






如何使用hmmer注释候选基因,当然blast也可~
Blast安装及使用-Blast+2.14.0(bioinfomatics tools-001)_blast软件-CSDN博客
blast的快速安装使用-简易版_blast安装-CSDN博客
JCVI-筛选blast最佳结果(生物信息学工具-015)-CSDN博客
Hmmer安装与使用-Hmmer-3.3.2(bioinfomatics tools-009)-CSDN博客
在interprosacn下载候选基因的隐马模型,比如检索糖基转移酶
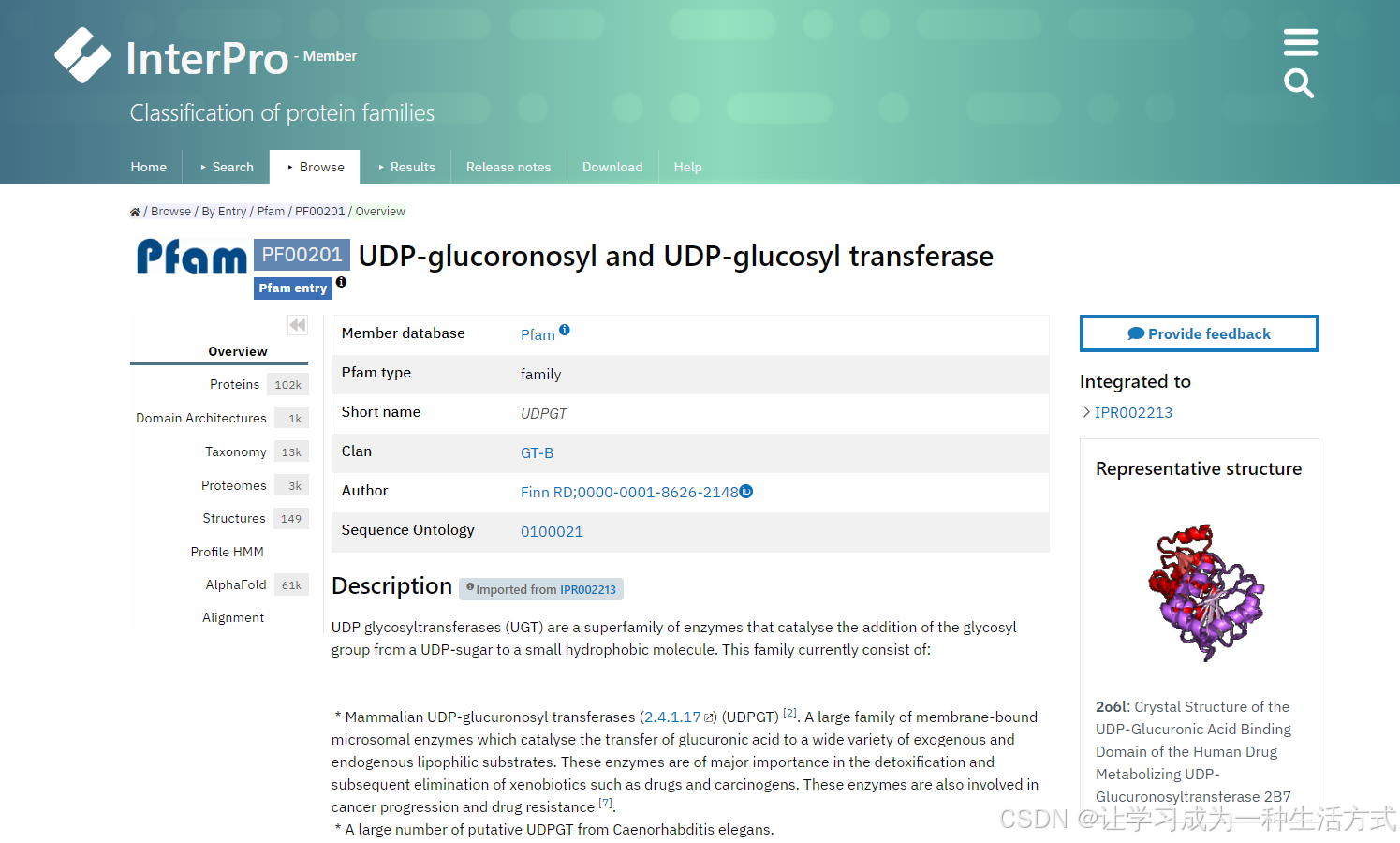
下载hmm模型
如果使用 hmmsearch 命令查询我们序列中的保守结构域:
hmmsearch --domtblout hmm_XXX.txt --cut_tc XXX.hmm Arabidopsis_thaliana.TAIR10.pep.all.fa
hmmsearch --cpu 20 --cut_ga --tblout out.tbl --domtblout out.dom PF1949.hmm ../XX.protein.fa- target length:这是输入序列的总长度。
- query length:这是查询序列的总长度,也就是蛋白结构域的长度。
- 在筛选时,不应关注这两个长度,因为它们没有实际意义。应该查看后面的两个 "from" 和 "to" 列,来确定这两条序列从哪里到哪里进行了比对。
- 一般来说,我们会筛选第 7 列中的 E-value 值。
一般来说,输出结果都输候选基因,处于blast比对40%的相似度,建议全部使用。
为了理解如何筛选,首先查看文件说明。以下是结构域格式输出的说明。官方文档可通过链接 http://eddylab.org/software/hmmer/Userguide.pdf 获取。
结构域比对表
在蛋白质搜索程序中,--domtblout 选项生成结构域比对表。每个结构域占一行,可能一个序列中会有多个结构域。结构域比对表有 22 个空格分隔的字段,后面跟着一个自由文本描述目标序列的字段。具体字段如下:
- 目标名称(Target Name):目标序列或 profile 的名称。
- 目标访问号(Target Accession):目标序列或 profile 的访问号,如果没有则为 "-"。
- 目标长度(tlen):目标序列或 profile 的长度,以氨基酸残基计。这个长度与查询序列的长度一起,有助于解释后续列中的结构域坐标。
