







 本文介绍了BEV感知中的LSS方法,重点阐述了Lift层和Splat层的工作原理,涉及深度特征提取、相机坐标系转换、特征融合和BEV空间表示。同时,作者分享了LSS源码中的关键部分,如数据预处理、模型构建和训练流程,以及使用的深度学习技术和优化策略。
本文介绍了BEV感知中的LSS方法,重点阐述了Lift层和Splat层的工作原理,涉及深度特征提取、相机坐标系转换、特征融合和BEV空间表示。同时,作者分享了LSS源码中的关键部分,如数据预处理、模型构建和训练流程,以及使用的深度学习技术和优化策略。
文章目录
一、prologue
最近在学习BEV感知的内容,为了强化自己的学习效果,我会将自己的习得总结于此。(包含大量自己总结的内容,可能有误,阅读需时刻保持专注,遇到的问题请大家指出。)
BEV感知主要有两大类方法,第一类是以BEVDet为代表的基于LSS的方法;另一种是以BEVFormer为代表的基于Transformer的方法。BEVDet好像是目前上车率比较高的一种感知算法,因此学习BEVDet非常有价值,那我们先来看看他的基础——LSS。
LSS分别是Lift、Splat、Shoot的首字母,一般BEV感知系统处理的输入是六路相机图像,Lift环节要做的事情就是将图像中的2D特征提升到3D空间中;然后Splat环节是将3D中的特征投射到BEV空间中;Shoot环节与感知无关,我们不做介绍。
LSS的核心贡献在于提供了一个将特征从2D图像空间转换到BEV空间下的View Transformer——Lift-Splat层。这个层连接了两个backbone,第一个是用来从图像中获得特征,另一个是对BEV空间中特征做进一步学习(也就是BEVDet中的BEV Encoder)
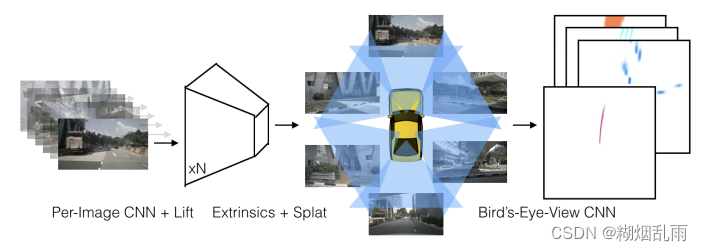
OK,那明确我们的重点——Lift-Splat层是如何实现的,在后面的学习也要时刻记住我们的目标,否则很容易钻到一些细节中出不来。
二、Lift-Splat层原理
输入是n张图像 { X k ∈ R 3 × H × W } n \{X_k\in\mathbb{R}^{3\times H\times W} \}_n {Xk∈R3×H×W}n,以及获取每张图像相机的外参矩阵 E k ∈ R 3 × 4 E_k\in \mathbb{R}^{3\times 4} Ek∈R3×4和内参矩阵 I k ∈ R 3 × 3 I_k\in \mathbb{R}^{3\times 3} Ik∈R3×3,输出是场景在BEV空间下的表征 y ∈ R C × X × Y y\in \mathbb{R}^{C\times X\times Y} y∈RC×X×Y。
2.1 Lift层
经过backbone之后,我们获得了一系列特征图。通过Lift层,可以将这些2D特征拉升到相机坐标系下(3D的),再利用内参和外参,将相机坐标系下的特征转换到自车坐标系下。
问题来了,如何拉升? LSS的方法是这样的,图像backbone不只学习图像特征,还学习像素的深度特征。深度学习的结果是可以获得相机光心与像素连线形成的射线上不同离散深度的概率分布,接着用这个概率去乘图像特征,作为该3D位置的特征。每个像素都这样处理,就可以获得自车坐标系下的特征。
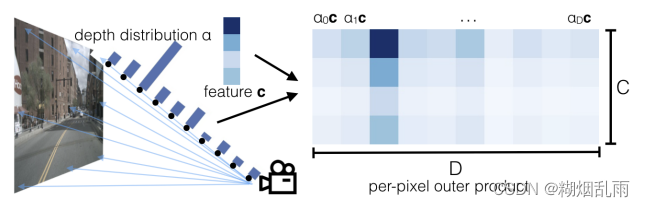
2.2 Splat层
Splat层做的更是简单粗暴,对位于同一个pillar中的所有特征做sum pooling即可。但直接这样做显然效率过低,因此LSS中进行了工程优化,使用了名为Cumulative Sum的trick。
