








本论文来自于2023年ICDE会议
关键词:Long-term time-series forecasting, Transformer, Normalizing Flow
Abstract
长期时间序列预测(LTTF)已成为许多应用中的迫切需求,例如风电供应规划。由于高计算自注意力机制,变压器模型已被采用来提供高预测能力。尽管可以通过引入 LTTF 的逐点自注意力的稀疏性来降低 Transformer 的复杂性,但有限的信息利用率阻碍了模型全面探索复杂的依赖关系。为此,我们提出了一种高效的基于 Transformer 的模型,名为 Conformer,它在三个方面与现有的 LTTF 方法不同:(i)在滑动窗口注意力和固定和平稳的基础上提出了一种结合线性复杂性而不牺牲信息利用率的编码器解码器架构。即时循环网络(SIRN); (ii) 设计了一个从归一化流程导出的模块,通过直接推断 SIRN 中潜在变量的输出来进一步提高信息利用率; (iii) 时间序列数据中的序列间相关性和时间动态被明确建模,以促进下游的自注意力机制。对七个真实世界数据集的广泛实验表明,Conformer 优于 LTTF 上最先进的方法,并通过不确定性量化生成可靠的预测结果。
I. INTRODUCTION
时间序列数据随着时间的推移而演变,这可能会导致短期和长期的时间演变模式令人困惑。时间序列数据的时间演化性质对于许多下游任务非常重要,包括时间序列分类、异常值检测和时间序列预测。在这些任务中,时间序列预测(TF)吸引了许多应用领域的研究人员和从业者,例如交通和城市规划[1]、能源和智能电网管理[2]以及天气[3] ]和疾病传播分析[4]。
在许多实际应用场景中,由于记录了大量的时间序列数据,因此需要提前做出决策,这样通过长期预测,可以最大化收益,同时也可以规避潜在风险。避免了。因此,在这项工作中,我们研究的是展望未来的时间序列预测问题,即长期时间序列预测(LTTF)。
虽然统计学习者已经提出了大量的 TF 方法 [5]-[8],但领域知识的使用对于 TF 的时间依赖性建模似乎是必不可少的,但也限制了应用的潜力。最近,针对 TF 提出了深度模型 [9]-[13],可以分为两类:基于 RNN 的模型和基于 Transformer 的模型。基于 RNN 的方法捕获并利用长期和短期时间依赖性来进行预测,但无法在长期时间序列预测任务中提供良好的性能。由于使用了自注意力机制,基于 Transformer 的模型在提取 LTTF 时间模式方面取得了可喜的性能。然而,这种“全”注意力机制给 TF 任务带来了二次计算复杂度,从而成为基于 Transformer 的模型解决长期时间序列预测任务的主要瓶颈。
一些工作致力于提高自注意力机制的计算效率,并将处理长度为 L 的序列的复杂度降低到 (O(L log L) 或 O(L√L)),例如 Logtrans [14], Reformer [12]、Informer [15] 和 Autoformer [13]。在 NLP 领域,已经提出了一些开创性的工作来将 self-attention 的复杂度降低为线性(O(L)),包括 Longformer [16] 和 BigBird [17]。然而,这些具有线性复杂度的深度模型可能会限制信息利用率并影响 LTTF 的性能。在不牺牲信息利用率的情况下将计算复杂度降低到 O(L) 对 LTTF 来说是一个巨大的挑战。
除了复杂性之外,随着输入长度的增加,复杂的时间序列可能会表现出模糊和混乱的时间模式,这可能会导致基于自注意力的模型的预测不稳定。此外,多元长期时间序列通常体现不同时间分辨率的多种时间模式,例如秒、分钟、小时或天。另一方面,时间序列数据错综复杂且普遍存在的多维特征表现出不同序列之间多方面的复杂相关性。因此,如何使 LTTF 的预测更加稳定并分解时间序列数据中的多尺度动态和多变量依赖性是另外两个挑战。
为此,我们的工作致力于上述三个挑战,并提出了一种基于 Transformer 的 LTTF 新颖模型,即 Conformer。特别是,Conformer 首先明确地指出通过快速傅立叶变换 (FFT) 和多尺度动态提取来探索序列间相关性和时间依赖性。然后,为了以线性计算复杂度的序列到序列方式解决 LTTF 问题,在滑动窗口自注意力机制和所提出的静态和即时循环网络(即 SIRN)之上采用编码器-解码器架构。更具体地说,滑动窗口注意力允许每个点关注其本地邻居以供参考,因此专用于长度为 L 的时间序列的自注意力需要 O(L) 复杂度。此外,为了在不违反线性复杂性的情况下探索时间序列数据中的全局信号,我们更新了循环神经网络(RNN)的循环结构,并使用序列分解模型提取长期时间序列中的平稳和瞬时模式。循环方式。
此外,为了减轻时间序列数据的任意不确定性[18]造成的波动影响并提高LTTF的预测可靠性,我们进一步努力对时间序列数据的底层分布进行建模。具体来说,我们设计了一个归一化流块来吸收 SIRN 模型中产生的潜在状态并直接生成未来序列的分布。更具体地说,我们利用编码器的输出潜在状态以及解码器的潜在状态作为输入来启动标准化流程。之后,可以级联解码器的潜在状态来推断目标序列的分布。沿着这条线,可以进一步提高LTTF的信息利用率,并且可以以更具抗噪声能力的生成方式实现时间序列预测。
