







关于目标检测中的Bounding box回归原理网上已经有很多解释的文章了,但是为了更好的阐述我的问题,一开始我还是先简单的过一下边框回归的基本原理,然后解释我在看源码时遇到的一点疑惑,最后分享一下在网上找的解释和我自己的理解。(文章中涉及到的源码来自torchvision)
一、Bounding box regression
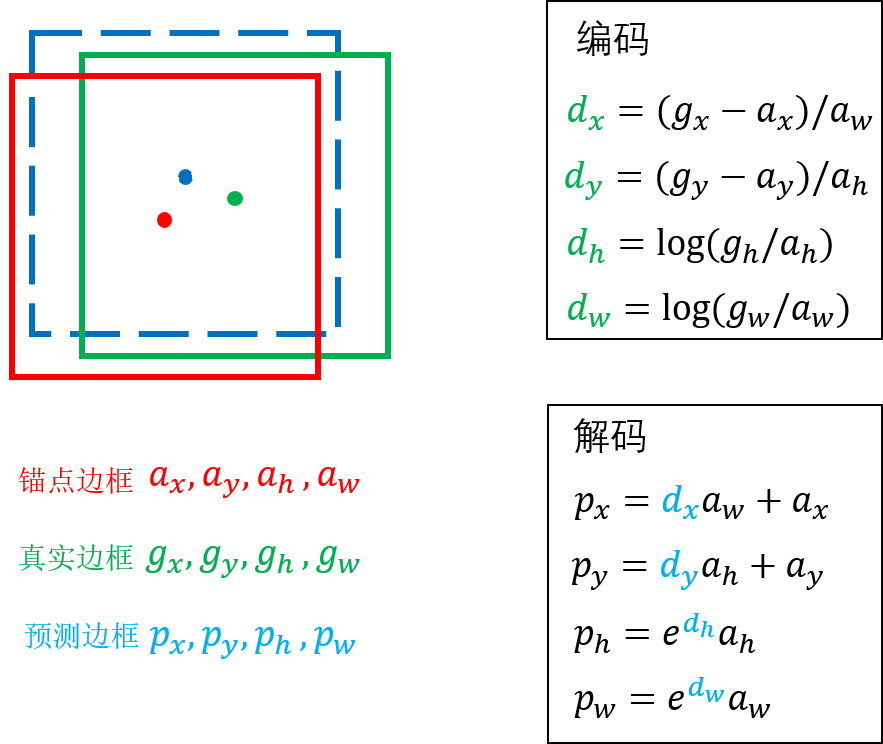
我们以一个边框的回归过程来解释,其中红色表示锚点边框,绿色代表真实边框,蓝色虚线代表预测边框,边框用中心点x,y和宽、高四个值表示。
1.1、编码过程
Faster RCNN网络中的RPN和ROIHeads阶段都分别有一个分类器和回归器,其中回归器就是边框回归的过程,回归器针对每个anchor会预测4个值,这4个值不是预测边框的x,y,h,w,而是预测边框相对于anchor边框的偏移值,即
(
d
x
d_{x}
dx,
d
y
d_{y}
dy,
d
h
d_{h}
dh,
d
w
d_{w}
dw)。我们要想训练回归器,就要找到对应的真实偏移(真实边框相对于锚点边框),这时就要用到编码过程了。对应上图右上方的公式,我们先找到与某一个anchor边框对应的真实边框(根据IOU匹配),使用编码公式获得真实的偏移值,(
d
x
d_{x}
dx,
d
y
d_{y}
dy,
d
h
d_{h}
dh,
d
w
d_{w}
dw)。然后再与回归器得到的(
d
x
d_{x}
dx,
d
y
d_{y}
dy,
d
h
d_{h}
dh,
d
w
d_{w}
dw)计算损失。
1.2、解码过程
RPN的回归器的输出结果在进入ROIHeads之前需要先解码,即将回归器得到的偏移值(
d
x
d_{x}
dx,
d
y
d_{y}
dy,
d
h
d_{h}
dh,
d
w
d_{w}
dw)应用到anchor上获得预测边框的(
p
x
p_{x}
px,
p
y
p_{y}
py,
p
h
p_{h}
ph,
p
w
p_{w}
pw)。参考上图右下侧的公式。
以上是回归器编码和解码的过程。
二、BoxCoder源码
下面的是torhvision版本的faster rcnn关于边框编码和解码的核心代码
class BoxCoder(object):
def __init__(self,weights,bbox_xform_clip=math.log(1000/16)):
self.weights=weights
self.bbox_xform_clip=bbox_xform_clip
def encode_boxes(reference_boxes, proposals, weights):
# type: (torch.Tensor, torch.Tensor, torch.Tensor) -> torch.Tensor
# perform some unpacking to make it JIT-fusion friendly
wx = weights[0]
wy = weights[1]
ww = weights[2]
wh = weights[3]
proposals_x1 = proposals[:, 0].unsqueeze(1)
proposals_y1 = proposals[:, 1].unsqueeze(1)
proposals_x2 = proposals[:, 2].unsqueeze(1)
proposals_y2 = proposals[:, 3].unsqueeze(1)
reference_boxes_x1 = reference_boxes[:, 0].unsqueeze(1)
reference_boxes_y1 = reference_boxes[:, 1].unsqueeze(1)
reference_boxes_x2 = reference_boxes[:, 2].unsqueeze(1)
reference_boxes_y2 = reference_boxes[:, 3].unsqueeze(1)
# implementation starts here
ex_widths = proposals_x2 - proposals_x1
ex_heights = proposals_y2 - proposals_y1
ex_ctr_x = proposals_x1 + 0.5 * ex_widths