这个方法的提出参照了OFT中使用的积分图(Integral images)的概念,积分图讲解,这篇博客写的嘎嘎明白。
积分图是在数字图像处理中经常运用到的一种手段,其目的是为了快速计算图像中任一矩形区域属性之和。如果我们已经获得了积分图像
I
(
x
,
y
)
I(x,y)
I(x,y),那么对于任何一个矩形区域都可以通过4次查表获得该区域的特征之和。
S
=
I
(
x
1
,
y
1
)
+
I
(
x
0
,
y
0
)
−
I
(
x
1
,
y
0
)
−
I
(
x
0
,
y
1
)
S=I(x_1,y_1)+I(x_0,y_0)-I(x_1,y_0)-I(x_0,y_1)
S=I(x1,y1)+I(x0,y0)−I(x1,y0)−I(x0,y1)

三、LSS源码阅读
3.1 准备工作
-
NuScenes数据集准备,下载链接,我下载的是mini版
重新组织文件结构如下:

下载最新的map,并解压到maps文件夹下
-
LSS环境配置
git clone git@github.com:nv-tlabs/lift-splat-shoot.git
conda create -n lss_env python=3.11
conda activate lss_env
pip3 install torch torchvision
pip install nuscenes-devkit tensorboardX efficientnet_pytorch==0.7.0
- 测试一下
- 下载LSS提供的预训练模型
python main.py viz_model_preds mini --modelf=model525000.pt --dataroot=data/nuscenes/ --map_folder=data/nuscenes/mini --gpuid=0- 查看运行结果:
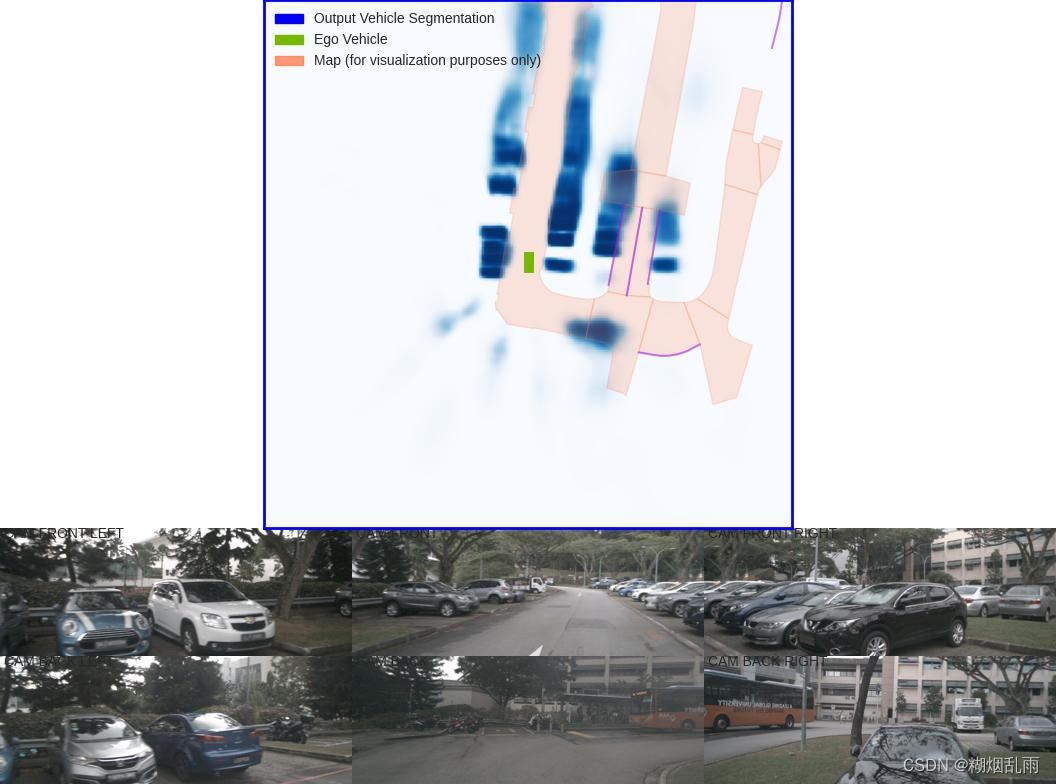
如果成功运行起来了,那接下来我们就边调试,边看看代码是如何实现的。
3.2 推理部分
主要从src/explore.py中的viz_model_preds()入手,来走一下LSS的推理过程,我们主要关注三点:1、配置了哪些参数;2、数据集如何构建;3、模型如何构建。
3.1.1 参数配置
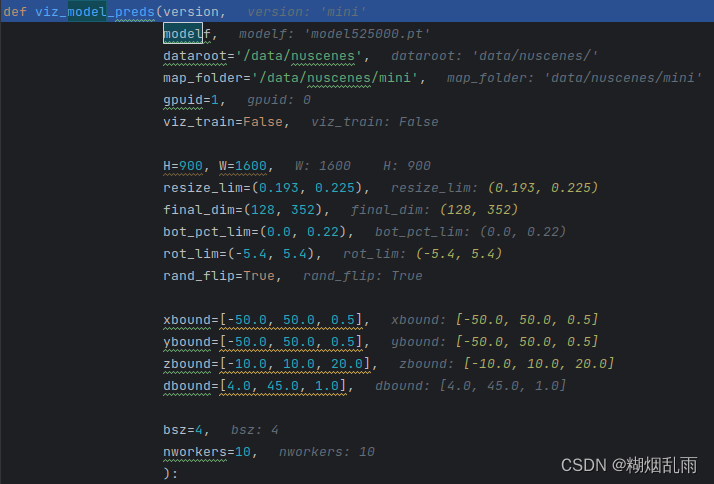
第一部分参数是一些系统参数,指定了数据集版本,模型路径、数据集路径等基本信息;第二部分是指定了图像的分辨率以及数据增强的参数范围;第三部分是指明体素分辨率的以及深度的离散化程度;最后是对数据读取的基本设置。
然后对输入数据进行重组
grid_conf = {
'xbound': xbound,
'ybound': ybound,
'zbound': zbound,
'dbound': dbound,
}
cams = ['CAM_FRONT_LEFT', 'CAM_FRONT', 'CAM_FRONT_RIGHT',
'CAM_BACK_LEFT', 'CAM_BACK', 'CAM_BACK_RIGHT']
data_aug_conf = {
'resize_lim': resize_lim,
'final_dim': final_dim,
'rot_lim': rot_lim,
'H': H, 'W': W,
'rand_flip': rand_flip,
'bot_pct_lim': bot_pct_lim,
'cams': cams,
'Ncams': 5,
}
3.1.2 compile_data()
数据集的构建也是常规的操作,核心就是获得dataset和dataloader
- nuscene数据集读入