对七个真实世界数据集的广泛实验验证了 Conformer 的性能优于最先进的 (SOTA) 基线,并且具有令人满意的裕度。总而言之,我们的贡献可突出如下:
1.借助窗口注意力和更新的循环网络,我们在不牺牲预测能力的情况下将自注意力的复杂性降低到 O(L)。
2.我们设计了一个归一化流块来直接从隐藏状态推断目标序列,这可以进一步改进预测并使输出具有不确定性意识。
3.对五个基准数据集和两个收集的数据集进行的广泛实验验证了 Conformer 卓越的长期时间序列预测性能。
II. RELATED WORK
A. Methods for Time-Series Forecasting
许多统计方法在时间序列预测(TF)方面取得了巨大成功。例如,ARIMA [5] 可以灵活地包含多种类型的时间序列,但有限的可扩展性限制了其进一步的应用。向量自回归 (VAR) [6]、[7] 通过发现高维变量之间的依赖性,在多元 TF 方面取得了重大进展。此外,TF问题还存在其他传统方法,如SVR[8]、SVM[19]等,它们也在不同领域发挥着重要作用。
另一条研究重点是 TF 的深度学习方法,包括基于 RNN 和 CNN 的模型。例如,LSTM [20] 和 GRU [21] 在提取长期和短期依赖性方面表现出了各自的优势,LSTNet [1] 结合了 CNN 和 RNN 来捕获时间序列数据中的时间依赖性,DeepAR [9] 利用自回归模型以及 RNN,对未来时间序列的分布进行建模。还有一些关注CNN模型的工作[22]-[25],它们可以通过卷积捕获时间序列数据的内部模式。
Transformer[26]由于其有效的自注意力机制,在NLP问题上表现出了巨大的优越性,并已成功扩展到许多不同的领域。将 Transformer 应用于 TF 任务的尝试有很多,主要思想在于通过关注 self-attention 机制的稀疏性来突破效率瓶颈。 LogSparse Transformer [14] 允许每个点以指数步长关注自身及其之前的点,Reformer [12] 探索散列自注意力,Informer [15] 利用概率估计来减少时间和内存复杂性,Autoformer [ 13]研究自相关机制代替自注意力。上述所有模型都将 self-attention 的复杂度降低到了 O(L log L)。稀疏变换器 [27] 通过注意矩阵分解将复杂度降低到 O(L√L)。最近的 Longformer [16] 和 BigBird [17] 采用了多种注意力模式,可以进一步将复杂度降低到 O(L)。然而,上述复杂性的降低通常是以牺牲信息利用率为代价的,并且当 LTTF 任务中的时间模式复杂时,自注意力机制可能不可靠。
B. Generative Models
有些工作试图了解未来时间序列数据的分布。高斯混合模型(GMM)[28]可以通过EM算法学习复杂的概率分布,但它无法适应动态场景。吴等人。 [29]提出了一种使用动态高斯混合的 TF 生成模型。 [30]设计了一种端到端模型,通过生成参数分布来进行连贯的概率预测。此外,[31]的作者提出了一种自回归模型来学习数据的分布并进行概率预测。
变分推理被提出用于生成建模,并引入潜在变量来解释观察到的数据[32],这为推理提供了更大的灵活性。 GAN [33]和VAE [34]在分布推理方面都表现出了令人印象深刻的表现,但繁琐的训练过程加上对新数据的有限泛化阻碍了它们更广泛的应用。归一化流 (NF) 是一系列生成模型,NF 是简单分布的转换,从而产生更复杂的分布。 NF 模型已成功应用于许多领域,以学习棘手的分布,包括图像生成、噪声建模、视频生成、音频生成等。Conformer 采用 NF 作为 LTTF 的内部块来吸收编码器-解码器架构中的潜在状态,这与之前的作品有所不同。
III. PROBLEM STATEMENT
我们在本节中介绍问题定义。给定长度为 L 的时间序列 X = {x1, x2, · · · xL| xi ∈ Rdx } 其中 xi 不限于单变量情况(即 dx ≥ 1),时间序列预测问题将长度为 Lx 的时间序列 X = {xm+1, · · · , xm+Lx } 为输入来预测未来长度-Ly 时间序列 Y = {xn+1, · · · , xn+Ly } (n = m + Lx 且 m = 1, · · · , L − Ly)。为了清楚起见,我们表示 Y = {yn+1, · · · , yn+Ly | yj ∈ X }。长期时间序列预测是对Ly较大的未来时间序列进行预测。
IV. METHODOLOGY
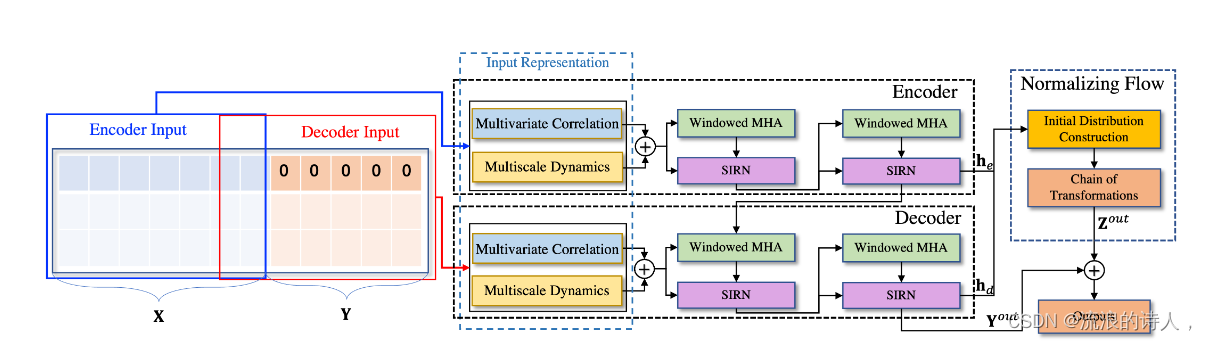 图1:Conformer的框架概述。特别是,编码器使用滑动窗口多头注意力(MHA)提取局部模式,并使用所提出的 SIRN 模块探索长期趋势和即时模式。然后,解码器接收长序列输入,其中目标元素被填充为零,测量多面时间模式的加权组合,并生成目标元素的预测。最后,归一化流块吸收编码器-解码器架构中产生的潜在状态,并直接通过一系列可逆变换来预测目标元素。
图1:Conformer的框架概述。特别是,编码器使用滑动窗口多头注意力(MHA)提取局部模式,并使用所提出的 SIRN 模块探索长期趋势和即时模式。然后,解码器接收长序列输入,其中目标元素被填充为零,测量多面时间模式的加权组合,并生成目标元素的预测。最后,归一化流块吸收编码器-解码器架构中产生的潜在状态,并直接通过一系列可逆变换来预测目标元素。