ex_ctr_y = proposals_y1 + 0.5 * ex_heights
gt_widths = reference_boxes_x2 - reference_boxes_x1
gt_heights = reference_boxes_y2 - reference_boxes_y1
gt_ctr_x = reference_boxes_x1 + 0.5 * gt_widths
gt_ctr_y = reference_boxes_y1 + 0.5 * gt_heights
targets_dx = wx * (gt_ctr_x - ex_ctr_x) / ex_widths
targets_dy = wy * (gt_ctr_y - ex_ctr_y) / ex_heights
targets_dw = ww * torch.log(gt_widths / ex_widths)
targets_dh = wh * torch.log(gt_heights / ex_heights)
targets = torch.cat((targets_dx, targets_dy, targets_dw, targets_dh), dim=1)
return targets
def decode_single(self, rel_codes, boxes):
boxes = boxes.to(rel_codes.dtype)
widths = boxes[:, 2] - boxes[:, 0]
heights = boxes[:, 3] - boxes[:, 1]
ctr_x = boxes[:, 0] + 0.5 * widths
ctr_y = boxes[:, 1] + 0.5 * heights
wx, wy, ww, wh = self.weights
dx = rel_codes[:, 0::4] / wx
dy = rel_codes[:, 1::4] / wy
dw = rel_codes[:, 2::4] / ww
dh = rel_codes[:, 3::4] / wh
# Prevent sending too large values into torch.exp()
dw = torch.clamp(dw, max=self.bbox_xform_clip)
dh = torch.clamp(dh, max=self.bbox_xform_clip)
pred_ctr_x = dx * widths[:, None] + ctr_x[:, None]
pred_ctr_y = dy * heights[:, None] + ctr_y[:, None]
pred_w = torch.exp(dw) * widths[:, None]
pred_h = torch.exp(dh) * heights[:, None]
pred_boxes1 = pred_ctr_x - torch.tensor(0.5, dtype=pred_ctr_x.dtype, device=pred_w.device) * pred_w
pred_boxes2 = pred_ctr_y - torch.tensor(0.5, dtype=pred_ctr_y.dtype, device=pred_h.device) * pred_h
pred_boxes3 = pred_ctr_x + torch.tensor(0.5, dtype=pred_ctr_x.dtype, device=pred_w.device) * pred_w
pred_boxes4 = pred_ctr_y + torch.tensor(0.5, dtype=pred_ctr_y.dtype, device=pred_h.device) * pred_h
pred_boxes = torch.stack((pred_boxes1, pred_boxes2, pred_boxes3, pred_boxes4), dim=2).flatten(1)
return pred_boxes
我们可以看到在源码中多了一个参数weights。根据源码我们第1小节中的公式变成了下图的形式:

可以看到,在编码后,偏移值分别乘了一个对应的权重,在解码前,偏移值分别除了一个对应的权重。
从第一小节中介绍bounding box回归的原理的时候我们可以看到是没有weights这个权重参数的,faster rcnn原论文中也没有这个参数。那么这个参数到底有啥用呢?