- 查询名称(Query Name):查询序列或 profile 的名称。
- 查询访问号(Accession):查询序列或 profile 的访问号,如果没有则为 "-"。
- 查询长度(qlen):查询序列或 profile 的长度,以氨基酸残基计。
- E-value:整体序列/ profile 比对的 E-value(包括所有结构域)。
- 得分(Score):整体序列/ profile 比对的 Bit 得分(包括所有结构域),包含了为 null2 组合偏差的得分修正。
- 偏差(Bias):应用于得分的组合偏差修正。
- 结构域编号(#):该结构域的编号(1..ndom)。
- 总结构域数(of):该序列中报告的结构域总数,ndom。
- 条件 E-value(c-Evalue):结构域可靠性的宽松度量,是在比独立 E-value 更小的搜索空间中计算出来的。
- 独立 E-value(i-Evalue):如果这是唯一发现的结构域,其独立 E-value,排除其他结构域的影响。是该结构域可靠性的严格度量。
- 结构域得分(Domain Score):该结构域的 Bit 得分。
- 结构域偏差(Domain Bias):应用于该结构域的组合(null2)偏差得分修正。
- from(hmm 坐标):该结构域在 profile 中的 MEA 比对起始位置,编号为 1..N。
- to(hmm 坐标):该结构域在 profile 中的 MEA 比对结束位置,编号为 1..N。
- from(ali 坐标):该结构域在序列中的 MEA 比对起始位置,编号为 1..L。
- to(ali 坐标):该结构域在序列中的 MEA 比对结束位置,编号为 1..L。
- from(env 坐标):该结构域在序列中的 envelope 起始位置,编号为 1..L。
- to(env 坐标):该结构域在序列中的 envelope 结束位置,编号为 1..L。
- 准确度(Acc):在 MEA 比对中已对齐残基的平均后验概率;是整体比对可靠性的度量(0 到 1 之间,1.00 表示完全可靠的比对)。
- 目标描述(Description of Target):该行的剩余部分是目标的自由文本描述。

















 1743
1743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









