







大体介绍
当训练deep Convolutional Neural Networks时往往需要大量的手动标记的数据。因此,这篇论文提出了一种非监督的框架来学习DCNN从而进行单视图的深度预测,这个框架的学习不需要预训练阶段和annotated ground-truth depths。我们使用真实的无注释图像,朝着能够进行in-situ甚至lifelong learning的系统迈进。我们使用类似于自动编码器的方式训练这个神经网络,并利用视觉几何中理解良好的想法。其结果是一个用于单视图深度估计的卷积神经网络,这是第一个可以从头开始端到端进行训练的卷积神经网络,在完全无监督的情况下,只需使用一个stereo rig捕获的数据。我们的目标是学习一个非线性预测函数,它将图像映射到深度图。
在训练时,我们考虑一对图像,源(source)和目标(target),在这两个图像之间有一个小的,已知的摄像机运动,例如一个立体对。我们训练卷积编码器来预测源图像的深度图。为此,我们显式地使用预测的深度和已知的视点间位移生成目标图像的逆扭曲(inverse warp),以重建源图像。重建中的光度误差(photometric error)是编码器的重建损失。
这种训练数据的获取比同等系统要简单得多,不需要手动注释,也不需要将深度传感器校准到摄像机上。我们的网络在不到一半的KITTI数据集上训练,其性能与目前最先进的单视深度估计监督方法相当。
1.Approach
为了训练网络,我们使用立体对(stereo pairs)。我们学习CNN来模拟复杂的非线性变换,将图像转换为深度图。我们用来学习这个CNN的损失是输入或源图像与反向扭曲目标图像(立体对中的另一个图像)之间的光度差。这种损失是可微的(为了便于反向传播),并且与预测误差高度相关。即,可以在不使用地面真值标签的情况下用于精确排列两个不同深度的地图。
这种方法可以在卷积自动编码器的上下文中解释。标准自动编码器的任务是用一系列非线性操作将输入编码为一个压缩代码,该压缩代码捕获足够的核心信息,以便解码器能够以最小的重建误差重建输入。在我们的例子中,我们根据预测的深度图和摄像机的相对位置,用标准的几何图像扭曲替换解码器。这有两个优点:第一,在我们的情况下,解码器不需要学习,因为它已经是一个很好理解的几何操作;第二,我们的重建损失自然鼓励代码成为正确的深度图像。

1.1Autoencoder loss
训练中的输入图像对是提前得到的,并且两者之间的水平间隔B并且焦距都是f 。
在处理光圈问题之前,我们对视差不连续性使用非常简单的L2正则化进行优化:

这种优化器会使得估计中的运动过度平滑,但是这个有利于计算梯度,获得更清晰的深度图。因此损失函数为:
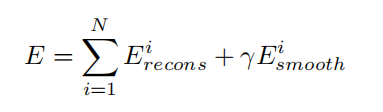
其中,γ是强制估计深度平滑的正则化强度。
注意,我们的视差图Di被参数化为输入图像和CNN未知权重的非线性函数,用于估计每个立体对之间的运动。
2.Coarse-to-fine training with skip architecture
为了计算标准反向传播的梯度,使用泰勒展开当前估计的线性化扭曲图像:
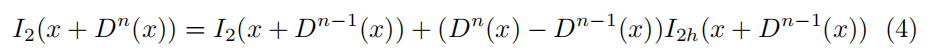
其中,I_2h表示第n次迭代时在当前视差D_n-1处计算的warp image的水平梯度。这种线性化仅仅对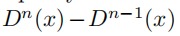 有效,其限制了图像估计差异的大小。
有效,其限制了图像估计差异的大小。
为了准确地估计较大的运动(较小的深度),在立体和光流文献中建立了具有迭代the warps的粗到细策略,这有助于基于梯度下降的连续优化。
Fortunately, the recent fully-convolutional architecture with upsampling, is a suitable choice to enable coarse-to-fine warping for our system.As depicted in Figure 2, given a network which predicts an M × N disparities, we can use a simple bilinear upsampling filter to initialize upscaled disparities (to get 2M × 2N depthmaps) keeping the other network parameters fixed. It has been shown that the finer details of the images are captured in the previous layers of CNN, and fusing back such information is helpful for refining a coarse CNN prediction. We use 1 × 1 convolution with the filter and bias both initialized to zero and the convolved output is then fused with the upscaled depths with an element-wise sum layer for refinement.

由粗到细的训练还有一步如上图,M*N的图像,经过双线形采样放大,再结合池化后的图层,叠加在一起,进行优化
3.Network Architecture
深度卷积编码的神经网络结构为:

C5层之前的结构与Alexnet相似,我们将Alexnet的全连接层替换为全卷积层,每个卷积层有2048个5×5大小的卷积滤波器。在深度卷积网络的最后几层中,图像中更精细的细节丢失了,我们采用了“skip architecture”,将更粗糙的深度预测与局部图像信息结合起来,以获得更精细的预测。在我们的网络中,L9输出(22×76 depth map)之后的层是简单的4×4卷积,每个卷积将较粗的低分辨率深度映射转换为较高分辨率的输出。















 337
337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









