







小罗碎碎念
两天前哈佛Faisal Mahmood课题组发布新的多模态病理基础模型TITAN,预印版论文和代码均已发布。
这篇论文**《Multimodal Whole Slide Foundation Model for Pathology》**提出了一种多模态全切片基础模型(TITAN),用于病理学中的图像和文本对齐。

与其他依赖单一视觉预训练或视觉-语言对齐的切片基础模型相比,TITAN结合了这两种策略,确保切片表示包含丰富且全面的结构形态语义。TITAN在预训练过程中没有使用大型公共组织学切片集合,如TCGA、PAIP、CPTAC、PANDA(这些公开数据通常用于计算病理学基准开发)。
为了尽可能给大家讲清楚TITAN,本期推文我会先介绍TITAN的基本架构,然后再介绍如何申请模型以及安装模型。作者在开源的代码中还提供了一个演示程序,如果大家感兴趣的话,我可以再写一篇推送介绍一下!
公开数据集汇总
虽然最新发布的TITAN没有使用公开数据集,但是对于大多数研究来讲,目前还是比较依赖公开数据集,小罗之前的推文也和大家分享过很多公开数据集,完整版表格也已经上传到知识星球,后续还会持续更新,感兴趣的可以前往获取!
一、多模态病理基础模型
计算病理学领域因基础模型的发展而发生了变革,这些模型通过自监督学习(SSL)将组织病理学感兴趣区(ROIs)编码为多功能且可迁移的特征表示。然而,将这些进展应用于解决患者和切片层面的复杂临床挑战仍受到疾病特异性队列中临床数据有限的制约,尤其是对于罕见临床状况。
本研究提出的TITAN是一种多模态全切片基础模型,该模型通过视觉自监督学习和视觉-语言对齐进行预训练,使用了335,645张全切片图像(WSIs)以及相应的病理报告,并与423,122个由多模态生成型AI协作者生成的合成字幕相结合。无需任何微调或要求临床标签,TITAN能够提取通用目的的切片表示,并生成在资源有限临床场景下,如罕见疾病检索和癌症预后,具有泛化能力的病理报告。
在多样化的临床任务上对TITAN进行了评估,发现TITAN在机器学习设置中,如线性探测、少样本和零样本分类、罕见癌症检索和跨模态检索,以及病理报告生成等方面,均优于基于ROIs和切片的基础模型。
二、TITAN
TITAN(Transformer-based pathology Image and Text Alignment Network)是一个多模态全切片基础模型,它通过视觉自监督学习和视觉-语言对齐进行预训练。