- 模式选择(字典访问和条件选择的组合,省去了写if-else的麻烦)
parser = {
'vizdata': VizData,
'segmentationdata': SegmentationData,
}[parser_name]
- 构建训练数据集和测试数据集traindata,valdata
- 构建dataloader
trainloader = torch.utils.data.DataLoader(traindata, batch_size=bsz,
shuffle=True, num_workers=nworkers, drop_last=True, worker_init_fn=worker_rnd_init)
valloader = torch.utils.data.DataLoader(valdata, batch_size=bsz, shuffle=False, num_workers=nworkers)
接下来详细看一下数据集traindata是如何构建的,重点就是看下__len__和__getitem__方法。
def __len__(self):
return len(self.ixes)
self.ixes = self.prepro()
def prepro(self):
samples = [samp for samp in self.nusc.sample]
# remove samples that aren't in this split
samples = [samp for samp in samples if
self.nusc.get('scene', samp['scene_token'])['name'] in self.scenes]
# sort by scene, timestamp (only to make chronological viz easier)
samples.sort(key=lambda x: (x['scene_token'], x['timestamp']))
return samples
prepro()去除了不属于当前数据集场景的数据,然后根据场景序号和时间戳对数据进行了排序,使用debug console输出samples可以获得包含下面类似元素的列表,我们从中也可以大概看出nuscene数据集的结构。nuscene通过数据库形式来组织数据,不同数据有不同的token,包含上下帧数据id,提供了做时序融合的可能。anns指的是是标注信息。
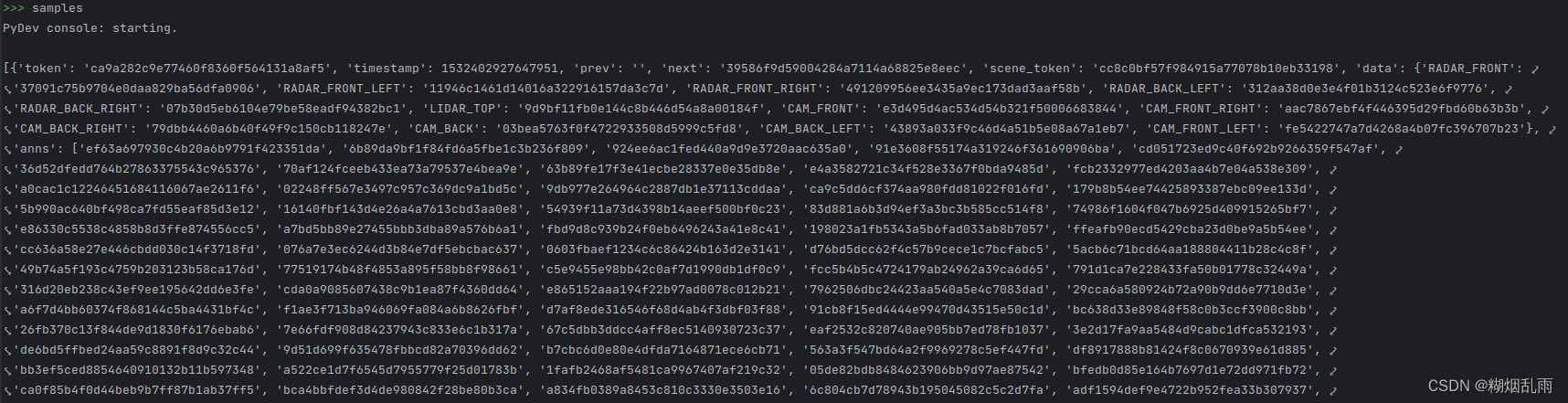
def __getitem__(self, index):
#根据索引获得某一个数据
rec = self.ixes[index]
#Nuscenes包含六路相机,但有些可能没有六个,因此需要做剔除
cams = self.choose_cams()
imgs, rots, trans, intrins, post_rots, post_trans = self.get_image_data(rec, cams)
binimg = self.get_binimg(rec)
return imgs, rots, trans, intrins, post_rots, post_trans, binimg
imgs:数据增强后的图像[6,3,128,352],rots/trans:相机外参[6,3,3] [6,3],intrins:相机内参[6,3,3],post_rots/post_trans:数据增强时候对图像做的变换[6,3,3]6,3,binimg是一个黑白图(1200200),好像是在bev空间标记了哪里有障碍物。

