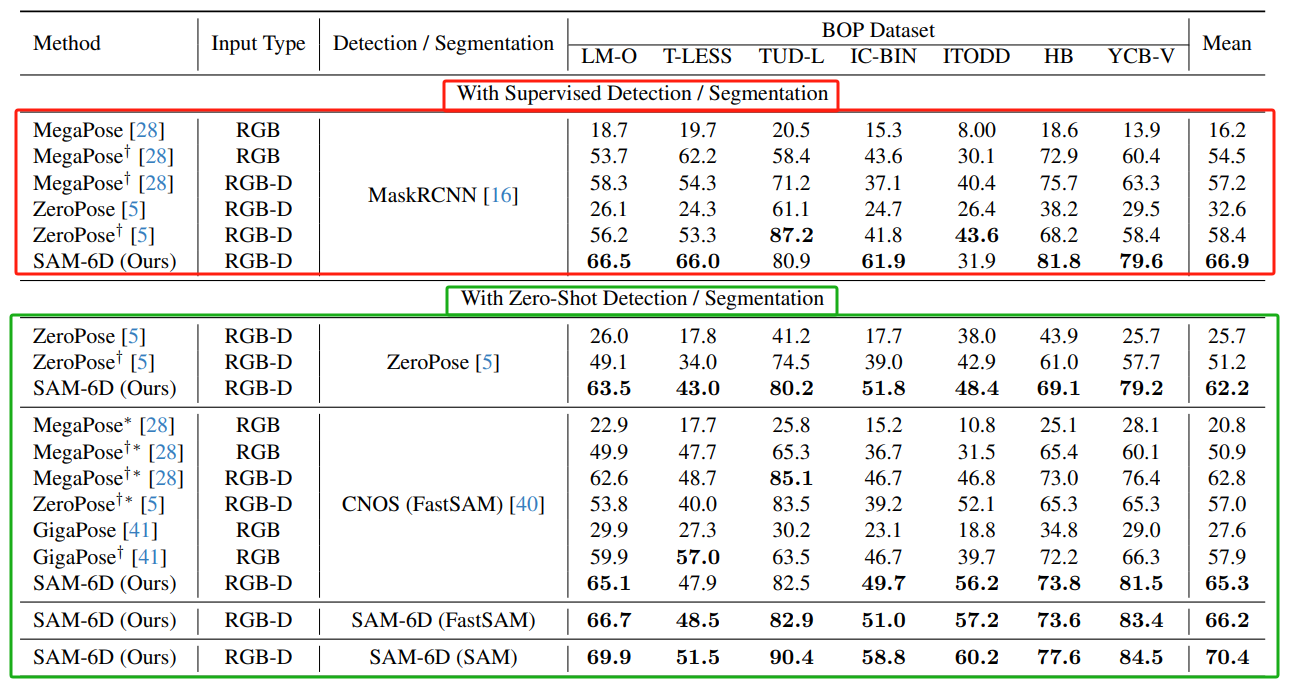
- 在有监督检测/分割下,MegaPose使用RGB-D输入和姿态细化方法时表现最好。
- 在零样本检测/分割下,SAM-6D使用SAM方法表现最好。
- 输入类型的影响:RGB-D输入通常比仅使用RGB输入能获得更高的得分,说明深度信息在姿态估计中具有重要作用。
SAM-6D模型在使用不同分割模型(FastSAM和SAM)时的运行时间,GeForce RTX 3090 GPU
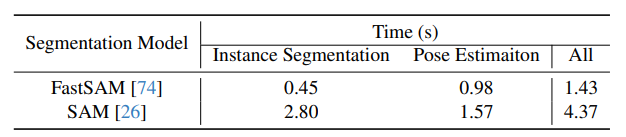
- 实例分割:FastSAM显著快于SAM,处理时间仅为0.45秒,而SAM需要2.80秒。
- 姿态估计:FastSAM仍然快于SAM,分别为0.98秒和1.57秒。
- 总体处理时间:FastSAM总共需要1.43秒,而SAM需要4.37秒。
模型效果:

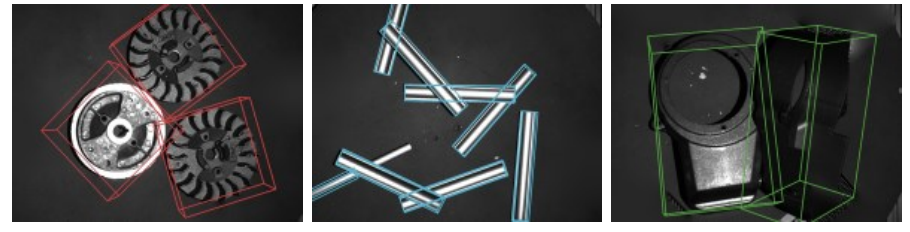

分享完成~
本文先介绍到这里,后面会分享“6D位姿估计”的其它数据集、算法、代码、具体应用示例。



















 683
683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