该模型利用了来自马萨诸塞州综合医院的内部收集的多样化肿瘤、感染和炎症病例的335,645张全切片图像(WSIs)。此外,TITAN还使用了超过182,000份病理报告以及由PathChat(https://www.nature.com/articles/s41586-024-07618-3)生成的超过423,000个合成字幕。

TITAN的切片嵌入在多种下游任务上实现了最先进的性能,包括线性探测、少样本和零样本分类、罕见癌症检索、跨模态检索和病理报告生成。
2-1:Mass-340K 数据集统计
Mass-340K包含来自20个器官的335,645张组织切片图像(WSIs),其中包括90.9%的苏木精-伊红染色和9.1%的免疫组化染色组织切片,或者是70.0%的肿瘤性和30.0%的非肿瘤性组织切片。
TITAN预训练(阶段2和3)使用带有配对字幕和医疗报告的Mass-340K的子集。
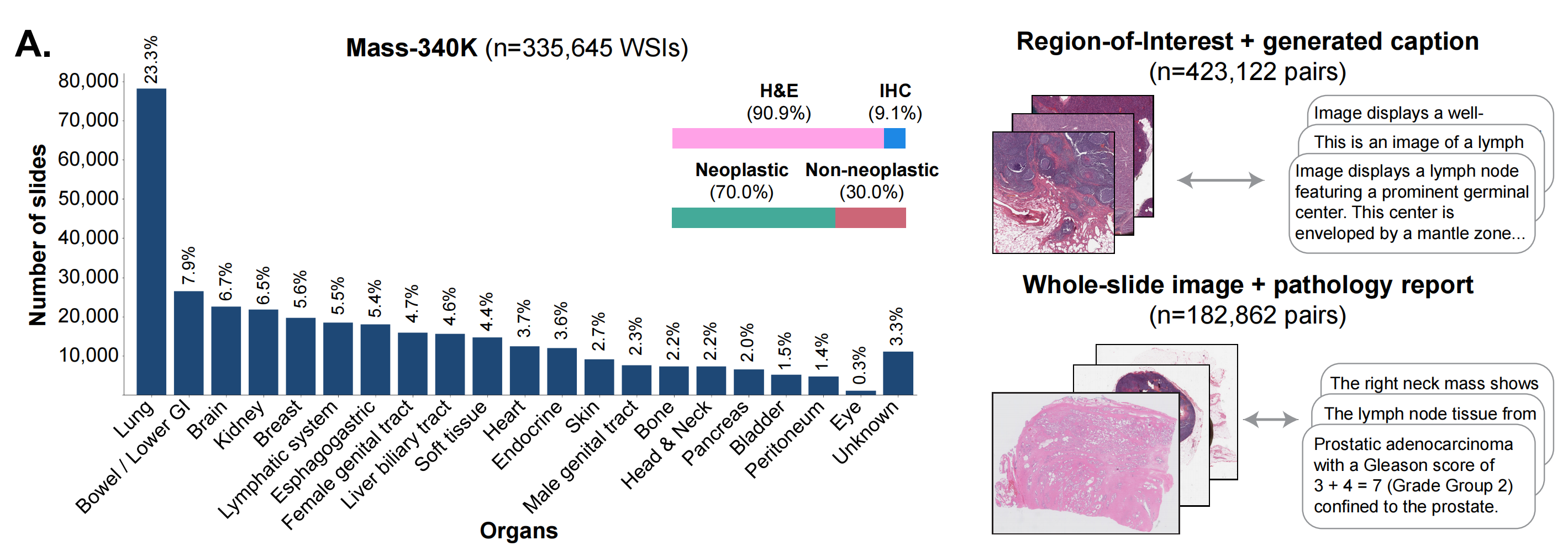
- 总切片数量: 335,645张
- 主要器官及其切片数量:
- 肺 (Lung): 77,332张,占比23.3%
- 肠道/下消化道 (Bowel / Lower GI): 27,677张,占比9.9%
- 脑 (Brain): 22,581张,占比6.7%
- 肾 (Kidney): 21,395张,占比6.3%
- 乳腺 (Breast): 19,006张,占比5.6%
- 呼吸系统 (Ephragmatic system): 18,336张,占比5.5%
- 女性生殖道 (Female genital tract): 17,296张,占比5.4%
- 肝胆道 (Liver biliary tract): 15,154张,占比4.7%
- 软组织 (Soft tissue): 15,154张,占比4.6%
- 心脏 (Heart): 14,256张,占比4.4%
- 内分泌系统 (Endocrine): 11,779张,占比3.7%
- 皮肤 (Skin): 10,179张,占比3.6%
- 男性生殖道 (Male genital tract): 9,054张,占比2.7%
- 骨 (Bone): 8,352张,占比2.3%
- 头颈部 (Head & Neck): 8,301张,占比2.2%
- 胰腺 (Pancreas): 7,966张,占比2.2%
- 膀胱 (Bladder): 7,966张,占比2.0%
- 腹膜 (Peritoneum): 7,966张,占比1.5%
- 眼 (Eye): 5,581张,占比1.4%
- 未知 (Unknown): 11,779张,占比3.3%
切片类型和注释
-
H&E 和 IHC 切片:
- H&E 切片占90.9%
- IHC 切片占9.1%
-
肿瘤和非肿瘤切片:
- 肿瘤切片占70.0%
- 非肿瘤切片占30.0%
感兴趣区域(Region-of-Interest)和生成描述(由pathchat实现)
- 示例图像: 显示了一个淋巴结的图像,描述为“这是一个淋巴结的图像,显示了一个显著的生殖中心,该中心被外套层包围。”
全视野图像和病理报告
- 示例图像: 显示了一个前列腺癌的全视野图像,描述为“右侧颈部肿块显示前列腺组织中的前列腺腺癌,Gleason评分为3+4=7(Grade Group 2),局限于前列腺。”
2-2:学生-教师知识蒸馏的自监督学习
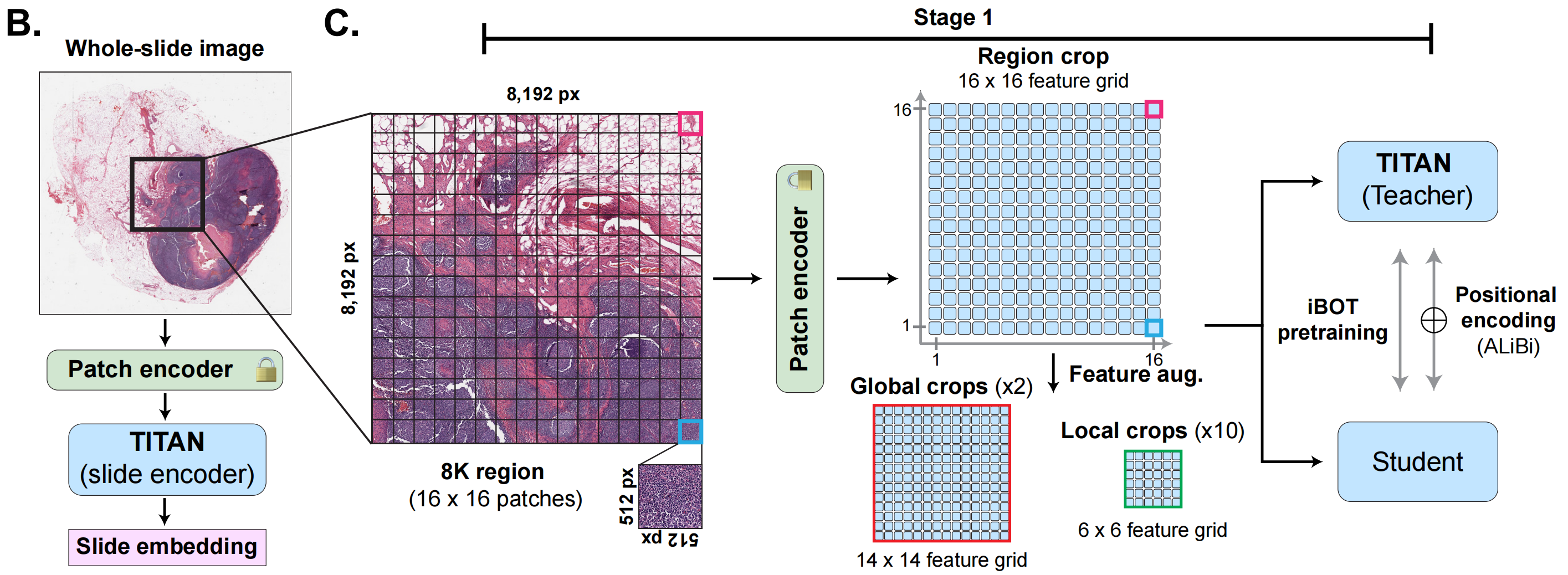
-
Patch encoder(片段编码器):
- 整张切片图像被分割成多个小片段(patches),每个片段的大小为8,192像素。
- 这些片段通过Patch encoder进行处理,生成每个片段的嵌入表示。
-
TITAN (slide encoder)(TITAN滑动编码器):
- 处理后的片段嵌入被传递给TITAN滑动编码器,进一步生成整个切片图像的嵌入表示(slide embedding)。
训练阶段
-
Stage 1(第一阶段):
-
Region crop(区域裁剪):
- 从整张切片图像中裁剪出一个8K区域(16x16个片段)。
-
Patch encoder(片段编码器):
- 裁剪出的8K区域再次被分割成更小的片段,并通过Patch encoder进行处理。
-
-
Feature augmentation(特征增强):
- Global crops(全局裁剪):
- 从整个图像中进行全局裁剪,生成多个全局特征图。
- Local crops(局部裁剪):
- 从局部区域中进行裁剪,生成多个局部特征图。
- Global crops(全局裁剪):
-
iBOT pretraining(iBOT预训练):
- 处理后的特征图被传递给TITAN(教师模型)进行预训练。
- 预训练过程中使用了位置编码(Positional encoding, ALiBi)。
-
Student(学生模型):
- 预训练后的TITAN模型作为教师模型,指导学生模型的训练。
- 学生模型通过学习教师模型的特征表示来提升自身的性能。
2-3:多模态数据对齐
这张图是全文最关键的几张图之一,也是其他推荐过这篇文章的推送里最容易跳过或者一笔带过的图。
首先你要明确,这两张图一张是全局视图,一张是对应的局部视图(8K),明确了这点你才能真正读懂作者的思路!