最终输入进模型的图片还需要做归一化,对输入图像做归一化,一方面保证了学习率的设置与输入无关;另一方面去除了图像中的共有部分,突出个体差异。下面的mean、std数值好像是通过imagenet里的图像统计出来的。
normalize_img = torchvision.transforms.Compose(( torchvision.transforms.ToTensor(), torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ))

3.1.3 compile_model()
终于到了关键部分,对于一个自定义模型,需要继承自torch.nn.Module类,这个基类为构建神经网络提供了必要的基础设施和一系列有用的方法和属性。一般查看一个模型需要关注__init__()中对模型结构的定义,以及在forward方法中实现的前向传播逻辑。
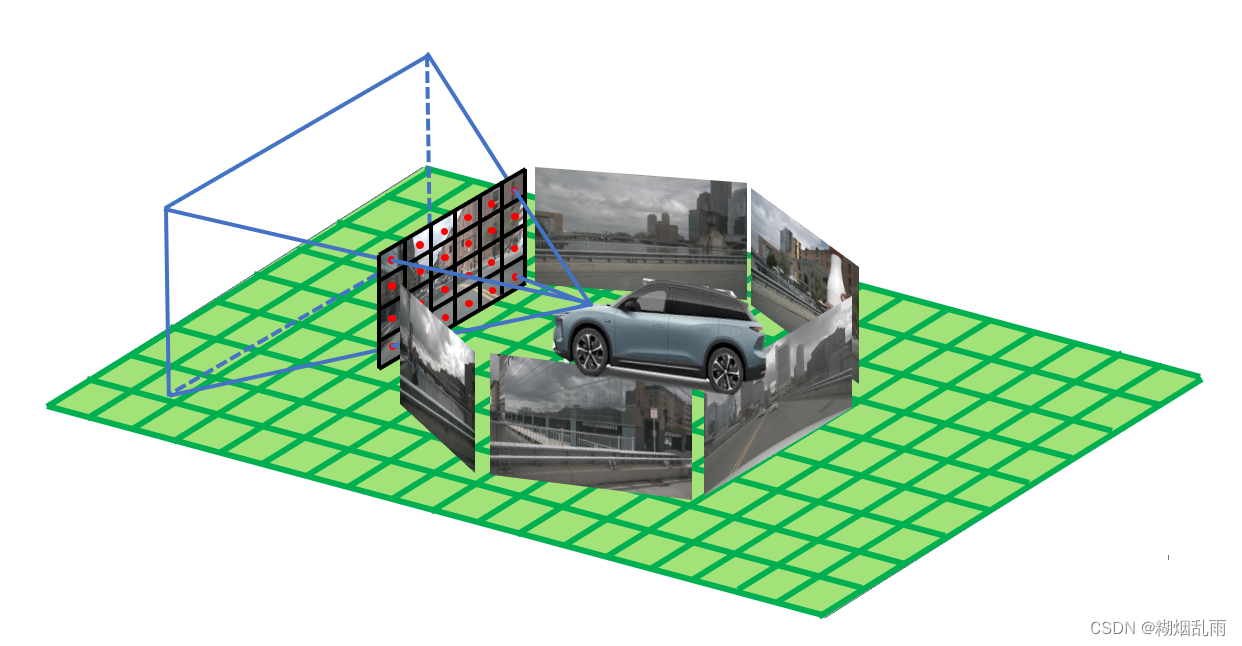
输入图像数据x[4,6,3,128,352],以及相机内参外参,数据增强矩阵,LSS模型的前向过程做了以下几步:
- 获得自车坐标系下点云geom[4,6,41,8,22,3],对应方法get_geometry()
- 利用backbone提取每个像素的特征,以及像素在空间中的深度分布,做外积获得空间特征x[4,6,41,8,22,64],对应方法get_cam_feats()
- 对空间做栅格化,将同一栅格中的点云特征做sum pooling,再将同一个pillar中的栅格投射到bev空间中,对应voxel_pooling()
- bevencoder来对bev空间的特征做深度融合
3.1.3.1 get_geometry()
def get_geometry(self, rots, trans, intrins, post_rots, post_trans):
"""Determine the (x,y,z) locations (in the ego frame)
of the points in the point cloud.
Returns B x N x D x H/downsample x W/downsample x 3
"""
B, N, _ = trans.shape
# 恢复原始图像
points = self.frustum - post_trans.view(B, N, 1, 1, 1, 3)
points = torch.inverse(post_rots).view(B, N, 1, 1, 1, 3, 3).matmul(points.unsqueeze(-1))
# 获得自车坐标系下点云
points = torch.cat((points[:, :, :, :, :, :2] * points[:, :, :, :, :, 2:3],
points[:, :, :, :, :, 2:3]
), 5)
combine = rots.matmul(torch.inverse(intrins))
points = combine.view(B, N, 1, 1, 1, 3, 3).matmul(points).squeeze(-1)
points += trans.view(B, N, 1, 1, 1, 3)
return points
自车坐标系点云的获得用了下面这个公式,如果有不懂可以看我之前的一篇相机内外参介绍
R
K
−
1
s
(
u
v
)
+
t
RK^{-1}s\begin{pmatrix} u\\v \end{pmatrix}+t
RK−1s(uv)+t
3.1.3.2 get_cam_feats()