Conformer的框架概述如图1所示。Conformer主要由三部分组成:输入表示块、编码器-解码器架构和归一化流块。首先,输入表示块相应地预处理并嵌入输入时间序列。然后,编码器解码器架构通过时间序列表示的窗口注意力来探索局部时间模式,并借助循环网络和时间序列分解从静态和即时角度检查长期复杂的动态。此外,为了提高信息利用率,归一化流块利用循环网络中的潜在状态并直接从潜在状态生成目标序列。这三个组件的技术细节将在下面的小节中介绍。
A. Input Representation
时间序列数据表现出复杂的模式,因为多方面的基础信号通常是复杂且变化的。给定一个长度为 L 的时间序列 X ,X = {x1, x2, · · · , xL|xi ∈ Rdx } (dx ≥ 1),我们从两个角度研究 X 中潜在的多方面相关性,即“垂直”特征视角和“水平”时间视角。
1) Multivariate Correlation:
多元时间序列中不同变量之间的复杂相关性阻碍了区分和利用重要信号进行未来序列预测的有效性。一方面,不同变量对预测未来序列的影响不同。
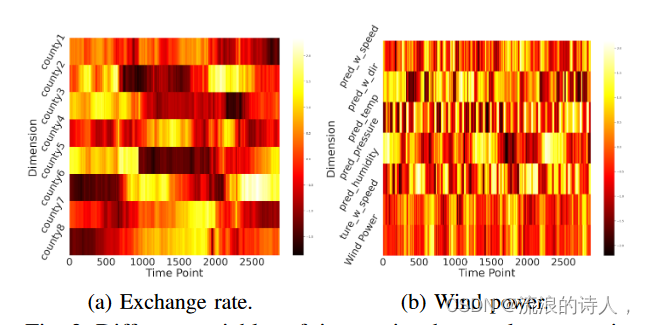
图 2:时间序列数据的不同变量以不同的节奏和动态演变。这些数据集的详细信息可以在第 V-A1 节中找到。
例如,图2中的热图说明了不同时间序列数据集中不同变量的节奏,很明显不同的变量与目标变量表现出明显的相关性,并且也会随着时间的推移而变化。另一方面,变量之间充分利用的依赖性可以有利于时间序列预测。快速傅里叶变换(FFT)[35]已被证明可以有效地发现时间序列数据的相关性[36]-[38]。受此启发,我们通过探索自相关性,采用 FFT 来表示长度为 L 的时间序列的隐式多元相关性,如下所示:
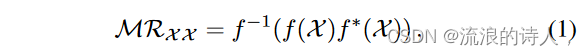
其中f和f -1 分别表示FFT和逆FFT。星号代表共轭运算。此外,我们使用 Softmax 来相应地突出显示信息变量:
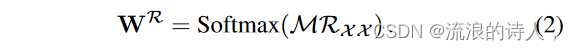
2) Multiscale Dynamics:
时间模式有助于解决长期时间序列预测问题[39]。我们通过多尺度表示进一步检查时间模式。具体来说,时间序列可以在不同的时间分辨率下呈现不同的时间模式。换句话说,应该更多地关注在某些时间分辨率下提取的信息动态。
为了实现不同尺度的时间模式提取,我们首先为 X 设计一个时间分辨率集 S j {秒,分,小时,日,周,月,年}。然后得到采样时间序列集合ГS = {ГS1,····,ГSK},其中K表示时间分辨率的数量,ГSk是对应时间分辨率Sk下的采样时间戳序列。然后,将 ГS 中的每个级数嵌入到 d×L 维的潜在空间中,使得 ГS 中的不同级数是可加的:
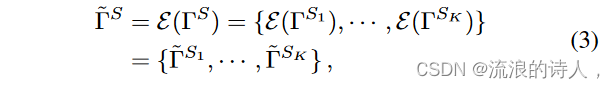
其中 E 表示嵌入操作,̃ ΓSk ∈ Rd×L 表示特定时间分辨率 Sk 下的嵌入序列。然后多尺度时间模式可以建模为
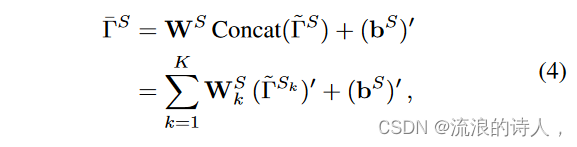
其中 WS ∈ RL×L×K 和 bS ∈ Rd×L 分别是可训练的权重和偏差。主符号表示矩阵转置。此外,WS k ∈ RL×L 表示 WS 的第 k 个切片矩阵。
3) Fusing Multivariate and Temporal Dependencies:
此外,为了使多元时间序列中的不同变量更容易区分。由于它们对未来系列的重要性,我们进一步应用卷积来考虑时间依赖性,其定义如下:
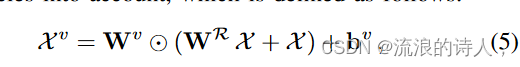
其中 表示卷积运算,Wv ∈ Rdx×d 和 bv ∈ Rd×L 分别表示权重和偏差。最后,通过将上述多元相关性和多尺度动力学与方程相结合。根据式(2)和式(5),可以得到结果时间序列表示如下:
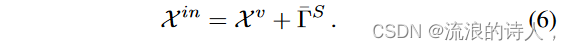
B. Encoder-Decoder Architecture
我们提出的 Conformer 采用编码器-解码器架构进行长期时间序列预测。
1) Attention Mechanism:
标准注意力机制 [26] 采用三元组(查询、键、值)作为输入,并使用缩放点积和 Softmax 来计算针对值的权重,如下所示: Attn(Q, K, V ) = Softmax( QKT √dk )V ,其中 Q ∈ RL×dk 、K ∈ RL×dk 和 V ∈ RL×dv 分别表示查询、键和值。此外,多头注意力(MHA)[26]对原始查询、键和值进行 N 次投影,第 i 个投影查询、键和值可以通过 Qi = QW Q i , Ki 获得= KW K i ,且 Vi = V W Vi ,其中 WQ i ∈ Rdk×dk/N ,W K i ∈ Rdk×dK /N ,且 W Vi ∈ Rdv×dv/N 。之后,可以并行地将注意力应用于这些查询、键和值,并且结果被进一步连接和投影,如下所示:
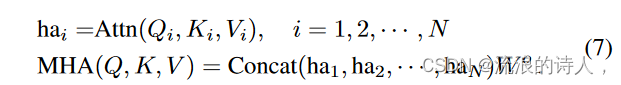
Sliding-Window Attention.
