







简 介
随着新一代测序技术的进步,在大量生物体中发现了许多新的转录本。为了快速、准确地评估RNA转录物的编码能力,将编码势计算器CPC1升级为CPC2。CPC2的运行速度比CPC1快 ~ 1000倍,与CPC1相比具有更高的准确性,特别是对于长的非编码转录本。此外,CPC2的模型是种中性的,这使得它可以用于不断生长的非模式生物转录组。可以在线分析,也可以下载独立包进行本地安装分析。

CPC2 在线分析工作流程:
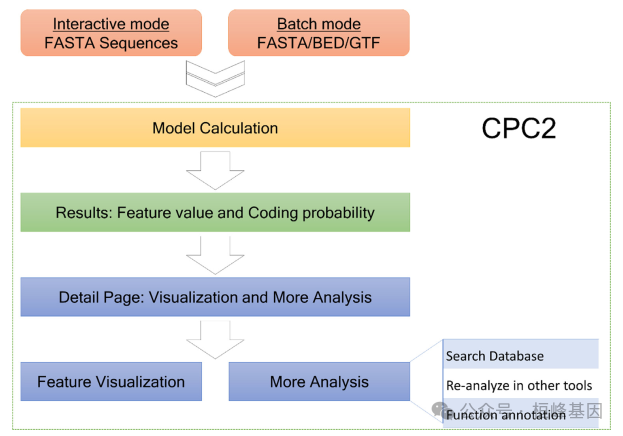
在人类、小鼠、斑马鱼、苍蝇、蠕虫和模式植物拟南芥中进行独立测试。