这里用了efficientnet做backbone,我想记录一下做外积的部分
def get_depth_feat(self, x):
#x[24,3,128,352]
x = self.get_eff_depth(x)#x[24,512,8,22]
# Depth
x = self.depthnet(x)#x[24,105,8,22],前41维是深度特征,后64维是图像特征
depth = self.get_depth_dist(x[:, :self.D])#depth[24,41,8,22],对前41维做了softmax获得深度分布
new_x = depth.unsqueeze(1) * x[:, self.D:(self.D + self.C)].unsqueeze(2)#[24,1,41,8,22]和[24,64,1,8,22]做外积,new_x[24,64,41,8,22],一直搞不清这些张量运算,每次要想好久。。。。
return depth, new_x
3.1.3.3 voxel_pooling()
这部分首先将自车坐标系点云转为栅格坐标,然后为每个栅格分配一个ID,接下来是对一个栅格中的全部点云做特征求和,本文的trick如下
#为栅格(x,y,z,b)分配一个ID,其实相当于对这个四维结构做了扁平化,因此x可以看做一个一维向量
#先获得x的积分图
x = x.cumsum(0)
#rank每一次变化说明,数据跳到另一个栅格中了,需要记录下来这个位置
kept = torch.ones(x.shape[0], device=x.device, dtype=torch.bool)
kept[:-1] = (ranks[1:] != ranks[:-1])
#用记录下来的位置与前项做差,可以获得栅格中的特征和
x, geom_feats = x[kept], geom_feats[kept]
x = torch.cat((x[:1], x[1:] - x[:-1]))
使用一份示例代码可以清楚地展示上面计算的流程
import torch
# 原始数据
x = torch.tensor([1, 2, 3, 4, 5, 6, 7, 8, 9])
print(x)
# 分组标识
ranks = torch.tensor([1, 1, 1, 2, 2, 2, 3, 3, 3])
print(ranks)
x = x.cumsum(0)
print(x)
kept = torch.ones(x.shape[0], dtype=torch.bool)
kept[:-1] = (ranks[1:] != ranks[:-1])
print(kept)
x = x[kept]
print(x)
x = torch.cat((x[:1], x[1:] - x[:-1]))
print(x)
tensor([1, 2, 3, 4, 5, 6, 7, 8, 9])
tensor([1, 1, 1, 2, 2, 2, 3, 3, 3])
tensor([ 1, 3, 6, 10, 15, 21, 28, 36, 45])
tensor([False, False, True, False, False, True, False, False, True])
tensor([ 6, 21, 45])
tensor([6, 15, 24])
最后将不同高度栅格的特征维拼接在一起,实现3D空间到BEV空间的特征转换
final = torch.zeros((B, C, self.nx[2], self.nx[0], self.nx[1]), device=x.device)