我在下面两处找到的比较合理的解释
2.1、cascade rcnn论文3.1.1小节


作者解释说公式4中的数值(
δ
x
,
δ
y
,
δ
h
,
δ
w
\delta_{x},\delta_{y},\delta_{h},\delta_{w}
δx,δy,δh,δw)会非常小,这样会导致回归损失远远小于分类损失,为了提高多任务学习的有效性,需要用偏移值的均值和标准差(作者原文是
Δ
\Delta
Δis normalized by its mean and variance,这里的variance是方差的意思,但是给出的公式5的分母是
σ
\sigma
σ,是标准差的数学符号)来对偏移值进行标准化。
但是好像还是和我给出的代码中的实现不一样,代码中box编码时直接乘以了权重,我们可以理解为除以了第一节中的weights的倒数,但是还要先减去均值啊?源码实现里没有减去均值啊?是不是有可能是均值为0?下面我们再来看个解释
2.2、Bounding Box Encoding and Decoding in Object Detection



这里也解释了偏移量需要做标准化,同时作者认为一些代码实现中把要除以的这个值当作方差的理解是错误的。这篇博客的作者也认为这个过程是偏移量的标准化,通过标准化把偏移量转换为均值为0,标准差为1的正态分布。博客的作者指出通常边框回归中偏移量的均值 μ x \mu_{x} μx约等于0,而偏移量的标准差 σ x \sigma_{x} σx是可以通过真实边框统计出来的。(这里我个人是有疑问的,源码中的设置应该是个经验值)。这样如果原来的偏移量是遵循正态分布的话,经过标准化后的偏移量分布就是标准正态分布( μ = 0 , σ = 1 \mu=0,\sigma=1 μ=0,σ=1)了,这对于模型的学习预测将会是理想的。
通过以上两处的分析,我们可以知道Faster RCNN中边框编码和解码时的这个weights参数的作用了。其实就是为了提升精度对偏移量进行了标准化。weights是偏移量的标准差的倒数。对 x x x来说, w x = 1 / σ x wx=1/\sigma_{x} wx=1/σx。因此weights=[10,10,5,5,] 对应 σ \sigma σ=[0.1,0.1,0.2,0.2]。
三、RPN和ROI_heads中的weight设置不一样
如果看源码再细一点可以发现RPN网络中使用边框回归的时候的weight设置是和ROI_heads中的weight不一样的。
首先看一下RPN网络初始化的时候BoxCoder的weight参数设置
class RegionProposalNetwork(torch.nn.Module):
__annotations__ = {
'box_coder': det_utils.BoxCoder,
'proposal_matcher': det_utils.Matcher,
'fg_bg_sampler': det_utils.BalancedPositiveNegativeSampler,
'pre_nms_top_n': Dict[str, int],
'post_nms_top_n': Dict[str, int],
}
def __init__(self,
anchor_generator,
head,
#
fg_iou_thresh, bg_iou_thresh,
batch_size_per_image, positive_fraction,
#
pre_nms_top_n, post_nms_top_n, nms_thresh):
super(RegionProposalNetwork, self).__init__()
self.anchor_generator = anchor_generator
self.head = head
self.box_coder = det_utils.BoxCoder(weights=(1.0, 1.0, 1.0, 1.0))
......
......
......
再来看一下ROI_Heads初始化时BoxCoder的weight参数设置。
class RoIHeads(torch.nn.Module):
__annotations__ = {
'box_coder': det_utils.BoxCoder,
'proposal_matcher': det_utils.Matcher,
'fg_bg_sampler': det_utils.BalancedPositiveNegativeSampler,
}
def __init__(self,
box_roi_pool,
box_head,
box_predictor,
# Faster R-CNN training
fg_iou_thresh, bg_iou_thresh,
batch_size_per_image, positive_fraction,
bbox_reg_weights,
# Faster R-CNN inference
score_thresh,
nms_thresh,
detections_per_img,
# Mask
mask_roi_pool=None,
mask_head=None,
mask_predictor=None,
keypoint_roi_pool=None,
keypoint_head=None,
keypoint_predictor=None,
):
super(RoIHeads, self).__init__()
self.box_similarity = box_ops.box_iou
# assign ground-truth boxes for each proposal
self.proposal_matcher = det_utils.Matcher(
fg_iou_thresh,
bg_iou_thresh,
allow_low_quality_matches=False)
self.fg_bg_sampler = det_utils.BalancedPositiveNegativeSampler(
batch_size_per_image,
positive_fraction)
if bbox_reg_weights is None:
bbox_reg_weights = (10., 10., 5., 5.)