文件准备
这个输入文件只有一个文件可以是核酸序列文件,例如:
>HOTAIR
AGGCGAGAGCCGCGGCTGACAGGGTCTGGGACAGAAGGAAAGCCCTCCAGCCTCCAGGCCCTGCCTTCTGCCTGCACATTCTGCCCTGATTTCCGGAACCTGGAAGCCTAGGCAGGCAGTGGGGAACTCTGACTCGCCTGTGCTCTGGAGCTTGATCCGAAAGCTTCCACAGTGAGGACTGCTCCGTGGGGGTAAGAGAGCACCAGGCACTGAGGCCTGGGAGTTCCACAGACCAACACCCCTGCTCCTGGCGGCTCCCACCCGGGACTTAGACCCTCAGGTCCCTAATATCCCGGAGGTGCTCTCAATCAGAAAGGTCCTGCTCCGCTTCGCAGTGGAATGGAACGGATTTAGAAGCCTGCAGTAGGGGAGTGGGGAGTGGAGAGAGGGAGCCCAGAGTTACAGACGGCGGCGAGAGGAAGGAGGGGCGTCTTTATTTTTTTAAGGCCCCAAAGAGTCTGATGTTTACAAGACCAGAAATGCCACGGCCGCGTCCTGGCAGAGAAAAGGCTGAAATGGAGGACCGGCGCCTTCCTTATAAGCTCGTTGGGGCCTAAGCCAGTACCGACCTGGTAGAAAAAGCAACCACGAAGCTAGAGAGAGAGCCAGAGGAGGGAAGAGAGCGCCAGACGAAGGTGAAAGCGAACCACGCAGAGAAATGCAGGCAAGGGAGCAAGGCGGCAGTTCCCGGAACAAACGTGGCAGAGGGCAAGACGGGCACTCACAGACAGAGGTTTATGTATTTTTATTTTTTAAAATCTGATTTGGTGTTCCATGAGGAAAAGGGAAAATCTAGGGAACGGGAGTACAGAGAGAATAATCCGGGTCCTAGCTCGCCACATGAACGCCCAGAGAACGCTGGAAAAACCTGAGCGGGTGCCGGGGCAGCACCCGGCTCGGGTCAGCCACTGCCCCACA在线分析
在线网址CPC2,在线使用还是非常简单,序列少可以优先选择在线操作。
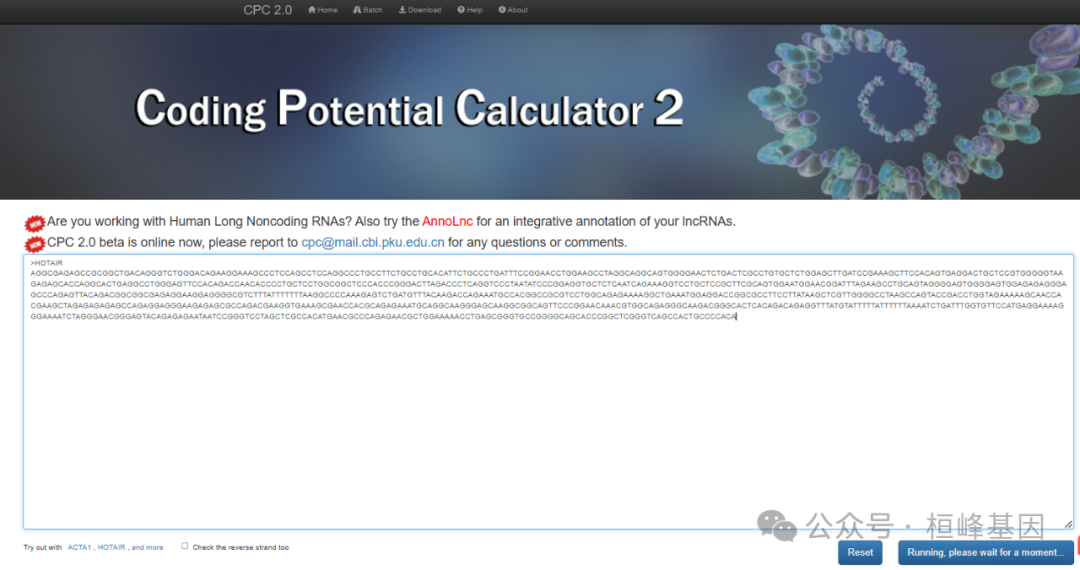
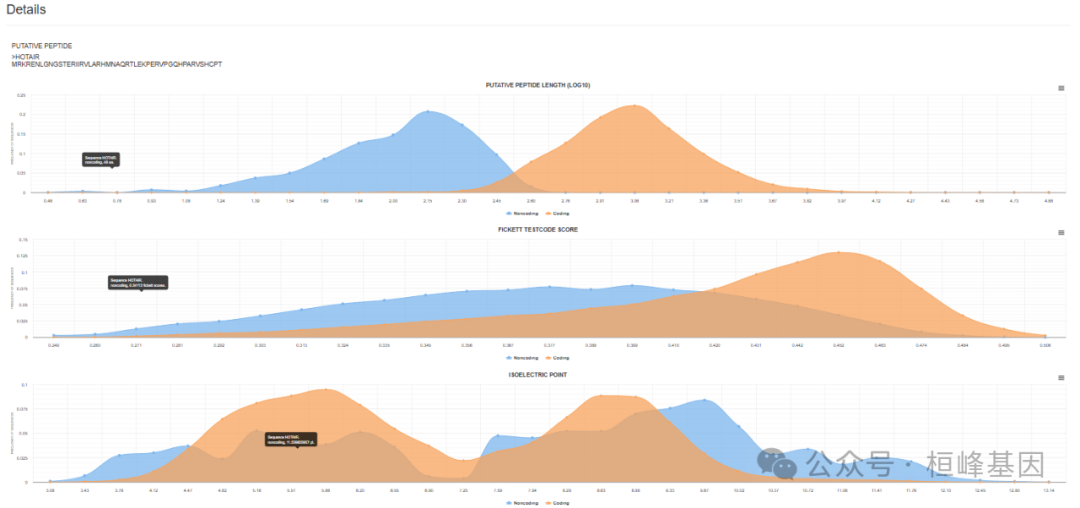
HOTAIR测试结果:
1. 带有编码概率的汇总表输出:

2. 功能分布的图形:
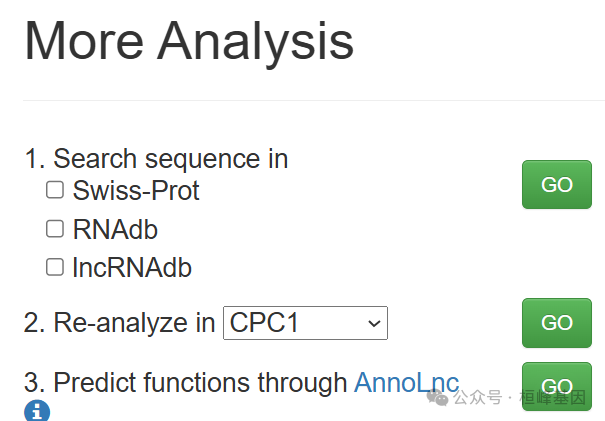
3. 更多针对已知数据库查询的分析,在替代方法中重新分析和注释函数:
本地分析
软件包安装
首先下载软件包,这个CPC2软件包基于python的2和3两个版本,建议大家下载3版本的,毕竟2版本的慢慢退出舞台了,如果出来bug,也没人维护了,接下来就是解压后,可以看到里面的READ.md,安装说明几条命令安装即可。
gzip -dc CPC2-beta.tar.gz | tar xf -
cd CPC2-beta
export CPC_HOME="$PWD"
cd libs/libsvm
gzip -dc libsvm-3.18.tar.gz | tar xf -
cd libsvm-3.18
make clean && make实际操作
1. 参数说明
参数仅有四个很简单,输入文件输出文件以及两个可调参数 -r 反义链,--ORF 是否输出最长ORF的起始位置,根据实际情况自己决定,一般默认参数即可。
Usage: CPC2.py [options] -i input.fasta -o output_file
Contact: Kang Yujian <kangyj@mail.cbi.pku.edu.cn>
Options:
--version show program's version number and exit
-h, --help show this help message and exit
Common Options:
-i FILE input sequence in fasta format [Required]
-o FILE output file [Default: cpc2output.txt]
-r also check the reverse strand [Default: FALSE]
--ORF output the start position of longest ORF [Default: FALSE]2. 实际操作命令如下:
python3 ./bin/CPC2.py -i ./data/example.fa -o ./data/example_output.txt
python3 ./bin/CPC2.py -i ./data/example.fa -o ./data/example_output_str.txt --ORF结果解读
不设置 --ORF 的结果:
1 #ID transcript_length peptide_length Fickett_score pI ORF_integrity coding_probability label
2 AF282387 528 176 0.47841 4.671051216125488 1 0.997542 coding
3 Tsix_mus 4300 70 0.28464 11.051186561584473 1 0.0447345 noncoding设置 --ORF 的结果多了一列 ORF_Start :
1 #ID transcript_length peptide_length Fickett_score pI ORF_integrity ORF_Start coding_probability label
2 AF282387 528 176 0.47841 4.671051216125488 1 1 0.997542 coding
3 Tsix_mus 4300 70 0.28464 11.051186561584473 1 105 0.0447345 noncodingReference
Kang Y. J., Yang D. C., Kong L., Hou M., Meng Y. Q., Wei L., Gao G. 2017. CPC2: a fast and accurate coding potential calculator based on sequence intrinsic features. Nucleic Acids Research 45(Web Server issue): W12–W16.
Kong L., Zhang Y., Ye Z. Q., Liu X. Q., Zhao S. Q., Wei L., Gao G. 2007. CPC: assess the protein-coding potential of transcripts using sequence features and support vector machine. Nucleic Acids Research 35(Web Server issue): W345-349.
桓峰基因,铸造成功的您!
未来桓峰基因公众号将不间断的推出单细胞系列生信分析教程,
敬请期待!!
桓峰基因官网正式上线,请大家多多关注,还有很多不足之处,大家多多指正!http://www.kyohogene.com/
桓峰基因和投必得合作,文章润色优惠85折,需要文章润色的老师可以直接到网站输入领取桓峰基因专属优惠券码:KYOHOGENE,然后上传,付款时选择桓峰基因优惠券即可享受85折优惠哦!https://www.topeditsci.com/


















 1573
1573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