重复的消息存在于完全自我关注的不同头部中[40]。时间序列通常表现出很强的参考局部性,因此可以从其邻居中导出有关点的大量信息。因此,完整的注意力消息对于未来的系列预测可能过于冗余。考虑到 TF 局部性的重要性,滑动窗口注意力(具有固定的窗口大小 w)允许每个点关注其每一侧的 1 2 w 个邻居。因此,该模式的时间复杂度为 O(w × L),随输入长度线性缩放。因此,我们采用这种窗口注意力来实现自注意力。
2) Stationary and Instant Recurrent Network: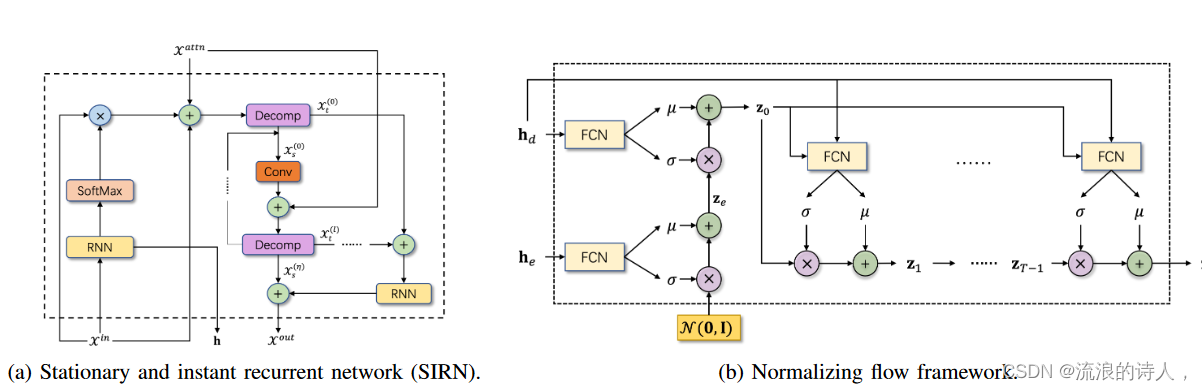
图 3:SIRN 的架构和归一化流程框架。 (a) 第一个 RNN 块嵌入输入时间序列的全局信息,第二个 RNN 块表示分解块提取的聚合趋势信息。初始分解之后的分解过程可以重复多次。第一个 RNN 产生的潜在状态将用于标准化流框架。 (b) 使用等式启动转换流程后。 (15)和(16)中,采用解码器的潜在状态来生成目标变量。
虽然窗口注意力可以将复杂度降低到 O(L),但由于点稀疏连接,LTTF 可能会牺牲信息利用率。 RNN 在许多序列数据应用中取得了巨大成功[41]-[44],这归因于它们通过节点网络中的循环捕获序列动态的能力。为了在不增加时间和内存复杂性的情况下提高信息利用率,我们相应地更新了循环网络。特别是,我们不仅从输入序列中提取静态(趋势)和即时(季节性)时间模式,而且还将提取的长期模式以及上述局部时间模式集成到时间序列表示中。所提出的固定和即时循环网络(SIRN)的架构如图 3a 所示具体来说,我们将输入表示馈送到第一个 RNN 块(后跟 Softmax)以初始化全局表示并将其添加到局部表示以及原始输入表示,如下所示: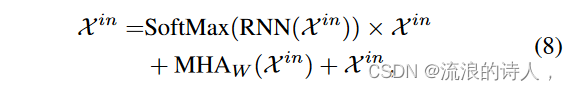
其中 MHAW (·) 表示滑动窗口注意力。请注意,方程第一项中的 RNN 块(后跟 Softmax)。 (8)旨在捕获全局时间依赖性,这可以补充窗口注意力捕获的局部依赖性。
尽管复杂多样,不同时间序列数据中的复杂时间模式可以大致分为(粗粒度)平稳趋势和(细粒度)即时模式。沿着这条线,我们采用[13]、[45]中引入的序列分解,通过捕获时间序列数据的趋势和季节性部分来提取静态和即时模式。与[13]类似,我们采用移动平均线来捕捉长期趋势,并将原始序列减去移动平均线的残差作为季节性模式:
![]()
其中Xt、Xs ∈ RL×dx 分别表示X in 的趋势部分和季节性部分。然后,我们使用卷积层来嵌入季节性模式。并且,我们将嵌入的表示与本地表示一起提供给另一个分解块,以提取更多的季节性模式。该蒸馏过程可以以循环方式实现:
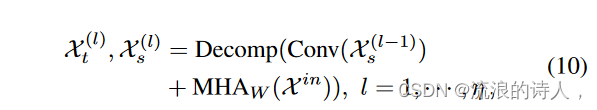
其中 Decomp 表示方程。 (9)、X(0)s=Xs,X(0)t=Xt。另一方面,不同分解生成的趋势部分被合并并馈送到第二个 RNN 块。最后,融合提炼的多方面时间动态以生成结果表示:
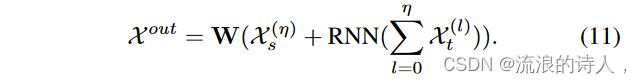
C. Time Series Prediction with Normalizing Flow
上述SIRN框架采用RNN来提取全局信号。此外,RNN 产生的隐藏状态有利于理解时间序列数据的分布。具体来说,我们设计了一个归一化流块来学习隐藏状态的分布,以提高预测的可靠性。
1) Background of Normalizing Flow:
X = {x1, · · · , xL} 可以通过最大化边际对数似然来重建:log p(X ) = ΣL i=1 log p(xi)。由于这种对数似然的棘手性,引入了针对潜在变量 z(即 q(z|x))的参数推理模型。然后,可以优化每个观测值 x 的边际对数似然的变分下界,如下所示:
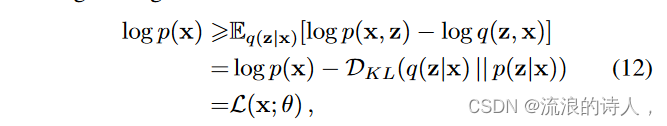
其中 DKL(·) 表示 Kullback-Leibler 散度。当z维数上升时,通常采用对角后验分布,然而,它不够灵活,无法匹配复杂的真实后验分布[46]。为了解决这个问题,提出了归一化流[47]来构建灵活的后验分布。'
基本上,可以从一个初始随机变量 z0 (具有简单的分布,加上已知的密度)开始函数),然后应用一系列可逆变换 ft,使得结果 zT 具有更灵活的分布:
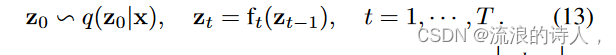
2) Normalizing Flow for LTTF:
Conformer 中所提出的标准化流程架构如图 3b 所示。令 h 表示 SIRN 中第一个 RNN 块产生的隐藏状态。然后,从高斯分布中抽取一个随机变量,即 v N (0, I),编码器中隐藏状态的分布可以得到:
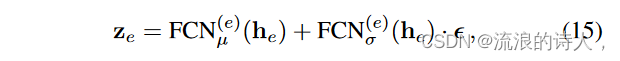
其中FCN(e) μ和FCN(e) σ是两个全连接网络,他表示编码器中的隐藏状态。之后,我们将潜在表示 ze 和解码器潜在状态 hd 作为输入来启动归一化流程:
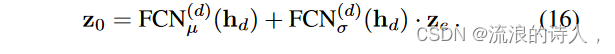
那么归一化流程可以迭代如下:
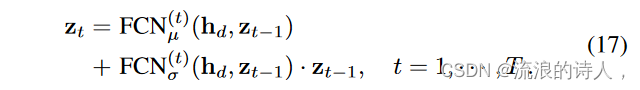
在这里,我们利用解码器潜在状态来级联消息,以便可以直接生成未来的序列。
D. Loss Function
为了与Conformer的其他部分协调,常用的对数似然代替了MSE(均方误差)损失函数来学习归一化流框架。特别地,从结果分布中采样的随机变量,即zt,被视为目标序列的点估计。然后,我们采用MSE损失预测函数编码器解码器架构和归一化流框架的目标系列。最后,损失函数定义如下:
![]()
其中Youth和Zout分别表示解码器和归一化流的输出,λ是平衡编码器解码器和归一化流的相对贡献的权衡超参数。
V. EXPERIMENTS
A. Experiment Settings
1) Datasets:
我们在七个数据集上进行实验,其中包括五个基准数据集和两个收集数据集。表一描述了这些数据集的一些基本统计数据。
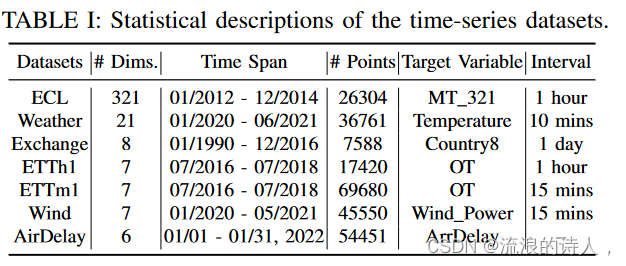
ECL1是从2011年到2014年以15分钟的间隔收集的。我们选择2012年到2014年的记录,因为2011年存在许多零值[1]。处理后的数据集包含 321 个客户每小时的用电量。我们使用“MT 321”作为目标,训练/验证/测试为12/2/2个月。
ECL1是从2011年到2014年以15分钟的间隔收集的。我们选择2012年到2014年的记录,因为2011年存在许多零值[1]。处理后的数据集包含 321 个客户每小时的用电量。我们使用“MT 321”作为目标,训练/验证/测试为12/2/2个月。
Exchange[1]记录了1990年至2016年8个国家的每日汇率。我们以新加坡的汇率为目标,train/val/test为16/2/2年。
ETT [15]记录电力变压器的温度。每个数据点由六个电力负荷特征组成,目标值为“油温”。该数据集分为 {ETTh1, ETTh2} 和 {ETTm1, ETTm2},分别用于 1 小时级别和 15 分钟级别的观测。我们使用 ETTh1 和 ETTm1 作为我们的数据集。 ETTh1 和 ETTm1 的训练/验证/测试分别为 12/2/2 和 12/1/1 个月。
Wind (Wind Power)3 记录风电场在 01/2020 至 07/2021 期间每 15 分钟的风力发电量。训练/验证/测试为 12/1/1 个月
AirDelay 是从 TranStas 数据库中的“On-Time”数据库收集的。我们提取了到达德克萨斯州机场的航班,检查了 2022 年第一个月的到达延误情况,并删除了取消的航班。请注意,该数据集的时间间隔是变化的。该数据集按 7:1:2 分为训练/验证/测试。
2) Baselines:
我们将Conformer与9个基线进行比较,即5种Transformer方法(Autoformer、Informer、Reformer、Longformer和LogTrans)、2种RNN方法(GRU和LSTNet)和2种其他深度方法(TS2Vec和N-Beats) 。
GRU [21]:GRU 采用门控机制,使得每个循环单元自适应地捕获序列中的时间信号。在这项工作中,我们采用 2 层 GRU。
LSTNet [1]:LSTNet 结合了卷积网络和循环网络来提取变量之间的短期依赖性和时间序列中的长期趋势。请注意,为了简化参数调整,省略了高速公路和跳过连接机制。
N-Beats [48]:N-Beats 的提出是为了通过后向和前向残差链接之上的深度模型以及非常深的全连接层堆栈来解决时间序列预测问题。我们使用建议的设置为多元 LTTF 实施 N-Beats。
Reformer [12]:Reformer 使用局部敏感哈希(LSH)注意力和可逆残差层来降低计算复杂度。我们通过将 LSH 注意力的桶长度和轮数分别设置为 24 和 4 来实现 Reformer。
Longformer [16]:Longformer 将窗口注意力与激励全局注意力的任务结合起来,随着序列长度的增长而线性扩展。
LogTrans [14]:LogTrans 通过在因果卷积自注意力的帮助下生成查询和键,打破了 Transformer for LTTF 的内存瓶颈。 LogTransformer 块的数量设置为 2,稀疏注意力的子长度设置为 1。
Autoformer[13]:Autoformer借助自相关机制革新了级数分解,将级数分解作为深层模型的基本内部块。
TS2Vec [49]:TS2Vec 是学习时间序列表示的通用框架。它通过增强上下文视图以分层方式执行对比学习,从而为每个时间戳提供稳健的上下文表示。我们使用建议的设置为单变量 LTTF 实现 TS2Vec。