self.box_coder = det_utils.BoxCoder(bbox_reg_weights)
从源码中可以看到RPN网络中用到的BoxCoder类的weights参数初始化为[1.0,1.0,1.0,1.0],而ROIHeads网络中的BoxCoder类的weights参数初始化为[10.0,10.0,5.0,5.0],分别换算成标准差
σ
\sigma
σ后,RPN中边框的偏移量
σ
=
[
1.0
,
1.0
,
1.0
,
1.0
]
\sigma=[1.0,1.0,1.0,1.0]
σ=[1.0,1.0,1.0,1.0],ROIHead的偏移量的标准差
σ
=
[
0.1
,
0.1
,
0.2
,
0.2
]
\sigma=[0.1,0.1,0.2,0.2]
σ=[0.1,0.1,0.2,0.2]。
第二节中我们尝试解释了为什么要做标准化,这里的问题是为什么两个stage使用的标准化的参数不一致?
如果都按照偏移量需要做标准化是要将偏移量转换为标准的正态分布的理解来看,那么可以认为RPN部分得到的偏移量本来就近似服从标准正态分布,所以
σ
=
1
\sigma=1
σ=1。到ROIHeads部分是又经过了一次边框回归,获得的偏移量不遵从标准正态分布。是否是这样的呢?,我们再往下看。
四、Cascade RCNN中ROI_Heads的三个stage的weights设置也不同
关于Bounding box中的weights参数问题,我是在做Cascade RCNN时发现的,因为想把Facebook的detectron2项目中的Cascade RCNN网络整合到torchvison版本的RCNN网络中,我需要一步一步的调试detectron2的源码,尤其是每个网络中的参数初始化。调试到Cascade ROIHeads的bounding box 回归这一步的时候发现三个stage边框回归的权重分别为[10,10,5,5],[20,20,10,10],[30,30,15,15](这部分参数来自detectron2源码)。
第3小节中我们尝试着解释了为什么Faster RCNN中RPN和ROIHeads阶段weights参数不一致的问题,那么这里的问题就是为啥Cascade RCNN网络中RoiHeads部分三个stage的偏移量的权重设置不一样呢?首先我们把3个stage中的权重换算成标准差
σ
\sigma
σ,即[0.1,0.1,0.2,0.2],[0.05,0.05,0.1,0.1],[0.033,0.033,0.066,0.066]。现在我来尝试解释一下为啥3个stage中的weights设置不一样。
我们以偏移量中的