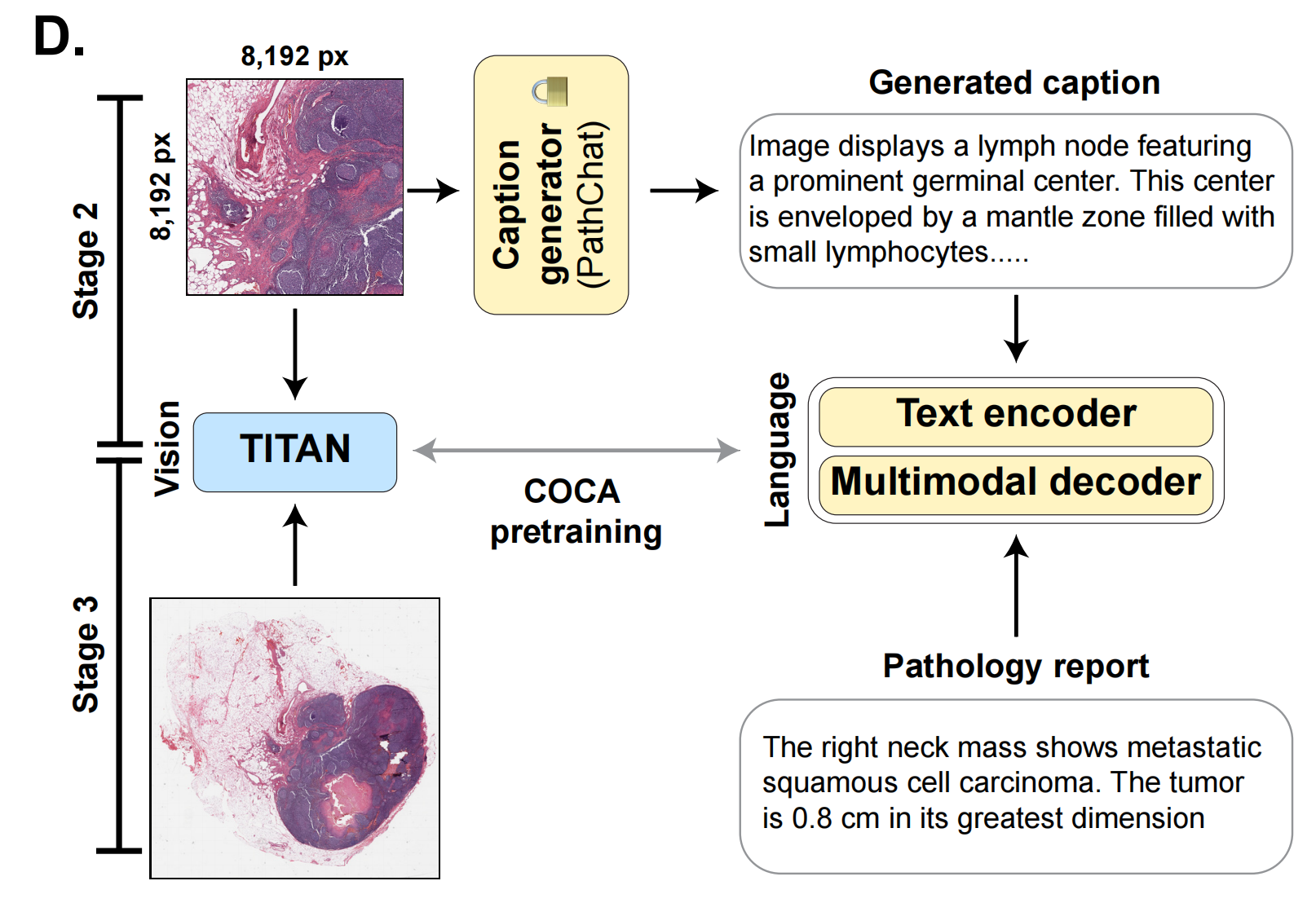
全局的视图对应经过核验的病理报告,局部视图则由之前作者团队发表的PathChat模型进行解读,并给出相应的文字描述。
PathChat生成的文字描述输入文本编码器,而病理报告则输入多模态解码器,随后提取出来的特征经过预训练的过程提供与TITAN建立联系,从而让所有的特征都能被TITAN学习到,所以我们会发现所有的箭头都指向TITAN!