所有基线均采用一步预测策略。对于基于 RNN 的方法,隐藏状态的数量从 {16,24,32,64} 中选择。对于基于 Transformer 的方法,实验中所有注意力机制的自注意力头数为 8,维数设置为 512。此外,Informer和Autoformer的selfattention的采样因子都设置为1,其他设置与[13]的建议相同。所有基于 Transformer 的基线(Autoformer 除外)都使用相同的嵌入方法应用于举报人。正如[13]所建议的,我们省略了位置嵌入并保留了 Autoformer 的值嵌入和时间戳嵌入。
3) Implementation Details:
Conformer5 包括一个 2 层编码器和一个 1 层解码器,以及一个 2 层归一化流块。滑动窗口注意力的窗口大小为2,式(1)中的λ为2。 (18) 设为 0.8。我们使用 Adam 优化器,初始学习率为 1 × 10−4。批量大小为 32,训练过程采用 10 个 epoch 内的提前停止。此外,我们使用MAE(平均绝对误差)和MSE(均方误差)作为评价指标。
应用输入 Lx-预测-Ly 窗口分别以一个时间步长滚动训练集、验证集和测试集。所有数据集均采用此设置。输入长度 Lx 为 96,预测长度 Ly 在所有数据集上从 {48, 96, 192, 384, 768} 中选择。报告 5 次运行的平均结果。所有模型均在 PyTorch 中实现,并在具有一个 A100 40GB GPU 的 Linux 机器上进行训练/测试。
应用输入 Lx-预测-Ly 窗口分别以一个时间步长滚动训练集、验证集和测试集。所有数据集均采用此设置。输入长度 Lx 为 96,预测长度 Ly 在所有数据集上从 {48, 96, 192, 384, 768} 中选择。报告 5 次运行的平均结果。所有模型均在 PyTorch 中实现,并在具有一个 A100 40GB GPU 的 Linux 机器上进行训练/测试。
B. Prediction Results of Multivariate LTTF
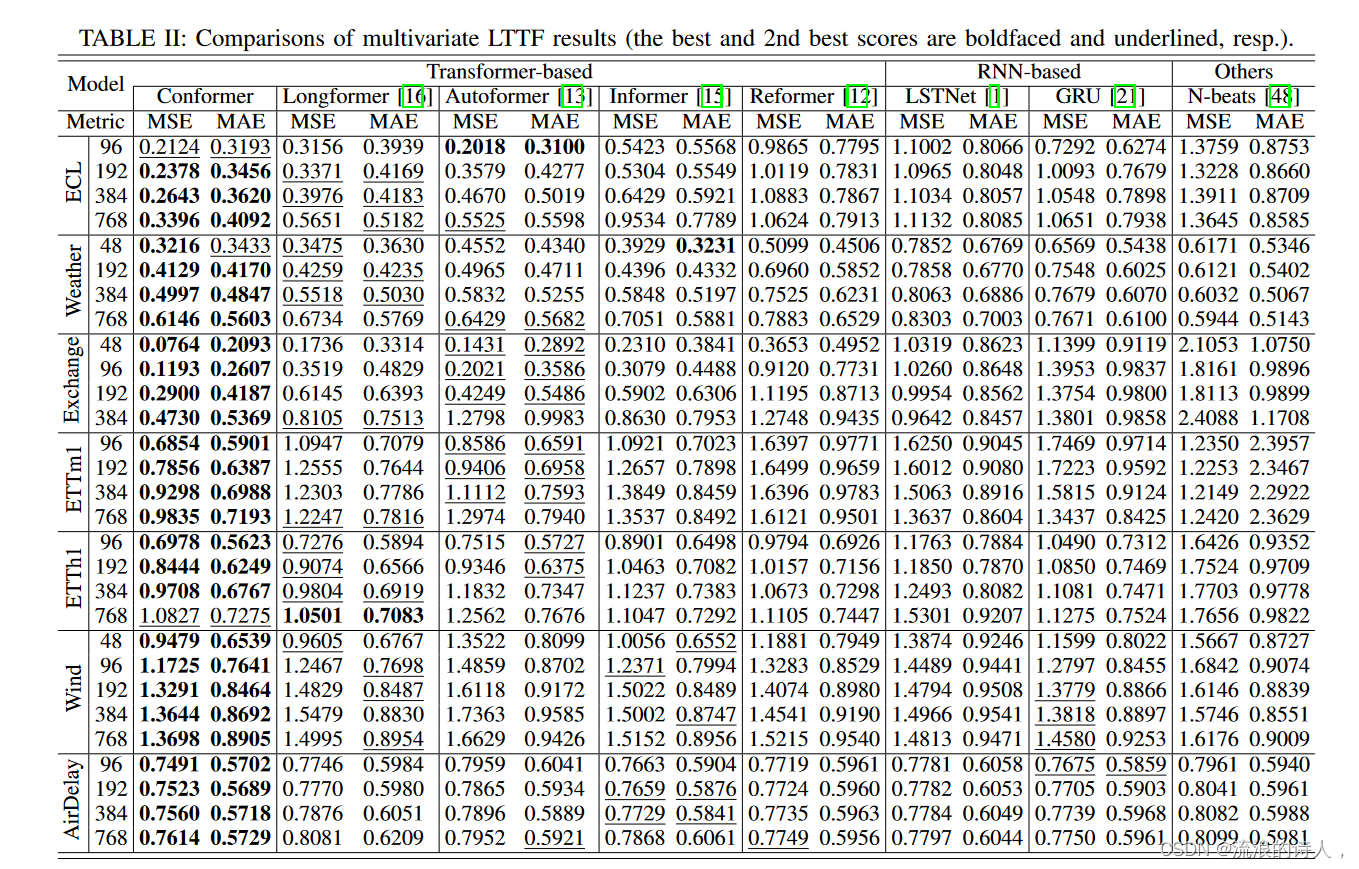 我们在多变量时间序列预测设置下将 Conformer 与其他基线的 MSE 和 MAE 进行比较,结果如表 II 所示。我们可以观察到,在不同的预测长度设置下,Conformer 优于基于 SOTA Transformer 的模型以及其他竞争方法。例如,在predict96设置下,与第二好的结果相比,Conformer的MSE降低了41.0%(0.2021→0.1193)、20.2%(0.8586→0.6854)、5.2%(1.2371→1.1725)和4.1%(0.7276→0.6978)分别在 Exchange、ETTm1、Wind 和 ETTh1 数据集上。此外,当 Ly = 384 时,Conformer 在 Exchange、ECL、ETTm1 和 Weather 上实现了 41.6% (0.8105→0.4730)、33.5% (0.3976→0.2643)、16.3% (1.1112→0.9298) 和 9.4% (0.5518→0.4997) MSE 降低数据集上的 MAE 分别降低了 28.5%(0.7513→0.5369)、13.5%(0.4183→0.3620)和 8.0%(0.7593→0.6988)。此外,当预测长度Ly延长到768时,Conformer在ECL、ETTm1和Wind数据集上分别实现了39.9%(0.5651→0.3396)、19.7%(1.2247→0.9835)和6.0%(1.4580→1.3698)MSE降低,在 ECL 和 ETTm1 数据集上分别增加 21.0% (0.5182→0.4092) 和 9.4% (0.7940→0.7193) MAE 降低。
我们在多变量时间序列预测设置下将 Conformer 与其他基线的 MSE 和 MAE 进行比较,结果如表 II 所示。我们可以观察到,在不同的预测长度设置下,Conformer 优于基于 SOTA Transformer 的模型以及其他竞争方法。例如,在predict96设置下,与第二好的结果相比,Conformer的MSE降低了41.0%(0.2021→0.1193)、20.2%(0.8586→0.6854)、5.2%(1.2371→1.1725)和4.1%(0.7276→0.6978)分别在 Exchange、ETTm1、Wind 和 ETTh1 数据集上。此外,当 Ly = 384 时,Conformer 在 Exchange、ECL、ETTm1 和 Weather 上实现了 41.6% (0.8105→0.4730)、33.5% (0.3976→0.2643)、16.3% (1.1112→0.9298) 和 9.4% (0.5518→0.4997) MSE 降低数据集上的 MAE 分别降低了 28.5%(0.7513→0.5369)、13.5%(0.4183→0.3620)和 8.0%(0.7593→0.6988)。此外,当预测长度Ly延长到768时,Conformer在ECL、ETTm1和Wind数据集上分别实现了39.9%(0.5651→0.3396)、19.7%(1.2247→0.9835)和6.0%(1.4580→1.3698)MSE降低,在 ECL 和 ETTm1 数据集上分别增加 21.0% (0.5182→0.4092) 和 9.4% (0.7940→0.7193) MAE 降低。