d
x
d_{x}
dx为例,将
d
x
d_{x}
dx满足均值为0,标准差分别为1,0.1,0.05,0.033的正态分布曲线图画出来。
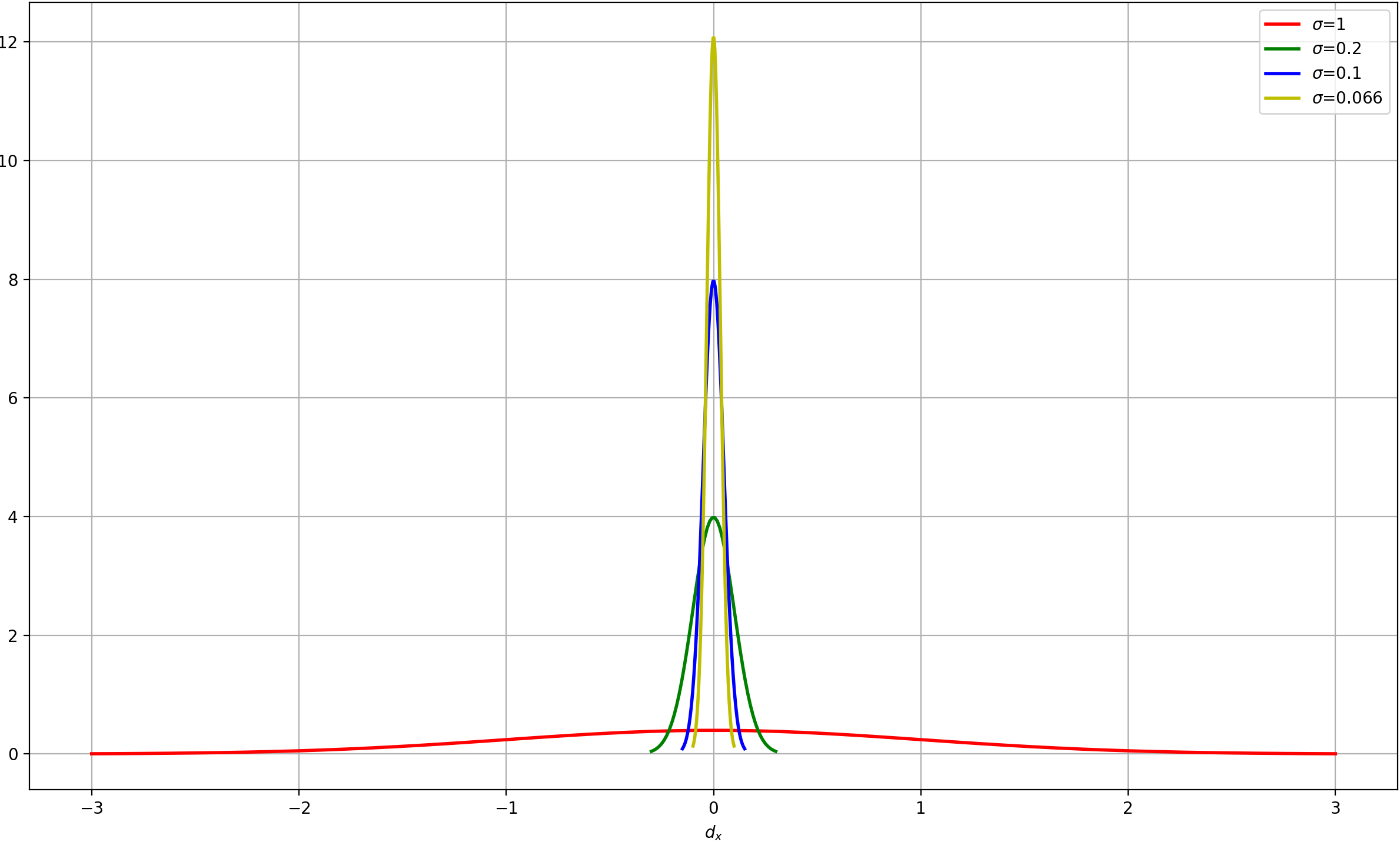
从上图可以看到标准差越小,分布曲线越向均值集中,cascade rcnn中的4个stage(RPN+ROIHeads中的3个stage)中,RPN网络是以anchor作为基础来进行偏移的,在ROIHeads的3个stage中,第一个stage是以RPN选出来的预选框作(anchor解码后的结果)为基础进行回归偏移的,后面的stage都是在前一个stage的回归基础上进一步做边框回归的,从Cascade RCNN论文中可以知道,越靠后的stage(IOU阈值越大),边框的精度越高,那么与真实边框的偏差就越小,所以边框偏移值的标准差就应该设置的越小。
综上所述,由于边框回归的偏移值特别小,所以获得的回归损失会远小于分类损失,因此需要对偏移值做标准化,标准化时需要用到偏移量的均值和标准差,一般认为边框回归中均值约等于0,不同阶段边框偏移量的标准差设置不同,偏移量越小,标准差越小。
总结
1.目标检测中边框回归时用到的weights参数其实是用来对边框回归得到的偏移值做标准化的,以提高模型精度。
2.标准化使用的公式为
d
t
′
=
(
d
t
−
μ
t
)
/
σ
t
,
t
∈
{
x
,
y
,
h
,
t
}
d_{t}^{'}=(d_{t}-\mu_t)/\sigma_{t},t\in\left\{x,y,h,t\right\}
dt′=(dt−μt)/σt,t∈{x,y,h,t},一般认为边框回归的偏移量均值为0,标准差需要设置,也就是1中的weights。
3.Faster RCNN中RPN边框回归对应的weights为[1,1,1,1],ROIHeads对应的weighs设置为[10,10,5,5]。
4.Cascade RCNN的ROIHeads的3个stage中weights设置为[10,10,5,5]、[20,20,10,10]、[30,30,15,15]。
5、参考
Bounding Box Encoding and Decoding in Object Detection
Cascade RCNN: High Quality Object Detection and Instance Segmentation


















 1316
1316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