2-4:TCGA切片嵌入的UMAP可视化
UMAP是一种非线性降维方法,能够有效地保留高维数据的结构信息,将其映射到二维或三维空间中进行可视化。
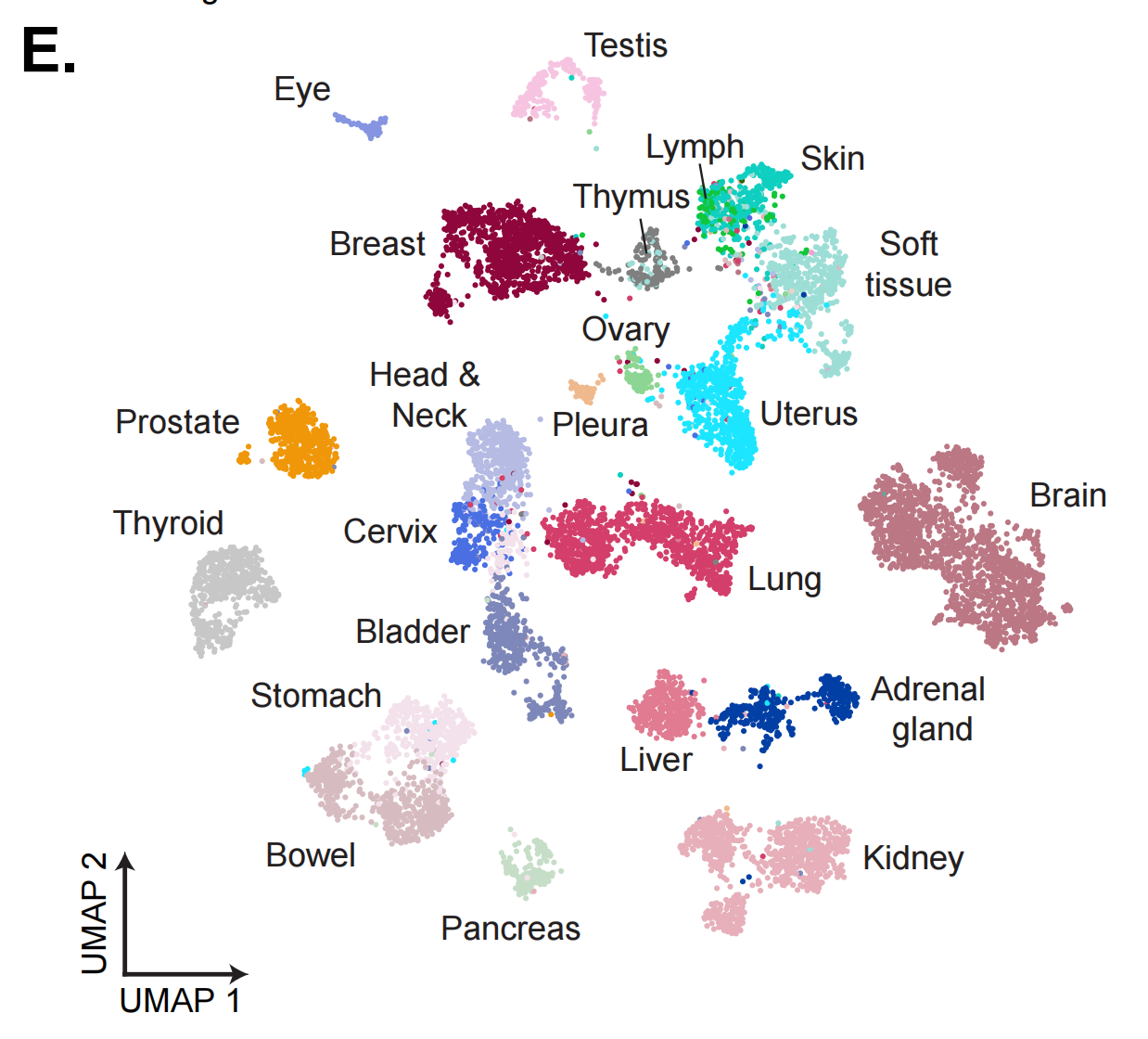
- 不同颜色的点:每个点代表一个样本,不同颜色表示不同的组织类型。图例中列出了各种组织的名称,例如:
- Testis(睾丸)
- Eye(眼睛)
- Lymph(淋巴)
- Thymus(胸腺)
- Skin(皮肤)
- Breast(乳腺)
- Soft tissue(软组织)
- Ovary(卵巢)
- Prostate(前列腺)
- Head & Neck(头颈部)
- Pleura(胸膜)
- Uterus(子宫)
- Brain(大脑)
- Thyroid(甲状腺)
- Cervix(宫颈)