另一方面,一般来说,基于 Transformer 的模型优于基于 RNN 的模型。这显示了自注意力机制在提取复杂的时间数据方面的实力高维时间序列数据中的依赖性。此外,随着预测长度的延长,Conformer 的 MSE 和 MAE 分数比其他基线增长得更慢,这表明我们提出的模型具有更好的稳定性。对于有周期性的数据集(例如,天气、ECL)和无周期性的数据集(例如,交换),Conformer 始终提供良好的性能,这表明其具有良好的泛化能力。此外,对于时间间隔不规则的数据集(例如 AirDelay),Conformer 仍然一致地实现了最佳性能,但改进不太显着。这表明,结构化程度较低的时间序列数据中的时间模式对于深度模型来说更具挑战性。
Forecasting with Time-Determined Lengths
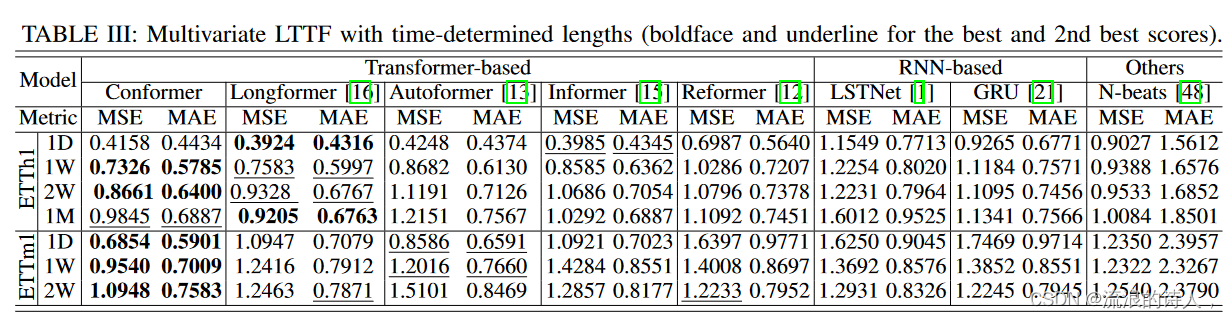 当输入和输出长度配置为时间确定的间隔(例如 1 天)时,我们进一步评估多元 LTTF 的性能。特别地,在该实验中,输入长度Lx设置为1天,输出长度Ly选自{1天(1D)、1周(1W)、2周(2W)、1个月(1M)}。我们检查不同方法在 ETTh1 和 ETTm1 数据集上的预测性能。结果报告于表III中。如图所示,Conformer 仍然实现了最佳(或有竞争力)的性能,这表明 Conformer 在感知长期信号方面具有很高的能力。
当输入和输出长度配置为时间确定的间隔(例如 1 天)时,我们进一步评估多元 LTTF 的性能。特别地,在该实验中,输入长度Lx设置为1天,输出长度Ly选自{1天(1D)、1周(1W)、2周(2W)、1个月(1M)}。我们检查不同方法在 ETTh1 和 ETTm1 数据集上的预测性能。结果报告于表III中。如图所示,Conformer 仍然实现了最佳(或有竞争力)的性能,这表明 Conformer 在感知长期信号方面具有很高的能力。
C. Performance Comparisons Under Univariate LTTF
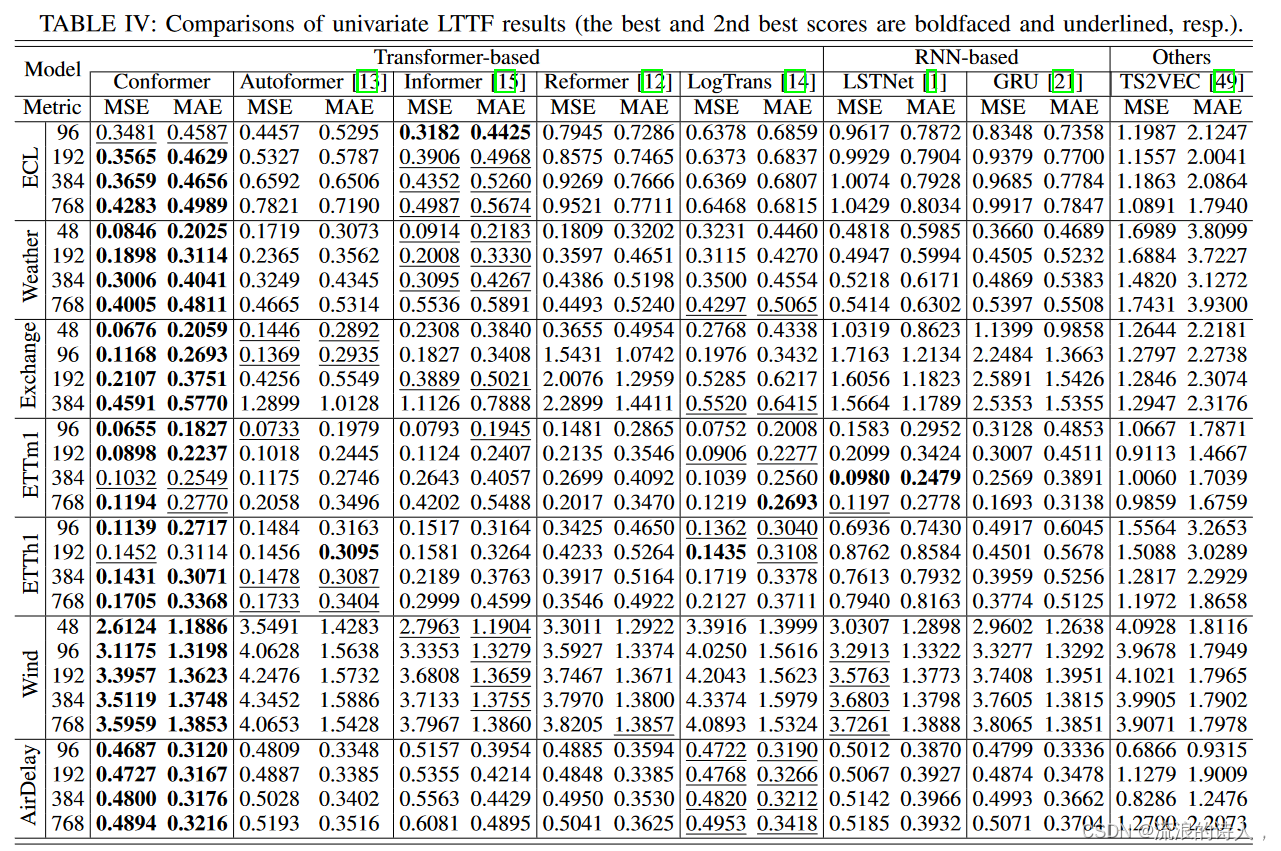 表 IV 报告了单变量 LTTF 设置下不同方法的预测性能。 Conformer 在各种预测长度设置下实现了最佳(或有竞争力)的 MSE 和 MAE 分数。特别是,在 Exchange、ECL 和 Weather 数据集上可以观察到令人满意的预测改进。例如,与第二好的结果相比,Conformer 在 Exchange 数据集的预测 192 下实现了 45.8% (0.3889→0.2107) MSE 降低,以及 15.9%在预测 384 和预测 48 下,在 ECL 数据集上分别为 (0.4352→0.3659),在天气数据集上分别为 7.4% (0.0914→0.0846)。此外,Conformer 在 AirDelay 数据集上仍然取得了最好的分数,这进一步证明了 Conformer 在提取复杂时间模式方面的有效性。此外,在单变量LTTF设置下,我们发现基于RNN的方法在天气和风数据集上取得了有竞争力的预测结果,这可以验证RNN在提取低熵和规则模式的时间序列数据的时间动态方面的优势。
表 IV 报告了单变量 LTTF 设置下不同方法的预测性能。 Conformer 在各种预测长度设置下实现了最佳(或有竞争力)的 MSE 和 MAE 分数。特别是,在 Exchange、ECL 和 Weather 数据集上可以观察到令人满意的预测改进。例如,与第二好的结果相比,Conformer 在 Exchange 数据集的预测 192 下实现了 45.8% (0.3889→0.2107) MSE 降低,以及 15.9%在预测 384 和预测 48 下,在 ECL 数据集上分别为 (0.4352→0.3659),在天气数据集上分别为 7.4% (0.0914→0.0846)。此外,Conformer 在 AirDelay 数据集上仍然取得了最好的分数,这进一步证明了 Conformer 在提取复杂时间模式方面的有效性。此外,在单变量LTTF设置下,我们发现基于RNN的方法在天气和风数据集上取得了有竞争力的预测结果,这可以验证RNN在提取低熵和规则模式的时间序列数据的时间动态方面的优势。
D. Ablation Study
我们在多变量 TF 设置下进行消融研究
1) Multivariate Correlation and Multiscale Dynamics:
我们将 Conformer 与其定制变体进行比较。多变量相关性和多尺度动力学,并报告它们在 ECL 和 ETTm1 数据集上的预测性能。从表 V 中,我们可以获得关于如何嵌入 LTTF 输入序列的一些富有洞察力的线索。 1) X in v. X in −R:当序列维度较高(ECL 数据的 #dims. 远大于 ETTm1 数据)或预测长度延长时,多元相关性的贡献较小。 2) v 中的 X。X in −X −Γ:时间依赖性对于低维序列更重要,而对于高维时间序列,当 Ly 向上爬升时,时间依赖性的有效性可以被序列间相关性所取代。 3) X in −R v. X in −X 和 X in −R− gamma v. X in −X − gamma:多尺度动力学在原始级数的指导下可提供更好的性能,无论#dims如何,它都保持不变。的时间序列。此外,对于低维时间序列,多元相关性比原始数据贡献更大。 4) X in −R v. X in −R− gamma 和 X in −X v. X in −X − gamma:如果原始时间序列为,当配备多变量相关性时,多尺度动力学可能会损害 LTTF 的性能缺席的。
2) Stationary and Instant Recurrent Network (SIRN):
为了对所提出的 SIRN 进行消融研究,我们通过在 Wind 数据集上定制编码器解码器架构来将 Conformer 与其不同变体进行比较,如表 VI 所示。具体来说,我们用其他自注意力机制替换滑动窗口注意力和 RNN,以验证 SIRN 的有效性。从表六中我们可以看到SIRN在不同设置下取得了最佳性能,这验证了结合局部和全局模式的信息利用的有效性。
3) Normalizing Flow:
为了验证 Conformer 中归一化流块对于 LTTF 任务的有效性,我们比较了最初的 Conformer 及其几个变体。特别是,我们通过借助高斯概率模型实现生成预测方法来定制 Conformer 中的归一化流块,如下所示:
图 7 中分别显示了 ECL 和 ETTm1 数据集中的情况。我们可以看到,潜在变量转换得越深,结果序列的表现就越好。因此,应该更专注地探索 LTTF 中 Conformer 中流标准化的威力。
4) How to Feed Hidden States to The Normalizing Flow Block in Conformer:
如图 1 所示,在编码器和解码器中,最后一个 SIRN 层的第一个输出隐藏状态被馈送到归一化流。为了评估将隐藏状态馈送到归一化流的效果,我们通过组合编码器/解码器的第一个/最后一个 SIRN 层中的结果隐藏状态来实现 Conformer,从而得到 Conformer (h(e) k , h(d) k )、Conformer (h(e) 1 、 h(d) k )、Conformer (h(e) 1 、 h(d) 1 ) 和 Conformer (h(e) k 、 h(d) 1 ) 其中 k 表示最后 SIRN 层。我们在表九中报告了预测结果。可以看出,尽管低维时间序列预测对流标准化更敏感,但将不同隐藏状态提供给归一化流的影响通常很小。
I. Discussion
Windowed Attention: Conformer v. Swin Transformer.
窗口注意力机制由于其线性复杂性而被应用于许多应用中,使得强大的自注意力可以扩展到大数据。最近的 Swin Transformer [50] 及其变体 [51] 采用窗口注意力并设计了转移窗口注意力来实现计算机视觉任务的通用主干。基本上,Conformer 和 Swin Transformer 都利用了相邻/分区窗口内关于计算效率。除了地理位置之外,连通性也是另一个不容忽视的优点。为了实现连通性,我们为 Swin Transformer 提出了移位窗口机制,而我们为 Conformer 提出了 SIRN,以吸收时间序列数据中的长程依赖性。、
Comparisons of Computational Complexity.
窗口注意力对于降低 Conformer 的复杂性贡献最大。因此,我们将不同的SOTA注意力机制作为竞争对手来进行第V-F节的计算复杂度分析。 Conformer 中其他组件的计算成本没有详细说明,这将在我们未来的工作中提供。
VI. CONCLUSION
在本文中,我们提出了一种基于变压器的模型,即 Conformer,来解决长期时间序列预测(LTTF)问题。具体来说,Conformer 首先将输入时间序列嵌入多元相关建模和多尺度动态提取,为下游提供动力自注意力机制。然后,为了降低自注意力的计算复杂度并充分提取序列级时间依赖性而不牺牲 LTTF 的信息利用率,滑动窗口注意力以及提出的固定和即时循环网络(SIRN)被装备到符合者。此外,采用归一化流框架来进一步吸收SIRN中的潜在状态,从而可以学习底层分布并可以以生成方式直接重建目标序列。对六个现实世界数据集的广泛实证研究证实,Conformer 在多变量和单变量预测设置下实现了长期时间序列预测的最先进性能。此外,借助归一化流,Conformer可以生成不确定性量化的预测结果

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









