







线性分类器基于特征的线性组合的值进行分类决策。 想象一下,线性分类器将把定义特定类的所有特征合并到其权重中。当问题是线性可分离的时,这种类型的分类器效果更好。

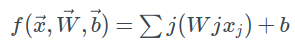
X: 输入向量 W:权重矩阵 B:偏差矢量

权重矩阵对于每个需要分类的类都有一行,对于x的元素(特征)有一列。在上面的图片中,每行将由权重矩阵中的一行表示。改变权重的效果将改变线条角度,同时改变偏压,将使线条左右移动。
参数化方法这个想法是假设/模型具有参数,这将有助于输入向量到特定类别评分之间的映射。 参数模型具有两个重要组成部分:
得分函数:是函数f(x,w,b)它将原始输入向量映射到得分向量
损失函数:量化我们当前的权重集将输入x映射到预期输出y的程度,在训练期间使用损失函数。
在这种方法上,训练阶段将为我们找到一组参数,这些参数将更改假设/模型以将某些输入映射到某些输出类别。在训练阶段(这是一个优化问题),权重(W)和偏差(b)是我们唯一可以更改的事情。

现在,上图中的一些重要主题:
- 输入图像x被拉伸为一个单维矢量,此宽松的空间信息
- 权重矩阵对于输入中的每个元素都有一列
- 权重矩阵对于输出的每个元素都有一行(在这种情况下为3个标签)
- 偏差将针对输出的每个元素排成一行(在这种情况下为3个标签)
- 亏损将收到当前得分和当前输入X的预期输出
将W的每一行考虑为指定类的一种模式匹配。 每个类别的分数是通过在输入向量X与该类别的特定行之间进行内积计算得出的。 例如:
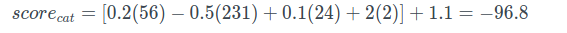
Matlab范例:

下面的图像将权重重塑为图像,我们可以通过该图像看到训练尝试将W的每一行压缩为同一类的所有变体。 (检查两头马)

偏见技巧
一些学习库的实现方式,将技巧作为权重矩阵的一部分考虑在内,是一种技巧,这种方法的优势在于我们可以使用单矩阵乘法来求解线性分类:f(x,w) = w.x
基本上,您在输入向量的末尾添加了额外的一行,并在W矩阵上串联了一列。
输入和功能
输入向量有时也称为特征向量,是您发送到分类器的输入数据。 由于线性分类器无法处理非线性问题,因此工程师必须负责处理,处理此数据并以可与分类器分离的形式呈现。最好的情况是您具有大量功能,并且每个功能与所需的输出具有较高的相关性,而它们之间的相关性较低。














 1422
1422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