- Lung(肺)
- Bladder(膀胱)
- Stomach(胃)
- Adrenal gland(肾上腺)
- Liver(肝脏)
- Bowel(肠道)
- Kidney(肾脏)
- Pancreas(胰腺)
- UMAP坐标轴:
- UMAP 1:水平轴,表示第一主成分。
- UMAP 2:垂直轴,表示第二主成分。
- 样本分布:
- 不同组织的样本在二维空间中分布情况各异,显示出它们在高维空间中的相似性和差异性。
- 例如,乳腺(Breast)样本集中在一个区域,显示出它们在高维空间中的相似性。
- 其他组织如大脑(Brain)、肺(Lung)等也有各自的集中区域。
三、安装
3-1:环境配置
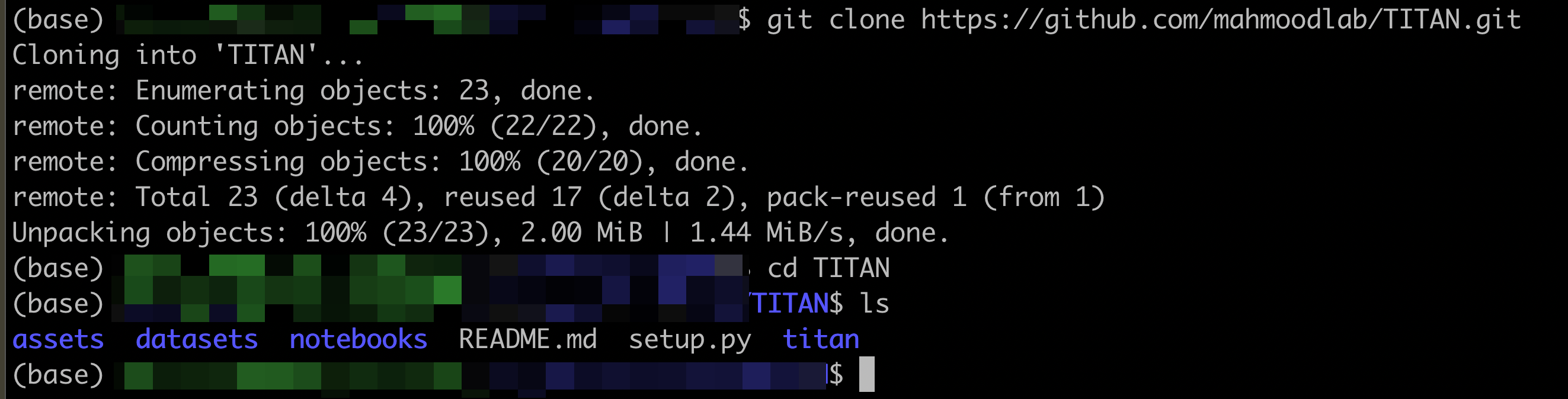
首先,克隆该仓库并进入目录:
git clone https://github.com/mahmoodlab/TITAN.git
cd TITAN
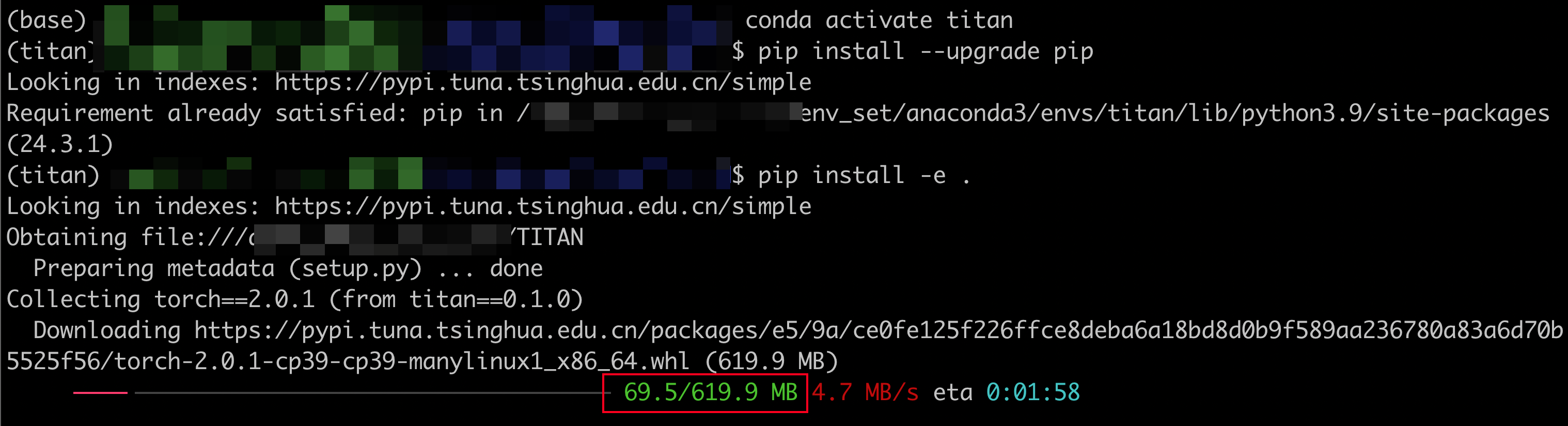
然后,创建一个conda环境并安装依赖项:
# 使用conda创建一个名为titan的新环境,并指定Python版本为3.9,-y表示自动确认所有提示
conda create -n titan python=3.9 -y
# 激活名为titan的环境
conda activate titan
# 使用pip升级当前环境中的pip(Python包管理器)到最新版本
pip install --upgrade pip
# 使用pip在当前环境中安装当前目录下的Python包(-e表示editable模式,即安装开发中的包)
pip install -e .