final[geom_feats[:, 3], :, geom_feats[:, 2], geom_feats[:, 0], geom_feats[:, 1]] = x
final = torch.cat(final.unbind(dim=2), 1)
模型输出的结果是一个概率图,通过sigmoid用来表示每一个bev栅格中存在障碍物的概率
3.3 训练部分
有了前面的铺垫,看训练部分的代码就轻松了不少,学习的时候尽量总结出框架,这样可以方便自己记忆。训练部分一般的框架如下:
构建部分:
- 模型初始化:创建或加载一个模型,并将其初始化到计算设备上
- torch.nn.Module:自定义模型需要继承此类,是所有神经网络模块的积累,包含一些功能块
- torchvision.models:包含预训练模型,如ResNet,VGG等,可以用于迁移学习
- 数据加载和预处理:配置数据加载器,包括训练集和验证集
- torch.utils.data.Dataset:用于自定义数据加载和预处理
- torch.utils.data.DataLoader:封装了Dataset,提供加载相关功能
- 设置优化器和相关参数:Adam,学习率和权重衰减
- torch.optim:包含多种优化算法的模块,如SGD,Adam,AdamW等
- 定义损失函数:知道模型学习的方向
- torch.nn中包含了许多构建块来构建损失函数
运行部分:
- 训练循环:
- 确定模型是训练模式:`model.train()``
- 梯度清零:
optimizer.zero_grad() - 前向传播:通过模型计算预测输出
model(x) - 损失计算:计算预测输出与真实标签之间的损失
- 反向传播:根据损失计算梯度
loss.backward() - 梯度裁剪(lss中第一次见到):作用是防止梯度爆炸
torch.nn.utils.clip_grad_norm() - 参数更新:更新模型权重
optimizer.step()
- 性能评估:定期在验证集上评估模型,以监控泛化能力
- 日志记录:TensorBoard就是日志记录工具
- tensorboardX.SummaryWriter
- torch.utils.tensorboard.SummaryWriter
用于记录训练过程中的指标,如损失和准确率,以便在TensorBoard中进行可视化。
- 模型保存:定期保存模型的权重,以便于后续的恢复和继续训练或进行推理
- torch.save():用于保存模型的状态字典
- torch.load():用于加载保存的模型状态字典
损失函数:
preds = model()
binimgs = binimgs.to(device)
loss = loss_fn(preds, binimgs)
preds的结果表征是bev栅格是否是障碍物,通过一个sigmoid可以转换为是障碍物的概率。binimg是当前场景下的障碍物真值。LSS使用交叉熵函数作为损失函数,交叉熵通常用于评估两个概率分布的差异程度,用在深度学习中表征的是真实世界与模型预测之间的分布差异,通常用于分类任务中。

loss_fn中使用的是BCEWithLogitsLoss,其与BCELoss的区别在于前者做了一个sigmoid,所以这里模型的输出后没有接sigmoid,所以注意不要再多加一个sigmoid了!快速理解binary cross entropy 二元交叉熵。这里还有一个trick需要注意,当正负样本数不平衡的时候,可以添加一个权重项,来提高正样本的损失的比重。


















 886
886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