3-2:获取模型
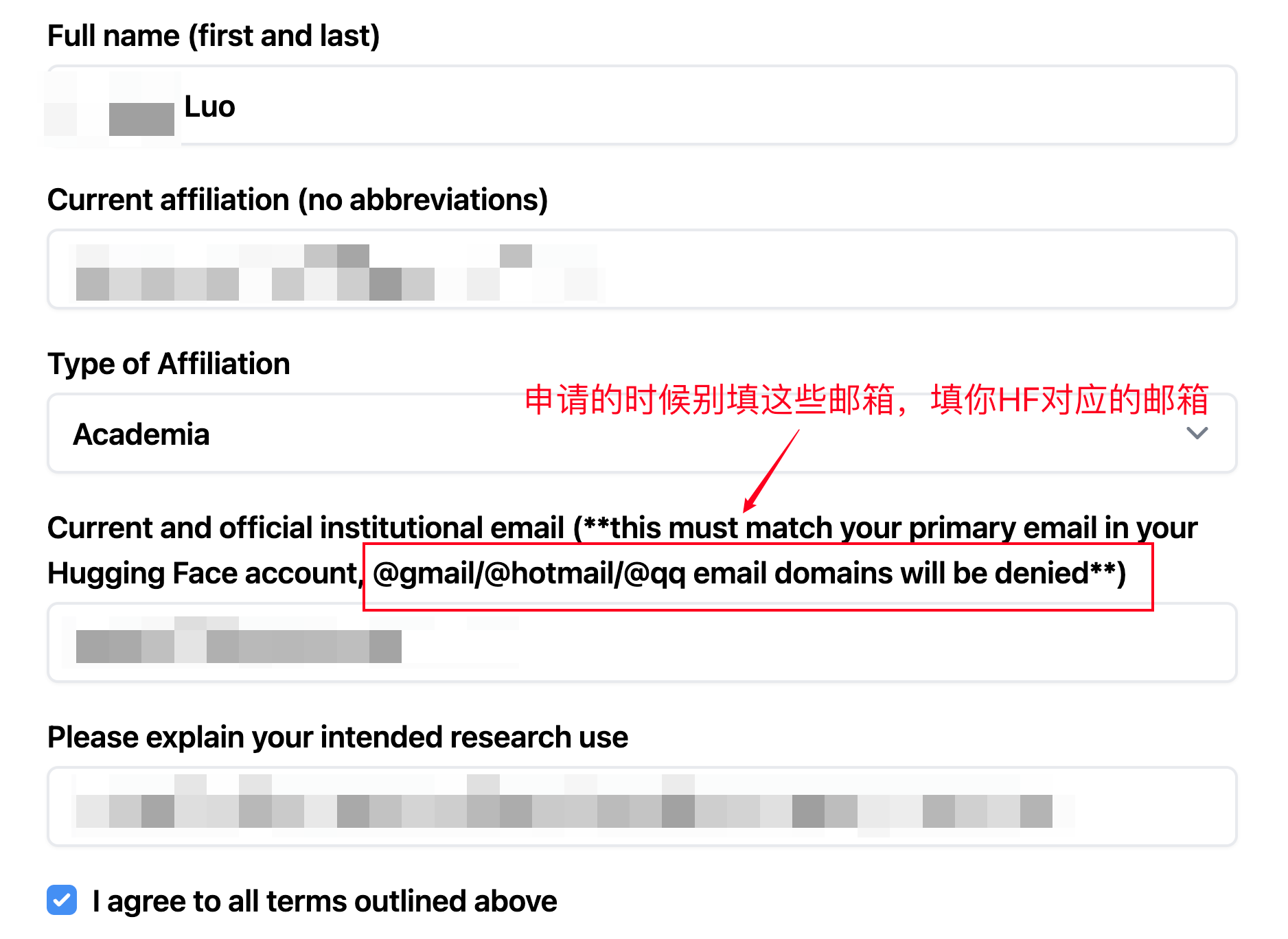
在Huggingface模型页面申请获取模型权重(分别为CONCHv1.5和TITAN-preview,用于补丁和切片特征提取)。
申请成功界面如下。
3-3:下载权重 + 创建模型
在完成认证(使用huggingface_hub)之后,可以按照以下步骤从Huggingface模型中心自动下载TITAN-preview和CONCH v1.5(补丁编码器)。这包括从补丁嵌入中提取切片嵌入的功能,以及执行零样本分类的功能。
from huggingface_hub import login
from transformers import AutoModel
login() # login with your User Access Token, found at https://huggingface.co/settings/tokens
titan = AutoModel.from_pretrained('MahmoodLab/TITAN', trust_remote_code=True)
conch, eval_transform = titan.return_conch()
更多细节请关注我后续的推文,或者直接前往查阅作者的开源代码。


















 6274
6274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









